Автор: Денис Аветисян
Новая система кэширования ToolCaching значительно ускоряет работу языковых моделей, использующих внешние инструменты, за счет адаптивной стратегии и учета семантических особенностей.
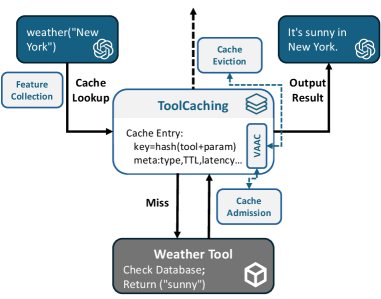
Представлен фреймворк ToolCaching, использующий семантические и системные признаки с алгоритмом адаптивного кэширования, ориентированным на ценность, для оптимизации рабочих нагрузок и снижения задержки в системах вызова инструментов.
Несмотря на значительные успехи в области больших языковых моделей (LLM) и их способности к взаимодействию с внешними API посредством tool-calling, проблема избыточных запросов остается нерешенной. В данной работе, ‘ToolCaching: Towards Efficient Caching for LLM Tool-calling’, предложен новый фреймворк ToolCaching, использующий семантические и системные признаки для адаптивного кэширования запросов. В основе решения лежит алгоритм VAAC, объединяющий bandit-based admission с многофакторным механизмом вытеснения, учитывающим частоту, давность и ценность кэшируемых данных. Сможет ли предложенный подход значительно снизить задержки и повысить эффективность LLM tool-calling в реальных приложениях, открывая новые горизонты для оптимизации workloads?
Эволюция больших языковых моделей: от возможностей к инструментарию
Всё более заметную роль в современной веб-разработке играют большие языковые модели (БЯМ), становясь основой для интеллектуальных чат-ботов и помощников в написании кода. Эти модели, обученные на огромных массивах данных, демонстрируют впечатляющую способность понимать и генерировать текст, что позволяет создавать приложения, способные к естественному взаимодействию с пользователем. От автоматизации клиентской поддержки до упрощения процессов разработки программного обеспечения, БЯМ открывают новые возможности для повышения эффективности и улучшения пользовательского опыта. Их интеграция в веб-приложения уже сейчас приводит к значительным изменениям в способах создания и использования цифровых сервисов, а потенциал для дальнейшего развития остается огромным.
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) сталкиваются с фундаментальным ограничением — их знания ограничены объемом данных, на которых они обучались. Это означает, что БЯМ не могут самостоятельно получать доступ к актуальной информации или выполнять действия за пределами своего внутреннего представления мира. Поэтому для решения сложных задач и предоставления действительно полезных ответов, БЯМ нуждаются в механизмах взаимодействия с внешними ресурсами, такими как базы данных, поисковые системы и различные API. Такое взаимодействие позволяет моделям расширять свои знания, получать доступ к реальному времени информации и выполнять действия в реальном мире, что значительно повышает их практическую ценность и открывает новые горизонты для применения в различных областях.
Потребность в расширении функциональности больших языковых моделей (LLM) привела к разработке механизма, известного как «вызов инструментов» (tool-calling). Эта инновация позволяет LLM преодолевать ограничения, связанные с объемом предварительно загруженных данных, и взаимодействовать с внешними ресурсами и API. Вместо того, чтобы полагаться исключительно на собственные знания, модель может динамически обращаться к специализированным инструментам для получения актуальной информации, выполнения конкретных задач или доступа к данным, которые ей недоступны в процессе обучения. Такой подход существенно расширяет спектр решаемых LLM задач, превращая их из простых генераторов текста в мощные платформы для автоматизации и принятия решений, способные интегрироваться с существующими системами и сервисами.

Проблема кэширования в эпоху вызова инструментов
Традиционные стратегии кэширования, эффективно работающие в различных областях, оказываются недостаточно эффективными применительно к вызовам инструментов большими языковыми моделями (LLM). Причина заключается в значительном разнообразии и динамичности запросов, поступающих к LLM. В отличие от предсказуемых запросов в традиционных системах, запросы к LLM могут варьироваться по структуре, содержанию и цели, что приводит к низкой эффективности попаданий в кэш при использовании стандартных методов. Это связано с тем, что даже незначительные изменения во входных данных могут приводить к существенно отличающимся результатам, что делает невозможным эффективное использование простых механизмов кэширования, основанных на точном совпадении запросов.
Эффективное кэширование в контексте вызова инструментов большими языковыми моделями (LLM) требует анализа семантики запроса, в частности, определения типа обращения к инструменту — информационного (INFORMATIONAL) или командного (COMMAND). Информационные запросы, как правило, возвращают данные, которые могут быть закэшированы на длительный срок, поскольку не зависят от изменений состояния системы. Командные запросы, напротив, изменяют состояние системы и требуют более короткого времени жизни (TTL) кэша, либо полной инвалидации кэша после выполнения, чтобы избежать возврата устаревших или некорректных данных. Разделение запросов по типу позволяет оптимизировать стратегию кэширования и существенно повысить производительность системы.
Простое сохранение результатов вызовов LLM недостаточно эффективно для кэширования, поскольку актуальность закэшированных данных напрямую зависит от контекста запроса. Для обеспечения корректности необходимо интеллектуальное управление значениями Time-to-Live (TTL). Длительность TTL должна динамически определяться на основе специфики запроса и типа вызванного инструмента, учитывая частоту изменений данных, на которые он ссылается. Например, для запросов, связанных с постоянно меняющимися данными (например, текущая погода), TTL должен быть короче, чем для запросов, основанных на статической информации. Неправильная настройка TTL может привести к предоставлению устаревших или неточных результатов, что снижает полезность системы.

ToolCaching: семантически осведомленная система кэширования
ToolCaching представляет собой систему кэширования, разработанную специально для задач вызова инструментов большими языковыми моделями (LLM). В отличие от общих решений кэширования, ToolCaching учитывает не только содержание запроса, но и его семантические характеристики — например, тип запрашиваемой операции — а также системные параметры, такие как задержка ответа и размер возвращаемых данных. Такой подход позволяет оптимизировать процесс кэширования, повышая эффективность и снижая нагрузку на LLM при повторных запросах.
Для оптимизации принятия решений о кэшировании, ToolCaching использует семантические характеристики запросов, такие как тип запроса (например, поиск, генерация текста, выполнение кода), и системные характеристики, включая задержку ответа и размер возвращаемого результата. Учет типа запроса позволяет различать запросы, требующие вычислений, и запросы, которые можно эффективно обслуживать из кэша. Мониторинг задержки и размера результата позволяет динамически адаптировать политику кэширования, отдавая предпочтение кэшированию быстрых и компактных ответов, что снижает нагрузку на систему и повышает скорость ответа.
В основе ToolCaching лежит алгоритм VAAC (Variable Adaptive Caching), который динамически корректирует стратегию кэширования на основе характеристик рабочей нагрузки и наблюдаемой производительности. VAAC анализирует такие параметры, как частота запросов к конкретным инструментам, латентность ответов и размер возвращаемых данных, для определения оптимального времени жизни кэшированных результатов и приоритета различных запросов. Алгоритм автоматически адаптируется к изменениям в характере нагрузки, обеспечивая высокую скорость ответа и эффективное использование ресурсов системы, избегая устаревших данных в кэше и минимизируя задержки, связанные с повторными вычислениями.
Результаты и оптимизация системы
Система VAAC демонстрирует значительное повышение коэффициента попадания в кэш, достигая улучшения в 11% по сравнению со стандартными подходами. Это означает, что большая часть запросов обслуживается непосредственно из кэша, а не требует повторных вычислений или доступа к более медленным источникам данных. В результате, снижается вычислительная нагрузка на систему, что позволяет ей работать быстрее и эффективнее, особенно при обработке большого количества однотипных запросов. Повышенный коэффициент попадания в кэш является ключевым фактором в оптимизации производительности, позволяя масштабировать систему без значительного увеличения требуемых ресурсов.
Исследования показали, что применение ToolCaching значительно сокращает общую задержку обработки запросов, достигая впечатляющего снижения в 34% при работе с набором данных для рекомендаций фильмов. Это достигается за счет оптимизации процесса поиска и обработки информации, позволяя системе быстрее предоставлять релевантные результаты пользователю. Сокращение задержки напрямую влияет на пользовательский опыт, обеспечивая более отзывчивую и плавную работу приложения, что особенно важно для интерактивных сервисов и приложений, требующих мгновенного отклика.
Интеграция разработанной системы с компилятором для больших языковых моделей (LLM) позволяет значительно оптимизировать управление многоступенчатыми процессами логического вывода. Компилятор, выступая в роли интеллектуального оркестратора, анализирует и перестраивает последовательность шагов рассуждений, необходимых для решения сложных задач. Это приводит к минимизации избыточных вычислений и эффективному распределению ресурсов, что, в свою очередь, существенно повышает общую производительность системы и снижает время отклика. В результате, сложные задачи, требующие многоэтапного анализа, решаются быстрее и точнее, открывая возможности для более сложных и интеллектуальных приложений.

Исследование представляет собой эволюцию подхода к оптимизации систем, где каждый коммит — это запись в летописи, а каждая версия — глава. Авторы предлагают ToolCaching, систему кэширования для LLM, которая адаптируется к рабочей нагрузке, используя семантические признаки и системные характеристики. Как заметил Брайан Керниган, «Простота — это высшая степень утонченности». В ToolCaching эта простота проявляется в элегантном использовании кэша для снижения задержки и повышения производительности, особенно при частом обращении к инструментам. Задержка исправлений — это налог на амбиции, и ToolCaching стремится минимизировать этот налог, обеспечивая быстрый доступ к результатам работы инструментов, тем самым позволяя системам стареть достойно.
Что дальше?
Представленная работа, касающаяся кэширования вызовов инструментов большими языковыми моделями, безусловно, демонстрирует прогресс в оптимизации систем. Однако, каждое улучшение — лишь отсрочка неизбежного. Время, как среда, в которой существуют эти системы, диктует свои условия. Кэш, как и любая структура, подвержен энтропии. Вопрос не в том, чтобы избежать сбоев, а в том, как достойно их принять и использовать как сигналы для рефакторинга.
Очевидным направлением для дальнейших исследований представляется адаптация к динамически меняющимся семантическим пространствам. Описанный подход, использующий семантические признаки, — лишь первый шаг. Более глубокое понимание того, как эти признаки стареют и деградируют, необходимо для создания действительно устойчивых систем. Рефакторинг, в данном контексте, предстает как диалог с прошлым, попытка извлечь уроки из ошибок и адаптироваться к новым реалиям.
Кроме того, заслуживает внимания исследование компромисса между стоимостью кэширования и потенциальной выгодой. Алгоритмы, основанные на принципах multi-armed bandit, — перспективный, но не единственный путь. Возможно, более эффективными окажутся гибридные подходы, сочетающие в себе различные стратегии и учитывающие специфику конкретной рабочей нагрузки. Каждая система стареет — вопрос лишь в том, насколько грациозно она это делает.
Оригинал статьи: https://arxiv.org/pdf/2601.15335.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 00:43