Автор: Денис Аветисян
Исследователи разработали фреймворк Puzzle для оптимизации архитектуры моделей, демонстрируя значительное повышение эффективности вычислений при сохранении точности.
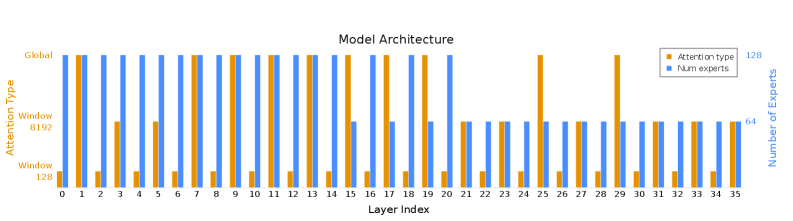
Представлен фреймворк Puzzle для нейронного архитектурного поиска и его применение к оптимизации модели gpt-oss-120B, что привело к созданию gpt-oss-puzzle-88B.
Повышение качества ответов больших языковых моделей (LLM) требует генерации более развернутых цепочек рассуждений, что, однако, значительно увеличивает вычислительные затраты. В работе «Extending Puzzle for Mixture-of-Experts Reasoning Models with Application to GPT-OSS Acceleration» представлен фреймворк Puzzle, основанный на нейронном архитектурном поиске, и его применение к модели gpt-oss-120B, в результате чего была получена gpt-oss-puzzle-88B — оптимизированная версия, демонстрирующая улучшенную эффективность инференса при сохранении или повышении точности. Полученные результаты показывают возможность значительного снижения стоимости инференса без ущерба для качества, но является ли предложенный подход универсальным решением для оптимизации LLM в различных контекстах и задачах?
Увядание иллюзий: вызовы масштабирования больших языковых моделей
Современные большие языковые модели, такие как gpt-oss-120B, демонстрируют впечатляющие возможности в обработке и генерации текста, превосходя многие предыдущие решения в задачах понимания языка и креативного письма. Однако, эта выдающаяся производительность достигается ценой значительных вычислительных ресурсов. Огромный размер этих моделей, измеряемый в миллиардах параметров, требует колоссальной памяти и вычислительной мощности для обучения и, особенно, для практического применения — инференса. Эта потребность в ресурсах становится серьезным препятствием для широкого внедрения подобных моделей, ограничивая их доступность для многих исследователей и организаций, а также усложняя развертывание в условиях ограниченных аппаратных возможностей или необходимости обработки больших объемов данных в реальном времени. Таким образом, несмотря на свой потенциал, высокая вычислительная стоимость остается ключевым фактором, сдерживающим повсеместное распространение передовых языковых моделей.
Традиционные методы масштабирования больших языковых моделей часто сталкиваются с ограничениями, обусловленными квадратичной сложностью механизмов внимания, таких как Self-Attention. Этот процесс требует вычислений, растущих пропорционально квадрату длины входной последовательности O(n^2), что делает обработку длинных текстов крайне затратной по ресурсам. Особенно значительную нагрузку создает необходимость хранения и обработки KV-кэша — матрицы, содержащей ключи и значения для каждого токена в последовательности. По мере увеличения длины последовательности, размер KV-кэша также растет квадратично, что приводит к экспоненциальному увеличению потребления памяти и снижению скорости инференса. В результате, существующие подходы к масштабированию часто достигают плато, не позволяя эффективно использовать потенциал более крупных моделей для обработки задач, требующих анализа длинных контекстов.
Основная сложность в масштабировании больших языковых моделей заключается в поиске баланса между их способностью к обучению и эффективностью обработки запросов в реальном времени. Несмотря на впечатляющие результаты, демонстрируемые моделями вроде gpt-oss-120B, их практическое применение ограничивается высокими вычислительными затратами. Для широкого внедрения необходимо обеспечить не только высокую точность ответов, но и возможность быстрого получения результатов при минимальных затратах энергии и ресурсов. Решение этой проблемы — ключ к созданию доступных и эффективных инструментов обработки естественного языка для самых разнообразных приложений, от виртуальных ассистентов до систем автоматического перевода и анализа больших объемов текста.
Puzzle: декомпозиция как путь к эффективности больших языковых моделей
Puzzle представляет собой фреймворк для поиска архитектуры нейронных сетей (NAS), ориентированный на оптимизацию эффективности инференса больших языковых моделей (LLM). В отличие от традиционных монолитных подходов к проектированию LLM, Puzzle предлагает декомпозированный подход, позволяющий исследовать и оптимизировать отдельные вычислительные блоки модели. Это достигается путем разделения LLM на составные части и проведения поиска оптимальной конфигурации этих блоков для достижения максимальной производительности и снижения вычислительных затрат при сохранении необходимой точности. Такой подход позволяет преодолеть ограничения, связанные с поиском оптимальной архитектуры в целостном пространстве, и обеспечивает более гибкую и эффективную оптимизацию.
Методика Puzzle использует целочисленное линейное программирование (ILP), разновидность математического программирования, для систематического исследования огромного пространства архитектурных конфигураций больших языковых моделей (LLM). В рамках ILP, параметры, определяющие структуру LLM, такие как типы и количество вычислительных блоков, представлены в виде целочисленных переменных. Решение задачи ILP позволяет определить оптимальную комбинацию этих блоков, максимизирующую эффективность вычислений при заданных ограничениях по производительности и ресурсам. Использование ILP обеспечивает гарантированно оптимальное решение в пределах заданного пространства поиска, в отличие от эвристических методов, которые могут приводить к субоптимальным результатам. По сути, ILP выступает в роли формального инструмента для автоматического проектирования архитектуры LLM.
Ключевым аспектом Puzzle является методика оценки влияния изменений в архитектуре посредством Replace-1-Block Scoring. Данный подход предполагает последовательную замену отдельных вычислительных блоков в модели и оценку результирующего изменения в производительности. Вместо переобучения всей модели после каждого изменения, Puzzle использует аппроксимацию для оценки влияния только одного блока, что значительно снижает вычислительные затраты. Оценка производится на небольшом подмножестве данных, позволяя быстро и эффективно идентифицировать архитектурные модификации, приводящие к улучшению эффективности вывода, без значительных затрат на переобучение и валидацию полной модели. Данный метод позволяет Puzzle эффективно исследовать пространство архитектурных решений и находить оптимальные конфигурации.

Оптимизация с помощью MoE и оценок на основе активаций: где прячется реальная эффективность?
Архитектура Puzzle эффективно использует слои Mixture of Experts (MoE) для увеличения емкости модели без пропорционального увеличения вычислительных затрат. В отличие от традиционных плотных моделей, где каждый параметр участвует в каждой операции, слои MoE маршрутизируют каждый токен ввода только к подмножеству экспертов — небольшим, специализированным подмоделям. Это позволяет значительно увеличить общее количество параметров модели (и, следовательно, ее потенциальную емкость) без линейного увеличения объема вычислений, необходимых для обработки каждого токена. По сути, это достигается за счет параллелизации вычислений и активации только части параметров для каждого конкретного ввода, что обеспечивает более эффективное использование вычислительных ресурсов.
Метод оценки на основе активаций позволяет более точно определить приоритетность слоев для оптимизации в моделях, использующих MoE (Mixture of Experts). Вместо равномерного применения методов оптимизации ко всем слоям, данный подход анализирует величину активаций в каждом слое во время работы модели. Слои с более высокими значениями активаций рассматриваются как наиболее значимые для производительности и точности модели, и, следовательно, получают приоритет при оптимизации, например, при применении Expert Pruning. Это позволяет целенаправленно снизить размер модели и повысить скорость инференса, сохраняя или даже улучшая общую производительность.
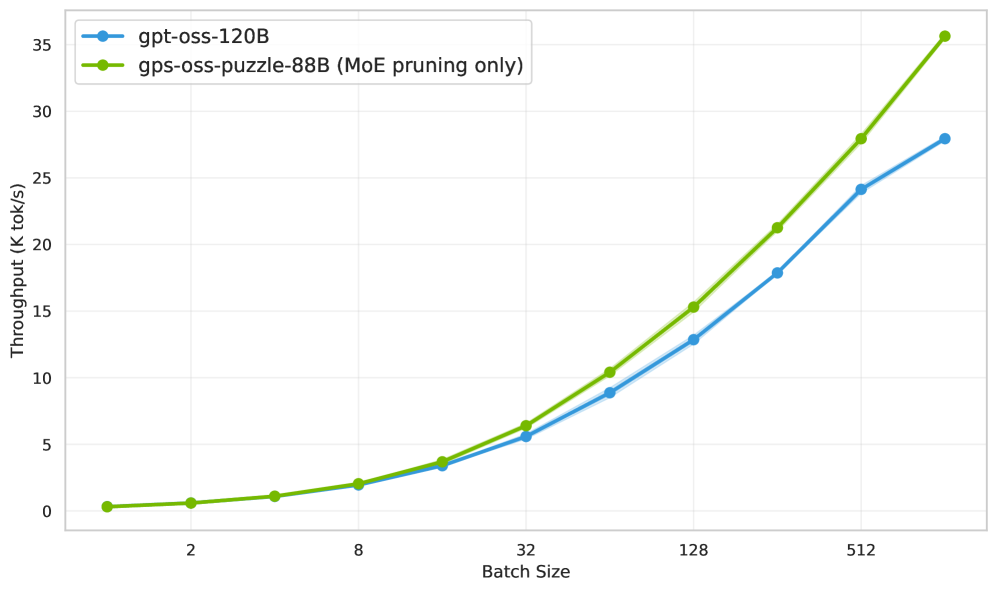
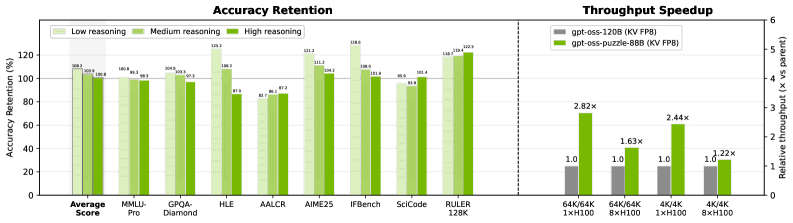
Применение экспертной обрезки (Expert Pruning) становится возможным благодаря оптимизации слоев с использованием MoE и активационной оценке. Этот подход позволяет целенаправленно уменьшать размер модели, удаляя менее значимые эксперты, что приводит к повышению скорости инференса. В сценарии обработки последовательностей длиной 64K/64K модель Puzzle демонстрирует увеличение пропускной способности на 1.63x по сравнению с gpt-oss-120B, подтверждая эффективность данной стратегии оптимизации.
Развертывание и производительность gpt-oss-puzzle-88B: от теории к практике
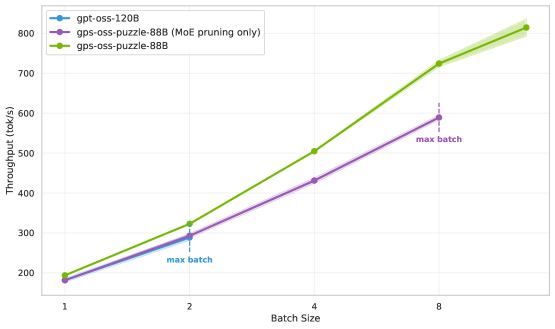
В результате применения методики Puzzle к модели gpt-oss-120B была создана значительно оптимизированная производная — gpt-oss-puzzle-88B, готовая к непосредственному развертыванию. Этот процесс позволил существенно уменьшить размер модели без значительной потери в качестве генерации текста. Оптимизация, достигнутая благодаря Puzzle, открывает возможности для более эффективного использования вычислительных ресурсов и снижения затрат на обслуживание. gpt-oss-puzzle-88B представляет собой практическое решение для широкого спектра задач, требующих обработки естественного языка, и является важным шагом в направлении создания доступных и эффективных больших языковых моделей.
Квантование FP8, поддерживаемое технологией KV Scales, представляет собой эффективный метод дальнейшей компрессии больших языковых моделей без существенной потери точности. Этот подход позволяет снизить требования к памяти и вычислительным ресурсам, делая развертывание и использование моделей, таких как gpt-oss-puzzle-88B, более экономичным и доступным. KV Scales оптимизирует процесс квантования, фокусируясь на ключевых компонентах модели — значениях ключей и запросов — для минимизации влияния на производительность и сохранения высокого качества генерируемого текста. Использование FP8, в сочетании с KV Scales, открывает возможности для более широкого применения мощных языковых моделей на различных аппаратных платформах и в условиях ограниченных ресурсов.
Модель gpt-oss-puzzle-88B демонстрирует значительное увеличение производительности и снижение задержки, что подтверждает её практическую применимость. В частности, в сценарии 64K/64K, наблюдается 2,82-кратное увеличение пропускной способности на одной GPU H100. Это означает, что модель способна обрабатывать значительно больший объем данных за единицу времени, обеспечивая более быструю и эффективную работу. Такой прирост производительности особенно важен для задач, требующих обработки больших объемов текста, таких как машинный перевод, генерация контента и анализ данных, делая gpt-oss-puzzle-88B перспективным решением для широкого спектра приложений.
Долгосрочное мышление: рассуждения в длинном контексте и будущие направления развития
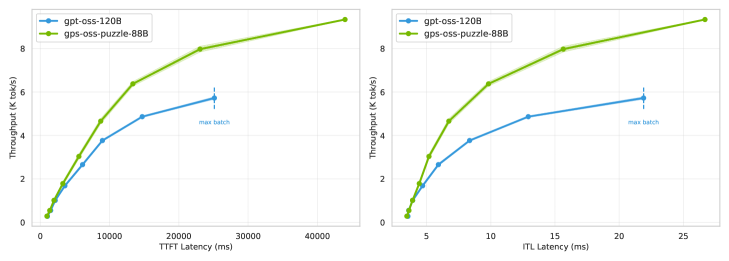
Модель gpt-oss-puzzle-88B продемонстрировала значительное улучшение в задачах, требующих рассуждений на основе длинных контекстов, что подтверждено результатами тестирования на AA-LCR Benchmark. Данное достижение свидетельствует о способности модели эффективно обрабатывать и использовать информацию из расширенных последовательностей данных. В ходе экспериментов было установлено, что gpt-oss-puzzle-88B способна извлекать релевантную информацию и делать обоснованные выводы даже при работе с очень большими объемами текста, что открывает новые возможности для решения сложных задач в области обработки естественного языка и искусственного интеллекта.
Для улучшения понимания длинных контекстов применяются инновационные методы, такие как YaRoPE и Window Attention. YaRoPE, представляющий собой усовершенствованную версию RoPE (Rotary Positional Embeddings), позволяет более эффективно кодировать позиционную информацию в длинных последовательностях, что критически важно для сохранения контекста. В свою очередь, Window Attention ограничивает область внимания модели, фокусируясь на наиболее релевантных частях входной последовательности, что снижает вычислительные затраты и повышает эффективность обработки длинных текстов. Комбинация этих техник позволяет моделям, таким как gpt-oss-puzzle-88B, значительно улучшить результаты в задачах, требующих анализа и обработки обширных объемов информации, демонстрируя потенциал для дальнейшего развития в области обработки естественного языка.
В будущем исследования сосредоточатся на применении обучения с подкреплением для динамической оптимизации архитектурных решений больших языковых моделей и адаптации к различным рабочим нагрузкам. Такой подход призван расширить границы эффективности и способности к рассуждению. Показательные результаты, полученные в ходе тестирования gpt-oss-puzzle-88B с использованием KV FP8, демонстрируют достижение 108.2% точности от gpt-oss-120B при незначительных затратах на логические операции, что указывает на перспективность данной стратегии для создания более мощных и экономичных систем искусственного интеллекта.
Данное исследование, демонстрирующее оптимизацию gpt-oss-120B посредством фреймворка Puzzle, закономерно вписывается в канву вечной борьбы за эффективность. Авторы, словно алхимики, пытаются выжать максимум производительности из существующей модели, не жертвуя точностью. Это напоминает о словах Дональда Кнута: «Оптимизация преждевременна — корень всех зол». Порой, кажется, что бесконечные поиски идеальной архитектуры — это лишь оттягивание неизбежного: рано или поздно, продакшен найдёт способ сломать даже самую элегантную теорию. И неважно, насколько тщательно подобраны параметры quantization или long-context attention — всегда найдется пользователь, который заставит систему пасть, демонстрируя, что настоящая оптимизация — это искусство управления хаосом.
Что дальше?
Представленная работа, безусловно, демонстрирует возможности автоматизированного поиска архитектур для оптимизации больших языковых моделей. Однако, опыт подсказывает, что каждая «оптимизация», каким бы элегантным ни казался алгоритм Puzzle, неминуемо породит новый вид техдолга. Ускорение вывода — это хорошо, но всегда найдётся способ загнать модель в ещё более сложные условия эксплуатации, где оптимизация окажется недостаточной.
Акцент на gpt-oss-120B, разумеется, понятен, но возникает вопрос о масштабируемости самого подхода. Автоматический поиск архитектур требует ресурсов, и не факт, что с ростом моделей эти ресурсы не станут непомерными. Более того, утверждения о «поддержании или улучшении точности» всегда требуют тщательной проверки в реальных, не лабораторных условиях. Если тесты зелёные — значит, они проверяют лишь то, что запланировано проверить.
Вполне вероятно, что следующие шаги в этой области будут связаны с поиском компромисса между автоматизацией и ручной настройкой. Полностью автоматизированные решения, возможно, останутся уделом исследовательских лабораторий, в то время как в продакшене всё равно придётся полагаться на опыт инженеров. И это, пожалуй, неплохо. Всё это уже было в 2012-м, только называлось иначе.
Оригинал статьи: https://arxiv.org/pdf/2602.11937.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Видеомонтаж без следов: Новый подход к удалению и вставке объектов
- Моделирование кровотока мозга: новый взгляд на скорость и точность
- Память как навык: как ИИ научился удерживать контекст
- Искусственный глаз: Как отличить реальное изображение от сгенерированного ИИ
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Рассуждения на графах: как большие языковые модели учатся видеть мир
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Квантовая магия: Революция нулевого уровня!
- Раскрывая потенциал языковых моделей: новый взгляд на оценку
2026-02-14 17:57