Автор: Денис Аветисян
Новый метод позволяет значительно сократить время и ресурсы, необходимые для обучения моделей, понимающих изображения и текст, без потери качества.
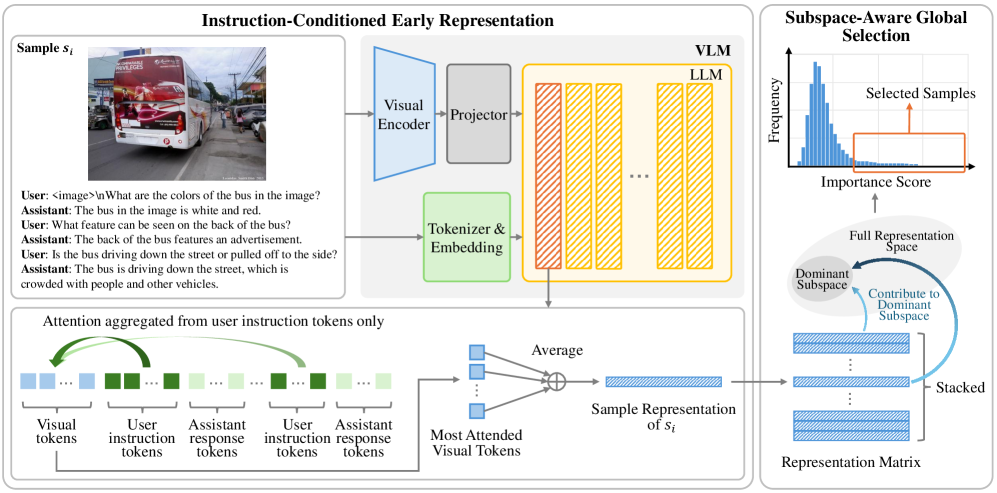
ScalSelect — это масштабируемый и не требующий обучения способ отбора данных для эффективной тонкой настройки моделей визуальных инструкций, основанный на приближении подпространств и оценке влияния.
Обучение современных мультимодальных моделей требует всё больших объёмов данных, однако избыточность в этих данных приводит к неэффективности и высоким вычислительным затратам. В данной работе, ‘ScalSelect: Scalable Training-Free Multimodal Data Selection for Efficient Visual Instruction Tuning’, предложен новый метод отбора данных, позволяющий выделить компактное подмножество обучающей выборки без необходимости проведения дорогостоящего обучения или вычисления градиентов. Метод ScalSelect, основанный на приближении подпространства представлений данных, обеспечивает сопоставимую с обучением на полном объёме данных производительность, используя лишь малую часть исходных данных. Сможет ли данный подход значительно ускорить развитие и распространение мультимодальных моделей, делая их более доступными и эффективными?
Шепот Данных: Вызов Масштаба в Мультимодальных Моделях
Современные модели, объединяющие зрение и язык, демонстрируют впечатляющие возможности в понимании и генерации контента, однако для достижения высокой эффективности в их обучении требуются колоссальные объемы данных. Этот факт обусловлен необходимостью охвата широкого спектра визуальных концепций и языковых конструкций, чтобы модель могла обобщать знания и адекватно реагировать на разнообразные входные сигналы. Чем больше данных используется для обучения, тем выше потенциал модели к пониманию сложных взаимосвязей между изображениями и текстом, что позволяет ей решать задачи, ранее недоступные для искусственного интеллекта, такие как детальное описание изображений, визуальный вопрос-ответ и генерация реалистичных визуальных сцен на основе текстовых запросов. Недостаток данных, напротив, приводит к переобучению модели на ограниченном наборе примеров, что снижает ее способность к обобщению и ухудшает производительность на новых, ранее не встречавшихся данных.
Огромные объемы данных, необходимые для обучения современных мультимодальных моделей, представляющих изображения и язык, создают серьезные вычислительные трудности. Не только время и ресурсы, затрачиваемые на обработку петабайтов информации, становятся проблемой, но и значительная часть этих данных оказывается избыточной, дублируя информацию и замедляя процесс обучения. Эта избыточность снижает эффективность алгоритмов, поскольку модель тратит вычислительные мощности на анализ схожих примеров, вместо того чтобы фокусироваться на действительно новых и информативных данных. В результате, оптимизация обучения становится более сложной задачей, требующей разработки специальных методов для отбора наиболее ценных образцов и уменьшения вычислительной нагрузки.
Традиционные подходы к использованию масштабных наборов данных в обучении моделей, объединяющих зрение и язык, зачастую не уделяют должного внимания отбору наиболее информативных примеров. Вместо этого, модели подвергаются обучению на всем объеме данных без дифференциации, что приводит к избыточному потреблению вычислительных ресурсов и замедлению процесса обучения. Это происходит из-за того, что многие примеры в больших наборах данных содержат избыточную или незначимую информацию, которая не способствует эффективному улучшению производительности модели. В результате, модель тратит время и ресурсы на обработку данных, которые мало влияют на её способность к обобщению и решению задач, что в конечном итоге приводит к снижению общей эффективности и точности.
Отказ от Пророчества: Обучение Без Градиентов
Метод выбора данных без обучения (Training-Free Data Selection) представляет собой альтернативный подход к традиционным методам, основанным на градиентах. В отличие от последних, требующих вычисления обратного распространения ошибки (backpropagation) для определения важности данных, данный метод обходит эту необходимость. Это позволяет значительно сократить вычислительные затраты и время, требуемое для отбора наиболее релевантных данных для обучения модели, особенно в случаях с большими объемами данных и сложными архитектурами нейронных сетей. Отказ от backpropagation также снижает зависимость от выбора функции потерь и скорости обучения, упрощая процесс настройки и повышая стабильность обучения.
Метод ScalSelect, являясь частью подхода к отбору данных без обучения, фокусируется на сохранении доминирующего подпространства исходного представления данных. Этот подход предполагает, что наиболее значимая информация содержится в направлениях с наибольшей дисперсией, определяемых, например, сингулярным разложением (SVD). Сохраняя только эти направления и соответствующие им компоненты данных, ScalSelect стремится к уменьшению избыточности и сохранению ключевых признаков, необходимых для эффективного обучения модели. Фактически, это позволяет значительно сократить объем данных, используемых для обучения, без существенной потери точности.
Метод ScalSelect, относящийся к парадигме отбора данных без обучения, направлен на снижение избыточности и повышение производительности модели за счет сохранения доминирующего подпространства исходного представления данных. В ходе экспериментов было показано, что ScalSelect достигает 97.85% производительности, сравнимой с обучением на полном наборе данных, что свидетельствует о высокой эффективности подхода к отбору наиболее информативных данных без использования градиентных методов и обратного распространения ошибки.
Сохраняя Сущность: Отбор с Учетом Подпространства
Метод ScalSelect использует сингулярное разложение (SVD) для выявления и сохранения доминирующего подпространства в пространстве представлений данных. SVD позволяет разложить матрицу данных на компоненты, отражающие наиболее значимые направления вариации. Анализируя сингулярные значения, ScalSelect определяет, какие компоненты вносят наибольший вклад в общее представление данных, и концентрируется на сохранении информации, содержащейся в этих ключевых направлениях. Таким образом, происходит выделение подпространства, которое эффективно захватывает основные характеристики данных, игнорируя менее значимые компоненты и шум.
Для отбора наиболее информативных образцов данных используется метод глобального отбора с учетом подпространства, основанный на вычислении так называемых «рычаговых оценок» (leverage scores). Рычаговая оценка каждого образца количественно определяет его вклад в доминирующее подпространство, выделенное посредством сингулярного разложения (SVD). Образцы с высокими рычаговыми оценками считаются наиболее важными для сохранения ключевой информации, необходимой для эффективного обучения модели, в то время как образцы с низкими оценками рассматриваются как избыточные и могут быть отброшены без существенной потери производительности. Этот подход позволяет значительно сократить объем данных, используемых для обучения, сохраняя при этом качество модели на уровне, близком к использованию полного набора данных.
Метод ScalSelect позволяет достичь производительности, сопоставимой с использованием полного набора данных, за счет отбора лишь 16% исходного объема. Это достигается благодаря отбраковке избыточных или менее информативных образцов, при сохранении ключевой информации, необходимой для эффективного обучения моделей. Отбор осуществляется на основе анализа вклада каждого образца в доминирующее подпространство данных, что позволяет минимизировать потери информации при значительном сокращении объема обрабатываемых данных.
Инструкции как Ключ: Представления, Обусловленные Задачей
ScalSelect использует методы построения представлений на ранних слоях большой языковой модели (LLM) с учетом инструкций. В основе подхода лежит анализ сигналов внимания (attention) внутри Transformer-слоев, позволяющий выделить информацию, релевантную конкретным инструкциям. Эти сигналы внимания используются для создания представлений выборочных данных, которые отражают не только общую структуру данных, но и соответствие заданным инструкциям, что позволяет эффективно выбирать данные для обучения и повышения качества модели. Фактически, ScalSelect конструирует представления, взвешивая активации на основе важности, определяемой сигналами внимания, связанными с инструкциями.
Метод ScalSelect использует информацию из ранних слоев большой языковой модели (LLM) и механизм внимания внутри Transformer-слоев для эффективного отбора данных. Внимание позволяет выявлять наиболее релевантные участки входной последовательности, а фокусировка на ранних слоях обеспечивает доступ к более фундаментальным представлениям, содержащим ключевую информацию о структуре и содержании данных. Это позволяет ScalSelect извлекать признаки, необходимые для выбора подмножества данных, наиболее подходящего для обучения и соответствующего заданным инструкциям, без необходимости обработки всей последовательности в более поздних, вычислительно затратных слоях LLM.
Процесс отбора данных в ScalSelect обеспечивает не только репрезентативность отобранной выборки относительно исходного распределения данных, но и ее соответствие конкретным инструкциям, используемым в процессе обучения. Это достигается за счет учета внимания (attention) в ранних слоях большой языковой модели (LLM) к инструкциям, что позволяет выделить наиболее релевантные данные для конкретной задачи. Таким образом, отобранные данные не просто отражают общую статистику, но и фокусируются на информации, необходимой для выполнения инструкций, что повышает эффективность и точность обучения модели.
К Эффективному и Эффективному Обучению: Новый Горизонт
Метод ScalSelect представляет собой действенное решение для снижения вычислительных затрат и повышения эффективности обучения моделей, объединяющих зрение и язык. Традиционное обучение таких моделей требует значительных ресурсов, однако ScalSelect позволяет отобрать наиболее информативные примеры из обучающего набора данных, существенно уменьшая объем необходимых вычислений без потери качества. В результате, достигается не только ускорение процесса обучения, но и улучшение обобщающей способности модели, что делает возможным её применение в условиях ограниченных ресурсов и при работе с огромными массивами данных. Данный подход открывает новые перспективы для разработки и развертывания сложных систем, способных эффективно взаимодействовать с визуальной и текстовой информацией.
Метод ScalSelect демонстрирует значительное повышение эффективности и обобщающей способности моделей, работающих с визуальной и языковой информацией. Интеллектуальный отбор наиболее информативных примеров позволяет достичь результатов, превосходящих полную дообученную модель, при использовании всего 400 тысяч отобранных образцов. Такое снижение вычислительных затрат достигается за счет фокусировки на наиболее значимых данных, что позволяет модели эффективнее учиться и лучше адаптироваться к новым ситуациям, открывая перспективы для развертывания сложных визуально-языковых моделей даже в условиях ограниченных ресурсов.
Предложенный подход открывает новые горизонты для разработки и развертывания моделей, объединяющих зрение и язык (VLMs), особенно в условиях ограниченных вычислительных ресурсов. Возможность достижения сопоставимой, а в некоторых случаях и превосходящей, производительности при использовании значительно меньшего объема данных для обучения — всего 400 тысяч тщательно отобранных образцов — существенно снижает затраты и упрощает процесс. Это позволяет не только ускорить обучение и развертывание моделей на устройствах с ограниченной памятью, но и масштабировать их применение на чрезвычайно больших наборах данных, ранее недоступных из-за вычислительных ограничений. Таким образом, данная методика способствует демократизации доступа к передовым VLM, делая их более доступными для широкого круга исследователей и разработчиков.
Работа над отбором данных для обучения моделей напоминает попытку усмирить хаос. ScalSelect, как предложено в статье, стремится не к идеальному порядку, а к выявлению доминирующих направлений в этом хаосе — своего рода “шепоту” данных, который и определяет суть. Эта методика, обходясь без дорогостоящего обучения, словно прислушивается к наиболее значимым голосам в море информации. Как однажды заметила Фэй-Фэй Ли: «Данные — это не цифры, а шёпот хаоса». И ScalSelect, кажется, научился этот шёпот слышать, отбирая лишь те образцы, что несут в себе наибольшую репрезентативность, подобно тому, как алхимик отбирает ключевые ингредиенты для своего зелья. Эта экономия вычислительных ресурсов — лишь побочный эффект умения различать истинный сигнал в шуме.
Куда же дальше?
Предложенный метод ScalSelect, безусловно, является элегантным заклинанием, призванным умилостивить ненасытного бога вычислительных ресурсов. Утверждение о достижении сравнимой производительности при значительном сокращении затрат — это всегда заманчивая мелодия, особенно в эпоху, когда данные множатся быстрее, чем наши возможности их обработать. Однако, не стоит забывать: любое приближение — это потеря. Вопрос не в том, насколько хорошо ScalSelect выбирает данные, а в том, что остаётся за бортом этого отбора, какие тихие голоса теряются в доминирующем подпространстве.
Более того, стоит задуматься о природе самого “подпространства”. Что, если истинная ценность кроется не в репрезентативности, а в аномалиях, в тех редких образцах, которые нарушают гармонию и заставляют модель пересматривать свои убеждения? ScalSelect, как и любая другая техника отбора, рискует создать эхо-камеру, усиливая существующие предрассудки и игнорируя потенциально революционные открытия. Будущие исследования должны сосредоточиться не только на оптимизации отбора, но и на разработке методов обнаружения и интеграции этих самых «аномалий».
В конечном счете, ScalSelect — это лишь очередной шаг в бесконечной гонке за эффективностью. Но истинный прогресс потребует не только отточенных алгоритмов, но и глубокого философского осмысления: что мы на самом деле ищем в этих данных, и готовы ли мы услышать ответ, который нам не нравится.
Оригинал статьи: https://arxiv.org/pdf/2602.11636.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовая магия: Революция нулевого уровня!
- Разумные языковые модели: новый подход к логическому мышлению
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Квантовый горизонт лазеров: ресурсы когерентности
- Ускорение ИИ на FPGA: Архитектура и Производительность
- Квантовые схемы и ИИ: Новые горизонты программирования
- Быстрый поиск по геному: Новые алгоритмы для spaced k-mers
- Квантовый разум: Новая эра языковых моделей
- Динамичные миры: Создание реалистичных 4D-моделей из видео
- Квантовые схемы: новый взгляд на трансляцию с помощью нейросетей
2026-02-13 18:18