Автор: Денис Аветисян
Исследование оценивает способность современных языковых моделей генерировать код, соответствующий заданным инструкциям, и представляет новый бенчмарк для более точной оценки.

Представлен бенчмарк C3-Bench для оценки управляемого автодополнения кода и показано улучшение результатов с помощью дообученной модели с открытым исходным кодом.
Несмотря на значительный прогресс в области языковых моделей для генерации кода, оценка их способности следовать инструкциям пользователя остаётся сложной задачей. В работе ‘Evaluating and Achieving Controllable Code Completion in Code LLM’ представлен новый бенчмарк C3-Bench, предназначенный для оценки контролируемого завершения кода, выявляющий существенные различия в следовании инструкциям между открытыми и проприетарными моделями. Разработанная на основе Qwen2.5-Coder модель Qwen2.5-Coder-C3 демонстрирует передовые результаты на C3-Bench, подтверждая важность специализированной тонкой настройки. Какие новые подходы к обучению и оценке позволят в полной мере реализовать потенциал языковых моделей в задачах разработки программного обеспечения?
Традиционные инструменты и ложные надежды
Традиционные инструменты автодополнения кода зачастую сталкиваются с трудностями при работе со сложными проектами. Их возможности по анализу обширной кодовой базы и пониманию контекста ограничены, что приводит к генерации нерелевантных или неточных предложений. Вместо того, чтобы предлагать фрагменты кода, действительно соответствующие текущей задаче и архитектуре проекта, эти инструменты, как правило, оперируют статистическими закономерностями или простыми шаблонами. Это снижает продуктивность разработчиков, заставляя их вручную корректировать предложенные варианты или искать альтернативные решения. В результате, потенциал автоматизации и ускорения процесса разработки остается нереализованным, а качество кода может страдать из-за увеличения вероятности ошибок и несоответствий.
Появление больших языковых моделей (LLM) открыло многообещающие перспективы в области автоматического завершения кода. Эти модели демонстрируют впечатляющую способность генерировать фрагменты кода, зачастую имитируя стиль и структуру, присущие человеческому программированию. Однако, несмотря на этот прогресс, LLM сталкиваются с трудностями при реализации тонкого и контролируемого завершения кода. В частности, им сложно учитывать сложные зависимости в больших проектах, придерживаться конкретных требований к реализации или генерировать код, точно соответствующий заданным ограничениям. В то время как LLM способны предложить синтаксически верные варианты, их способность к семантически корректному и контекстуально релевантному завершению кода, особенно в сложных сценариях, остается ограниченной, что требует дальнейших исследований и разработок в этой области.
Существующие эталоны оценки, такие как HumanEval и CrossCodeEval, несмотря на свою ценность, оказываются недостаточными при проверке способности моделей следовать конкретным требованиям к реализации в рамках крупных проектов. Эти тесты, как правило, фокусируются на генерации небольших, изолированных фрагментов кода, не учитывая необходимость интеграции с существующей кодовой базой, соблюдения архитектурных принципов и соответствия специфическим соглашениям о кодировании. В результате, модель может успешно проходить тесты на генерацию синтаксически верного кода, но испытывать трудности при адаптации к реальным условиям разработки, где важна не только функциональность, но и поддерживаемость, масштабируемость и совместимость с другими компонентами системы. Поэтому для всесторонней оценки инструментов автодополнения кода необходимы более сложные и реалистичные эталоны, имитирующие сценарии разработки в больших проектах.
Недостаток существующих методов оценки и моделей автозавершения кода обуславливает необходимость разработки нового поколения инструментов, ориентированных на управляемое автозавершение (Controllable Code Completion, CCC). В отличие от традиционных подходов, CCC предполагает не просто предсказание следующего фрагмента кода, а генерацию решений, точно соответствующих заданным требованиям и контексту более крупного проекта. Это требует от моделей способности учитывать специфические ограничения, архитектурные принципы и предпочтения разработчика, что значительно повышает практическую ценность и надежность предлагаемых решений. Разработка адекватных критериев оценки для CCC, выходящих за рамки простого совпадения кода, является ключевым шагом к созданию интеллектуальных помощников для программирования, способных эффективно интегрироваться в сложные рабочие процессы и существенно повышать производительность разработчиков.

C3-Bench: Новый стандарт оценки управляемого автодополнения
C3-Bench представляет собой новый эталон для оценки моделей, специализирующийся на контролируемом завершении кода, что отличает его от традиционных тестов, ограничивающихся генерацией отдельных фрагментов. В отличие от существующих бенчмарков, C3-Bench оценивает способность модели генерировать код, соответствующий заданным параметрам масштаба и конкретным требованиям к реализации. Это позволяет получить более точную оценку возможностей модели в контексте сложных задач разработки программного обеспечения, требующих не просто генерации синтаксически корректного кода, но и учета дополнительных ограничений и контекста.
Бенчмарк C3-Bench включает в себя два основных компонента: Scale-Control Completion (SCC) и Implementation-Control Completion (ICC). SCC оценивает способность модели генерировать код заданного масштаба и сложности, проверяя, насколько точно модель может соблюдать ограничения по объему и структуре генерируемого кода. В свою очередь, ICC фокусируется на оценке соответствия с конкретными требованиями к реализации, таким как использование определенных алгоритмов, структур данных или API. Таким образом, оба компонента в совокупности позволяют комплексно оценить способность модели к контролируемому завершению кода.
Эффективная оценка на базе C3-Bench напрямую зависит от способности модели к точному следованию инструкциям. Это означает, что модель должна корректно интерпретировать и выполнять пользовательские ограничения, заданные в запросе. Успешное прохождение тестов C3-Bench требует от модели не просто генерации синтаксически верного кода, но и его соответствия всем заданным условиям, включая требуемый масштаб (scope) и специфические требования к реализации. Неспособность к точному пониманию и исполнению инструкций приводит к снижению показателей оценки, даже если сгенерированный код функционально работоспособен.
C3-Bench разработан для оценки возможностей моделей в условиях, приближенных к реальным задачам разработки программного обеспечения. Традиционные бенчмарки часто ограничиваются генерацией небольших фрагментов кода, не учитывая необходимость соблюдения заданного масштаба или конкретных требований к реализации. C3-Bench, напротив, проверяет способность модели генерировать код, соответствующий определенному контексту и сложности (Scale-Control Completion), а также точно выполнять заданные спецификации и ограничения (Implementation-Control Completion). Такой подход позволяет более адекватно оценить пригодность модели для использования в сложных проектах, где важна не только функциональность, но и соответствие архитектурным требованиям и стандартам кодирования.
Qwen2.5-Coder-C3: Высокопроизводительная модель управляемого автодополнения
Модель Qwen2.5-Coder-C3 разработана на основе Qwen2.5-Coder-32B-Instruct и представляет собой специализированную версию, подвергнутую тонкой настройке для задач контролируемого завершения кода. В отличие от базовой модели, Qwen2.5-Coder-C3 оптимизирована для более точного и предсказуемого генерирования кода, что позволяет разработчикам управлять процессом автодополнения и получать результаты, соответствующие заданным требованиям и контексту. Этот процесс тонкой настройки направлен на улучшение способности модели к пониманию намерений программиста и генерации кода, который легко интегрируется в существующие проекты.
Для создания масштабного и высококачественного набора данных для обучения модели Qwen2.5-Coder-C3 был использован сложный конвейер синтеза данных. В его работе задействованы мощные языковые модели, такие как GPT-4, Claude3.5-Sonnet и DeepSeek-V3. Данный конвейер позволяет автоматически генерировать примеры кода, обеспечивая разнообразие и сложность обучающих данных, необходимые для эффективной работы модели в задачах кодирования. Использование нескольких моделей позволило повысить надежность и качество сгенерированных данных, минимизируя потенциальные ошибки и предвзятости.
В процессе генерации обучающих данных использовалось извлечение абстрактного синтаксического дерева (AST) для обеспечения синтаксической корректности генерируемого кода. AST представляет собой древовидную структуру, отражающую грамматическую структуру исходного кода, что позволяет точно контролировать его валидность и соответствие заданным требованиям. Этот метод гарантирует, что сгенерированный код компилируется и выполняет ожидаемые функции, а также позволяет управлять уровнем сложности кода путем манипулирования структурой AST.
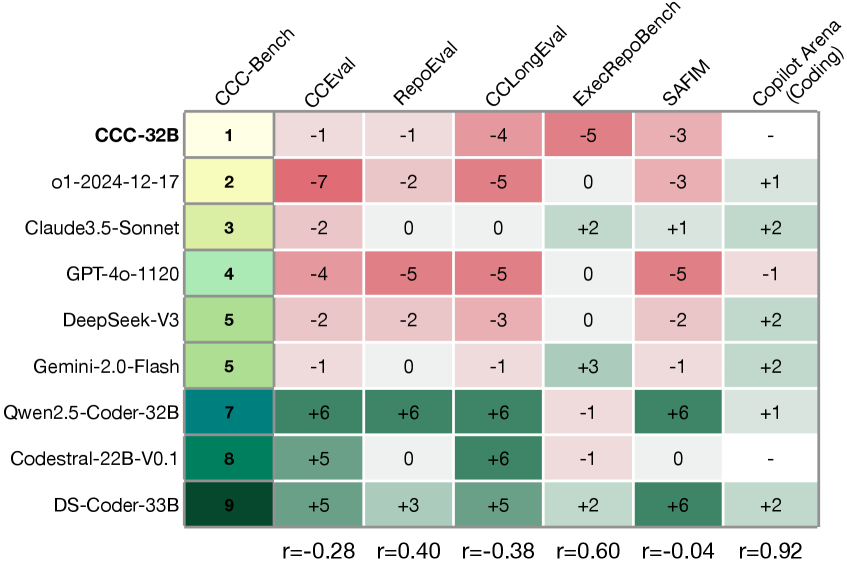
Модель Qwen2.5-Coder-C3 продемонстрировала передовые результаты на бенчмарке C3-Bench, достигнув показателя точного соответствия (Exact Match, EM) в 57.1% на наборе CrossCodeEval и 51.6% на RepoEval. Эти результаты превосходят показатели, ранее демонстрировавшиеся другими моделями, что подтверждает высокую эффективность Qwen2.5-Coder-C3 в задачах генерации и завершения кода.
Проверка производительности на сложных бенчмарках: Практическая ценность и ограничения
Тщательная оценка с использованием таких эталонов, как RepoEval, CrossCodeLongEval и ExecRepoBench, подтверждает высокую эффективность Qwen2.5-Coder-C3 в сложных сценариях завершения кода. Эти тесты не ограничиваются простым предсказанием следующей строки, а требуют от модели понимания контекста всего репозитория, обработки длинных последовательностей кода и работы в рамках исполняемых кодовых баз. Успешное прохождение этих сложных испытаний демонстрирует способность Qwen2.5-Coder-C3 адаптироваться к различным стилям кодирования и эффективно функционировать в реалистичных условиях разработки, что делает его ценным инструментом для профессиональных разработчиков и энтузиастов.
Оценка возможностей модели Qwen2.5-Coder-C3 проводилась с использованием специализированных бенчмарков, позволяющих проверить её способность не просто генерировать отдельные фрагменты кода, но и интегрировать их в существующие, крупные программные проекты. Эти тесты, такие как RepoEval, CrossCodeLongEval и ExecRepoBench, имитируют реальные сценарии разработки, требуя от модели понимать контекст всего репозитория, обрабатывать длинные последовательности кода и обеспечивать работоспособность генерируемого кода в рамках полноценной, исполняемой кодовой базы. Такой подход позволяет достоверно оценить, насколько хорошо модель адаптируется к сложным задачам кодирования, выходящим за рамки простых примеров, и демонстрирует её потенциал для практического применения в разработке программного обеспечения.
Исследования, проведенные с использованием разнообразных эталонных тестов, таких как RepoEval, CrossCodeLongEval и ExecRepoBench, подтверждают выдающиеся способности модели Qwen2.5-Coder-C3 к адаптации и обобщению. Постоянно высокие результаты на этих платформах демонстрируют, что модель способна эффективно решать сложные задачи кодирования в различных контекстах и условиях. В частности, на CrossCodeLongEval Qwen2.5-Coder-C3 достигла показателя Exact Match (EM) в 36.9%, что свидетельствует о ее точности в предсказании и генерации кода, соответствующего эталонным решениям. Такая способность к обобщению позволяет модели успешно применяться к новым, ранее не встречавшимся задачам, что делает ее ценным инструментом для разработчиков.
В ходе тестирования на бенчмарке SAFIM, модель Qwen2.5-Coder-C3 продемонстрировала выдающийся результат, достигнув показателя успешного выполнения задач в 71.2%. Этот результат является наивысшим среди всех протестированных моделей и подчеркивает практическую применимость Qwen2.5-Coder-C3 в реальных сценариях разработки программного обеспечения. Высокий процент успешности указывает на способность модели эффективно решать сложные задачи кодирования, что делает её ценным инструментом для профессиональных разработчиков и автоматизации процессов программирования. Полученные данные свидетельствуют о превосходстве Qwen2.5-Coder-C3 в контексте практического применения и её потенциале для повышения эффективности разработки.
Статья, посвящённая оценке возможностей языковых моделей в генерации кода, не могла не вызвать знакомое чувство дежавю. Авторы представляют C3-Bench, новый эталон для проверки следования инструкциям, и обнаруживают, что текущие модели далеки от совершенства. Это предсказуемо. Как говорил Кен Томпсон: «Всё сложное — это просто.» Иными словами, чем больше абстракций и “интеллекта” добавляется в систему, тем больше вероятность, что в ней найдётся неочевидный баг. Похоже, что даже в мире машинного обучения, “продакшен” неизбежно найдёт способ сломать элегантную теорию, особенно когда речь идет о точном следовании инструкциям в генерации кода. C3-Bench — это, конечно, полезный инструмент, но он лишь подтверждает старую истину: надеяться на идеальную работу сложной системы — наивно.
Что Дальше?
Представленный бенчмарк, C3-Bench, конечно, аккуратно выявляет, что существующие большие языковые модели для кода не всегда способны следовать инструкциям так, как хотелось бы теоретику. Удивительно? Нет. Каждая «революционная» технология, как известно, завтра станет техдолгом, требующим постоянной доработки и обхода найденных ограничений. Тесты — это, скорее, форма надежды, нежели гарантия, и C3-Bench это лишь подтверждает.
Очевидно, что простое увеличение размера модели не решит проблему. Более тонкая настройка открытых моделей, безусловно, дает временный выигрыш, но это лишь отодвигает неизбежное. Продакшен всегда найдет способ сломать элегантную теорию, заставив разработчиков вновь копаться в коде, пытаясь обойти очередную крайнюю ситуацию. Автоматизация, конечно, прекрасна, но уже виделись скрипты, удаляющие прод.
Поэтому, вероятно, будущее лежит не в создании идеальной модели, а в разработке инструментов, позволяющих эффективно отлаживать и контролировать поведение этих моделей в реальных условиях. То есть, в создании более изощренных способов борьбы с неизбежным хаосом. И, возможно, в принятии того факта, что код всегда будет немного «кривым», а задача программиста — находить способы, чтобы он работал по понедельникам.
Оригинал статьи: https://arxiv.org/pdf/2601.15879.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Робот, который видит, понимает и действует: новая эра общего назначения
- Квантовые сети для моделирования молекул: новый подход
2026-01-24 00:03