Автор: Денис Аветисян
Исследователи представили QuEPT — инновационную методику квантизации, позволяющую значительно повысить эффективность и снизить вычислительные затраты моделей искусственного интеллекта.
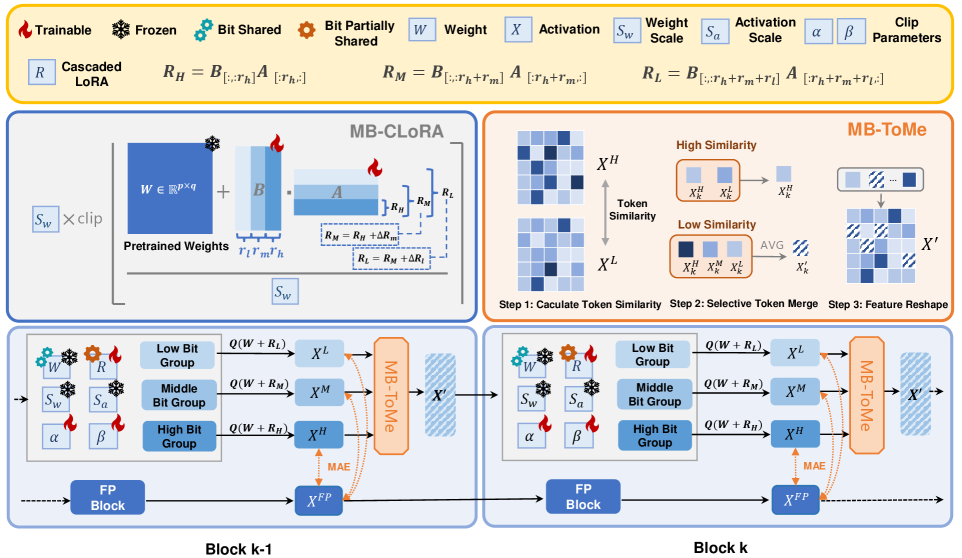
QuEPT использует многобитовую квантизацию, адаптацию низкого ранга и селективное объединение токенов для достижения передовых результатов на различных типах моделей, включая Vision Transformers и большие языковые модели.
Несмотря на успехи в области квантования моделей, адаптация к различным сценариям с использованием нескольких битов остается сложной задачей, особенно для больших трансформеров. В данной работе представлена система ‘QuEPT: Quantized Elastic Precision Transformers with One-Shot Calibration for Multi-Bit Switching’, предлагающая эффективный постобучающий метод, восстанавливающий многобитовые ошибки с помощью однократной калибровки на небольшом наборе данных. QuEPT позволяет динамически адаптироваться к различным битовым ширинам, используя каскадные адаптеры с низким рангом и поддерживая переключение между равномерным и смешанным квантованием без повторной оптимизации. Не приведет ли предложенный подход к созданию более гибких и экономичных моделей, способных эффективно работать в различных вычислительных средах?
Пределы Точности: Масштабируемость Современного ИИ
Современные большие языковые модели (БЯМ) и мультимодальные большие языковые модели (МБЯМ) демонстрируют впечатляющие возможности в обработке и генерации информации, превосходя существующие подходы во многих областях, включая машинный перевод, создание текста и анализ изображений. Однако, эти достижения достигаются за счет экспоненциального увеличения вычислительных затрат. Для обучения и запуска таких моделей требуются огромные объемы памяти, мощные графические процессоры и значительное количество энергии. Это создает серьезные препятствия для широкого внедрения и использования БЯМ и МБЯМ, особенно в условиях ограниченных ресурсов или для приложений, требующих высокой скорости обработки данных. По мере увеличения размера моделей и сложности задач, потребность в вычислительных ресурсах продолжает расти, что ставит под вопрос масштабируемость и доступность этих технологий.
Размер современной модели искусственного интеллекта, особенно в контексте больших языковых и мультимодальных моделей, оказывает непосредственное влияние на стоимость и доступность ее использования. Чем масштабнее архитектура и больше параметров содержит модель, тем больше вычислительных ресурсов требуется для осуществления даже единого запроса — процесса, известного как инференс. Это приводит к значительному увеличению финансовых затрат на инфраструктуру, что, в свою очередь, ограничивает возможности широкого внедрения и использования передовых технологий ИИ. Компании и исследователи, не располагающие достаточными ресурсами, оказываются неспособными эффективно применять эти модели, что создает препятствия для инноваций и замедляет прогресс в различных областях — от обработки естественного языка до компьютерного зрения. Таким образом, размер модели становится ключевым фактором, определяющим, кто может воспользоваться преимуществами новейших достижений в области искусственного интеллекта.
Снижение вычислительной точности, или квантизация, является ключевым методом сжатия больших языковых моделей, позволяющим существенно уменьшить их размер и вычислительные затраты. Однако, упрощенные подходы к квантизации, при которых точность представления чисел снижается без учета особенностей модели, часто приводят к неприемлемой потере точности и ухудшению качества генерируемого текста или результатов анализа. Потеря информации при переходе от, например, 32-битной точности к 8-битной или даже меньше, может значительно повлиять на способность модели различать тонкие нюансы в данных и корректно выполнять сложные задачи. Поэтому, современные исследования направлены на разработку более изощренных методов квантизации, учитывающих структуру и чувствительность различных частей модели, чтобы минимизировать потери точности и сохранить высокую производительность даже при значительном снижении вычислительных затрат.
Смешанная Точность: Баланс Между Эффективностью и Качеством
Смешанная квантизация (Mixed-Precision Quantization) представляет собой метод оптимизации моделей, заключающийся в назначении различной разрядности (количества бит) различным компонентам модели. В отличие от традиционной квантизации, где все веса и активации представляются одинаковым числом бит, смешанная квантизация позволяет использовать, например, 8 бит для наиболее чувствительных слоев и 4 или даже 2 бита для менее критичных. Это позволяет добиться более эффективного сжатия модели и снижения вычислительных затрат, сохраняя при этом приемлемый уровень точности. Выбор оптимальной разрядности для каждого компонента является ключевым фактором, определяющим эффективность данного подхода.
Оптимизация распределения разрядности (bit-width) между компонентами модели является критически важной задачей при использовании смешанной точности квантования. Для её решения применяются алгоритмические подходы, в частности, динамическое программирование (DP), позволяющее найти оптимальное распределение разрядности, минимизирующее потери точности. В качестве метрики для оценки влияния различных распределений разрядности на изменение распределения активаций часто используется расхождение Кульбака-Лейблера (KL Divergence) D_{KL}(P||Q), которое количественно оценивает разницу между исходным распределением и распределением после квантования. Применение DP в сочетании с KL Divergence позволяет автоматизировать процесс подбора оптимальной разрядности для каждого слоя или компонента модели, что способствует повышению эффективности квантования и минимизации потерь точности.
Простые подходы к смешанно-точной квантизации зачастую сталкиваются с трудностями при согласовании различных уровней точности, что приводит к возникновению новых ошибок. Несогласованность в использовании разных бит-ширин для различных слоев или весов модели может приводить к накоплению ошибок квантизации и снижению общей точности. В частности, переходы между слоями, использующими разную точность, требуют специальных методов для минимизации потери информации и поддержания стабильности вычислений. Это проявляется в увеличении расхождения между результатами, полученными в полной и квантованной точности, и может потребовать дополнительных техник калибровки или fine-tuning для восстановления исходной производительности.
Основная сложность при использовании квантизации смешанной точности заключается в эффективном управлении возникающей ошибкой квантизации. Квантизация, представляющая собой снижение точности чисел с плавающей запятой до целочисленных форматов, неизбежно вносит погрешности. Эти погрешности могут накапливаться и существенно влиять на точность модели, особенно при использовании различных разрядностей для разных слоев. Минимизация этой ошибки требует тщательного анализа чувствительности каждого слоя к квантизации и применения методов, таких как калибровка и тонкая настройка (fine-tuning), для компенсации возникающих искажений. Эффективные стратегии управления ошибкой квантизации критически важны для сохранения производительности и точности модели после квантизации.
QuEPT: Эластичная Квантизация для Реальных Условий
QuEPT представляет собой фреймворк эластичной постобученной квантизации, позволяющий динамически настраивать разрядность весов и активаций модели без необходимости переобучения. В отличие от традиционных методов квантизации, требующих повторного обучения для каждой новой разрядности, QuEPT обеспечивает гибкую конфигурацию разрядности в реальном времени, что существенно упрощает развертывание моделей на различных аппаратных платформах и позволяет адаптироваться к изменяющимся требованиям к производительности и точности. Такой подход особенно важен для задач, где ресурсы ограничены или требуется быстрое переключение между разными режимами работы.
Квантование весов и активаций является ключевым компонентом эффективной компрессии моделей глубокого обучения. Квантование весов подразумевает снижение разрядности представления весов нейронной сети, например, с 32-битных чисел с плавающей точкой до 8-битных целых чисел. Аналогично, квантование активаций уменьшает разрядность выходных данных слоев сети. Оба подхода приводят к значительному уменьшению объема памяти, необходимого для хранения модели, и снижению вычислительной сложности, поскольку операции с целыми числами выполняются быстрее, чем с числами с плавающей точкой. Комбинирование квантования весов и активаций позволяет достичь высокой степени сжатия при сохранении приемлемого уровня точности модели.
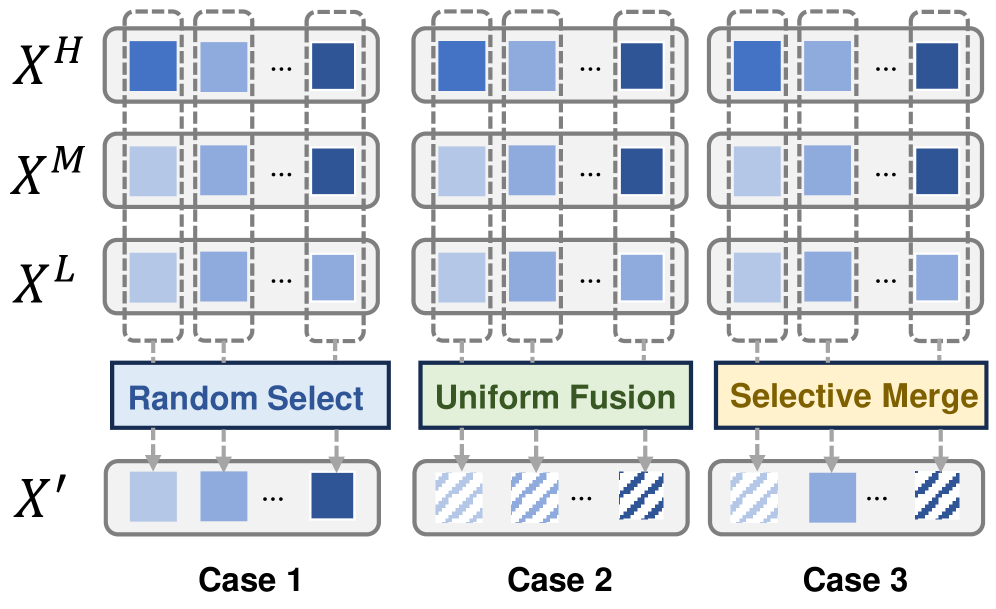
Для смягчения ошибок, возникающих при использовании смешанной точности в процессе квантизации, QuEPT использует методы Multi-Bit Token Merging (MB-ToMe) и Multi-Bit Cascaded Low-Rank Adapters (MB-CLoRA). MB-ToMe объединяет токены, что позволяет снизить гранулярность квантизации и уменьшить потери информации. MB-CLoRA, основанный на адаптации низкого ранга, применяет каскадные адаптеры для тонкой настройки весов модели в условиях пониженной точности, эффективно компенсируя возникающие погрешности и сохраняя производительность. Оба подхода направлены на минимизацию влияния квантизации на точность модели без необходимости переобучения.
При использовании архитектуры ViT-S на наборе данных ImageNet, QuEPT демонстрирует точность в 6,2% при квантовании весов и активаций до 4 бит (W4A4). Этот результат превосходит показатели, достигнутые алгоритмом ERQ (Error-Resilient Quantization) при аналогичных условиях. Достижение более высокой точности при таком низком уровне квантования позволяет значительно снизить требования к памяти и вычислительным ресурсам, делая модель более подходящей для развертывания на устройствах с ограниченными ресурсами.
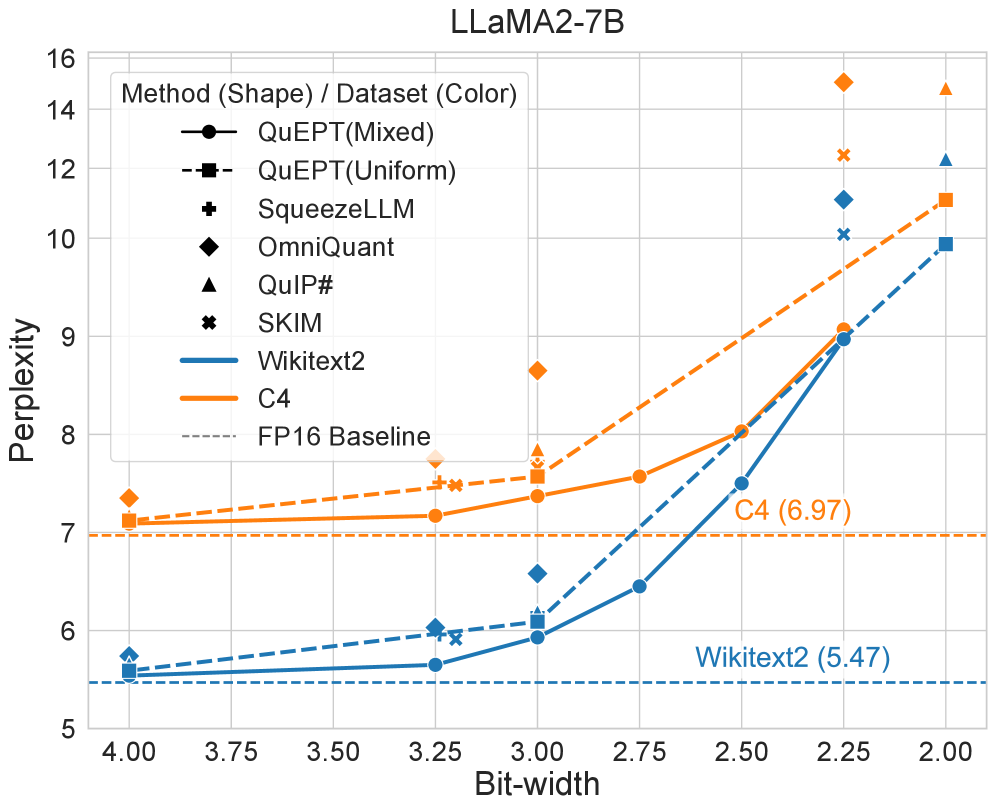
При использовании модели LLaMA2-7B и набора данных WikiText2 с квантованием W2.25, разработанный фреймворк QuEPT достиг показателя перплексии в 8.97. Этот результат демонстрирует высокую эффективность QuEPT в задачах языкового моделирования, обеспечивая низкую перплексию, что свидетельствует о качественном предсказании вероятности последовательностей слов. Достигнутая перплексия подтверждает возможность эффективной компрессии модели с сохранением ее производительности в задачах генерации и анализа текста.
В основе QuEPT лежит использование метода Low-Rank Adaptation (LoRA), что позволяет оптимизировать производительность модели с минимальными вычислительными затратами. LoRA предполагает добавление небольшого количества обучаемых параметров к исходной предобученной модели, что снижает количество параметров, необходимых для адаптации к новым задачам. В QuEPT, LoRA применяется для тонкой настройки весов после квантизации, компенсируя потерю точности, вызванную понижением разрядности. Такой подход позволяет добиться высокой производительности при сохранении относительно небольшого размера модели и снижении требований к вычислительным ресурсам, необходимых для обучения и развертывания.
Широкая Применимость и Перспективы Развития
Разработанный фреймворк QuEPT демонстрирует высокую эффективность при работе как с моделями Vision Transformer (ViT), обрабатывающими визуальную информацию, так и с крупными языковыми моделями, оперирующими текстом. Эта универсальность существенно расширяет сферу его применения, позволяя эффективно квантовать модели, работающие с различными типами данных. Подобная мультимодальная адаптивность открывает возможности для создания компактных и производительных AI-систем, способных решать широкий спектр задач, от обработки изображений и видео до анализа текста и генерации контента. Фактически, QuEPT предоставляет единую платформу для оптимизации моделей, работающих с разными модальностями данных, что упрощает разработку и развертывание передовых AI-приложений.
В ходе тестирования на мультимодальной модели LLaVA-OneVision-7B, включающего пять различных наборов данных с использованием квантизации W3A16, разработанный фреймворк QuEPT продемонстрировал среднюю точность в 1.5%. Этот результат превосходит показатели, достигнутые конкурирующим методом MBQ, что свидетельствует о более эффективной обработке и сохранении информации при снижении точности вычислений. Достигнутое превосходство подтверждает способность QuEPT обеспечивать высокую производительность даже в условиях ограниченных вычислительных ресурсов, что открывает возможности для применения передовых моделей искусственного интеллекта в более широком спектре устройств и приложений.
В ходе экспериментов с квантованием W4A8, разработанный фреймворк QuEPT демонстрирует среднюю точность в 4.3% на рассматриваемых наборах данных. Этот результат превосходит показатели альтернативного метода MBQ, подтверждая эффективность QuEPT в снижении вычислительной нагрузки без значительной потери качества. Достижение более высокой точности при использовании меньшего количества бит имеет существенное значение для развертывания сложных моделей искусственного интеллекта на устройствах с ограниченными ресурсами, расширяя сферу их применения.
В ходе экспериментов с языковой моделью LLaMA2-7B и текстовым корпусом WikiText2, при использовании квантования W3.00, разработанный фреймворк QuEPT достиг показателя перплексии в 5.93. Данный результат демонстрирует способность QuEPT эффективно сжимать модели без существенной потери качества генерируемого текста. Перплексия, являясь мерой неопределенности языковой модели, указывает на то, насколько хорошо модель предсказывает последовательность слов; более низкое значение указывает на лучшую производительность. Достигнутый результат подчеркивает потенциал QuEPT для развертывания сложных языковых моделей даже на устройствах с ограниченными ресурсами, открывая новые возможности для применения искусственного интеллекта в различных сферах.
При использовании квантования W4.00, фреймворк QuEPT демонстрирует значение перплексии в 5.54. Этот показатель, полученный на модели LLaMA2-7B и датасете WikiText2, свидетельствует о высокой эффективности алгоритма в сжатии моделей без существенной потери качества генерируемого текста. Низкая перплексия указывает на то, что модель хорошо предсказывает последовательность слов в тексте, что является ключевым показателем для задач обработки естественного языка и генерации текста. Достижение такого результата с использованием 4-битного квантования открывает возможности для развертывания сложных языковых моделей на устройствах с ограниченными вычислительными ресурсами, расширяя сферу их применения.
Адаптивность разработанного фреймворка открывает возможности для внедрения передовых моделей искусственного интеллекта на устройствах с ограниченными ресурсами. Это достигается благодаря оптимизации, позволяющей эффективно использовать вычислительные мощности и память, что критически важно для мобильных устройств, встроенных систем и других платформ, где энергоэффективность и компактность имеют первостепенное значение. Возможность развертывания сложных моделей на подобных устройствах значительно расширяет доступ к технологиям искусственного интеллекта, позволяя решать задачи непосредственно на месте, без необходимости передачи данных в облако, что обеспечивает повышенную конфиденциальность и снижает задержки. Таким образом, фреймворк способствует демократизации искусственного интеллекта, делая его более доступным и полезным для широкого круга пользователей и приложений.
Для повышения точности квантования и минимизации возникающих ошибок применяются методы сглаживания, такие как SmoothQuant и SpinQuant. Эти техники позволяют более эффективно аппроксимировать веса нейронной сети, снижая потери информации, неизбежные при переходе к более низким битовым представлениям. SmoothQuant, например, использует стратегию, направленную на равномерное распределение ошибок квантизации, в то время как SpinQuant опирается на вращение векторов весов для оптимизации процесса квантования. В результате применения этих методов значительно улучшается производительность модели при использовании квантованных весов, приближая её к результатам, достигаемым с использованием полноразрядных представлений, и обеспечивая более высокую эффективность работы, особенно на устройствах с ограниченными ресурсами.
Дальнейшие исследования направлены на автоматизацию выбора разрядности, что позволит оптимизировать процесс квантования и добиться максимальной эффективности. Разрабатываются динамические стратегии квантования, способные адаптироваться к особенностям данных и модели в реальном времени. Это позволит не только сократить вычислительные затраты и объем памяти, необходимые для хранения и обработки моделей искусственного интеллекта, но и повысить их производительность на различных аппаратных платформах, включая устройства с ограниченными ресурсами. Автоматизация выбора разрядности и внедрение динамических стратегий представляют собой перспективное направление, способное значительно расширить возможности применения передовых моделей ИИ в самых разнообразных областях.
Исследование демонстрирует, что эффективное управление вычислительной сложностью современных трансформеров требует не просто снижения точности представления данных, но и интеллектуального распределения ресурсов. Как отмечает Ян Лекун: «Машинное обучение — это не столько программирование, сколько математическое моделирование». QuEPT, представляя собой фреймворк пост-тренировочной квантизации, подтверждает эту мысль. Использование многобитной квантизации и селективного объединения признаков токенов позволяет достичь значительного сжатия моделей без существенной потери производительности, что является ярким примером математической дисциплины в хаосе больших данных. Это особенно важно для Vision Transformers, больших языковых моделей и мультимодальных LLM, где каждый процент повышения эффективности имеет решающее значение.
Куда двигаться дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к квантованию, однако следует признать, что истинная красота алгоритма не ограничивается достижением state-of-the-art метрик. Вопрос о вычислительной устойчивости в экстремальных условиях, когда размер модели приближается к пределу возможностей оборудования, остаётся открытым. Необходимо исследовать, насколько эффективно предложенная схема масштабируется при дальнейшем увеличении числа параметров и сложности архитектуры, не превращаясь в сложноуправляемый хаос.
Особое внимание следует уделить исследованию теоретических пределов сжатия информации. Возможно ли, применительно к трансформерам, достичь точки, за которой дальнейшее уменьшение битовой точности неизбежно приводит к катастрофической потере информации? Или же, существуют ещё не открытые закономерности, позволяющие эффективно кодировать семантическую информацию, используя всё меньше и меньше бит? Простое увеличение числа параметров, даже с применением LoRA, — это лишь временное решение, а не фундаментальный прорыв.
Наконец, стоит задуматься о связи между архитектурой модели и эффективностью квантования. Возможно, существуют альтернативные архитектуры, изначально более приспособленные к низкоточному представлению данных, чем стандартные трансформеры. Истинная элегантность заключается не в оптимизации существующего решения, а в создании принципиально нового, свободного от избыточности и основанного на глубоком понимании математических основ машинного обучения.
Оригинал статьи: https://arxiv.org/pdf/2602.12609.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Путь к Оптиму: Новый Алгоритм, Вдохновленный Человеческим Поиском
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Сборка с подсказками: Искусственный интеллект и дополненная реальность на службе у мастера
- Звук в коде: новая эра токенизации аудио
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
2026-02-16 12:04