Автор: Денис Аветисян
Новая модель объединяет возможности авторегрессии и диффузии для комплексного анализа и генерации изображений грудной клетки.
Представлена унифицированная медицинская базовая модель с двухканальной архитектурой и механизмом кросс-модального внимания для повышения эффективности понимания и генерации медицинских изображений.
Несмотря на значительный прогресс в области медицинских фундаментальных моделей, объединение задач визуального понимания и генерации изображений остается сложной проблемой из-за противоречивых целей: семантической абстракции и пиксельной реконструкции. В данной работе представлена модель ‘UniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation’, использующая инновационную архитектуру с разделением задач на авторегрессивную ветвь для понимания и диффузионную ветвь для высокоточной генерации, объединенные механизмом кросс-модального внимания. Это позволяет добиться синергии между задачами и превзойти существующие подходы, достигнув улучшения на 46.1% в понимании и на 24.2% в качестве генерации при значительно меньшем количестве параметров. Может ли подобный подход стать основой для создания масштабируемых и эффективных систем поддержки принятия решений в медицинской диагностике и лечении?
Вызов Мультимодального Медицинского Рассуждения
Современные системы автоматической генерации медицинских заключений по изображениям зачастую демонстрируют недостаток глубокого понимания визуальной информации и не обеспечивают точного соответствия между изображением и текстом отчета. Это проявляется в неспособности выявить тонкие, но клинически значимые детали на снимках, что приводит к неполным или неточным описаниям. Несмотря на прогресс в области искусственного интеллекта, существующие модели испытывают трудности с интерпретацией сложных визуальных паттернов и их корректным переводом в связный и медицински обоснованный текст. В результате, генерируемые отчеты могут содержать обобщенные формулировки или упускать важные нюансы, что снижает их ценность для врачей и потенциально влияет на качество диагностики.
Существующие методы автоматической генерации медицинских заключений зачастую сталкиваются с трудностями при интерпретации визуальных данных и их преобразовании в связный, научно обоснованный текст. Сложность заключается не только в распознавании отдельных элементов на изображениях, но и в установлении корректных взаимосвязей между ними, а также в формулировании выводов, соответствующих медицинским стандартам. Многие алгоритмы демонстрируют ограниченную способность к пониманию контекста и нюансов, что приводит к неточностям и неполноте генерируемых отчетов. Это особенно заметно при анализе сложных медицинских изображений, таких как рентгенограммы грудной клетки, где для постановки точного диагноза требуется учитывать множество факторов и тонкостей визуальной информации. В результате, автоматизированные системы пока не могут полностью заменить квалифицированных врачей-радиологов в процессе интерпретации изображений и составления заключений.
Несоответствие между визуальными данными медицинских изображений и их текстовым описанием существенно снижает точность диагностики и замедляет работу клинических служб. Неспособность существующих систем полноценно интегрировать и анализировать информацию из различных источников — изображения и текстовые заключения — приводит к ошибкам в интерпретации, необходимости дополнительной проверки и увеличению нагрузки на врачей-радиологов. В связи с этим, требуется принципиально новый подход к мультимодальному рассуждению, способный не просто генерировать текст, но и глубоко понимать взаимосвязь между визуальной информацией и медицинскими знаниями, обеспечивая тем самым более надежные и эффективные инструменты для принятия клинических решений.
Особая потребность в надежных и устойчивых моделях искусственного интеллекта проявляется при анализе рентгеновских снимков грудной клетки. Ручная интерпретация таких изображений сопряжена с высокой вероятностью ошибок, обусловленной как субъективностью врачей-радиологов, так и влиянием усталости и ограниченности времени. Выявление тонких признаков патологий, таких как начальные стадии пневмонии или небольшие новообразования, требует высокой концентрации и опыта, что делает процесс уязвимым для человеческого фактора. Автоматизированные системы, способные к точному и последовательному анализу рентгеновских снимков, могут существенно снизить количество диагностических ошибок, обеспечить более раннее выявление заболеваний и, как следствие, улучшить исходы лечения для пациентов. Разработка таких систем является критически важной задачей современной медицинской диагностики.
UniX: Декомпозированная Архитектура для Улучшенного Понимания
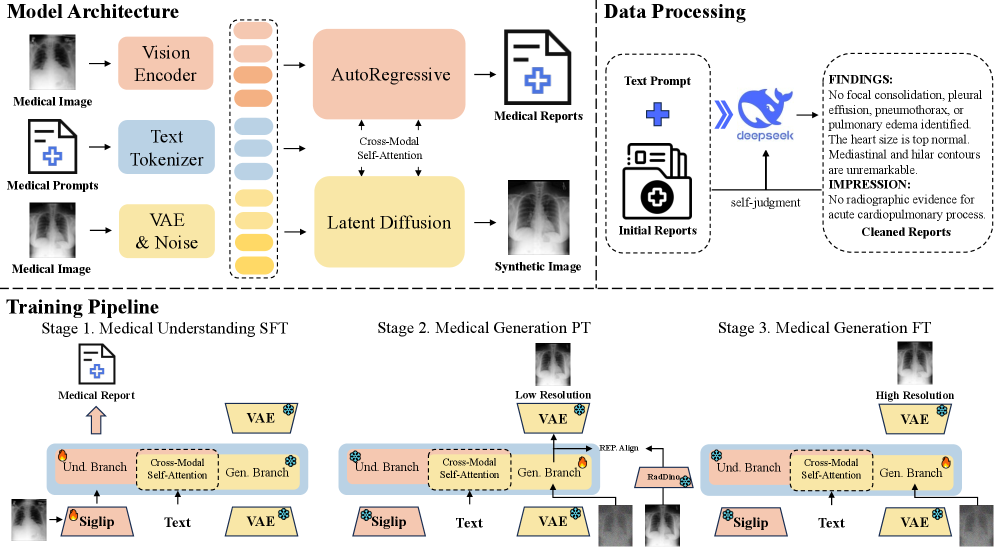
Архитектура UniX построена на принципе разделения, включающего два отдельных потока обработки: семантическое понимание изображения и генерация текстового отчета. Такое разделение позволяет оптимизировать каждый этап независимо, что приводит к повышению общей производительности системы. Вместо единой модели, пытающейся одновременно понять изображение и сгенерировать отчет, UniX сначала извлекает семантическую информацию об изображении, а затем использует ее для формирования отчета. Этот подход позволяет более эффективно использовать вычислительные ресурсы и улучшает качество генерируемых отчетов, поскольку генерация основывается на четком и структурированном понимании визуального контента.
Ветвь понимания в UniX использует авторегрессионное моделирование и визуальный энкодер Siglip-large-patch16-384 для извлечения насыщенных векторных представлений изображения и последующего анализа визуального контента. Siglip-large-patch16-384 преобразует входное изображение в векторное представление, фиксирующее ключевые визуальные характеристики. Авторегрессионное моделирование, применяемое к этим представлениям, позволяет системе последовательно обрабатывать и интерпретировать визуальную информацию, выявляя взаимосвязи между различными элементами изображения и формируя семантическое понимание содержимого. Это обеспечивает основу для последующего анализа и обоснования отчетов.
Обучение ветви понимания осуществляется с использованием функции потерь Cross-Entropy, что позволяет достичь точной семантической абстракции и логического вывода при формировании отчетов. Cross-Entropy Loss оптимизирует модель для предсказания наиболее вероятного класса или метки, основываясь на входных данных изображения и извлеченных признаков. Это способствует более эффективному пониманию визуального контента и формированию клинически релевантных заключений, поскольку модель учится правильно интерпретировать изображения и связывать их с соответствующими медицинскими терминами и концепциями. Выбор данной функции потерь обусловлен ее способностью эффективно работать с задачами классификации и категоризации, что критически важно для анализа медицинских изображений и формирования точных отчетов.
Изоляция этапа понимания изображения в UniX позволяет создать надёжную основу для генерации клинически релевантных и медицински обоснованных отчётов. Разделение процесса на отдельные ветви — понимание и генерация — обеспечивает более точное извлечение семантической информации из визуальных данных, что критически важно для формирования корректных медицинских заключений. Эта архитектура минимизирует влияние ошибок в процессе генерации отчёта, вызванных неточным пониманием изображения, и позволяет UniX выдавать более надёжные и информативные результаты, соответствующие медицинским стандартам.
Высокоточная Генерация с Диффузионными Моделями
Генеративная ветвь модели использует подход Latent Diffusion и вариационный автоэнкодер (VAE) для синтеза детализированных изображений рентгена грудной клетки на основе семантических представлений. VAE сжимает входные данные в латентное пространство, уменьшая вычислительную сложность, а Latent Diffusion, работая в этом сжатом пространстве, генерирует новые изображения. Этот процесс позволяет создавать высококачественные изображения, сохраняя при этом вычислительную эффективность и управляя характеристиками генерируемых данных на основе семантического ввода.
Обучение модели осуществляется с использованием среднеквадратичной ошибки (Mean Squared Error, MSE), которая минимизирует разницу между предсказанными и целевыми полями скорости. Поля скорости, полученные из семантических представлений, направляют процесс диффузии, позволяя модели эффективно реконструировать детализированные изображения. Минимизация MSE обеспечивает точное соответствие между предсказанными изменениями в латентном пространстве и фактическими изменениями, необходимыми для создания высококачественного изображения. Такой подход позволяет добиться более четкой и реалистичной реконструкции, улучшая качество генерируемых изображений рентгена грудной клетки.
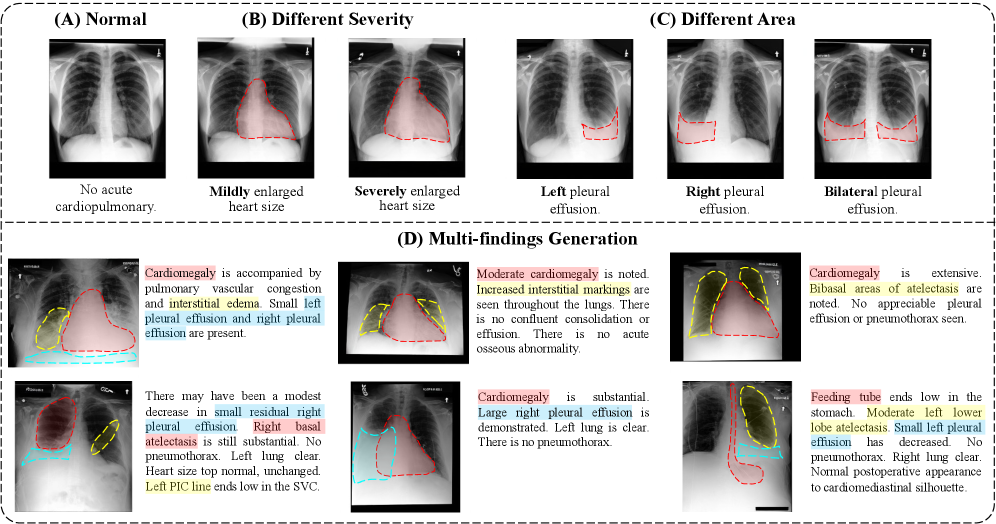
Использование диффузионного подхода в UniX позволяет генерировать реалистичные и клинически релевантные изображения органов грудной клетки. В основе лежит процесс постепенного добавления шума к исходному изображению, а затем его обратного удаления, что позволяет создавать высококачественные снимки, соответствующие медицинским стандартам. Такой подход обеспечивает связь между семантическим пониманием анатомических структур и их визуализацией, позволяя не только анализировать данные, но и создавать наглядные изображения для диагностики и обучения. Сгенерированные изображения могут использоваться для расширения обучающих наборов данных, проведения исследований и поддержки принятия клинических решений.
Разделение на отдельные ветви (understanding и generation) в архитектуре UniX позволяет проводить независимую оптимизацию каждой из них. Это означает, что улучшения, направленные на повышение точности интерпретации изображений (например, сегментации или классификации), не оказывают влияния на качество генерируемых рентгеновских снимков, и наоборот. Такая модульность упрощает процесс разработки и позволяет целенаправленно улучшать отдельные аспекты системы, избегая нежелательных побочных эффектов и обеспечивая стабильность работы обеих ветвей.
Подтверждение Эффективности UniX: Производительность и Согласованность
Обучение UniX осуществляется посредством трехэтапного конвейера, направленного на последовательное согласование ветвей понимания и генерации. На первом этапе модель фокусируется на освоении понимания рентгеновских изображений и связанных с ними медицинских отчетов. Второй этап направлен на обучение генерации текста, описывающего изображения, используя информацию, полученную на первом этапе. На заключительном этапе происходит совместная оптимизация обеих ветвей, что позволяет модели не только понимать рентгеновские снимки, но и генерировать точные и информативные отчеты, обеспечивая тем самым согласованность между визуальным и текстовым представлением данных. Такой подход позволяет добиться более высокой производительности и надежности модели в задачах медицинской диагностики и анализа.
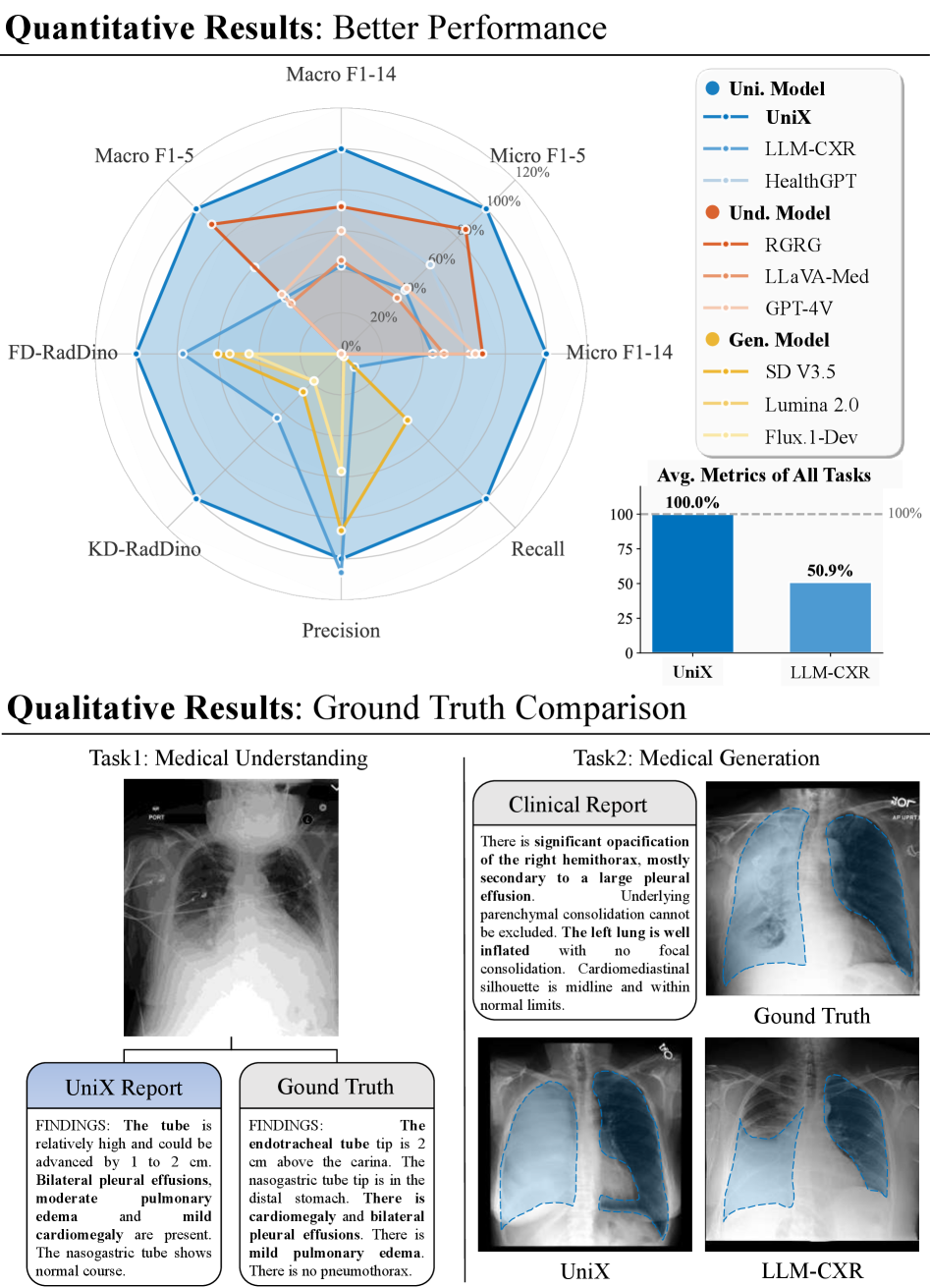
Оценка модели UniX с использованием RadDino и CheXbert подтверждает ее способность генерировать изображения высокого качества и создавать достоверные медицинские заключения. RadDino, предназначенный для оценки качества генерируемых изображений, показал высокие результаты, свидетельствующие о реалистичности и детализации сгенерированных рентгеновских снимков. CheXbert, специализирующийся на оценке надежности медицинских отчетов, подтвердил точность и клиническую релевантность генерируемых заключений, что указывает на потенциальную применимость UniX в качестве инструмента поддержки принятия решений в медицинской практике.
Модель UniX демонстрирует превосходство над существующими решениями, таким как Sana, в задачах анализа и генерации рентгеновских снимков, что подтверждается результатами на бенчмарке CheXGenBench. Данный бенчмарк позволяет оценить способность модели к комплексному пониманию рентгеновских изображений и генерации соответствующих медицинских заключений. UniX превосходит Sana по ключевым метрикам, что свидетельствует о более высокой точности и эффективности в задачах медицинской визуализации и автоматизированной радиологической диагностики.
В ходе оценки производительности модели UniX было зафиксировано значительное улучшение ключевых метрик по сравнению с LLM-CXR. В частности, UniX демонстрирует прирост в 46.1% по метрике Micro-F1, используемой для оценки понимания рентгеновских изображений, и 24.2% по метрике FD-Raddino, предназначенной для оценки качества генерируемых отчетов. Эти результаты свидетельствуют о превосходстве UniX в задачах как интерпретации медицинских изображений, так и автоматизированного создания соответствующих заключений.
Использование весов, полученных из предварительно обученной модели Janus-Pro, позволило значительно ускорить процесс обучения UniX и добиться повышения производительности. Перенос знаний из Janus-Pro, обладающей широким спектром общих лингвистических и визуальных представлений, снизил потребность в обучении с нуля, что привело к более быстрой сходимости модели и улучшению ее способности к пониманию и генерации медицинских отчетов. Этот подход позволил UniX достичь высоких показателей, используя меньшее количество параметров по сравнению с другими моделями, такими как LLM-CXR.
Модель UniX демонстрирует значительное повышение эффективности за счет использования лишь 25% от количества параметров, необходимых для LLM-CXR, при сохранении и превосходстве в показателях производительности. Это достигается благодаря оптимизированной архитектуре и процессу обучения, позволяющим добиться сопоставимых, а в ряде случаев и лучших результатов при значительно меньшем объеме вычислительных ресурсов и памяти. Сокращение количества параметров не только снижает требования к оборудованию, но и потенциально ускоряет процесс инференса и развертывания модели в клинической практике.
Перспективы Развития: К Комплексному Клиническому ИИ
UniX представляет собой заметный прорыв в создании комплексных клинических систем искусственного интеллекта, способных не только анализировать, но и генерировать медицинские данные. В отличие от существующих моделей, ориентированных на узкоспециализированные задачи, UniX демонстрирует способность к универсальной обработке информации, охватывая широкий спектр медицинских модальностей и типов данных. Такой подход позволяет создавать системы, которые могут интегрировать результаты различных исследований — от рентгеновских снимков до текстовых заключений — и формировать целостное представление о состоянии пациента. Благодаря своей архитектуре, UniX открывает перспективы для разработки интеллектуальных помощников, способных поддерживать врачей в принятии решений, а также для автоматизации рутинных задач, что, в конечном итоге, способствует повышению качества и доступности медицинской помощи.
Архитектура UniX, отличающаяся своей модульностью, предоставляет уникальную возможность для поэтапного улучшения и адаптации к разнообразным методам медицинской визуализации. Разделение на отдельные компоненты позволяет исследователям и разработчикам совершенствовать каждый модуль независимо, не затрагивая функционирование всей системы. Это особенно важно, учитывая разнообразие медицинских изображений — от рентгеновских снимков и компьютерной томографии до магнитно-резонансной томографии и ультразвуковых исследований. Благодаря такой конструкции, UniX может быть легко адаптирован для обработки новых типов изображений и применения в различных клинических сценариях, обеспечивая гибкость и масштабируемость, необходимые для создания комплексной системы искусственного интеллекта в медицине.
Предстоящие исследования сосредоточены на интеграции UniX с существующими клиническими инструментами, что позволит создать комплексные системы поддержки принятия решений для врачей. Особое внимание уделяется разработке персонализированных диагностических решений, использующих возможности UniX для анализа медицинских изображений и данных пациента с целью выявления индивидуальных особенностей и прогнозирования рисков. Внедрение UniX в клиническую практику предполагает создание адаптивных систем, способных учитывать уникальный анамнез каждого пациента и предлагать наиболее эффективные стратегии лечения, что, в свою очередь, откроет новые возможности для прецизионной медицины и повышения качества оказания медицинской помощи.
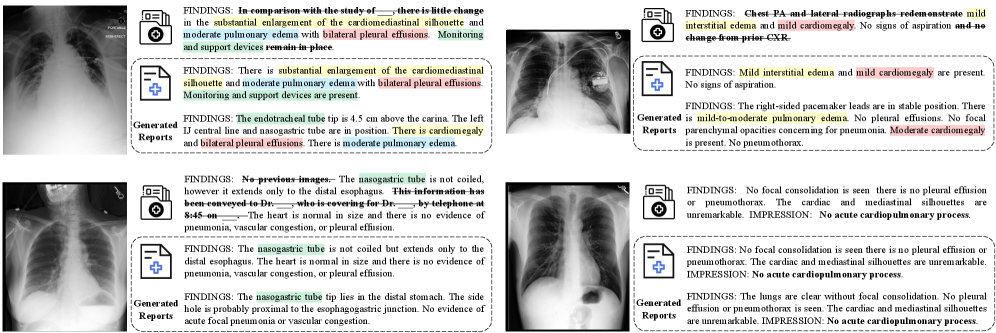
Исследования, в которых применяются модели, такие как DeepSeek LLM для очистки набора данных MIMIC-CXR, наглядно демонстрируют критическую роль качества данных в эффективности фундаментальных моделей искусственного интеллекта. Тщательная предобработка и верификация медицинских данных, включая рентгеновские снимки, позволяют значительно повысить точность и надежность диагностических систем. В дальнейшем, усовершенствование методов очистки данных и разработка новых алгоритмов для выявления и исправления ошибок станут ключевым направлением исследований, обеспечивающим прогресс в области клинического применения искусственного интеллекта и способствующим созданию более эффективных и персонализированных решений для здравоохранения.
Представленная работа демонстрирует стремление к элегантности в архитектуре медицинских моделей. UniX, с её раздвоенной структурой и механизмом кросс-модального внимания, представляет собой попытку создать систему, чья внутренняя логика столь же ясна, как и результаты. Это напоминает высказывание Эндрю Ына: «Если решение кажется магией — значит, вы не раскрыли инвариант». Успех UniX в задачах понимания и генерации рентгеновских снимков грудной клетки подтверждает, что строгое следование математической чистоте и принципам доказуемости позволяет создавать действительно эффективные и надежные алгоритмы, избегая эвристик и полагаясь на фундаментальные принципы.
Куда Ведет Этот Путь?
Представленная работа, несмотря на достигнутые результаты в области унификации авторегрессионного и диффузионного моделирования для рентгеновских снимков грудной клетки, лишь обозначает начало пути, а не его завершение. Истинная элегантность заключается не в достижении state-of-the-art, а в демонстрации фундаментальной возможности создания модели, масштабируемой до объемов данных, превосходящих текущие возможности. Очевидно, что упрощение архитектуры и повышение эффективности использования параметров — это не просто инженерные задачи, но и необходимость для преодоления вычислительных ограничений, которые неизбежно встанут на пути дальнейшего прогресса.
Ключевым вопросом остаётся проблема обобщения. Способность модели к адаптации к новым, ранее не встречавшимся патологиям, без существенной перестройки, — вот истинный критерий её интеллекта. Текущие методы, основанные на кросс-модальном внимании, безусловно, перспективны, однако они требуют дальнейшей оптимизации и, возможно, принципиально новых подходов к представлению и обработке медицинских знаний. Недостаточно просто «видеть» признаки; необходимо понимать их взаимосвязь и контекст.
В конечном итоге, успех в этой области будет определяться не количеством публикаций, а способностью создавать модели, которые действительно улучшают качество диагностики и лечения. И пусть эта цель кажется утопичной, но именно к ней и следует стремиться, помня, что сложность алгоритма измеряется не количеством строк кода, а пределом его масштабируемости и асимптотической устойчивостью.
Оригинал статьи: https://arxiv.org/pdf/2601.11522.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые прорывы: Хорошее, плохое и смешное
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2026-01-21 08:03