Автор: Денис Аветисян
Исследователи предлагают PISA — механизм разреженного внимания, позволяющий существенно повысить скорость работы диффузионных трансформаторов без потери качества генерируемых изображений и видео.

PISA сочетает точные вычисления с эффективной кусочно-аппроксимацией на основе разложения в ряд Тейлора для оптимизации разреженного внимания в диффузионных моделях.
В то время как диффузионные трансформаторы демонстрируют впечатляющие результаты в генерации изображений и видео, их вычислительная сложность, обусловленная квадратичной зависимостью внимания, ограничивает их масштабируемость. В данной работе, озаглавленной ‘PISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers’, предложен новый подход к разреженному вниманию, основанный на идее точного вычисления для критичных блоков и эффективной кусочно-аппроксимации остальных с использованием разложения в ряд Тейлора. Такой подход позволяет добиться значительного ускорения вычислений — до 2.57 раз на моделях Wan2.1-14B и Hunyuan-Video — без потери качества генерируемых данных. Сможет ли предложенный механизм PISA стать стандартом де-факто для ускорения диффузионных моделей в задачах компьютерного зрения и видеообработки?
Внимание к деталям: Ограничения и вызовы современных генеративных моделей
Диффузионные трансформеры (DiT) в настоящее время зарекомендовали себя как передовые модели для генерации высококачественных изображений и видео, однако их применение сопряжено со значительными вычислительными затратами. Эти модели демонстрируют впечатляющую способность создавать детализированный и реалистичный контент, но для этого требуется огромная вычислительная мощность и большие объемы памяти. По мере увеличения разрешения генерируемых изображений и длительности видео, потребность в ресурсах возрастает экспоненциально, что создает серьезные ограничения для их широкого применения и разработки более сложных моделей. В результате, исследователи активно ищут способы оптимизации архитектуры DiT и разработки новых методов, позволяющих снизить вычислительную сложность без ущерба для качества генерируемого контента.
Традиционные механизмы «полного внимания», несмотря на свою эффективность, сталкиваются с серьезными ограничениями при работе с длинными последовательностями данных и изображениями высокого разрешения. Суть проблемы заключается в квадратичной зависимости вычислительных затрат от длины последовательности — то есть, при удвоении длины входных данных, потребность в вычислительных ресурсах возрастает в четыре раза. O(n^2) — такова сложность вычислений, что делает обработку длинных видео или изображений с большим количеством деталей крайне затратной и часто непрактичной. Это препятствует моделированию долгосрочных зависимостей, необходимых для создания связных и детализированных изображений и видео, поскольку объем вычислений быстро становится непосильным даже для современных вычислительных систем.
Ограничения вычислительных ресурсов оказывают существенное влияние на способность моделей генерировать связные и детализированные изображения или видео. Невозможность эффективно учитывать зависимости между удаленными элементами последовательности — ключевая проблема, препятствующая созданию целостных и правдоподобных результатов. В частности, при генерации длинных видео или изображений высокого разрешения, модели, сталкиваясь с вычислительными трудностями, вынуждены упрощать анализ связей между различными частями изображения, что приводит к потере когерентности и детализации. В результате, финальное изображение или видео может страдать от несогласованности, размытости или отсутствия важных деталей, поскольку модель не смогла полноценно учесть взаимосвязи между всеми элементами генерируемой сцены. Таким образом, преодоление этого вычислительного барьера является необходимым условием для достижения высокого качества и реалистичности в задачах генерации контента.

Разреженное внимание: Путь к эффективности вычислений
Методы разреженного внимания (Sparse Attention) представляют собой подход к снижению вычислительной сложности механизма внимания в нейронных сетях. Традиционный механизм внимания требует вычисления внимания между каждой парой элементов входной последовательности, что приводит к квадратичной зависимости от длины последовательности O(n^2). Разреженное внимание решает эту проблему, выборочно вычисляя внимание только над подмножеством пар «ключ-значение». Это достигается за счет различных стратегий, таких как выборка фиксированного числа наиболее релевантных пар, или использование паттернов разреженности, определяющих, какие пары должны быть обработаны. В результате, вычислительная сложность может быть снижена до O(n \sqrt{n}) или даже O(n) в зависимости от выбранной стратегии разреженности, что позволяет обрабатывать более длинные последовательности с меньшими вычислительными затратами.
Методы блочной разреженной аттенции (Block Sparse Attention) и SANA исследуют различные уровни гранулярности разреженности для оптимизации вычислений. Блочная разреженность оперирует блоками токенов, что упрощает реализацию и снижает вычислительные затраты, однако может приводить к потере информации при разделении на блоки. SANA (Sparse Attention with Non-uniform Attention) использует неравномерное распределение разреженности, фокусируясь на наиболее важных токенах и уменьшая вычислительную сложность без значительной потери точности. Оба подхода стремятся к балансу между эффективностью вычислений и сохранением качества модели, позволяя снизить потребление памяти и ускорить процесс обучения и инференса.
Методы SLA (Sparse Linear Attention) и Linfusion представляют собой дальнейшее развитие механизмов внимания, комбинируя преимущества разреженного и линейного внимания. SLA использует разреженное внимание для снижения вычислительной сложности, а затем применяет линейное внимание для обработки оставшихся пар ключ-значение, обеспечивая баланс между эффективностью и точностью. Linfusion, в свою очередь, интегрирует разреженные и линейные компоненты внимания параллельно, позволяя модели динамически выбирать, какой тип внимания наиболее подходит для конкретных входных данных. Это позволяет добиться значительного снижения вычислительных затрат по сравнению с полным вниманием, сохраняя при этом высокую производительность на различных задачах обработки естественного языка.
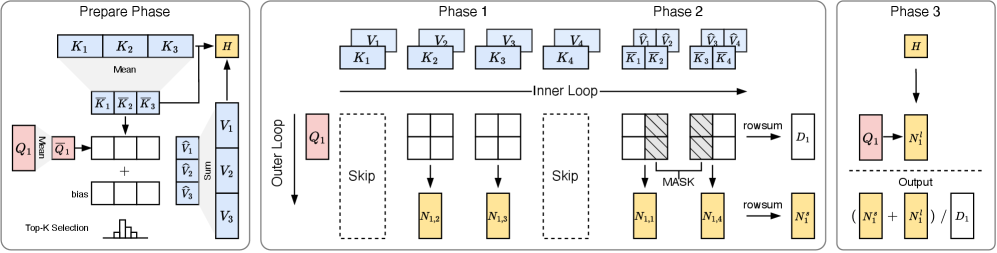
PISA: Обучение без затрат: Разреженное внимание через аппроксимацию Тейлора
Метод Piecewise Sparse Attention (PISA) представляет собой новый подход к разреженному вниманию, не требующий обучения и позволяющий ускорить работу DiT (Diffusion Transformers) без потери точности. В отличие от традиционных методов разреженного внимания, требующих предварительного обучения для определения оптимальных паттернов разреженности, PISA использует детерминированные правила для выбора блоков внимания, что исключает необходимость в дополнительном обучении. Это достигается за счет разделения матрицы внимания на блоки и применения разреженных вычислений только к этим блокам, что значительно снижает вычислительную сложность и требования к памяти, сохраняя при этом качество генерируемого контента. PISA позволяет добиться существенного ускорения обработки данных по сравнению с другими методами, такими как FlashAttention, при сохранении или даже улучшении результатов.
Метод PISA использует разложения Тейлора — в частности, разложение нулевого и первого порядка — для аппроксимации полной матрицы внимания, что позволяет существенно снизить вычислительные затраты. Разложение нулевого порядка представляет собой простейшую аппроксимацию, где матрица внимания заменяется на константу. Разложение первого порядка добавляет линейный член, учитывающий изменение матрицы внимания в окрестности определенной точки. Использование этих аппроксимаций позволяет избежать вычисления полной матрицы внимания Attention(Q, K, V) = softmax(QK^T)V, значительно ускоряя процесс вычислений без существенной потери точности, поскольку разложения Тейлора обеспечивают локальную точность аппроксимации.
Метод PISA использует стратегию ‘Выбора блоков с учетом ковариации’ (Covariance-Aware Block Selection) для минимизации ошибок аппроксимации при использовании разреженного внимания. Данный подход заключается в анализе ковариации между элементами матрицы внимания и, на основе этого анализа, в выборе блоков, наиболее важных для сохранения информативности и качества генерируемого контента. Выбор блоков, основанный на ковариации, позволяет PISA более эффективно приближать полную матрицу внимания, снижая потери информации и поддерживая высокую точность модели, в отличие от случайного или фиксированного выбора блоков. Это особенно важно для задач, требующих высокой степени детализации и сохранения семантической целостности выходных данных.
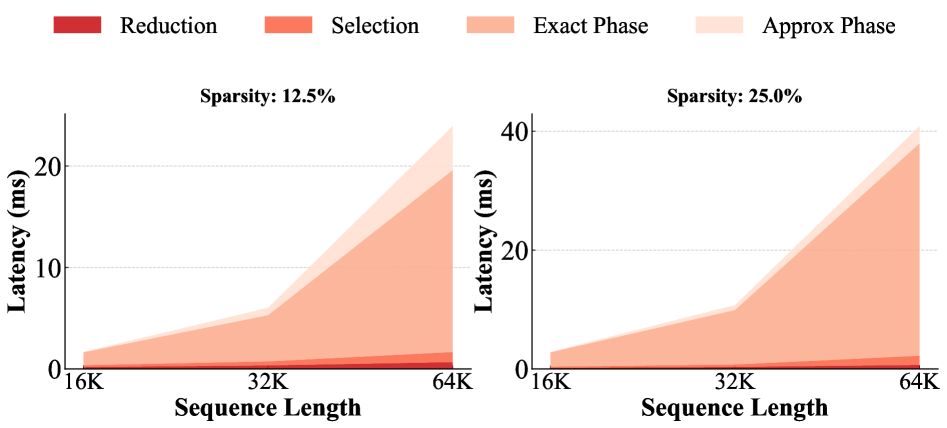
В ходе экспериментов, предложенный метод PISA продемонстрировал превосходство над алгоритмом FlashAttention по скорости вычислений. На модели Wan2.1-14B зафиксировано ускорение в 1.91 раза, а на Hunyuan-Video — 2.57 раза. Данные результаты подтверждают эффективность PISA как альтернативного подхода к разреженному вниманию, позволяющего добиться значительного прироста производительности без потери точности.
Оценка PISA: Результаты на стандартных эталонных наборах данных
Для всесторонней оценки возможностей PISA проводилось тестирование на общепринятых эталонных наборах данных, включая ‘FLUX.1-dev’. Особое внимание уделялось измерению качества генерируемого видео и его временной согласованности, для чего использовался инструмент ‘VBench’. Данный подход позволил получить объективные показатели производительности, подтверждающие способность PISA создавать видеоматериалы высокого качества с сохранением плавности и реалистичности движения. Результаты, полученные на этих наборах данных, служат надежным подтверждением эффективности и надежности PISA в задачах генерации видеоконтента.
Исследования с использованием диффузионного трансформатора ‘Wan2.1-14B’ показали, что PISA обеспечивает значительное ускорение генеративных процессов без существенной потери качества изображений и видео. Данная архитектура позволяет добиться существенного прироста производительности, сохраняя при этом высокую степень детализации и визуальной согласованности генерируемого контента. Полученные результаты демонстрируют, что PISA представляет собой перспективное решение для ускорения широкого спектра задач генерации, открывая новые возможности для разработки более эффективных диффузионных моделей и снижения вычислительных затрат.
Исследования показали, что PISA демонстрирует передовые результаты в тесте VBench, что подтверждает его высокую эффективность в задачах генерации видео. Особенно примечательно, что эта производительность достигается при сохранении уровня разреженности в 87.5%, что значительно снижает вычислительные затраты и требования к памяти. Данный показатель разреженности указывает на способность PISA эффективно использовать ресурсы, не жертвуя качеством генерируемых видеоматериалов. Полученные результаты свидетельствуют о потенциале PISA для создания более быстрых и экономичных моделей диффузии, способных решать широкий спектр задач в области генеративного искусственного интеллекта.
Полученные результаты демонстрируют значительный потенциал PISA в ускорении широкого спектра задач генерации контента. Исследования показывают, что данная технология способна не только повысить скорость работы существующих генеративных моделей, но и стать основой для создания принципиально новых, более эффективных диффузионных моделей. Особенно важно, что PISA позволяет добиться значительного ускорения без существенной потери качества генерируемого контента, открывая возможности для более оперативной обработки и создания визуальных материалов в различных областях — от искусства и дизайна до научных исследований и разработки новых технологий. Это делает PISA перспективным инструментом для дальнейших разработок в области искусственного интеллекта и машинного обучения.

Будущие направления: Расширение возможностей PISA
Исследования показывают, что адаптивное изменение порядка разложения в ряде Тейлора может значительно повысить точность и эффективность PISA. Вместо использования фиксированного порядка приближения, предлагается динамически подстраивать его в зависимости от характеристик входных данных. Такой подход позволяет более эффективно аппроксимировать сложные функции, используя меньше вычислительных ресурсов для областей с низкой чувствительностью и увеличивая порядок разложения в областях, где требуется большая точность. В результате, достигается оптимальный баланс между скоростью вычислений и качеством приближения, что особенно важно при работе с большими объемами данных и сложными моделями. Перспективные исследования в этой области направлены на разработку алгоритмов, автоматически определяющих оптимальный порядок разложения для каждого конкретного случая, тем самым максимизируя потенциал PISA.
Исследование применимости PISA к архитектурам моделей, отличным от диффузионных трансформаторов, в частности, к большим языковым моделям, представляет собой перспективное направление развития. В то время как PISA продемонстрировала свою эффективность в оптимизации диффузионных моделей, потенциал её адаптации к другим типам нейронных сетей огромен. Большие языковые модели, характеризующиеся значительно большим количеством параметров и сложной структурой, могут получить существенную выгоду от применения PISA для снижения вычислительных затрат и повышения скорости инференса. Успешная интеграция PISA с этими моделями позволит не только ускорить процесс обучения, но и сделать развертывание масштабных языковых моделей более доступным и эффективным, открывая новые возможности для обработки естественного языка и создания интеллектуальных систем.
Исследования показывают, что объединение PISA с другими методами разрежения может привести к значительному повышению эффективности. Вместо того чтобы полагаться на единственный подход к разрежению, гибридные стратегии, комбинирующие преимущества различных техник, позволяют более гибко адаптироваться к особенностям конкретных моделей и данных. Например, сочетание PISA с техниками, основанными на величине весов, или с методами, использующими структурное разрежение, может обеспечить более точное и эффективное сокращение числа параметров без существенной потери производительности. Такой подход позволяет не только уменьшить вычислительную нагрузку и потребление памяти, но и повысить обобщающую способность модели, что особенно важно при работе с ограниченными объемами данных или сложными задачами машинного обучения.
Исследование, представленное в статье, демонстрирует, как подход к разреженному вниманию может значительно ускорить генерацию изображений и видео. Авторы предлагают механизм PISA, который сочетает точные вычисления с эффективной кусочной аппроксимацией, используя разложение в ряд Тейлора. Это позволяет добиться существенного прироста скорости без потери качества. Как заметил Эндрю Ын: «Мы должны стремиться создавать системы, которые не просто работают, но и понятны.» Этот принцип находит отражение в PISA, где упрощение вычислений достигается за счет логичного и прозрачного использования математических инструментов, что делает процесс генерации более управляемым и интерпретируемым.
Что дальше?
Представленный подход к разреженному вниманию, обозначенный как PISA, демонстрирует многообещающие результаты в ускорении диффузионных трансформаторов. Однако, закономерности, выявленные через приближение с использованием разложения в ряд Тейлора, требуют дальнейшего, критического осмысления. Важно тщательно исследовать границы применимости данного приближения, чтобы избежать ложных корреляций и гарантировать стабильность генерации изображений и видео при различных параметрах. Очевидно, что простое увеличение скорости не является самоцелью; необходимо понять, как приближение влияет на качество генерируемого контента и не вносит ли оно нежелательных артефактов.
Перспективным направлением представляется исследование адаптивных схем разреженности, где структура разреженного внимания динамически меняется в зависимости от входных данных. Это может позволить более эффективно использовать вычислительные ресурсы и повысить качество генерации. Кроме того, интересно рассмотреть возможность комбинирования PISA с другими методами разреженного внимания, чтобы создать гибридные системы, использующие преимущества каждого подхода. Необходимо помнить, что упрощение вычислений — это лишь один из аспектов; понимание внутренней логики системы и её способности к обобщению является ключевым.
В конечном счете, успех данного направления исследований будет зависеть от способности выйти за рамки простых оптимизаций и углубиться в фундаментальные принципы, управляющие процессами внимания и генерации. Наблюдаемые улучшения в скорости — это лишь симптомы; необходимо понять, что скрывается за этой видимостью эффективности, и как это знание можно использовать для создания более интеллектуальных и гибких систем.
Оригинал статьи: https://arxiv.org/pdf/2602.01077.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Взлом языковых моделей: эволюция атак, а не подсказок
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Квантовый оптимизатор: Новый подход к сложным задачам
- Эволюция Симуляций: От Агентов к Сложным Социальным Системам
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Роботы учатся видеть: новая стратегия управления на основе видео
- Молекулярный конструктор: Искусственный интеллект на службе создания лекарств
- Диффузия против Квантов: Новый Взгляд на Факторизацию
2026-02-03 20:58