Автор: Денис Аветисян
В статье представлен унифицированный механизм ограничения для повышения стабильности обучения и улучшения исследования в процессе оптимизации политик для больших языковых моделей.
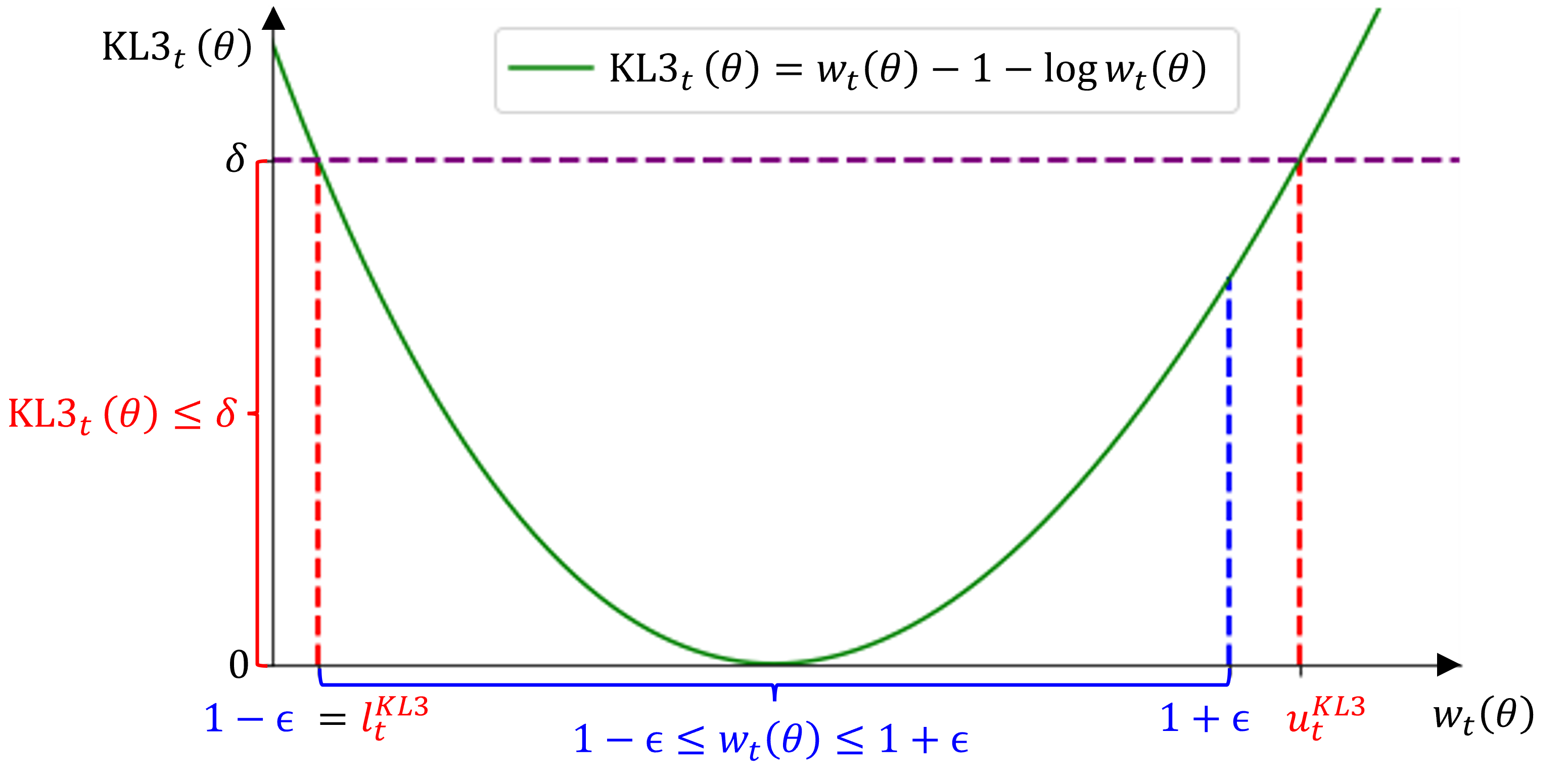
Исследование предлагает единую структуру для оценки расхождения политик в алгоритмах обучения с подкреплением, выделяя KL3-оценщик как ключевой фактор для обеспечения баланса между исследованием и стабильностью.
Несмотря на успехи обучения с подкреплением для больших языковых моделей, обеспечение стабильности и эффективности поиска оптимальной политики остается сложной задачей. В работе ‘A Unified Framework for Rethinking Policy Divergence Measures in GRPO’ предложен унифицированный подход к ограничению расхождения политик, объединяющий различные метрики, включая отношение правдоподобия и расхождение Кульбака-Лейблера KL. Ключевым результатом является идентификация оценки KL3 как эффективного ограничения, способствующего более сильному исследованию пространства действий и повышению стабильности обучения. Не откроет ли это путь к разработке более надежных и эффективных алгоритмов обучения с подкреплением для языковых моделей?
Вызов математического мышления для больших языковых моделей
Несмотря на впечатляющие возможности в обработке естественного языка, современные большие языковые модели (LLM) сталкиваются с серьезными трудностями при решении математических задач, требующих последовательных, многошаговых умозаключений. В то время как LLM превосходно справляются с распознаванием закономерностей и генерацией текста, выполнение сложных вычислений и логических выводов, необходимых для решения математических проблем, зачастую оказывается за пределами их возможностей. Проблемы возникают не только при работе с числовыми данными, но и при интерпретации условий задачи и применении соответствующих математических принципов. Это связано с тем, что LLM, как правило, обучаются на огромных объемах текстовых данных, в которых математические рассуждения представлены неявно, что затрудняет их обобщение и применение к новым, нестандартным задачам. Поэтому, несмотря на кажущуюся “умностью”, LLM часто нуждаются в дополнительных механизмах для эффективного решения даже относительно простых математических задач, требующих последовательного применения a^2 + b^2 = c^2 и других базовых принципов.
Традиционные методы решения математических задач, основанные на жестко заданных алгоритмах и шаблонах, зачастую демонстрируют ограниченную способность к обобщению. Исследования показывают, что при столкновении с задачами, отличающимися от тех, на которых модель обучалась — иными распределениями вероятностей или незнакомыми условиями — точность решения резко падает. Это связано с тем, что такие подходы не способны адаптироваться к новым ситуациям и извлекать общие принципы из разнородных данных. В связи с этим, все больше внимания уделяется разработке более устойчивых и гибких методов, способных к переносу знаний и эффективному решению задач в условиях неопределенности и изменяющихся данных, что является ключевым шагом на пути к созданию действительно интеллектуальных систем, способных к полноценному математическому мышлению.
Несмотря на впечатляющий прогресс в области больших языковых моделей, простое увеличение их размера не является панацеей для решения сложных математических задач. Исследования показывают, что, хотя масштабные модели демонстрируют определенные успехи, их способность к многоступенчатым рассуждениям остается ограниченной. Вместо слепого наращивания параметров, ключевым фактором достижения истинной математической грамотности представляется разработка более эффективных алгоритмов. Эти алгоритмы должны обеспечивать не просто запоминание решений, но и способность к логическому анализу, абстрагированию и построению доказательств, подобно тому, как это делает человек. Упор на оптимизацию алгоритмов позволит создавать модели, которые не просто “угадывают” ответы, а действительно понимают математические принципы и способны применять их к новым, ранее не встречавшимся задачам, даже при ограниченных вычислительных ресурсах.
Обучение с подкреплением для усиления рассуждений
Обучение с подкреплением (RL) представляет собой эффективный подход к тренировке больших языковых моделей (LLM) для оптимизации процессов принятия решений, что особенно важно для задач, требующих многошагового рассуждения. В отличие от традиционных методов обучения, где модель обучается на заранее размеченных данных, RL позволяет модели обучаться посредством взаимодействия со средой и получения обратной связи в виде вознаграждения или штрафа. Этот процесс позволяет LLM не только прогнозировать следующий токен, но и разрабатывать стратегии для достижения определенных целей, последовательно выполняя действия и оценивая их результаты. Такой подход позволяет значительно улучшить способность модели к решению сложных задач, требующих планирования и логического вывода.
Алгоритмы Proximal Policy Optimization (PPO) и Trust Region Policy Optimization (TRPO) широко используются для обучения моделей с подкреплением, однако требуют тщательной настройки гиперпараметров для обеспечения стабильности процесса обучения. Некорректный выбор параметров может привести к резким изменениям в политике агента, что приведет к нестабильности обучения и снижению производительности. PPO, в частности, использует обрезку коэффициента вероятности ( \hat{\pi}_t / \pi_t ) для ограничения отклонения новой политики от старой, в то время как TRPO использует ограничение на величину изменения политики, измеряемого с помощью KL-дивергенции. Оба подхода направлены на предотвращение слишком больших шагов в пространстве политик, что позволяет поддерживать стабильность обучения и улучшать сходимость.
Ограничение обновлений политики является критически важным для стабильности обучения с подкреплением (RL) при использовании больших языковых моделей (LLM). Методы, основанные на ограничении коэффициента (ratio-based clipping), предотвращают чрезмерные изменения в политике на каждом шаге обучения, обрезая вероятностное отношение новой и старой политики. Альтернативно, использование расхождения Кульбака-Лейблера (KL Divergence) позволяет измерять степень отклонения новой политики от предыдущей. Внедрение штрафов, пропорциональных KL-дивергенции D_{KL}(π_{old} || π_{new}), в функцию потерь эффективно ограничивает изменения политики и способствует более стабильному обучению. Оба подхода направлены на предотвращение резких изменений, которые могут привести к дестабилизации обучения и ухудшению производительности LLM.
Эффективное исследование с помощью приближенного доверительного региона GRPO
Групная относительная оптимизация политики (GRPO) обеспечивает эффективность использования памяти при работе с крупномасштабными языковыми моделями (LLM) за счет нормализации возвратов. Этот подход позволяет снизить вычислительные затраты и требования к памяти по сравнению с традиционными методами обучения с подкреплением. Однако, нормализация возвратов может привести к проблеме локальных оптимумов, где алгоритм застревает в субоптимальных решениях. Для преодоления этой проблемы требуется тщательное исследование пространства политики, чтобы избежать сходимости к локальным оптимумам и обеспечить поиск глобально оптимального решения. Недостаточная или неэффективная разведка может значительно ухудшить производительность модели, особенно в сложных задачах, требующих долгосрочного планирования и принятия решений.
Предложенный метод Approximate Trust Region GRPO использует KL3 Estimator в качестве легковесного суррогата для расхождения Кульбака-Лейблера (KL Divergence). KL3 Estimator, в отличие от точного вычисления D_{KL}(p||q), обеспечивает аппроксимацию с существенно меньшими вычислительными затратами. Это позволяет более эффективно оценивать ограничения доверительной области при обновлении политики, что особенно важно для масштабных языковых моделей. В результате, использование KL3 Estimator способствует стабильному исследованию пространства действий и снижает риск выхода за пределы доверительной области, обеспечивая более надежное обучение и улучшенную производительность.
Асимметричный клиппинг (Asymmetric Clipping) в алгоритме GRPO усиливает исследование пространства параметров, позволяя алгоритму совершать более значительные шаги в направлениях, показывающих перспективные результаты. Это достигается путем применения различных ограничений на величину обновления параметров в зависимости от их влияния на политику. В частности, обновления, приводящие к улучшению результатов, получают больший вес, а те, которые ухудшают результаты, — меньший. Такой подход позволяет ускорить обучение и повысить производительность на сложных задачах, требующих рассуждений, за счет более эффективного исследования и эксплуатации пространства поиска.
Эмпирическая валидация и производительность на бенчмарках
Эксперименты с моделями Qwen3-1.7B и Qwen3-8B, подвергнутыми тонкой настройке с использованием предложенных методов и обученными на наборе данных DAPO-Math-17k, показали существенное улучшение результатов на бенчмарках AIME2023, AIME2024 и AIME2025. Достигнутые показатели сопоставимы с результатами современных передовых методов решения математических задач, что подтверждает эффективность предложенного подхода к обучению и тонкой настройке языковых моделей для задач, требующих логического мышления и математических вычислений.
Метод адаптации с использованием низкого ранга (Low-Rank Adaptation, LoRA) позволяет существенно снизить вычислительные затраты и объем используемой памяти при обучении и развертывании моделей. LoRA замораживает предобученные веса модели и вводит небольшое количество обучаемых параметров низкого ранга, что значительно уменьшает количество параметров, требующих обновления во время обучения. Это снижает потребность в вычислительных ресурсах, ускоряет процесс обучения и позволяет эффективно развертывать модели на устройствах с ограниченными ресурсами, сохраняя при этом высокую производительность и качество результатов. Практическая реализация LoRA предполагает разложение матриц изменений весов на произведения матриц меньшего размера, что и обеспечивает сокращение числа параметров.
Использование разреженной бинарной функции вознаграждения обеспечивает четкий и лаконичный сигнал для агента обучения с подкреплением (RL), направляя его к правильным решениям и ускоряя процесс обучения. В данном контексте, функция вознаграждения выдает значение +1 за полностью корректное решение задачи и 0 во всех остальных случаях. Отсутствие промежуточных вознаграждений упрощает задачу для агента, фокусируя его исключительно на достижении конечной цели — получения правильного ответа. Такая схема способствует быстрой конвергенции и повышению эффективности обучения модели по сравнению с использованием более сложных или детализированных функций вознаграждения.
Перспективы и более широкие последствия
Данное исследование закладывает основу для создания более устойчивых и адаптируемых больших языковых моделей (LLM), способных решать сложные задачи рассуждения не только в математике, но и в различных других областях знаний. Показав принципиальную возможность эффективного обучения LLM с использованием обучения с подкреплением, работа открывает перспективы для применения этих моделей в научных исследованиях, автоматизированном анализе данных и других сферах, требующих логического мышления и решения проблем. Дальнейшее развитие этой технологии может привести к созданию интеллектуальных систем, способных самостоятельно выдвигать гипотезы, анализировать сложные взаимосвязи и делать обоснованные выводы, существенно расширяя возможности искусственного интеллекта за пределами узкоспециализированных задач.
Исследования показывают, что повышение эффективности языковых моделей возможно за счет модификации систем вознаграждения и интеграции специализированных знаний в конкретных областях. Традиционные функции вознаграждения, ориентированные на простое соответствие ответам, могут быть недостаточны для стимулирования сложных рассуждений. Альтернативные подходы, учитывающие не только правильность, но и креативность, логическую последовательность и полноту ответа, способны значительно улучшить производительность модели. Кроме того, включение в процесс обучения структурированных данных и экспертных знаний, характерных для определенной предметной области — например, медицинских протоколов или юридических норм — позволяет модели не только быстрее обучаться, но и демонстрировать более высокую степень обобщения и адаптации к новым, нестандартным задачам. Таким образом, комбинация инновационных функций вознаграждения и углубленного предметного обучения представляется перспективным путем к созданию более интеллектуальных и универсальных систем искусственного интеллекта.
Разработка эффективных алгоритмов обучения с подкреплением и техник масштабирования больших языковых моделей (LLM) представляется ключевым фактором для реализации полного потенциала искусственного интеллекта в различных областях. Успешное преодоление вычислительных сложностей и повышение эффективности обучения позволит LLM не только решать сложные задачи рассуждения, но и активно участвовать в научных открытиях, автоматизируя процессы анализа данных и выдвижения гипотез. Совершенствование алгоритмов, направленное на снижение требований к вычислительным ресурсам и времени обучения, откроет возможности для создания более доступных и масштабируемых систем искусственного интеллекта, способных решать широкий спектр задач, от автоматизации научных исследований до разработки новых технологий и оптимизации сложных процессов.
Представленная работа демонстрирует стремление к созданию элегантной и универсальной системы оптимизации политик для обучения больших языковых моделей. Авторы предлагают единый фреймворк с использованием механизма отсечения, что позволяет добиться большей стабильности и эффективности обучения. Этот подход особенно важен при работе с моделями, требующими тщательного баланса между исследованием и использованием уже полученных знаний. Как однажды заметил Карл Фридрих Гаусс: «Я не знаю, как мир устроен, но я знаю, что он должен быть прост». Простота и ясность предлагаемого фреймворка, заключающаяся в унификации различных мер расхождения политик, позволяет лучше понять и контролировать процесс обучения, обеспечивая надежность системы даже в сложных условиях. Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений.
Куда Далее?
Представленная работа выявляет не столько новую меру расхождения политик, сколько элегантную систематизацию существующих. Однако, упрощение — это всегда своего рода искажение. Ключевым остается вопрос: насколько предложенная унификация масштабируется за пределы контролируемой лабораторной среды, где параметры обучения тщательно подобраны? В реальных, шумных системах, где языковые модели сталкиваются с непредсказуемыми входными данными, простота может оказаться хрупкой.
Эффективность KL3-оценщика в стимулировании исследования не является самоцелью. Важнее понять, как это исследование влияет на общую структуру обучающейся системы. Недостаточно лишь «открыть» пространство политик; необходимо обеспечить его устойчивость и предсказуемость. Вопрос не в том, чтобы заставить модель действовать более разнообразно, а в том, чтобы гарантировать, что эта разнообразие служит четко определенной цели.
В конечном счете, настоящая проблема заключается не в оптимизации отдельных механизмов обрезки, а в создании саморегулирующейся экосистемы обучения. Системы, способной адаптироваться к изменяющимся условиям, находить баланс между исследованием и эксплуатацией, и, что самое главное, — избегать ловушек локальных оптимумов, которые неизбежно возникают в сложных языковых ландшафтах. Поиск такой системы — задача, требующая не только технических инноваций, но и глубокого понимания принципов самоорганизации.
Оригинал статьи: https://arxiv.org/pdf/2602.05494.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Квантовые амбиции: Иран вступает в гонку
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Федеративное обучение: баланс между конфиденциальностью и скоростью
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-07 09:05