Автор: Денис Аветисян
Новый подход к организации контекста позволяет большим языковым моделям эффективно обрабатывать длинные и сложные тексты, снижая нагрузку и повышая точность.
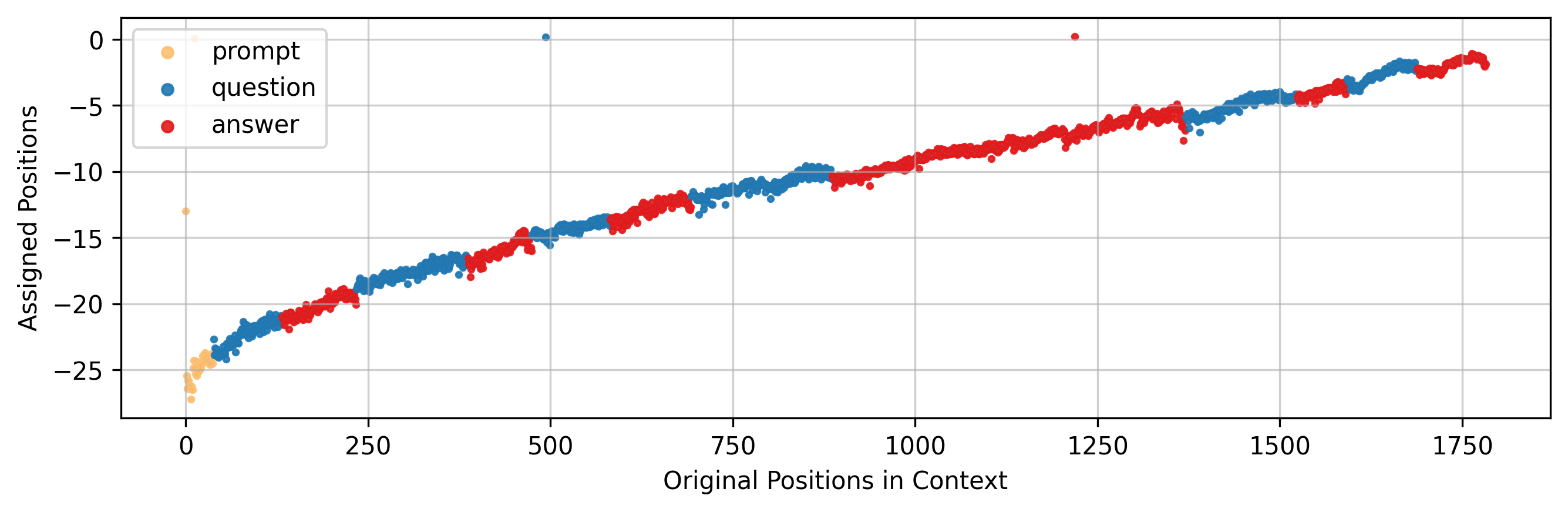
В статье представлена методика Context Re-Positioning (RePo), позволяющая динамически переупорядочивать контекстную информацию для улучшения работы языковых моделей с длинными последовательностями и зашумленными данными.
Несмотря на успехи современных больших языковых моделей, их способность эффективно использовать контекст ограничена жесткой структурой позиционных индексов. В работе «RePo: Language Models with Context Re-Positioning» предложен новый механизм, перепозиционирующий контекст для снижения когнитивной нагрузки и повышения производительности. Авторы демонстрируют, что динамическое назначение позиций токенов, основанное на контекстуальных зависимостях, значительно улучшает работу моделей на задачах с зашумленными данными, структурированной информацией и длинным контекстом. Не приведет ли это к переосмыслению способов кодирования позиций в архитектурах больших языковых моделей и открытию новых горизонтов в понимании длинных последовательностей?
Пределы контекста: большие языковые модели и рабочая память
Несмотря на впечатляющие способности, современные большие языковые модели (LLM) часто сталкиваются с трудностями при решении задач, требующих установления связей между отдаленными друг от друга элементами информации или проведения сложных рассуждений. Это проявляется в неспособности последовательно поддерживать длинные диалоги, понимать сюжетные перипетии в объемных текстах или решать задачи, требующие учета множества взаимосвязанных факторов. В то время как модели демонстрируют высокую производительность при обработке локального контекста, их эффективность значительно снижается при необходимости учитывать информацию, находящуюся за пределами ограниченного «окна внимания». Данное ограничение не связано с недостатком обучающих данных, а обусловлено фундаментальными принципами работы архитектуры Transformer и сложностью эффективной обработки длинных последовательностей информации.
Ограничения больших языковых моделей в обработке длинных последовательностей и сложных рассуждений тесно связаны с принципиальными особенностями их архитектуры. Ключевым фактором является механизм внимания (Attention Mechanism) в трансформерах, который, хотя и позволяет модели фокусироваться на релевантных частях входных данных, требует $O(n^2)$ вычислительных ресурсов и памяти, где $n$ — длина последовательности. Это означает, что с увеличением контекстного окна, необходимая память и время обработки растут квадратично, что быстро становится непосильным даже для мощнейших вычислительных систем. По сути, модель сталкивается с ограничениями, аналогичными тем, что существуют у человеческой рабочей памяти — невозможностью одновременно удерживать и эффективно обрабатывать слишком большой объем информации. Таким образом, сложность заключается не только в масштабировании размера модели, но и в разработке методов, позволяющих эффективно управлять и сохранять информацию в ограниченном контекстном окне.
Проблема, с которой сталкиваются большие языковые модели, заключается не только в увеличении их размера, но и в эффективной обработке и удержании информации в рамках ограниченного контекстного окна. Несмотря на впечатляющий рост параметров и вычислительных мощностей, способность модели к долгосрочному запоминанию и использованию информации существенно ограничена. Это связано с архитектурой Transformer, где внимание к каждому элементу контекста требует $O(n^2)$ операций, где $n$ — длина последовательности. Таким образом, даже небольшое увеличение длины контекста приводит к экспоненциальному росту вычислительных затрат и снижению производительности. Решение заключается не только в увеличении размера модели, но и в разработке более эффективных механизмов внимания и методов сжатия информации, позволяющих обрабатывать большие объемы данных, не теряя при этом релевантность и точность.
Существующие подходы, такие как генерация с расширением извлечением (Retrieval-Augmented Generation), предлагают частичные решения проблемы ограниченного контекста больших языковых моделей, однако не лишены недостатков. Эти методы, требующие поиска и интеграции релевантной информации из внешних источников, значительно усложняют архитектуру системы и увеличивают вычислительную нагрузку. В частности, процесс извлечения информации добавляет задержку, что может быть критично для приложений, требующих быстрого отклика. Более того, эффективность таких систем напрямую зависит от качества и релевантности извлечённых данных, а также от точности алгоритмов поиска, что требует дополнительных усилий по их оптимизации и поддержанию. Таким образом, несмотря на свою полезность, генерация с расширением извлечением не является идеальным решением и требует тщательного взвешивания преимуществ и недостатков в каждом конкретном случае.

За пределами традиционного кодирования: переосмысление позиционной информации
Традиционные методы кодирования позиции, такие как RoPE и ALiBi, несмотря на свою эффективность, по-прежнему полагаются на явные позиционные вложения ($positional embeddings$). В контексте обработки очень длинных последовательностей, информативность этих вложений снижается. Это связано с тем, что фиксированные векторы, представляющие позицию токена, становятся менее различимыми на больших расстояниях, затрудняя модели различение относительных позиций токенов, находящихся далеко друг от друга. В результате, способность модели эффективно обрабатывать долгосрочные зависимости ухудшается, что требует разработки альтернативных подходов или модификаций существующих методов для поддержания производительности при работе с большими объемами данных.
Метод NoPE представляет собой радикальный отказ от использования позиционных кодировок, традиционно применяемых в архитектурах Transformer для учета порядка токенов в последовательности. Вместо явного кодирования позиции, NoPE полагается на механизм внимания для неявно определения взаимосвязей между токенами. Однако, полное исключение позиционной информации может приводить к снижению производительности модели, особенно при обработке длинных последовательностей, где порядок токенов становится критически важным. Для смягчения этого эффекта требуются дополнительные стратегии, такие как тщательная инициализация весов и использование регуляризации, чтобы модель могла эффективно извлекать информацию о позиции из данных.
Гибридное позиционное кодирование представляет собой стратегию, направленную на объединение преимуществ различных подходов к кодированию позиции токенов в последовательности. Вместо использования единственного метода, такого как абсолютное или относительное позиционное кодирование, гибридные подходы комбинируют их, чтобы смягчить недостатки каждого. Например, можно использовать абсолютное позиционное кодирование для близких токенов и относительное — для дальних, что позволяет более эффективно обрабатывать как локальные, так и глобальные зависимости в длинных последовательностях. Такой подход позволяет добиться большей гибкости и улучшить общую производительность модели, особенно при работе с данными, требующими учета как абсолютного положения токенов, так и их относительной близости друг к другу. Комбинация может включать в себя не только различные типы позиционного кодирования, но и адаптивные методы, динамически изменяющие стратегию кодирования в зависимости от характеристик входной последовательности.
Метод перепозиционирования контекста (RePo) представляет собой новый подход к обработке последовательностей, основанный на динамической реорганизации позиций токенов внутри входной последовательности. В отличие от традиционных методов, RePo не использует фиксированные или абсолютные позиционные вложения. Вместо этого, позиции токенов пересчитываются в процессе обработки, что позволяет модели более эффективно фокусироваться на релевантных контекстных взаимосвязях. Это достигается путем изменения порядка токенов таким образом, чтобы близкие по смыслу элементы располагались ближе друг к другу, что снижает влияние дальних зависимостей и повышает эффективность механизма внимания ($Attention$). Репозиционирование контекста призвано оптимизировать вычисление внимания, сокращая необходимое количество операций и улучшая производительность модели при обработке длинных последовательностей.
Подтверждение эффективности RePo: бенчмаркинг производительности при работе с длинным контекстом
Для оценки производительности больших языковых моделей (LLM) при работе с длинным контекстом необходимы специализированные бенчмарки, такие как LongBench и Needle-in-a-Haystack (NIAH). LongBench предназначен для комплексной оценки возможностей LLM при обработке длинных последовательностей, охватывая различные типы задач и сценарии. NIAH, в свою очередь, фокусируется на способности модели находить релевантную информацию в большом объеме неструктурированных данных, имитируя реальные сценарии поиска. Использование этих бенчмарков позволяет количественно оценить способность LLM сохранять и использовать информацию из длинного контекста, выявляя слабые места и направляя дальнейшие исследования в области улучшения производительности.
Метрика RULER играет важную роль в оценке устойчивости языковых моделей к зашумленному контексту, что является распространенной проблемой при практическом применении. RULER оценивает способность модели корректно отвечать на вопросы, когда в контексте присутствуют отвлекающие или нерелевантные данные. Тесты RULER позволяют выявить, насколько эффективно модель фильтрует шум и извлекает полезную информацию, необходимую для точного ответа. Результаты показывают, что RePo демонстрирует улучшение на 11.04 балла в метрике RULER при длине контекста 4K, что свидетельствует о повышенной устойчивости к шуму в контексте по сравнению с другими подходами.
При использовании базовой языковой модели OLMo-2 и слоя SwiGLU в архитектуре RePo, исследователи зафиксировали улучшение производительности на стандартных бенчмарках. В частности, наблюдается прирост до 13.25 баллов EM (Exact Match) в задачах вопросно-ответной системы (QA) и поиска иголки в стоге сена (Needle-in-a-Haystack, NIAH). Данный результат демонстрирует эффективность предложенного подхода к обработке длинного контекста и его способность повышать точность выполнения задач, требующих анализа больших объемов информации.
В дополнение к RePo, для расширения длины контекста используется YaRN, что позволяет провести сравнительный анализ двух подходов. При увеличении длины контекста до 16K токенов YaRN демонстрирует улучшение на 5.48 пункта в бенчмарке LongBench. В свою очередь, RePo показывает более значительное улучшение в 11.04 пункта в бенчмарке RULER при решении задач с зашумленным контекстом при длине контекста 4K, а также улучшение на 1.94 пункта в задачах, связанных со структурированными данными.

Влияние на когнитивную нагрузку и эффективность рассуждений
Теория когнитивной нагрузки подчеркивает ограниченность оперативной памяти человека, рассматривая её как узкое «горлышко» в процессе обработки информации. В этой связи, крайне важно минимизировать избыточную нагрузку — когнитивные усилия, затрачиваемые на обработку нерелевантной информации или плохо структурированных данных. Одновременно с этим, необходимо максимизировать продуктивную нагрузку, направленную на осмысление и усвоение действительно важного материала. По сути, речь идет о создании оптимальных условий для обучения и решения задач, где ресурсы оперативной памяти используются максимально эффективно, а не расходуются на преодоление когнитивного «шума». Понимание этих принципов позволяет разрабатывать более эффективные стратегии обучения и проектировать интерфейсы, способствующие лучшему усвоению и применению знаний.
Механизм RePo позволяет большим языковым моделям (LLM) значительно повысить эффективность обработки информации, минимизируя вычислительную нагрузку, связанную с анализом нерелевантных данных. Вместо того чтобы тратить ресурсы на отсеивание бесполезного контекста, LLM, использующие RePo, получают возможность сосредоточиться исключительно на наиболее важных аспектах входной информации. Этот подход не только ускоряет процесс обработки, но и позволяет моделям глубже понимать суть задачи, что критически важно для сложных рассуждений и принятия решений. По сути, RePo действует как интеллектуальный фильтр, обеспечивающий LLM доступ к наиболее релевантным данным, что приводит к более точным и эффективным результатам.
Повышение эффективности обработки информации, достигаемое благодаря оптимизации контекста, ведет к заметному снижению задержки ответа у больших языковых моделей (LLM). Это не только улучшает пользовательский опыт, но и открывает возможности для более оперативного решения задач в режиме реального времени. Более того, сокращение вычислительной нагрузки напрямую влияет на энергопотребление, делая LLM более устойчивыми и доступными для широкого круга пользователей и приложений. В перспективе, это способствует развитию экологически чистых технологий искусственного интеллекта и расширению возможностей применения LLM в ресурсоограниченных средах, таких как мобильные устройства и периферийные вычисления.
Эффективное управление контекстом, обеспечиваемое RePo, имеет решающее значение для функционирования автономных систем и обучения с небольшим количеством примеров. В агентных системах, где требуется самостоятельное принятие решений на основе имеющейся информации, способность быстро и точно извлекать релевантный контекст напрямую влияет на качество и скорость реакций. Аналогично, в задачах обучения с небольшим количеством примеров, где модель должна адаптироваться к новым данным с ограниченным набором обучающих данных, грамотное управление контекстом позволяет модели обобщать знания и эффективно применять их к новым ситуациям. Таким образом, RePo способствует повышению надежности и гибкости интеллектуальных систем, открывая новые возможности для их применения в различных областях, требующих адаптивности и самостоятельности.
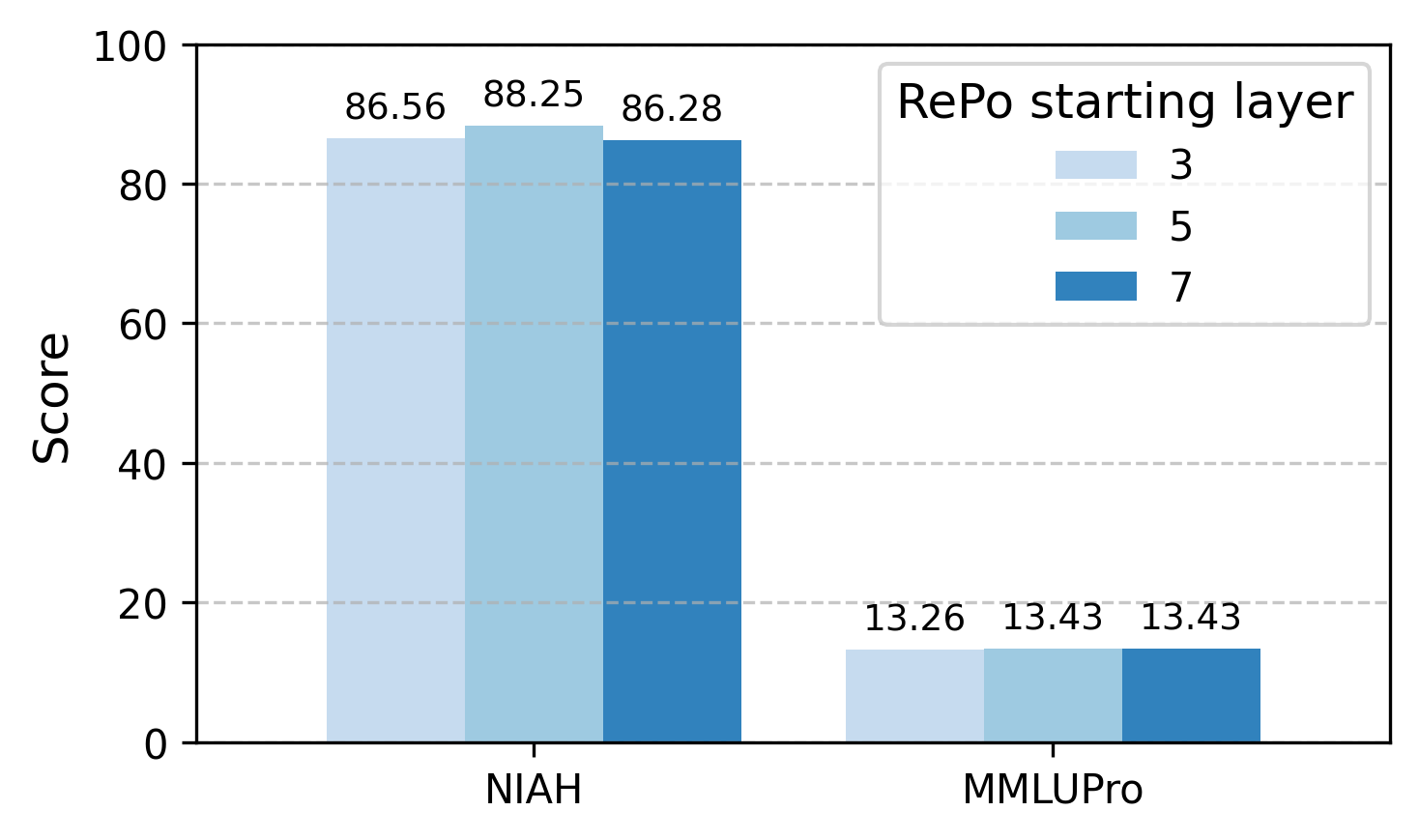
В исследовании, посвященном динамической реорганизации контекстной информации, отчетливо прослеживается закономерность, знакомая всякому, кто сталкивался с архитектурой сложных систем. Авторы предлагают метод Context Re-Positioning, стремясь снизить когнитивную нагрузку на модели, что невольно напоминает о необходимости постоянного рефакторинга и оптимизации любого программного обеспечения. Как метко заметил Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать машины, чтобы они делали вещи, которые требуют интеллекта, когда их делают люди». Иными словами, задача не в создании идеального алгоритма, а в адаптации к неизбежному хаосу входных данных и ограничений ресурсов. Подобно тому, как RePo переупорядочивает контекст, так и эффективная архитектура должна предвидеть и смягчать будущие сбои, превращая их из катастроф в управляемые отклонения.
Куда же дальше?
Предложенный метод перепозиционирования контекста, несомненно, добавляет ещё один слой сложности в и без того запутанную архитектуру больших языковых моделей. Масштабируемость — всего лишь слово, которым мы оправдываем эту сложность, и легко забыть, что каждое нововведение — это пророчество о будущей точке отказа. Улучшение производительности на задачах с длинным контекстом и шумом — это, конечно, хорошо, но всё оптимизированное однажды потеряет гибкость. Вопрос в том, не усугубляем ли мы проблему, пытаясь «накормить» модели всё большим объёмом информации, вместо того чтобы научить их более эффективно извлекать суть?
Истинная проблема не в длине контекста, а в нашей неспособности создать системы, которые могут адаптироваться к неполноте и неопределенности. Позиционное кодирование и механизмы внимания — это лишь инструменты, и каждое их усовершенствование — временное решение. Идеальная архитектура — это миф, нужный, чтобы мы не сошли с ума, но за ним не должно скрываться нежелание переосмыслить саму парадигму обработки информации.
Будущие исследования, вероятно, будут направлены на создание более динамических и адаптивных систем, которые могут самостоятельно определять релевантность информации и отбрасывать шум. Вместо того чтобы строить всё более сложные «экосистемы» из алгоритмов, возможно, стоит обратить внимание на принципы самоорганизации и эмерджентности. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Оригинал статьи: https://arxiv.org/pdf/2512.14391.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-12-17 23:18