Автор: Денис Аветисян
Исследователи предлагают эффективный метод повышения скорости работы больших языковых моделей при обработке длинных текстов, не жертвуя качеством генерации.
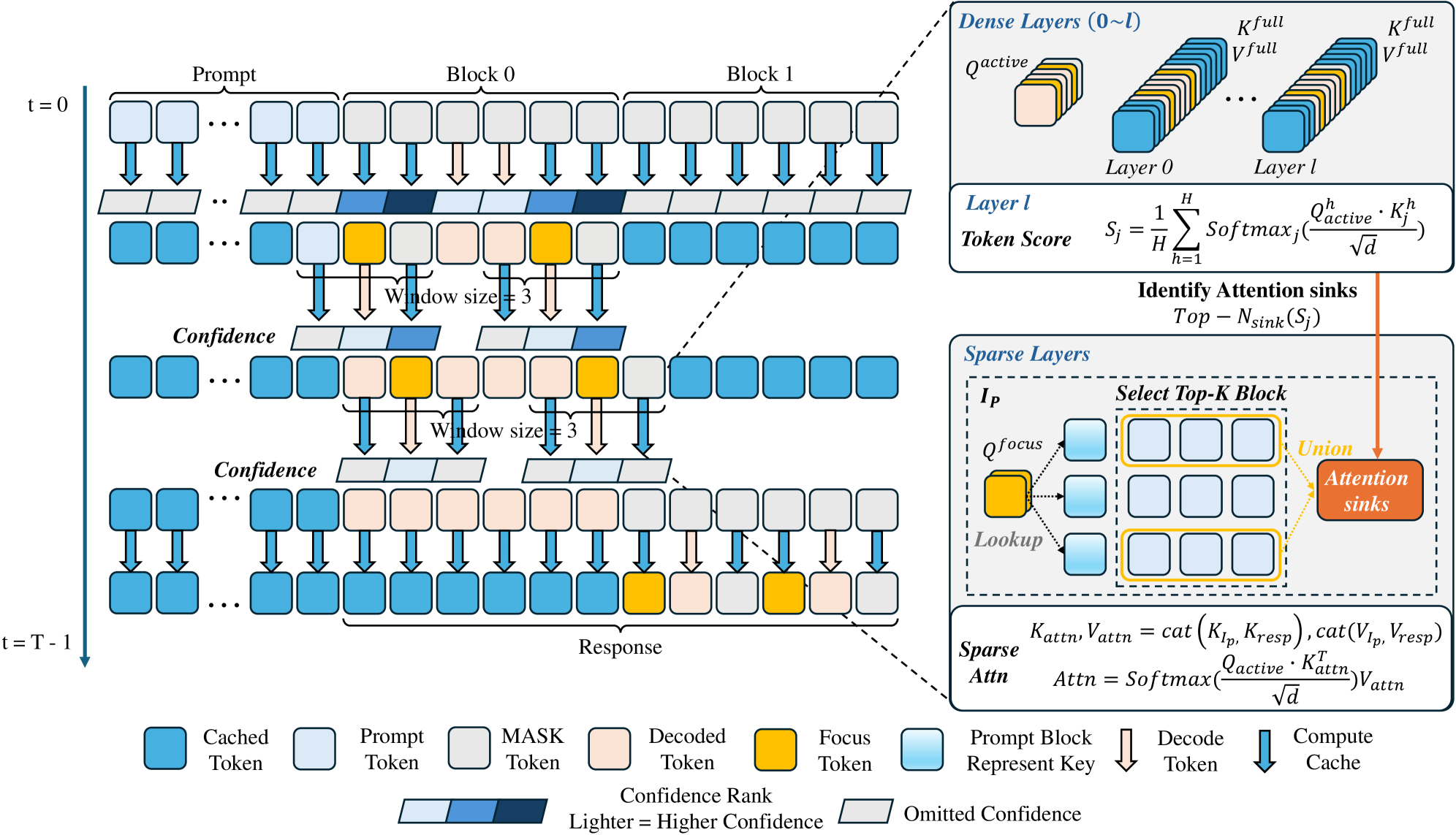
Предложенная система Focus-dLLM использует предсказание будущих токенов и выборочное внимание к релевантной информации для ускорения инференса диффузионных языковых моделей.
Несмотря на впечатляющие возможности диффузионных больших языковых моделей (dLLM) в обработке длинных контекстов, их неавторегрессивная природа сталкивается с ограничениями вычислительной эффективности из-за затрат на двунаправленное внимание. В данной работе, ‘Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing’, предлагается новый фреймворк, не требующий обучения, для ускорения вывода dLLM, основанный на прогнозировании будущих токенов и выборочном внимании к релевантной информации. Предложенный подход, использующий индикатор, управляемый уверенностью в прошлых шагах, позволяет эффективно идентифицировать и отсекать избыточные вычисления внимания, сохраняя при этом критически важные «стоки» внимания. Способен ли этот метод существенно повысить производительность dLLM при обработке действительно больших контекстов и открыть новые возможности для применения в различных задачах обработки естественного языка?
Преодолевая Границы Контекста: Проблема Длинных Последовательностей
Традиционные трансформеры, несмотря на свою впечатляющую производительность, сталкиваются с серьезными трудностями при обработке длинных последовательностей данных. Эта проблема обусловлена квадратичной сложностью вычислений — с увеличением длины текста потребность в вычислительных ресурсах и времени растет экспоненциально. В частности, механизм внимания, ключевой компонент трансформеров, требует сравнения каждого элемента последовательности со всеми остальными, что приводит к O(n^2) сложности, где n — длина последовательности. Это существенно ограничивает возможности модели при анализе больших документов, длинных диалогов или задач, требующих установления связей между отдаленными друг от друга элементами текста, делая обработку очень ресурсоемкой и замедляя процесс обучения и инференса.
Ограничение, связанное с обработкой длинных текстов, существенно влияет на эффективность моделей в задачах, требующих глубокого анализа и логических выводов. Например, при автоматическом реферировании больших документов, модели испытывают трудности с выделением ключевой информации и поддержанием связности текста, что приводит к неполным или неточным резюме. Аналогичная проблема возникает и при ответе на сложные вопросы, требующие сопоставления информации из разных частей текста — модели могут упускать важные детали или делать ошибочные заключения из-за неспособности эффективно обрабатывать длинные последовательности. Таким образом, преодоление этих ограничений является ключевым шагом на пути к созданию действительно интеллектуальных систем обработки естественного языка, способных понимать и анализировать тексты любой длины.
Диффузионные Языковые Модели: Новый Подход к Инференсу
Диффузионные языковые модели (Diffusion LLMs) представляют собой неавторегрессивную альтернативу традиционным трансформерам. В отличие от авторегрессивных моделей, генерирующих токены последовательно, опираясь на предыдущие, Diffusion LLMs осуществляют генерацию, отвязанную от последовательного декодирования. Это означает, что каждый токен может быть сгенерирован параллельно и независимо от других, что позволяет отказаться от необходимости последовательной обработки и, следовательно, значительно повысить скорость вывода. Вместо предсказания следующего токена, Diffusion LLMs работают путем итеративного удаления шума из случайного распределения, постепенно формируя желаемый текст. Такой подход кардинально отличается от принципа последовательного декодирования, используемого в Transformer-based моделях.
В отличие от авторегрессионных моделей, таких как Transformer, диффузионные языковые модели (Diffusion LLMs) позволяют осуществлять генерацию текста параллельно, а не последовательно. Это достигается за счет отказа от поэтапного декодирования, что существенно ускоряет процесс инференса. Параллельная обработка данных позволяет значительно повысить пропускную способность и снизить задержки, особенно при работе с длинными последовательностями текста, где традиционные модели испытывают ограничения по скорости и потреблению памяти. Возможность одновременной обработки различных частей последовательности открывает перспективы для масштабирования и эффективной обработки больших объемов текста.
Диффузионные языковые модели (Diffusion LLMs) функционируют посредством итеративного процесса шумоподавления, где последовательно уменьшается уровень шума в данных до получения целевого результата. Эффективное управление KV-кэшем (ключ-значение) становится критически важным для производительности, поскольку в процессе шумоподавления многократно используются ранее вычисленные промежуточные представления. Неоптимальное управление KV-кэшем приводит к избыточным вычислениям и значительно замедляет процесс генерации, особенно при работе с длинными последовательностями. Минимизация объема хранимых в кэше данных и оптимизация алгоритмов доступа к ним напрямую влияют на скорость и эффективность диффузионных моделей.
Focus-dLLM: Ускорение Разреженного Внимания
Focus-dLLM представляет собой фреймворк разреженного внимания, не требующий обучения, разработанный для ускорения инференса Diffusion LLM при работе с длинными контекстами. В отличие от подходов, требующих дополнительной тренировки модели для адаптации к разреженному вниманию, Focus-dLLM применяет методы, позволяющие эффективно сократить вычислительные затраты непосредственно во время инференса. Это достигается за счет интеллектуального отбора релевантных ключей внимания, что позволяет снизить объем вычислений без значительной потери качества генерируемого текста. Фреймворк ориентирован на применение в сценариях, где важна скорость обработки длинных последовательностей, например, при анализе больших объемов текста или генерации длинных текстов.
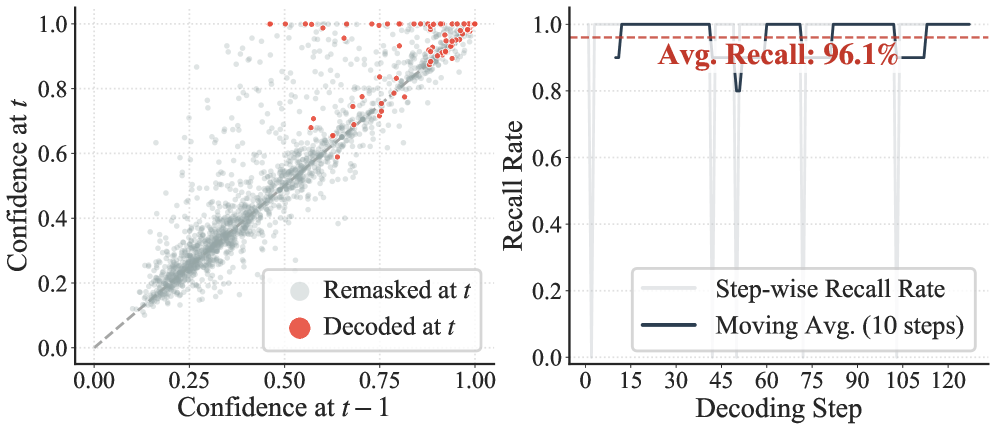
Механизм Focus-dLLM использует два основных подхода для интеллектуального отбора релевантных ключей внимания и снижения вычислительных затрат. Во-первых, применяется Past Confidence-Guided Indicator, который оценивает важность ключей на основе их предыдущего вклада в процесс внимания. Во-вторых, используется Sink-Aware Pruning, направленный на сохранение так называемых ‘Attention Sinks’ — критически важных контекстуальных элементов, которые необходимо удерживать для обеспечения качества генерации. Комбинация этих двух методов позволяет эффективно сократить количество обрабатываемых ключей внимания без значительной потери точности, что приводит к ускорению вычислений.
Метод Sink-Aware Pruning направлен на сохранение так называемых “Attention Sinks” — ключевых элементов в механизме внимания, представляющих собой паттерны концентрации внимания на определенных токенах входной последовательности. В процессе разрежения (pruning) стандартные методы могут случайно удалить эти важные точки концентрации, что приведет к потере критической контекстной информации. Sink-Aware Pruning идентифицирует и сохраняет эти «Attention Sinks», обеспечивая тем самым сохранение значимых зависимостей в длинных последовательностях и минимизируя снижение производительности модели после разрежения. Это достигается путем анализа матрицы внимания и определения токенов, которые наиболее часто и интенсивно привлекают внимание других токенов.
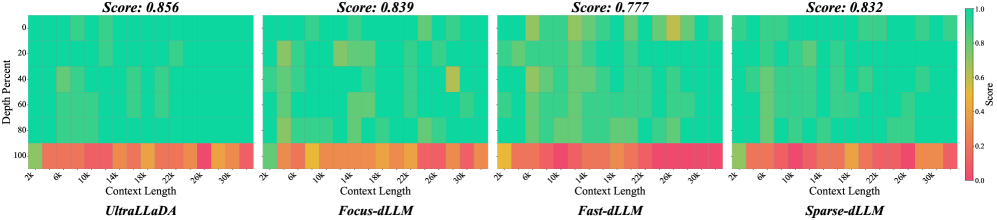
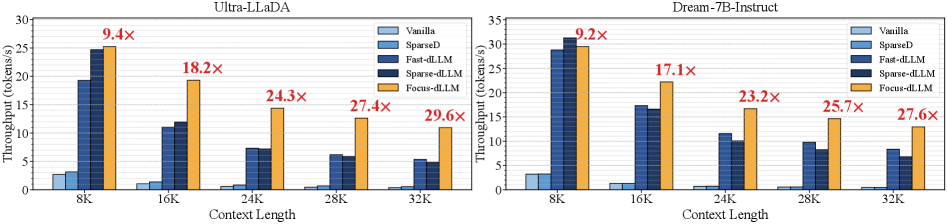
В ходе тестирования на наборе данных LongBench, Focus-dLLM продемонстрировал значительное ускорение обработки контекста длиной 32K — более чем в 29 раз по сравнению с современными аналогами. Кроме того, для модели UltraLLaDA при той же длине контекста, Focus-dLLM показал прирост скорости в 2.05 раза по сравнению с Fast-dLLM. Эти результаты подтверждают эффективность предложенного подхода к разреженной аттенции для ускорения вывода больших языковых моделей.
Подтверждение Эффективности и Широкие Возможности Применения
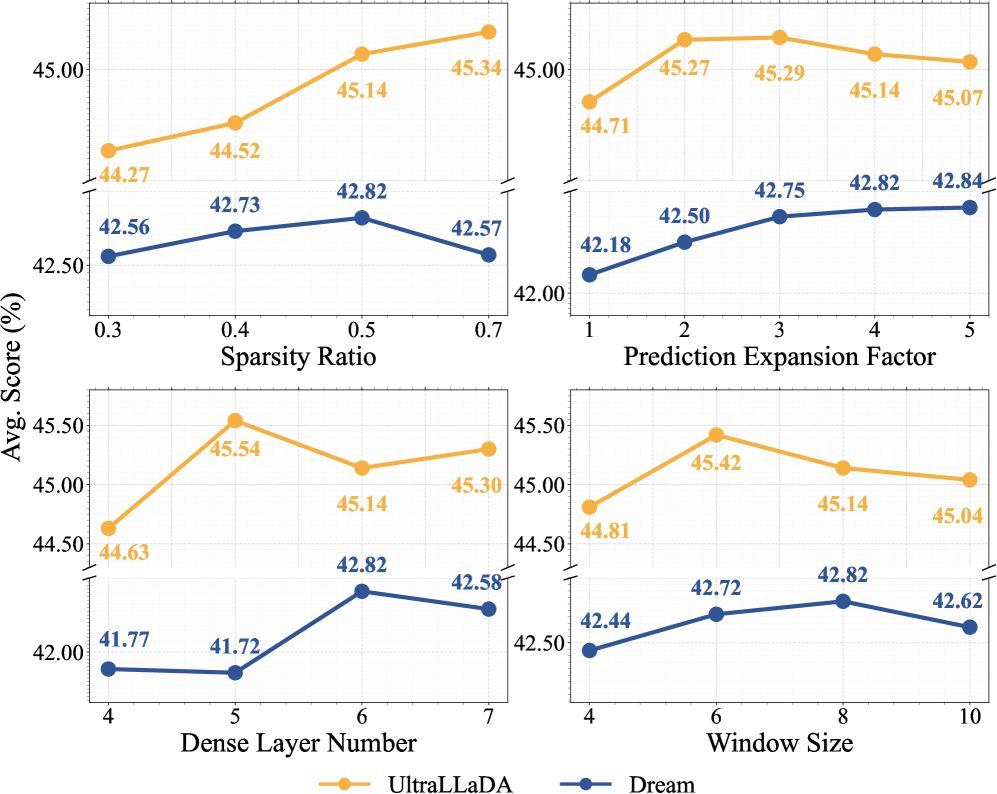
Эффективность Focus-dLLM получила дополнительное подтверждение благодаря успешному применению к различным моделям, включая UltraLLaDA и Dream-7B-Instruct. Данные эксперименты продемонстрировали, что разработанный подход не ограничивается конкретной архитектурой Diffusion LLM, а обладает высокой степенью обобщения. Успешная интеграция с этими моделями свидетельствует о гибкости и адаптивности Focus-dLLM, позволяя эффективно улучшать производительность широкого спектра языковых моделей и открывая перспективы для дальнейшего развития технологий обработки естественного языка.
Исследования показали, что разработанный подход, известный как Focus-dLLM, демонстрирует высокую степень обобщения, успешно применяясь к различным архитектурам Diffusion LLM, включая UltraLLaDA и Dream-7B-Instruct. Этот факт свидетельствует о том, что методика не ограничена спецификой конкретной модели и способна эффективно адаптироваться к различным способам реализации языковых моделей, основанных на диффузии. Универсальность данного подхода открывает возможности для его широкого применения в различных областях обработки естественного языка, позволяя значительно улучшить производительность и эффективность работы с длинными контекстами в различных системах искусственного интеллекта.
Исследования показали, что Focus-dLLM демонстрирует превосходные результаты в задачах обработки длинного контекста, достигая наивысшего среднего балла в тесте LongBench среди всех протестированных методов. Эта эффективность подтверждается высокой точностью предсказания скрытых токенов — в среднем 96.1% — благодаря использованию оценки уверенности на предыдущем шаге. Такая способность к точному прогнозированию и общему превосходству над конкурентами указывает на значительный прогресс в области эффективной обработки больших объемов информации, что открывает новые возможности для создания более интеллектуальных и отзывчивых систем искусственного интеллекта.
Разработка Focus-dLLM открывает новые перспективы в области обработки длинных последовательностей данных, существенно ускоряя и повышая эффективность вывода моделей. Благодаря этому, становится возможным более глубокое понимание сложных документов, анализ больших объемов текста и решение задач, требующих комплексного логического мышления. Улучшенная скорость и эффективность обработки данных также оказывают значительное влияние на развитие систем искусственного интеллекта, используемых в диалоговых приложениях, позволяя создавать более естественные и информативные беседы. В конечном итоге, Focus-dLLM способствует расширению возможностей применения больших языковых моделей в самых разных областях, от научных исследований до повседневного общения.

Перспективы Развития: К Эффективному и Масштабируемому Рассуждению
Исследования в области приближенных методов кэширования KV (Key-Value) направлены на существенное снижение объема памяти, необходимого для работы больших языковых моделей, особенно при обработке чрезвычайно длинных последовательностей текста. Традиционные методы кэширования хранят все векторы ключей и значений, что приводит к квадратичному росту потребления памяти с увеличением длины последовательности. Приближенные методы, напротив, позволяют снизить точность представления этих векторов, жертвуя незначительной долей информации ради значительного уменьшения занимаемой памяти. Это, в свою очередь, позволяет ускорить процесс инференса, поскольку модель может быстрее получать доступ к необходимой информации из кэша. Дальнейшая оптимизация этих методов, включая разработку новых алгоритмов аппроксимации и адаптивных стратегий управления кэшем, представляется перспективным направлением для повышения эффективности и масштабируемости языковых моделей.
Исследования показывают, что объединение подхода Focus-dLLM со стратегиями расширения окна контекста способно значительно улучшить связность и понимание текста. Focus-dLLM, концентрируясь на наиболее релевантных частях входной последовательности, обеспечивает эффективную обработку информации. Однако, ограничение контекстного окна может приводить к потере важных деталей. Стратегии расширения окна, такие как использование скользящего окна или рекуррентной обработки, позволяют модели учитывать более широкий контекст, что особенно важно для длинных текстов и сложных задач. Сочетание этих двух подходов позволяет не только снизить вычислительные затраты за счет фокусировки внимания, но и повысить точность и согласованность генерируемого текста, приближая модели к человеческому уровню понимания.
Принципы, лежащие в основе Focus-dLLM, обладают значительным потенциалом для адаптации к другим неавторегрессивным моделям обработки естественного языка. Вместо последовательного генерирования токенов, как в традиционных авторегрессивных сетях, Focus-dLLM определяет наиболее релевантные части входной последовательности для непосредственного формирования выходных данных. Этот подход позволяет существенно повысить скорость обработки и снизить вычислительные затраты, что особенно важно для задач, требующих обработки больших объемов текста. Успешная интеграция этих принципов в другие неавторегрессивные архитектуры может открыть новые возможности для создания более эффективных и масштабируемых систем, способных решать сложные задачи в области машинного перевода, суммаризации текста и анализа тональности, расширяя горизонты применения искусственного интеллекта в лингвистике.
В представленной работе акцент сделан на оптимизацию процесса инференса больших языковых моделей, работающих на основе диффузии, в условиях длинного контекста. Подход Focus-dLLM демонстрирует возможность значительного ускорения вычислений без потери точности, благодаря выборочному вниманию к релевантной информации. Это согласуется с высказыванием Брайана Кернигана: «Простота — это главное. Сложность — это признак плохого дизайна». В данном случае, элегантность решения заключается в эффективном использовании ресурсов для обработки длинных последовательностей, избегая излишней вычислительной нагрузки и сохраняя математическую чистоту алгоритма, что позволяет достичь высокой масштабируемости.
Куда Далее?
Представленная работа, безусловно, демонстрирует элегантность подхода к ускорению инференса диффузионных языковых моделей. Однако, истинная проверка любого алгоритма — не скорость на синтетических данных, а его устойчивость к непредсказуемости реальных последовательностей. Вопрос о том, насколько предсказания о будущих токенах коррелируют с истинным распределением в сложных, неоднозначных контекстах, остаётся открытым. Неизбежно возникнет необходимость в формальной оценке стабильности и границ применимости предложенного метода.
Очевидно, что селективное внимание, основанное на уверенности, является лишь одним из возможных путей оптимизации. Более глубокое исследование взаимосвязи между структурой KV-кэша и эффективностью внимания представляется перспективным направлением. Вместо того, чтобы просто отбрасывать «неважные» части контекста, возможно ли их преобразование в более компактное, но информативное представление? Решение этой задачи требует не просто инженерной оптимизации, а переосмысления самой концепции внимания.
В конечном итоге, ускорение инференса — это лишь средство достижения цели. Истинная ценность заключается в создании моделей, способных к истинному пониманию и генерации осмысленного текста. Пока алгоритмы остаются лишь приближениями к идеалу, необходимо помнить, что красота решения не определяется его скоростью, а его математической непротиворечивостью и обобщающей способностью.
Оригинал статьи: https://arxiv.org/pdf/2602.02159.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Bibby AI: Новый помощник для исследователей в LaTeX
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- Квантовые амбиции: Иран вступает в гонку
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
2026-02-09 03:16