Автор: Денис Аветисян
Исследователи представили DFlash — инновационную систему, сочетающую скорость диффузионных моделей с точностью авторегрессивных, что позволяет значительно ускорить процесс генерации текста большими языковыми моделями.
DFlash использует блочную диффузию для быстрого создания черновиков и авторегрессивную проверку для обеспечения высокой точности и скорости вывода.
Авторегрессионные большие языковые модели демонстрируют высокую производительность, но страдают от последовательного декодирования, ограничивающего скорость работы и эффективность использования GPU. В данной работе представлена система ‘DFlash: Block Diffusion for Flash Speculative Decoding’, использующая блочную диффузионную модель для параллельной генерации черновиков, что позволяет значительно ускорить процесс вывода. DFlash сочетает скорость параллельного декодирования с высокой точностью, обеспечивая более чем 6-кратное ускорение без потерь качества, превосходя современные методы спекулятивного декодирования, такие как EAGLE-3. Возможно ли дальнейшее повышение эффективности за счет адаптации архитектуры диффузионной модели и оптимизации процесса верификации?
Авторегрессионное Ограничение: Пределы Последовательного Декодирования
Современные большие языковые модели совершили революцию в области обработки естественного языка, однако их работа основана на авторегрессионном декодировании — принципиально последовательном процессе. Этот метод предполагает генерацию текста по одному токену за раз, где каждый новый токен обусловлен всеми предыдущими. Несмотря на свою эффективность, такая последовательность становится узким местом при обработке сложных задач, требующих долгосрочного планирования и рассуждений. Фактически, каждое новое слово зависит от предыдущих вычислений, что ограничивает возможности параллелизации и, как следствие, снижает общую скорость генерации, особенно при работе с длинными текстами или задачами, требующими многоступенчатых рассуждений.
Последовательный характер авторегрессивного декодирования создает ощутимые ограничения в производительности, особенно при решении сложных задач, таких как рассуждения с цепочкой мыслей (Chain-of-Thought Reasoning). Каждый новый токен генерируется только после завершения генерации предыдущего, что приводит к экспоненциальному увеличению времени обработки при увеличении длины последовательности. В задачах, требующих многоступенчатых рассуждений, эта последовательность становится критически важной, поскольку модель должна последовательно выводить каждый шаг логического заключения. Таким образом, даже при значительном увеличении вычислительных ресурсов и масштабировании модели, принципиальная линейность процесса декодирования становится узким местом, ограничивающим скорость и эффективность решения сложных когнитивных задач. Это подчеркивает необходимость поиска альтернативных подходов к генерации текста, способных преодолеть ограничения последовательной обработки информации.
Несмотря на впечатляющий прогресс в области больших языковых моделей, простое увеличение их размера не является решением проблемы эффективности генерации текста. Исследования показывают, что последовательный, авторегрессивный подход к декодированию становится узким местом, особенно при решении сложных задач, требующих многоступенчатого логического вывода. Увеличение количества параметров модели лишь незначительно улучшает скорость генерации и требует экспоненциального роста вычислительных ресурсов. Поэтому для достижения реального прорыва необходим принципиально новый подход к генерации текста, который позволит распараллелить процесс и преодолеть ограничения последовательного декодирования, открывая путь к более быстрым, эффективным и масштабируемым языковым моделям.
Параллельные Пути: Введение в Спекулятивное Декодирование и Диффузионные Модели
Спекулятивное декодирование предлагает решение для ускорения процесса инференса за счет параллельной генерации предварительных токенов. Традиционное авторегрессионное декодирование генерирует токены последовательно, что является узким местом для скорости. Спекулятивное декодирование позволяет генерировать несколько токенов одновременно, используя механизм предсказания. Эти предварительные токены затем проверяются на соответствие фактической модели, и при необходимости корректируются. Параллелизация генерации значительно снижает задержку, особенно для длинных последовательностей, обеспечивая более быструю обработку и отклик системы.
Диффузионные языковые модели (Diffusion Language Models) предоставляют эффективную основу для параллельной генерации текста благодаря своей способности моделировать контекст в обоих направлениях — как прошлое, так и будущее. В отличие от традиционных авторегрессионных моделей, которые генерируют токены последовательно, опираясь только на предыдущий контекст, диффузионные модели используют процесс диффузии и обратного диффузии, позволяя учитывать взаимосвязи между токенами в обоих направлениях. Это достигается путем постепенного добавления шума к входным данным (процесс диффузии) и последующего удаления шума для восстановления исходного сигнала (обратный процесс диффузии). Моделирование двунаправленного контекста позволяет более точно предсказывать следующие токены, улучшая качество генерируемого текста и обеспечивая возможность параллельной обработки, что значительно ускоряет процесс инференса.
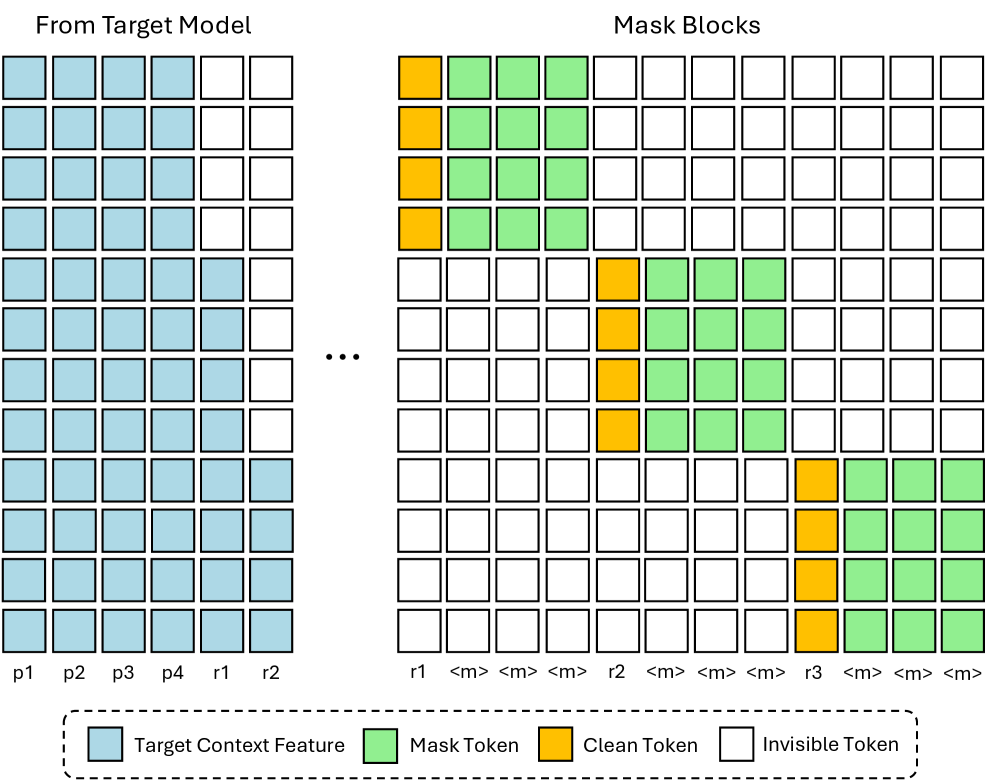
Блочные диффузионные модели (Block Diffusion Models) оптимизируют процесс генерации текста, одновременно обрабатывая блоки замаскированных токенов. В отличие от последовательной обработки, характерной для традиционных авторегрессионных моделей, данная архитектура позволяет распараллелить процесс шумоподавления (denoising) для нескольких токенов. Это достигается путем маскирования определенных участков последовательности и последующего восстановления этих участков параллельно, что значительно ускоряет инференс. Сочетание параллелизма с сохранением авторегрессионной структуры обеспечивает как скорость генерации, так и когерентность выходного текста. Данный подход позволяет эффективно использовать вычислительные ресурсы и снизить задержку при генерации длинных последовательностей.
DFlash: Блочная Диффузионная Схема для Эффективного Создания Черновиков и Верификации
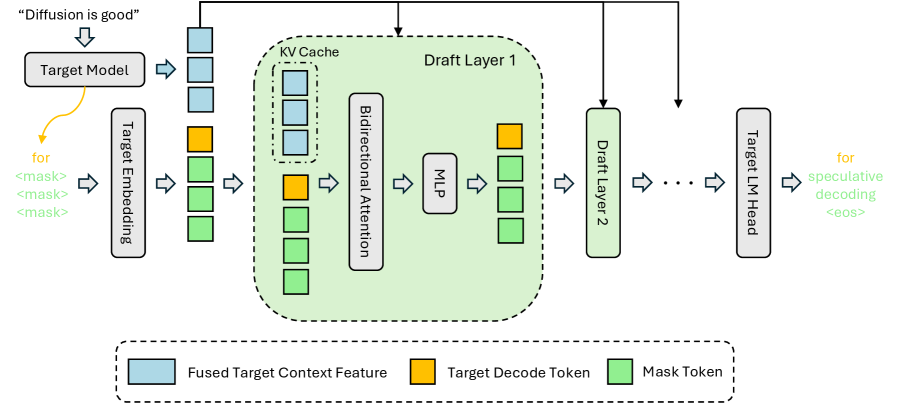
DFlash представляет новую схему спекулятивного декодирования, использующую блочные диффузионные модели для быстрого и качественного создания черновиков текста. В отличие от традиционных авторегрессионных моделей, DFlash генерирует токены блоками, что позволяет распараллелить процесс и значительно увеличить скорость генерации. Эта схема использует диффузионные модели, обученные для предсказания вероятности токенов на основе контекста, и применяет итеративный процесс шумоподавления для создания последовательности токенов. В результате достигается баланс между скоростью генерации и качеством текста, обеспечивая высокую производительность при создании черновиков различной длины и сложности.
В DFlash для повышения точности модели предварительного наброска используются признаки целевого контекста (Target Context Features), представляющие собой векторное представление релевантной информации из входной последовательности. Эти признаки подаются на вход модели в качестве дополнительного условия, что позволяет ей более эффективно учитывать контекст при генерации. Для улучшения потока информации внутри модели применяется метод KV Injection, который заключается в прямой передаче ключей (Key) и значений (Value) из этапов кодирования в этапы декодирования. Это позволяет модели сохранять и использовать более полную информацию о входных данных, что способствует повышению качества генерируемого текста и снижению вероятности ошибок.
DFlash использует параллельную генерацию и спекулятивную верификацию для оптимизации процесса декодирования. Параллельная генерация позволяет одновременно создавать несколько вариантов продолжения текста, значительно увеличивая скорость работы модели. Спекулятивная верификация, в свою очередь, предполагает предварительную оценку сгенерированных фрагментов на соответствие заданным критериям качества. Этот процесс позволяет отсеять нерелевантные или неточные варианты на ранней стадии, избегая дорогостоящих вычислений для их полной обработки. Комбинация этих двух подходов обеспечивает как высокую скорость генерации текста, так и поддержание требуемого уровня качества выходных данных.
Эмпирическая Валидация и Сравнительные Тесты Производительности
Тщательное тестирование DFlash с использованием таких моделей, как LLaMA-3.1 и Qwen3, продемонстрировало существенное увеличение скорости обработки данных. В ходе экспериментов зафиксировано значительное ускорение работы системы по сравнению с традиционными подходами, что подтверждает эффективность предложенной архитектуры. Полученные результаты свидетельствуют о потенциале DFlash для оптимизации ресурсоемких задач, связанных с обработкой больших объемов информации и повышением производительности приложений искусственного интеллекта. Данное увеличение скорости открывает новые возможности для применения в различных областях, требующих быстрой и эффективной обработки данных.
В основе DFlash лежит фреймворк SGLang, обеспечивающий значительное ускорение процесса инференса благодаря ряду оптимизаций, среди которых ключевую роль играет FlashAttention. Данная технология позволяет существенно сократить потребление памяти и вычислительные затраты при обработке длинных последовательностей, что особенно важно для современных больших языковых моделей. FlashAttention эффективно использует иерархическую структуру памяти, минимизируя количество операций чтения и записи, и тем самым ускоряя процесс вычисления внимания — критически важной операции в архитектуре трансформеров. Использование SGLang и FlashAttention позволяет DFlash достигать впечатляющих показателей производительности, превосходя традиционные подходы к инференсу и открывая возможности для более эффективного и быстрого использования больших языковых моделей в реальных приложениях.
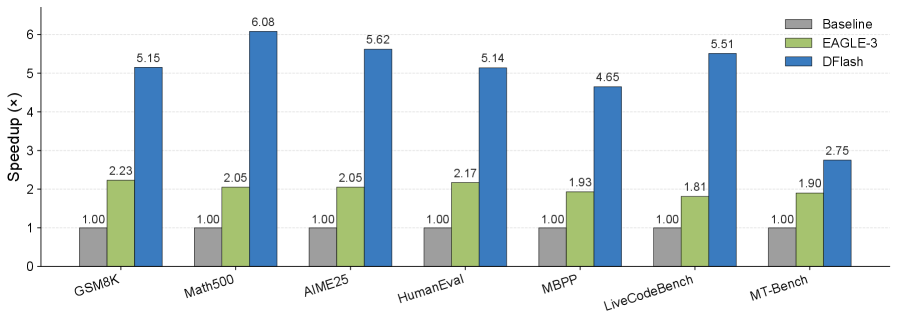
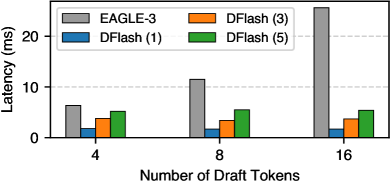
Исследования показали, что DFlash демонстрирует значительное ускорение работы с моделью Qwen3-8B, достигая вплоть до 6.1-кратного увеличения скорости по сравнению с традиционным авторегрессионным подходом. Более того, в большинстве тестов производительность DFlash превосходит показатель, установленный передовой системой EAGLE-3, почти в 2.5 раза. Данные результаты подтверждают эффективность разработанного фреймворка в задачах ускорения вычислений, что делает его перспективным решением для развертывания больших языковых моделей и повышения общей скорости обработки информации.
В условиях практического развертывания и обслуживания моделей, фреймворк DFlash демонстрирует значительное увеличение скорости обработки данных. Наблюдается ускорение в 5.1 раза при работе с моделью Qwen3-8B, 4.7 раза — с Qwen3-4B, и 4.3 раза — с Qwen3-Coder-30B-A3B-Instruct. Эти результаты подтверждают эффективность DFlash в реальных сценариях использования, где важна высокая пропускная способность и минимальная задержка при обслуживании запросов к большим языковым моделям.
Перспективы Развития: К Эффективной и Масштабируемой Генерации Языка
Перспективные исследования направлены на интеграцию скрытых признаков из целевой модели, что позволит значительно улучшить способность предварительной модели предсказывать последующие токены. Этот подход предполагает извлечение и использование внутренней информации, генерируемой более мощной моделью, для повышения точности и эффективности менее ресурсоемкой модели-черновика. Внедрение таких скрытых признаков может предоставить дополнительный контекст и знания, позволяя модели-черновику более точно улавливать сложные языковые закономерности и генерировать более связные и осмысленные тексты. Ожидается, что подобная интеграция приведет к созданию более эффективных и масштабируемых систем генерации языка, способных решать широкий спектр задач обработки естественного языка.
Дальнейшее развитие платформы DFlash, направленное на поддержку моделей ещё большего масштаба и решение более сложных задач, остаётся первостепенной задачей. Исследователи стремятся к расширению возможностей системы для обработки чрезвычайно крупных языковых моделей, содержащих миллиарды параметров, и к адаптации её к разнообразным приложениям, таким как генерация длинных текстов, машинный перевод и ответы на сложные вопросы. Успешная реализация этих улучшений позволит существенно повысить эффективность и масштабируемость языковых моделей, открывая новые горизонты для создания более интеллектуальных и полезных систем искусственного интеллекта, доступных для широкого круга пользователей и разработчиков.
Данная работа вносит значительный вклад в развитие эффективной и масштабируемой генерации языка, открывая путь к созданию более мощных и доступных приложений искусственного интеллекта. Развитие технологий, позволяющих генерировать текст с меньшими вычислительными затратами и большими возможностями адаптации, имеет решающее значение для широкого спектра задач — от автоматического перевода и создания контента до разработки интеллектуальных помощников и чат-ботов. Преодолевая существующие ограничения в скорости и эффективности языковых моделей, исследование способствует демократизации доступа к передовым технологиям обработки естественного языка, делая их доступными для большего числа исследователей и разработчиков, а также для конечных пользователей. В перспективе, это может привести к созданию инновационных приложений, способных решать сложные задачи и улучшать качество жизни.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в процессе генерации текста. Авторы предлагают DFlash — систему, сочетающую в себе скорость предварительного наброска и точность финальной проверки. Это напоминает подход, где избыточность отсекается, оставляя лишь суть. Как заметил Анри Пуанкаре: «Наука не состоит из цепи, в которой каждое звено необходимо, а скорее из огромного количества уловок». DFlash, подобно этим уловкам, использует диффузионные модели для быстрой генерации, а затем верифицирует результат с помощью авторегрессионных моделей, что позволяет достичь значительного прироста скорости при сохранении качества. В стремлении к оптимальной производительности, разработчики избегают ненужной сложности, подобно тому, как хороший художник удаляет лишние мазки, чтобы подчеркнуть главное.
Что дальше?
Представленная работа, стремясь к скорости вывода больших языковых моделей, неизбежно сталкивается с фундаментальным вопросом: достаточно ли скорости, если истина остаётся за кадром? DFlash, объединяя диффузионные модели для набросков и авторегрессивные — для проверки, предлагает элегантное решение, но и подчёркивает избыточность самой постановки задачи. Ведь, в конечном счёте, ценность текста не в скорости его генерации, а в его содержании. Очевидно, что будущее лежит не в ускорении проверки, а в создании моделей, изначально генерирующих текст, близкий к истине.
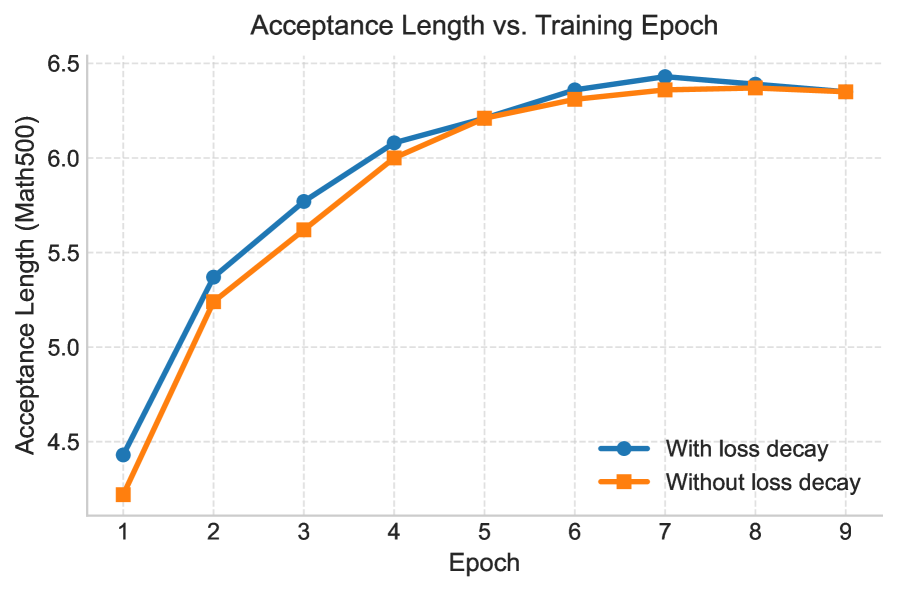
Особое внимание следует уделить не столько повышению процента принятия (acceptance rate), сколько снижению потребности в проверке. Иными словами, необходимо переосмыслить саму архитектуру языковых моделей, стремясь к большей внутренней согласованности и логичности. Упрощение — не ограничение, а свидетельство понимания. Вместо бесконечного наращивания вычислительных мощностей, целесообразно сосредоточиться на создании более лаконичных и эффективных алгоритмов.
Неизбежный вопрос — масштабируемость. Успех DFlash в лабораторных условиях — лишь первый шаг. Реальное применение потребует адаптации к различным архитектурам моделей и объёмам данных. Однако, истинная сложность заключается не в технических деталях, а в философском осмыслении самой задачи: стремимся ли мы к скорости ради скорости, или к более глубокому пониманию языка и мышления?
Оригинал статьи: https://arxiv.org/pdf/2602.06036.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Квантовый скачок венчурного капитала: между надеждой и реальностью
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Визуальный разум: Как видеомодели научились понимать текст и создавать изображения
- Многокритериальная оптимизация: взгляд на народные методы
- Муза и Алгоритм: Как ИИ Помогает Писать Песни
2026-02-08 01:49