Автор: Денис Аветисян
Исследователи предлагают инновационную систему обслуживания больших языковых моделей, оптимизирующую использование памяти для повышения производительности и энергоэффективности.
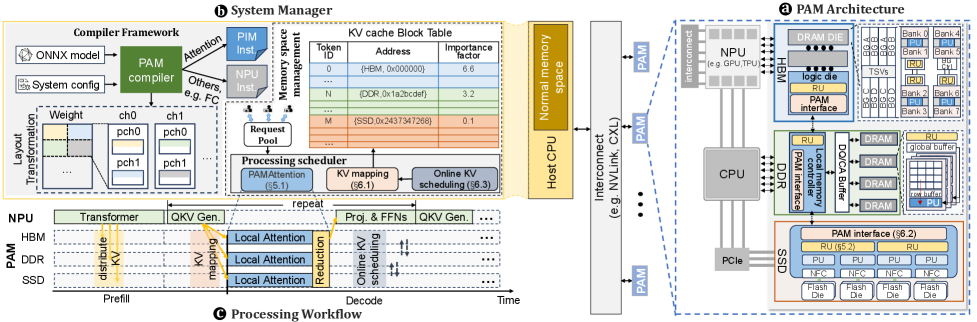
Предлагаемая система PAM использует гетерогенную память и парадигму обработки данных непосредственно в памяти для эффективного управления KV-кэшем и вычислений механизма внимания.
Растущие требования к пропускной способности и емкости памяти становятся серьезным препятствием для эффективного обслуживания больших языковых моделей (LLM). В данной работе, посвященной системе ‘PAM: Processing Across Memory Hierarchy for Efficient KV-centric LLM Serving System’, предложен инновационный подход, использующий гетерогенные устройства памяти и парадигму обработки данных непосредственно в памяти для оптимизации операций с кэшем ключей-значений (KV) и вычислений механизма внимания. Предлагаемая система PAM обеспечивает баланс между высокой пропускной способностью и масштабируемой емкостью, используя контекстную локальность данных и алгоритм PAMattention. Сможет ли данный подход стать основой для создания экономичных и высокопроизводительных систем обслуживания LLM нового поколения?
Узкое Место Современного Вывода: Цена Сложности
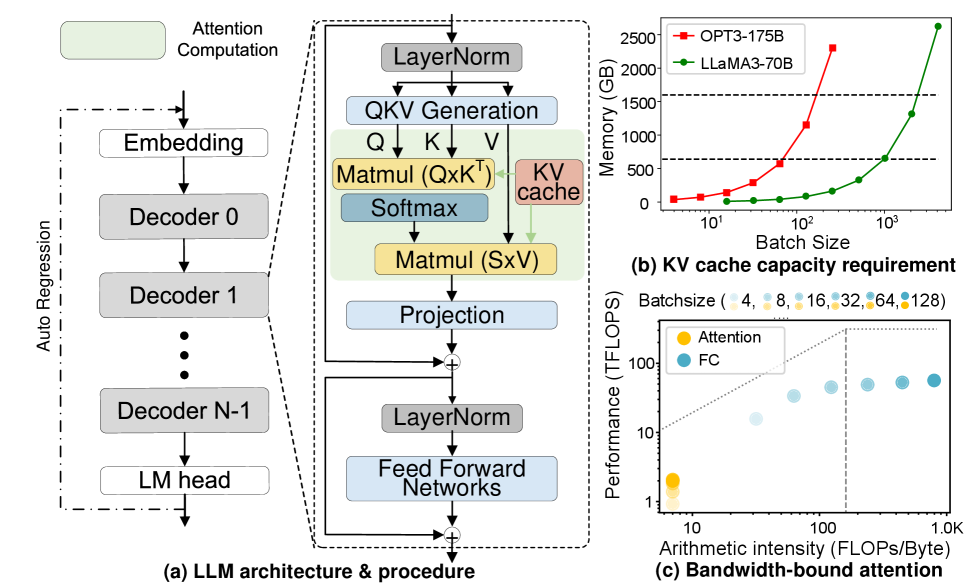
Современные большие языковые модели (БЯМ) стремительно меняют ландшафт искусственного интеллекта, однако эта трансформация сопряжена с экспоненциальным ростом вычислительных требований. По мере увеличения числа параметров и сложности архитектур, потребность в вычислительных ресурсах, необходимых для обучения и, особенно, для инференса, возрастает в геометрической прогрессии. Это создает серьезные трудности для широкого внедрения БЯМ, поскольку доступ к необходимым ресурсам становится все более ограниченным и дорогостоящим. Прогресс в области аппаратного обеспечения, такого как специализированные ускорители, лишь частично компенсирует эту тенденцию, подчеркивая необходимость разработки инновационных алгоритмов и методов оптимизации, способных эффективно использовать существующие ресурсы и снижать общую вычислительную нагрузку.
Современные подходы к выводу заключений большими языковыми моделями (LLM) сталкиваются с существенным ограничением, обусловленным пропускной способностью иерархии памяти. Проблема заключается в том, что LLM оперируют огромными объемами данных, и скорость, с которой процессор может получать доступ к этим данным из оперативной памяти и, особенно, из более медленных уровней памяти (таких как твердотельные накопители), становится узким местом. Несмотря на постоянное увеличение вычислительной мощности процессоров, она не успевает за экспоненциальным ростом размеров моделей и объемов обрабатываемой информации. В результате, большая часть времени тратится не на сами вычисления, а на ожидание данных, что существенно ограничивает скорость обработки запросов и делает масштабирование LLM крайне сложной задачей. Эта неспособность эффективно использовать доступную вычислительную мощность препятствует дальнейшему развитию и внедрению LLM в реальные приложения.
Размер так называемого KV-кэша, являющегося ключевым элементом эффективного декодирования в больших языковых моделях, становится все более критичным фактором, ограничивающим производительность. Этот кэш хранит информацию о предыдущих токенах, позволяя модели быстро предсказывать следующие, однако его объем экспоненциально растет с увеличением длины контекста и размера модели. В результате, доступ к данным в KV-кэше становится узким местом, поскольку пропускная способность памяти не успевает за потребностями вычислений. Поэтому, для преодоления этого препятствия, разрабатываются инновационные подходы, направленные на оптимизацию хранения и доступа к данным в KV-кэше, включая квантизацию, разреженность и эффективные алгоритмы кэширования, чтобы обеспечить масштабируемость и производительность будущих языковых моделей.
Невозможность преодоления данного узкого места в производительности ставит под вопрос дальнейшее развитие больших языковых моделей (LLM). По мере увеличения сложности решаемых задач и объемов обрабатываемого контекста, потребность в вычислительных ресурсах растет экспоненциально. Если не разработать эффективные методы оптимизации и преодоления ограничений пропускной способности памяти, дальнейшее масштабирование LLM станет экономически и технически нецелесообразным. Это означает, что потенциал LLM в решении сложных задач, таких как глубокий анализ данных, создание детализированных сценариев и поддержание содержательных диалогов, останется нереализованным. Дальнейшие инновации в архитектуре моделей и методах вычислений критически необходимы для обеспечения устойчивого развития и широкого применения LLM в будущем.
PAM: Решение, Переносящее Вычисления Ближе к Данным
Обработка в памяти (PIM) является ключевым компонентом PAM, позволяющим выполнять вычисления непосредственно внутри устройств памяти. Традиционные архитектуры требуют перемещения данных между памятью и процессором, что создает узкое место и увеличивает задержки. PIM устраняет это ограничение, интегрируя вычислительные элементы непосредственно в чипы памяти, что позволяет выполнять операции над данными, не извлекая их из памяти. Это значительно снижает потребление энергии и задержки, а также повышает пропускную способность, поскольку данные не нужно перемещать по шинам данных. Реализация PIM включает в себя как цифровые, так и аналоговые схемы, адаптированные для выполнения определенных типов вычислений, таких как умножение матриц, непосредственно в памяти.
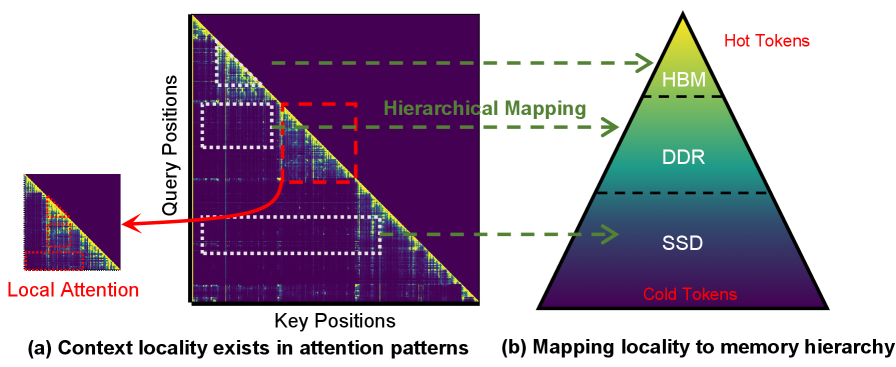
Архитектура PAM использует гетерогенную память, распределяя данные ключ-значение (KV) между различными типами памяти для оптимизации производительности и масштабируемости. В частности, часто используемые KV-токены размещаются в памяти High Bandwidth Memory (HBM) для обеспечения максимальной пропускной способности и минимальной задержки. Более редкие данные хранятся в оперативной памяти DDR, а для расширения общей емкости и хранения менее часто используемых данных используется твердотельная память SSD. Такое распределение позволяет эффективно использовать ресурсы каждого типа памяти и оптимизировать доступ к данным в процессе инференса больших языковых моделей.
Многоуровневая PIM (Layered PIM) реализует иерархическую структуру памяти, распределяя данные ключей и значений (KV) по различным типам памяти с учетом частоты их использования. Наиболее часто запрашиваемые KV-токены размещаются в высокоскоростной памяти HBM для обеспечения минимальной задержки доступа. Менее часто используемые данные хранятся в более емких, но медленных типах памяти, таких как DDR и твердотельные накопители (SSD). Такой подход позволяет оптимизировать производительность за счет быстрого доступа к критически важным данным, одновременно расширяя общую емкость системы для хранения больших языковых моделей и их рабочих нагрузок.
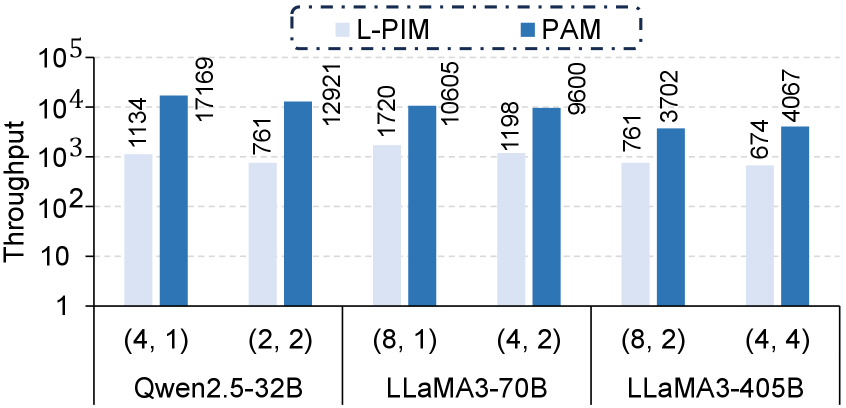
Архитектура PAM значительно снижает задержку и увеличивает пропускную способность при выводе LLM за счет стратегического размещения вычислений непосредственно рядом с данными. В ходе тестирования было продемонстрировано, что PAM обеспечивает до 26-кратного улучшения производительности по сравнению с существующими системами, что обусловлено минимизацией необходимости перемещения данных между памятью и процессором. Данное повышение эффективности достигается за счет выполнения операций непосредственно в памяти, что позволяет избежать узких мест, связанных с традиционными архитектурами фон Неймана и значительно ускорить обработку больших объемов данных, характерных для современных языковых моделей.
Оптимизация Размещения и Доступа к Данным Ключ-Значение
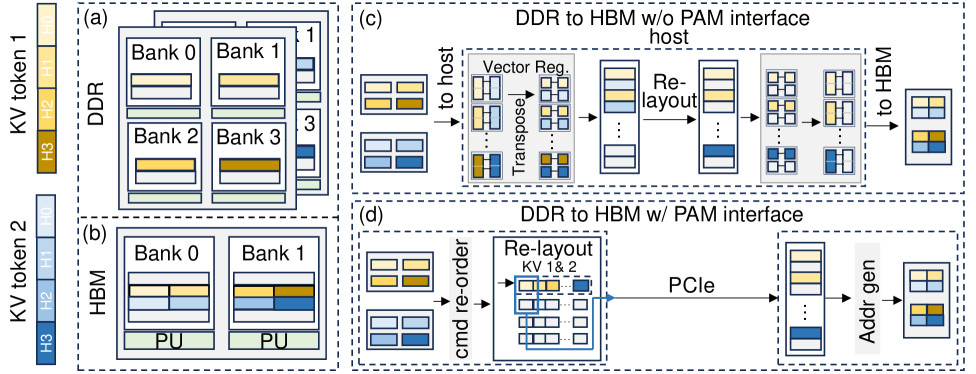
В PAM используется KV-планирование (KV Scheduling) — стратегия динамического размещения KV-токенов между различными уровнями памяти на основе их важности и паттернов доступа. Эта стратегия позволяет перемещать наиболее часто используемые токены в более быстрые уровни памяти (например, SRAM), а менее востребованные — в более медленные (например, DRAM или даже NVMe SSD). Определение важности токенов и прогнозирование паттернов доступа осуществляется на основе статистического анализа истории использования данных, что позволяет оптимизировать использование пропускной способности памяти и снизить задержки при вычислениях, особенно в задачах, связанных с вниманием (attention mechanisms).
Оптимизация размещения данных ключ-значение (KV) включает в себя методы межпроцессорного планирования KV (Inter-device KV Scheduling) и внутрипроцессорного отображения KV (Intra-device KV Mapping). Межпроцессорное планирование распределяет KV-токены между различными вычислительными устройствами, стремясь минимизировать коммуникационные издержки и обеспечить баланс нагрузки. Внутрипроцессорное отображение, в свою очередь, оптимизирует размещение данных внутри каждого устройства, учитывая особенности архитектуры памяти и паттерны доступа. Комбинированное применение этих техник позволяет эффективно использовать доступные ресурсы памяти и повысить общую производительность системы за счет сокращения времени доступа к данным.
Эффективность обработки данных в системах, использующих механизм внимания, значительно повышается за счет использования принципа локальности контекста. Этот принцип основан на статистической закономерности, согласно которой токены, к которым осуществлялся доступ в недавнем прошлом, с высокой вероятностью будут повторно использованы в ближайшем будущем. Соответственно, алгоритмы размещения данных, оптимизированные для сохранения недавно использованных токенов в быстродоступных слоях памяти, позволяют снизить задержки при доступе к данным и повысить общую пропускную способность системы. Это достигается за счет минимизации необходимости обращения к более медленным уровням памяти, что особенно важно для задач, требующих высокой скорости обработки больших объемов данных, таких как обработка естественного языка и компьютерное зрение.
PAMattention использует выделенные блоки редукции (Reduction Units) для повышения параллелизма и эффективности вычислений механизма внимания. Вместо последовательного суммирования весов внимания, блоки редукции позволяют выполнять эту операцию параллельно для различных частей входных данных, значительно сокращая время вычислений. Такой подход особенно эффективен при обработке больших последовательностей, где стандартные методы суммирования становятся узким местом. Выделенные блоки редукции оптимизированы для операций накопления и суммирования, что обеспечивает более высокую пропускную способность и снижает задержки при вычислении контекстных векторов.
Масштабирование LLM с Использованием Параллелизма на Уровне Системы
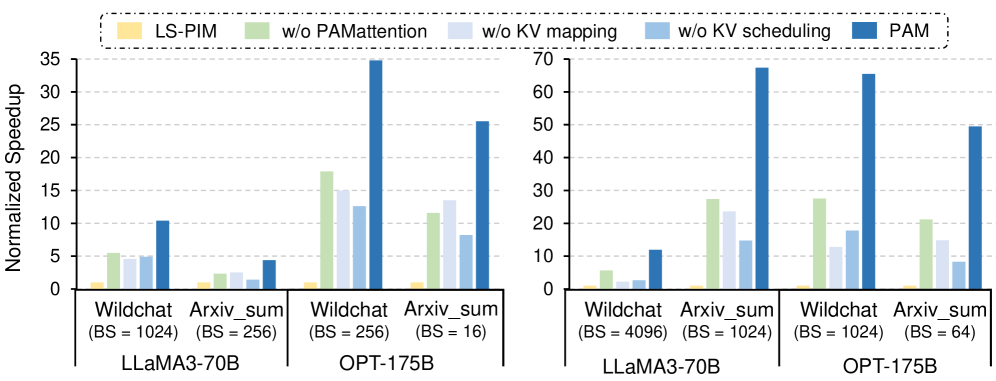
Система PAM не является заменой существующим методам параллелизации, таким как тензорный и конвейерный параллелизм, а эффективно интегрируется с ними для достижения максимальной пропускной способности. Вместо того чтобы полностью перестраивать процесс, PAM использует сильные стороны этих проверенных техник, оптимизируя взаимодействие между ними и устраняя узкие места. Благодаря такому подходу, система способна более эффективно распределять вычислительную нагрузку между доступными ресурсами, значительно повышая общую производительность больших языковых моделей. В результате, существующая инфраструктура может быть использована более полно, что позволяет запускать и обслуживать модели, требующие больших объемов памяти и вычислительной мощности, без необходимости дорогостоящего обновления оборудования.
Для достижения повышенной производительности при работе с большими языковыми моделями (LLM) используются оптимизированные алгоритмы FlashAttention и FlashDecoding. Эти алгоритмы специально разработаны для снижения требований к памяти, что является критическим фактором при работе с огромными объемами данных, характерными для современных LLM. В отличие от традиционных методов, FlashAttention и FlashDecoding эффективно используют аппаратные ресурсы, минимизируя перемещение данных между памятью и процессором. Это приводит к значительному ускорению вычислений и позволяет запускать более крупные и сложные модели на существующем оборудовании, существенно расширяя возможности в области искусственного интеллекта и открывая новые горизонты для научных исследований и разработки передовых приложений.
Разработанная система PAM позволяет преодолеть узкое место, связанное с пропускной способностью памяти, что открывает возможность развертывания более крупных и мощных языковых моделей на существующем оборудовании. Исследования показали значительное увеличение производительности: на модели Qwen2.5-32B достигнут прирост пропускной способности в 7.20 раза, а на LLaMA3-70B — в 6.93 раза по сравнению с системой vLLM-offloading. Это означает, что сложные вычислительные задачи, ранее требовавшие дорогостоящего оборудования, теперь могут быть эффективно решены на стандартных платформах, что существенно расширяет возможности применения больших языковых моделей в различных областях, от разработки продвинутых чат-ботов до научных исследований.
Возможности, открываемые данной масштабируемостью, простираются далеко за пределы стандартных задач. Повышение производительности, достигающее 24.53-кратного ускорения для модели OPT-175B по сравнению с vLLM-offloading, позволяет решать задачи, ранее недоступные из-за вычислительных ограничений. Это открывает новые горизонты для создания продвинутых чат-ботов, способных к более сложным и осмысленным диалогам, а также для проведения научных исследований в таких областях, как геномика, материаловедение и астрофизика, где анализ огромных объемов данных требует колоссальных вычислительных ресурсов. Такое увеличение производительности не просто оптимизирует существующие приложения искусственного интеллекта, но и делает возможным создание принципиально новых, более сложных и эффективных инструментов для решения широкого спектра задач.
Будущее Ориентированного на Память Искусственного Интеллекта
Предлагаемая архитектура PAM знаменует собой кардинальный сдвиг в парадигме искусственного интеллекта, перенося вычислительные процессы непосредственно к данным, а не наоборот. Традиционно, данные перемещаются между памятью и процессором, создавая узкое место и ограничивая производительность. PAM, напротив, внедряет вычислительные элементы в саму память, минимизируя необходимость в передаче данных и значительно ускоряя обработку информации. Этот подход позволяет существенно повысить эффективность и масштабируемость систем искусственного интеллекта, открывая возможности для решения задач, ранее недоступных из-за ограничений пропускной способности и энергопотребления. Подобная архитектура позволяет не только сократить задержки, но и снизить энергозатраты, что особенно важно для ресурсоемких приложений, таких как обработка больших данных и машинное обучение.
Перспективные исследования в области памяти-ориентированного искусственного интеллекта (PAM) сосредоточены на разработке адаптивных алгоритмов планирования, способных динамически реагировать на меняющиеся нагрузки и паттерны доступа к данным. Эти алгоритмы призваны оптимизировать порядок выполнения операций, максимально используя преимущества вычислений вблизи памяти. В отличие от традиционных подходов с фиксированным планированием, адаптивные алгоритмы будут способны перестраивать график выполнения задач в реальном времени, учитывая текущую ситуацию с использованием памяти и требования к производительности. Это позволит значительно повысить эффективность работы систем искусственного интеллекта, особенно в сценариях с высокой степенью изменчивости и непредсказуемости нагрузки, и обеспечит более гибкое и эффективное использование ресурсов памяти.
Исследования новых технологий памяти и архитектур способны значительно усилить преимущества, предоставляемые концепцией памяти-ориентированного искусственного интеллекта. В частности, разработанная система PAM демонстрирует впечатляющий прирост производительности, достигая 48.56-кратного увеличения пропускной способности в масштабируемых системах. Этот значительный скачок обусловлен оптимизацией доступа к данным и переносом вычислений ближе к памяти, что позволяет сократить задержки и повысить эффективность обработки информации. Дальнейшее развитие в этой области обещает не только ускорить выполнение задач искусственного интеллекта, но и снизить энергопотребление, открывая новые возможности для создания более мощных и энергоэффективных систем.
Перспективная архитектура PAM открывает новые возможности для искусственного интеллекта, преодолевая узкие места, связанные с традиционными иерархиями памяти. Этот подход позволяет значительно повысить производительность, минимизируя задержки при доступе к данным и обеспечивая более эффективную обработку информации. При этом, инновационная конструкция демонстрирует впечатляющую энергоэффективность, снижая энергопотребление на 53.1% — 92.7% по сравнению с технологией vLLM-offloading. Важно отметить, что реализация данной архитектуры не требует значительного увеличения площади чипа, составляя всего 9.25% от площади типичной HBM3, что делает её привлекательной для широкого спектра приложений и способствует дальнейшему развитию ИИ-систем.
В представленной работе авторы стремятся к оптимизации обслуживания больших языковых моделей, фокусируясь на управлении кэшем KV и вычислениях механизма внимания. Эта задача неизбежно ведёт к усложнению системы, но истинная эффективность достигается через простоту и элегантность решений. Как однажды заметил Дональд Дэвис: «Сложность — это тщеславие. Ясность — милосердие». PAM, предлагая парадигму ‘обработки через память’, демонстрирует стремление к этой ясности, оптимизируя доступ к данным и снижая вычислительную нагрузку. Подобный подход позволяет избежать излишней сложности, характерной для многих современных систем, и сосредоточиться на ключевых аспектах производительности и энергоэффективности.
Куда Далее?
Представленная работа, оптимизируя управление кэшем KV и вычисления внимания, лишь обозначила горизонт, а не достигла его. Попытка примирить гетерогенную память и парадигму вычислений внутри памяти, несомненно, продуктивна, однако вопрос о масштабируемости остается открытым. Достаточно ли оптимизации на уровне кэша, или неизбежно возникнет необходимость в радикальном пересмотре архитектуры внимания — это вопрос, требующий дальнейшего исследования. Ненужное усложнение архитектуры ради кажущейся эффективности — это насилие над вниманием, и необходимо помнить об этом.
Следующим шагом видится не просто ускорение существующих моделей, а разработка принципиально новых, учитывающих физические ограничения памяти и энергопотребления. Поиск компромисса между точностью и эффективностью — это не техническая, а философская задача. Настоящий прогресс не в увеличении размеров моделей, а в их интеллектуальной концентрации — плотность смысла, новый минимализм.
Игнорировать контекстную локальность — значит сознательно строить неэффективные системы. Будущие исследования должны сосредоточиться на динамическом управлении памятью, учитывающем паттерны доступа к данным. Простота — высшая форма сложности, и только отбрасывая ненужное, можно приблизиться к истинной элегантности и эффективности.
Оригинал статьи: https://arxiv.org/pdf/2602.11521.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Разреженность и масштаб: семейство языковых моделей Trinity
- Искры инноваций: Как генеративный ИИ помогает организациям адаптироваться в эпоху поликризиса
- Зона ближайшего развития LLM: где синтез данных взламывает границы разума.
- Квантовая физика: От хаоса к пониманию
- Быстрая оценка эффективности клинических испытаний: новый подход
- Квантовый разум: Новая эра языковых моделей
- Языковые модели и границы возможного: что делает язык человеческим?
- Обучение в контексте: новый взгляд на персонализацию образования
- Ищем закономерности: Новый пакет TSQCA для R
2026-02-14 11:16