Автор: Денис Аветисян
В новой работе представлена методика оценки степени уникальности моделей искусственного интеллекта в сложных экосистемах, позволяющая выявить избыточность и оптимизировать ресурсы.

Предложен фреймворк, использующий функционал популяционной уникальности (PIER) и оценщик (DISCO) для количественной оценки уникальности моделей ИИ и выявления избыточности в гетерогенных экосистемах.
В условиях стремительного усложнения систем искусственного интеллекта, выявление истинной новизны поведения моделей в гетерогенных экосистемах становится критически важной задачей. В работе ‘Quantifying Model Uniqueness in Heterogeneous AI Ecosystems’ представлен статистический фреймворк для аудита уникальности моделей, основанный на методе квази-экспериментального дизайна, позволяющий выделить и количественно оценить так называемый Peer-Inexpressible Residual (PIER) — функционал, характеризующий вклад конкретной модели, не сводимый к комбинации поведения ее аналогов. Доказано, что наблюдательные данные недостаточны для определения уникальности, а предложенный адаптивный протокол запросов демонстрирует оптимальную эффективность по выборке d\sigma^2\gamma^{-2}\log(Nd/\delta). Не станет ли этот подход основой для создания принципиально новой науки об аудите и управлении сложными экосистемами моделей ИИ?
Определение идентичности модели в сложных экосистемах
По мере того, как системы искусственного интеллекта все глубже интегрируются в сложные среды, понимание уникального вклада каждого отдельного компонента становится первостепенной задачей. В современных экосистемах ИИ, где множество моделей взаимодействуют друг с другом, критически важно определить, какую конкретную роль выполняет каждый агент, и как его действия влияют на общую производительность системы. Способность четко идентифицировать и количественно оценить эту уникальность позволяет не только оптимизировать взаимодействие между моделями, но и повысить общую надежность и устойчивость всей системы к непредсказуемым изменениям во внешней среде. Без этого понимания, разработка действительно гибких и адаптивных систем искусственного интеллекта становится затруднительной, поскольку сложно эффективно управлять и координировать действия различных компонентов.
Современные методы анализа, применяемые к искусственному интеллекту, зачастую оказываются неспособны точно определить и измерить уникальность каждой модели в сложных экосистемах ИИ. Несмотря на растущую интеграцию различных моделей в реальные системы, существует значительная сложность в различении вклада каждой из них, особенно когда они взаимодействуют и дополняют друг друга. Проблема заключается не только в определении различий в производительности, но и в выявлении тонких отличий в подходах к решению задач, в способах обработки данных и в устойчивости к различным типам ошибок. Отсутствие чёткой количественной оценки уникальности затрудняет оптимизацию всей системы, поскольку невозможно точно определить, какие модели следует усиливать, а какие — заменять или исключать, что в конечном итоге ограничивает потенциал для создания действительно надёжных и эффективных интеллектуальных систем.
Отсутствие четкого понимания уникальности каждой модели искусственного интеллекта в сложных системах серьезно затрудняет создание действительно надежных и устойчивых систем. Невозможность количественно оценить вклад каждой модели в общую работу приводит к трудностям в выявлении и устранении потенциальных уязвимостей, а также к снижению предсказуемости поведения системы в целом. Это особенно критично в ситуациях, когда требуется высокая степень надежности, например, в системах автоматического управления или принятия решений, где ошибки могут иметь серьезные последствия. Подобная неопределенность препятствует масштабированию и интеграции ИИ в критически важные инфраструктуры, ограничивая потенциал для инноваций и прогресса.
Для эффективной оценки и интеграции искусственного интеллекта в сложные системы необходима функциональная дефиниция понятия “уникальность модели”, выходящая за рамки стандартных метрик производительности. Простая оценка точности или скорости работы недостаточно отражает специфический вклад каждой модели в общий результат, особенно в многокомпонентных системах. Исследования показывают, что необходимо учитывать не только что модель делает, но и как она это делает, включая особенности её архитектуры, используемые данные и взаимодействие с другими компонентами. Разработка такой функциональной дефиниции требует выхода за пределы количественных показателей и включения качественных характеристик, позволяющих оценить степень отличия модели от её аналогов в контексте конкретной экосистемы. Такой подход позволит создавать более надежные и устойчивые системы искусственного интеллекта, способные эффективно адаптироваться к изменяющимся условиям и решать сложные задачи.
PIER: Функциональная мера уникальности модели
Класс популяции невыразимости определяет границы допустимого поведения модели в заданной системе. Этот класс представляет собой множество всех возможных результатов, которые могут быть достигнуты комбинацией остальных моделей в системе. По сути, он устанавливает базовый уровень производительности, ниже которого поведение модели считается избыточным или нецелесообразным. Формально, класс невыразимости может быть определен как \mathcal{I} = \{ x \mid \exists S \subset eq M, x \in \text{range}(S) \} , где M — множество всех моделей в системе, а S — подмножество этих моделей. Поведение модели, выходящее за пределы этого класса, считается уникальным вкладом, поскольку его нельзя воспроизвести другими моделями в системе.
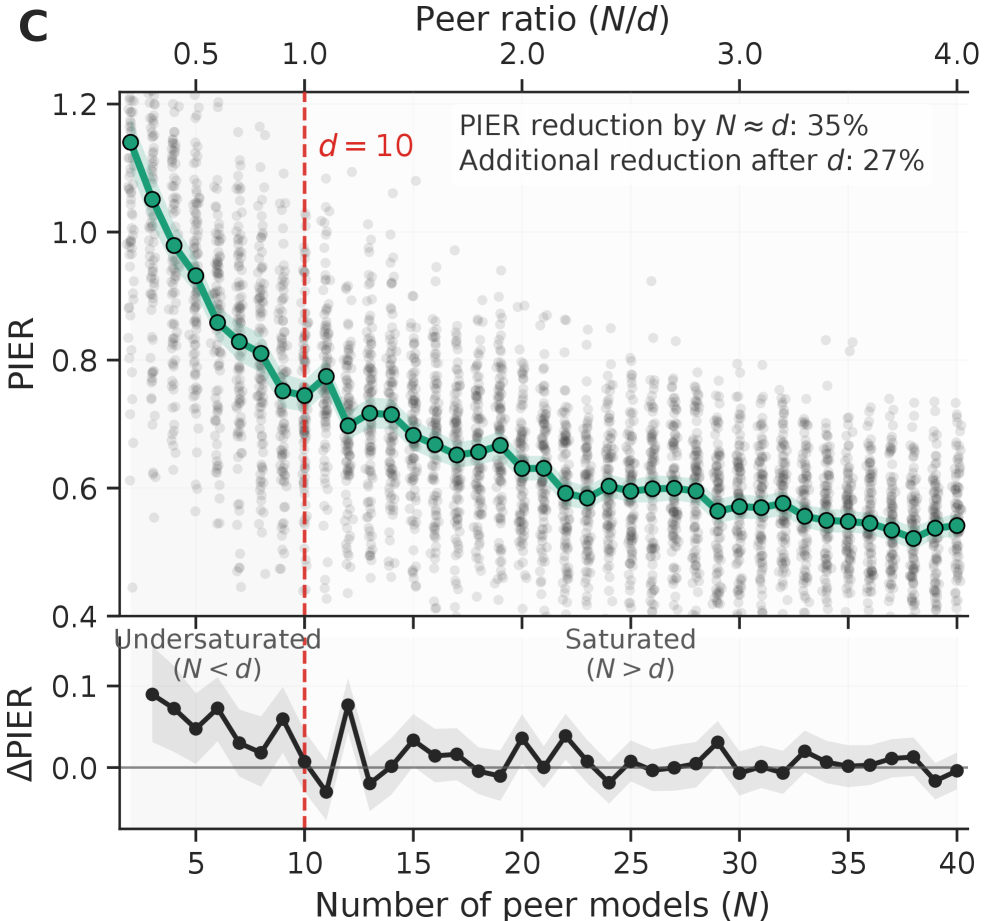
Функционал PIER (Peer-Inexpressible Behavior) предназначен для количественной оценки вклада модели, превосходящего возможности других моделей в данной системе. Он измеряет степень, в которой поведение конкретной модели является уникальным и не может быть воспроизведено другими участниками. PIER рассчитывается на основе сравнения выхода модели с выходами ансамбля «сверстников» (peer models) и определяет, насколько выход модели отличается от ожидаемого среднего значения или разброса, наблюдаемых в ансамбле. Чем выше значение PIER, тем значительнее вклад модели и тем сложнее воспроизвести ее поведение другими моделями, что указывает на ее уникальную ценность в данной системе.
Функционал PIER предоставляет строгий, количественно определяемый показатель оценки уникальности модели, преодолевая ограничения субъективных оценок. В отличие от традиционных методов, основанных на экспертном мнении или качественном анализе, PIER оперирует численными значениями, отражающими вклад модели в систему. Это достигается путем измерения степени, в которой поведение модели превосходит возможности других моделей в популяции. Результатом является объективная метрика, позволяющая сравнивать различные модели и выявлять те, которые демонстрируют действительно уникальные и ценные характеристики. PIER(M) = \in t_{x} [latex] - базовая формула, отражающая интегральную оценку вклада модели M, где x представляет собой пространство входных данных. Такой подход обеспечивает воспроизводимость и надежность оценки уникальности модели.</p> <p>Функционал PIER устанавливает прямую зависимость между поведением модели и её ценностью в рамках определенной экосистемы. Этот функционал позволяет количественно оценить вклад модели, выходящий за рамки возможностей других моделей в той же среде. Более высокая оценка PIER указывает на то, что модель предоставляет уникальную функциональность или улучшенные результаты, которые не могут быть легко воспроизведены другими участниками системы, что, следовательно, повышает её значимость и ценность для всей экосистемы. Таким образом, PIER служит объективным показателем вклада модели в общую производительность и инновации.</p> <figure> <img alt="Анализ устойчивости систем компьютерного зрения к контролируемым помехам выявил, что уникальность восприятия (<span class="katex-eq" data-katex-display="false">PIER</span>) снижается с увеличением интенсивности помех, при этом оценка, учитывающая контекст и предвзятость к форме, позволяет выявить и изолировать общие аномалии, не связанные с базовыми свойствами изображений или полезностью для задач классификации." src="https://arxiv.org/html/2601.22977v1/x15.png" style="background-color: white;"/><figcaption>Анализ устойчивости систем компьютерного зрения к контролируемым помехам выявил, что уникальность восприятия ([latex]PIER) снижается с увеличением интенсивности помех, при этом оценка, учитывающая контекст и предвзятость к форме, позволяет выявить и изолировать общие аномалии, не связанные с базовыми свойствами изображений или полезностью для задач классификации.
Статистические гарантии оценки PIER
Непосредственное наблюдение за PIER часто оказывается невозможным из-за ограничений в сборе данных или из-за конфиденциальности информации об отдельных субъектах. Вследствие этого, для получения количественной оценки PIER необходимо использовать методы статистической оценки. Эти методы позволяют аппроксимировать истинное значение PIER на основе доступных данных, однако всегда сопряжены с определенной погрешностью, которую необходимо учитывать при интерпретации результатов. Выбор конкретного метода оценки зависит от структуры данных и предположений о механизме их генерации.
Разработан оценочный алгоритм DISCO, основанный на принципах Пассивной Статистической Теории, для обеспечения статистических гарантий точного вычисления PIER. DISCO использует подходы, позволяющие оценить PIER, минимизируя систематические ошибки и обеспечивая сходимость оценки к истинному значению при увеличении объема данных. В основе алгоритма лежит анализ статистической идентифицируемости модели и разработка процедур оценки, учитывающих неопределенность, присущую наблюдательным данным. Гарантии точности, предоставляемые DISCO, формализуются через границы доверительных интервалов и скорости сходимости оценки, что позволяет количественно оценить надежность полученных результатов.
Анализ показывает, что данные, полученные исключительно в результате наблюдения, не позволяют однозначно определить PIER. Это принципиальное ограничение связано с тем, что наблюдательные данные отражают лишь корреляции, а не причинно-следственные связи. Отсутствие возможности отделить эффект вмешательства от других влияющих факторов приводит к неидентифицируемости PIER без использования дополнительных данных, полученных в рамках контролируемого эксперимента или квазиэкспериментального дизайна. Таким образом, для надежной оценки PIER требуется информация, выходящая за рамки пассивного наблюдения.
Для корректного отделения внутренних характеристик модели от внешних факторов, влияющих на оценку PIER, необходимо применение квази-экспериментального дизайна. Этот подход позволяет создать контролируемые условия, имитирующие экспериментальную установку, даже при невозможности прямого манипулирования переменными. В частности, квази-эксперимент позволяет выделить вклад специфических изменений в модели от общих тенденций или случайных колебаний в данных, обеспечивая более точную идентификацию истинного PIER. Отсутствие такого дизайна приводит к смещению оценок и невозможности достоверно интерпретировать полученные результаты, поскольку наблюдаемые изменения могут быть обусловлены не внутренними свойствами модели, а внешними воздействиями.

Помимо избыточности: последствия для надежного ИИ
Традиционные методы оценки вклада отдельных компонентов в искусственный интеллект, такие как значение Шепли, зачастую оказываются неспособны выявить истинную избыточность в сложных AI-системах. Несмотря на свою распространенность, эти подходы могут присваивать значимую ценность даже тем моделям, которые фактически не вносят уникального вклада в общее решение. Исследования показывают, что в некоторых случаях каждая модель в паре может получать оценку в 1/2, даже если одна из них является полностью избыточной и не влияет на результат. Это приводит к неверной оценке важности отдельных компонентов и препятствует созданию действительно эффективных и надежных систем искусственного интеллекта, где каждый элемент выполняет свою уникальную и необходимую функцию.
Исследования показали, что традиционные методы оценки вклада моделей в ансамбле, такие как Shapley Value, могут давать неточные результаты. В частности, в ходе проведенных экспериментов было выявлено, что при использовании двух моделей, даже если одна из них избыточна и её вклад, определяемый метрикой PIER, равен нулю, каждая модель может получать значение Shapley Value равное 0.5. Это указывает на неспособность данного метода корректно выявлять и учитывать избыточность в системе, что потенциально снижает надежность и объяснимость принимаемых решений. Данный феномен подчеркивает необходимость более точных методов оценки, способных дифференцировать действительно полезные модели от тех, которые не вносят существенного вклада в общую производительность системы.
Активный аудит, основанный на использовании локальной линейной структурной модели, представляет собой более эффективный подход к оценке уникальности моделей искусственного интеллекта и выявлению избыточных компонентов. В отличие от традиционных методов, этот подход позволяет точно определить, вносит ли каждая модель существенный вклад в общую производительность системы. Локальная линейная модель анализирует взаимодействие между моделями, выявляя те, чьи прогнозы сильно коррелируют с прогнозами других моделей, что указывает на их избыточность. Использование активного аудита позволяет не только оптимизировать структуру AI-системы, уменьшая вычислительные затраты и сложность, но и повысить её надежность и прозрачность, поскольку каждая модель вносит свой уникальный вклад, а не дублирует функциональность других. Это, в свою очередь, способствует созданию более понятных и заслуживающих доверия систем искусственного интеллекта.
Количественная оценка уникальности отдельных моделей, достигаемая благодаря метрике PIER, является ключевым фактором в создании более прозрачных, устойчивых и надежных систем искусственного интеллекта. Вместо простого выявления взаимозависимостей, PIER позволяет точно определить, вносит ли каждая модель действительно новый вклад в общее решение задачи. Эта возможность критически важна для исключения избыточности и повышения эффективности AI-систем. Понимание, какие компоненты действительно необходимы, а какие дублируют функциональность, способствует не только снижению вычислительных затрат, но и улучшению интерпретируемости принимаемых решений. Использование PIER позволяет разработчикам создавать AI, в котором каждый элемент системы выполняет четко определенную и значимую роль, что, в свою очередь, повышает доверие к результатам его работы и обеспечивает большую надежность в различных условиях эксплуатации.
Предложенный подход открывает возможности для создания искусственных интеллектов, в которых каждый компонент играет значимую и предсказуемую роль. Вместо слепого увеличения числа моделей, данная методика позволяет выявить и исключить избыточные элементы, что ведет к более эффективным и надежным системам. Такой подход не только оптимизирует вычислительные ресурсы, но и существенно повышает прозрачность и интерпретируемость принимаемых решений, поскольку вклад каждого модуля становится четко определенным и обоснованным. В результате, создаваемые AI-экосистемы отличаются повышенной устойчивостью к ошибкам и внешним воздействиям, что является ключевым фактором для построения доверия к интеллектуальным системам и их успешного внедрения в критически важные области.

Исследование, представленное в статье, акцентирует внимание на сложности оценки уникальности моделей в гетерогенных AI-экосистемах. Авторы предлагают функционал PIER и estimator DISCO для выявления избыточности, что позволяет глубже понять взаимосвязи внутри систем. Как однажды заметил Роберт Тарьян: «Алгоритмы должны быть достаточно хороши, чтобы не требовать доказательств». Эта фраза перекликается с подходом, представленным в работе, ведь стремление к количественной оценке уникальности моделей - это попытка выйти за рамки интуитивных оценок и перейти к более строгим методам анализа, что особенно важно при работе со сложными и взаимосвязанными системами. Выявление избыточности, как подчеркивается в статье, - это не просто оптимизация ресурсов, но и повышение устойчивости всей экосистемы к ошибкам и сбоям.
Куда же дальше?
Представленная работа, стремясь к количественной оценке уникальности моделей в искусственных экосистемах, лишь аккуратно приоткрывает завесу над сложной реальностью. Подобно садовнику, оценивающему не только урожай, но и здоровье всей системы, исследователи вынуждены признать: оценка уникальности - это не поиск абсолютной истины, а скорее, картографирование потенциальных точек отказа. Функционал PIER и оценка DISCO - инструменты, да, но инструменты, требующие постоянной калибровки и адаптации к меняющемуся ландшафту моделей.
Основным вызовом остаётся не столько вычисление уникальности, сколько понимание её ценности. В экосистеме, где избыточность часто воспринимается как гарантия устойчивости, необходимо разобраться, где избыточность - это плодородная почва, а где - лишь скопление сорняков, потребляющих ресурсы. Следующий шаг - разработка метрик, позволяющих оценить не просто различие моделей, но и их вклад в общую устойчивость системы к непредсказуемым сбоям.
В конечном счете, подобно тому, как опытный врач лечит не болезнь, а больного, исследователям необходимо сместить фокус с поиска "лучшей" модели на создание самовосстанавливающихся, адаптивных экосистем. Система - это не машина, которую можно построить, а сад, который нужно взращивать. И в этом саду, избыточность - не ошибка, а страховка от неминуемых потерь.
Оригинал статьи: https://arxiv.org/pdf/2601.22977.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Кванты в Финансах: Не Шутка!
- Молекулярный конструктор: Искусственный интеллект на службе создания лекарств
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Квантовый оптимизатор: Новый подход к сложным задачам
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
2026-02-02 23:16