Автор: Денис Аветисян
Новый подход позволяет значительно повысить эффективность и скорость работы ИИ-помощников в разработке программного обеспечения.
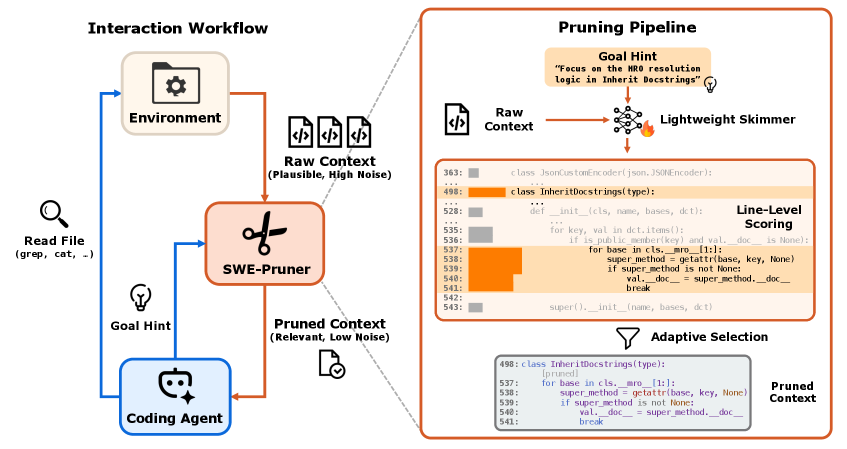
SWE-Pruner: адаптивная обрезка контекста на уровне строк кода для повышения производительности кодирующих агентов.
Несмотря на впечатляющие возможности LLM-агентов в разработке программного обеспечения, их производительность часто ограничивается длинными контекстами, приводящими к высоким затратам и задержкам. В данной работе представлена система ‘SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents’, предлагающая адаптивный механизм отсечения контекста, ориентированный на задачи кодирования. SWE-Pruner, вдохновленный практикой опытных программистов, динамически выбирает релевантные строки кода, основываясь на текущей цели, и позволяет значительно сократить объем токенов — до 54% на бенчмарке SWE-Bench Verified — без существенной потери производительности. Возможно ли дальнейшее повышение эффективности LLM-агентов за счет более тонкой настройки механизмов управления контекстом и адаптации к специфике задач разработки?
Преодоление «Стены Контекста»: Вызов для Больших Языковых Моделей
Большие языковые модели (БЯМ) сталкиваются с фундаментальным ограничением, связанным с объемом контекстного окна — количеством информации, которую модель способна эффективно обработать одновременно. Это особенно критично при работе с большими кодовыми базами, поскольку реальные программные проекты часто состоят из тысяч или даже миллионов строк кода. Ограниченный контекст не позволяет модели уловить взаимосвязи между удаленными частями кода, что существенно затрудняет выполнение задач, таких как отладка, рефакторинг или даже простое понимание логики работы программы. В результате, применение БЯМ к практическим задачам разработки программного обеспечения оказывается затруднено, требуя поиска новых подходов к управлению контекстом и эффективной обработке больших объемов информации.
Ограниченность контекстного окна существенно влияет на способность больших языковых моделей (LLM) эффективно выполнять отладку и всесторонний анализ кода. Традиционные подходы к отладке, требующие одновременного рассмотрения значительных фрагментов кода и взаимосвязей между ними, становятся затруднительными, поскольку LLM не могут удержать в памяти весь необходимый объем информации. Это влечет за собой необходимость разработки новых методов управления контекстом, позволяющих моделям избирательно фокусироваться на релевантных частях кода, игнорируя несущественные детали. Такие подходы должны обеспечивать сохранение логической целостности анализа и отладки, несмотря на ограниченный объем обрабатываемой информации, что требует инновационных алгоритмов и структур данных для представления и манипулирования кодом в рамках ограниченного контекста.
Попытки решения проблемы ограниченного контекста больших языковых моделей (LLM) путем простого увеличения длины контекстного окна сталкиваются с существенными трудностями. Увеличение объема обрабатываемой информации ведет к экспоненциальному росту вычислительных затрат и требований к памяти, делая этот подход непрактичным для работы с крупномасштабным кодом. Более того, простое расширение контекста не решает проблему информативной перегрузки — LLM становится сложно выделить релевантную информацию из огромного объема данных, что снижает точность и эффективность анализа кода. Вместо этого требуется разработка более интеллектуальных методов управления контекстом, способных эффективно фильтровать, структурировать и приоритизировать информацию, представляя LLM только наиболее важные фрагменты кода для решения поставленной задачи.
Эффективная обработка больших объемов кода является ключевым фактором для реализации полного потенциала языковых моделей (LLM) в сфере разработки программного обеспечения. Ограниченность контекстного окна LLM традиционно препятствует анализу и отладке крупных проектов, однако преодоление этого барьера откроет возможности для автоматизации сложных задач, таких как рефакторинг, обнаружение уязвимостей и генерация нового кода на основе существующих баз. Разработка методов, позволяющих LLM выборочно фокусироваться на релевантных частях кода и эффективно управлять информацией, станет основой для создания интеллектуальных инструментов, способных существенно повысить производительность и качество разработки. В конечном итоге, успешное решение этой проблемы позволит превратить LLM из перспективной технологии в незаменимого помощника для профессиональных разработчиков.
SWE-Pruner: Целенаправленная Фильтрация Кода для Языковых Моделей
SWE-Pruner — это новый фреймворк, предназначенный для отсеивания избыточного кода в длинных контекстах, передаваемых большим языковым моделям (LLM). Его основная цель — позволить LLM концентрироваться исключительно на релевантной информации, необходимой для выполнения конкретной задачи. В отличие от существующих методов, работающих со всем объемом кода, SWE-Pruner динамически фильтрует информацию, основываясь на текущем целевом запросе, что позволяет повысить эффективность обработки и снизить вычислительные затраты.
В отличие от статических методов обрезки контекста, SWE-Pruner использует динамическую фильтрацию кода, ориентированную на текущую задачу агента. Это означает, что система не просто удаляет неиспользуемый код глобально, а адаптирует процесс обрезки в зависимости от конкретной цели, которую необходимо достичь. Определение релевантности кода производится на основе анализа текущего запроса и логики выполнения задачи, что позволяет точно отсекать фрагменты, не имеющие отношения к текущему этапу работы. Такой подход обеспечивает более эффективное использование контекстного окна языковой модели и снижает вычислительные затраты.
В рамках SWE-Pruner фильтрация длинного контекста кода осуществляется на уровне отдельных строк. Такой подход позволяет гарантировать синтаксическую корректность результирующего кода после удаления избыточной информации. Сохранение целостности синтаксиса критически важно для дальнейшей обработки кода языковой моделью и предотвращения ошибок компиляции или интерпретации. Использование гранулярности на уровне строк обеспечивает более точную и безопасную фильтрацию по сравнению с подходами, работающими с большими блоками кода, минимизируя риск внесения ошибок в работающий код.
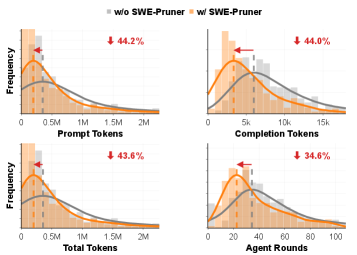
Применение SWE-Pruner позволяет эффективно преодолеть проблему ограничения контекста (“Context Wall”) в больших языковых моделях. Экспериментальные данные, полученные на тестовых наборах SWE-Bench и SWE-QA, демонстрируют снижение потребления токенов на 23-54% по сравнению с базовыми моделями. Более того, данная оптимизация приводит к сокращению количества раундов взаимодействия агента на 18-35%, что свидетельствует о повышении эффективности и скорости решения задач за счет более целенаправленной обработки релевантной информации.
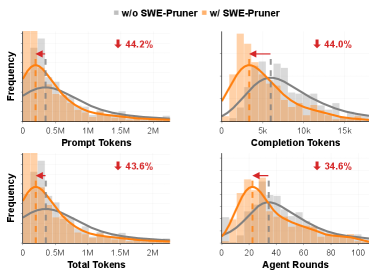
Нейронный Скиммер: Архитектура и Обучение
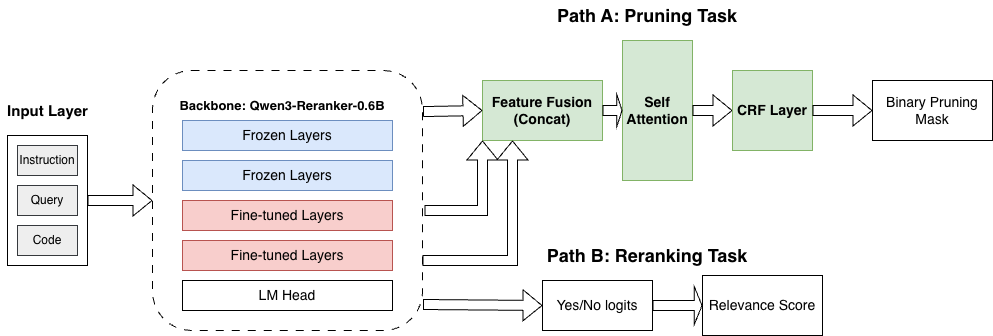
В основе фильтрации в SWE-Pruner лежит нейронный скиммер, реализованный на базе Qwen3-Reranker — легковесной и эффективной модели переранжирования. Qwen3-Reranker предназначен для оценки релевантности сегментов кода и выделения наиболее значимых фрагментов. Использование данной модели позволяет снизить вычислительную нагрузку, сохраняя при этом ключевую информацию, необходимую для последующей обработки кодом. Легковесность Qwen3-Reranker обеспечивает высокую скорость работы и позволяет применять SWE-Pruner в ресурсоограниченных средах.
Модель Qwen3-Reranker обучается с использованием функции потерь Conditional Random Field Negative Log Likelihood (CRF-NLL), которая оптимизирована для точного предсказания релевантности фрагментов кода. CRF-NLL позволяет модели учитывать взаимосвязи между соседними фрагментами кода при оценке их важности, что повышает точность определения релевантных участков. Оптимизация на основе CRF-NLL направлена на максимизацию вероятности правильной оценки релевантности каждого фрагмента кода в контексте всей программы, что критически важно для эффективной фильтрации и сохранения структурной целостности кода.
Архитектура SWE-Pruner обеспечивает эффективную идентификацию значимых сегментов кода и минимизацию обработки нерелевантной информации. Это достигается за счет использования нейронного скиммера, который позволяет отфильтровывать фрагменты кода, не влияющие на общую структуру и логику программы. В результате, количество токенов, передаваемых агенту кодирования, существенно сокращается, что повышает эффективность обработки и снижает вычислительные затраты без потери критически важной информации. Данный подход позволяет сохранить структурную целостность кода, обеспечивая точность AST в 87.3%.
Использование нейронного скиммера в SWE-Pruner позволяет значительно сократить количество токенов, обрабатываемых кодирующим агентом, без потери критически важной информации. Достигнутая точность сохранения структуры абстрактного синтаксического дерева (AST) составляет 87.3%, что подтверждает эффективность подхода к сохранению структурной целостности кода при сокращении объема обрабатываемых данных. Это снижение нагрузки на кодирующий агент способствует повышению скорости и эффективности процесса кодирования.
Эмпирическая Валидация и Влияние на Задачи Кодирования
Проведенная оценка SWE-Pruner на задачах Long Code QA и SWE-Bench Verified продемонстрировала существенное превосходство над существующими подходами. Исследование показало, что оптимизация кода с помощью данного инструмента приводит к заметному улучшению производительности при решении сложных задач, связанных с длинным кодом. Наблюдаемые результаты подтверждают эффективность SWE-Pruner в контексте автоматизированного исправления и завершения кода, открывая возможности для создания более быстрых и надежных систем разработки программного обеспечения. Данный подход позволяет значительно повысить эффективность существующих инструментов и алгоритмов, используемых в процессе кодирования.
Ключевым преимуществом SWE-Pruner является его способность сохранять синтаксическую корректность абстрактного синтаксического дерева (AST) при удалении избыточного кода. Это гарантирует, что после процесса обрезки, полученный код остается не только функциональным, но и полностью исполняемым, избегая ошибок компиляции или выполнения. Сохранение AST-корректности позволяет избежать внесения синтаксических ошибок, которые часто возникают при автоматическом изменении кода, и обеспечивает надежность и предсказуемость работы системы. В результате, SWE-Pruner не просто уменьшает объем кода, но и гарантирует его работоспособность после оптимизации, что критически важно для практического применения в реальных проектах разработки программного обеспечения.
Исследование показало, что SWE-Pruner значительно повышает эффективность решения задач за счет сокращения количества итераций, необходимых агенту. Уменьшение числа раундов взаимодействия не только ускоряет процесс кодирования, но и существенно снижает вычислительные затраты, что особенно важно при работе со сложными и объемными проектами. Повышение эффективности достигается благодаря интеллектуальной обрезке кода, позволяющей агенту быстрее сфокусироваться на наиболее важных аспектах задачи и избежать избыточных вычислений. Данный подход позволяет более рационально использовать ресурсы и делает процесс разработки более экономичным и быстрым.
Исследования показали, что SWE-Pruner демонстрирует значительные улучшения в задачах, связанных с длинным кодом. В частности, при использовании с SeedCoder, система достигла показателя 56.73\% в оценке завершения длинного кода (Long Code Completion ES) и 55.75\% точности в задачах ответа на вопросы по длинному коду (Long Code QA), при этом обеспечивая восьмикратное сжатие кода. В ряде случаев, таких как задача Django-10554, SWE-Pruner позволил успешно завершить задачу, которая не могла быть решена без предварительной обрезки, достигнув при этом снижения количества токенов на 83.3\%. Эти результаты подчеркивают способность системы не только оптимизировать код, но и повышать эффективность решения сложных задач программирования.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области разработки программного обеспечения. Авторы предлагают SWE-Pruner — систему, оптимизирующую контекст для кодирующих агентов, что напрямую соответствует идее доказательства корректности, а не просто достижения работоспособности на тестовых примерах. Как заметил Блез Паскаль: «Вся наша логика заключается в том, что мы не знаем ничего». В контексте SWE-Pruner, это означает признание необходимости постоянной оптимизации и сокращения избыточной информации, чтобы алгоритм функционировал не просто ‘работал’, а был доказательно эффективным и надежным. Сокращение потребления токенов, предложенное в статье, — это шаг к более строгой, логически обоснованной разработке.
Что дальше?
Представленная работа, хотя и демонстрирует ощутимый прогресс в области оптимизации контекста для кодирующих агентов, лишь приоткрывает дверь в сложный мир эффективной обработки длинных последовательностей. Доказательство истинной элегантности алгоритма SWE-Pruner потребует не просто расширения набора тестовых примеров, но и формальной верификации его поведения в граничных случаях. Проблема не в том, чтобы заставить модель “работать” на конкретных задачах, а в том, чтобы предсказать ее поведение в произвольной ситуации.
Очевидным направлением для дальнейших исследований является разработка более изощренных метрик релевантности контекста. Простое отслеживание использования строк кода, безусловно, полезно, но недостаточно. Необходимо учитывать семантическую сложность, взаимосвязи между различными частями кода и, возможно, даже вероятность внесения изменений в конкретную строку в процессе отладки. Иначе, это лишь иллюзия оптимизации.
В конечном итоге, истинный прорыв потребует отказа от наивной веры в масштабирование моделей. Более глубокое понимание принципов работы внимания, разработка новых архитектур, способных эффективно обрабатывать информацию, и, возможно, даже отказ от текущих парадигм машинного обучения — вот что действительно необходимо. В противном случае, мы обречены на бесконечную гонку за вычислительными ресурсами.
Оригинал статьи: https://arxiv.org/pdf/2601.16746.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Квантовый скачок из Андхра-Прадеш: что это значит?
- LLM: математика — предел возможностей.
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Почему ваш Steam — патологический лжец, и как мы научили компьютер читать между строк
2026-01-26 16:00