Автор: Денис Аветисян
Исследователи предлагают метод, использующий обучение с подкреплением для оптимизации быстрых весов, позволяющий нейросетям эффективнее обрабатывать длинные контексты.
В статье представлена ReFINE — система, использующая обучение с подкреплением и предсказание следующей последовательности для улучшения работы моделей с быстрыми весами на протяжении всего процесса обучения.
Несмотря на перспективность архитектур с быстрыми весами как альтернативы трансформерам для работы с длинным контекстом, их потенциал сдерживается парадигмой обучения предсказанию следующего токена. В данной работе, посвященной ‘Reinforced Fast Weights with Next-Sequence Prediction’, предложен фреймворк ReFINE, использующий обучение с подкреплением и задачу предсказания следующей последовательности для оптимизации моделей с быстрыми весами. ReFINE позволяет эффективно захватывать долгосрочные зависимости и улучшает качество моделирования длинного контекста на протяжении всего жизненного цикла обучения. Возможно ли дальнейшее расширение возможностей ReFINE за счет интеграции с другими методами обучения с подкреплением и адаптации к различным типам данных?
Вызов длинного контекста: границы возможностей
Традиционные языковые модели, несмотря на свою впечатляющую производительность, сталкиваются с серьезными трудностями при обработке длинных последовательностей текста. Ограничения вычислительных ресурсов приводят к тому, что модели теряют способность поддерживать согласованность и релевантность информации по мере увеличения длины текста. Это связано с тем, что обработка каждого последующего токена требует все больше вычислительной мощности, и модель начинает упрощать представление информации, отбрасывая важные детали и связи. В результате, чем длиннее текст, тем сложнее модели уловить общую картину и сохранить контекст, что негативно сказывается на качестве анализа и генерации текста.
Стандартный подход к обучению языковых моделей, заключающийся в предсказании следующего токена в последовательности, оказывается недостаточным для улавливания долгосрочных зависимостей, необходимых для глубокого понимания текста. В то время как модель успешно справляется с краткосрочными связями между соседними словами, способность улавливать отношения между элементами, разнесенными на значительное расстояние, существенно снижается. Это связано с тем, что предсказание следующего токена фокусируется на локальном контексте, не учитывая глобальную структуру и смысловые связи, которые формируют целостное понимание длинных текстов или диалогов. В результате, модель испытывает трудности в удержании когерентности и релевантности информации на протяжении всей последовательности, что ограничивает ее способность к логическим выводам и осмысленному анализу сложных текстов.
Ограничения в обработке длинных последовательностей текста существенно влияют на эффективность выполнения задач, требующих логического мышления и понимания контекста. Когда модели сталкиваются с большими объемами информации, такими как объемные документы или продолжительные диалоги, способность поддерживать последовательность и релевантность ответов снижается. Это приводит к ошибкам в умозаключениях, неверной интерпретации смысла и, как следствие, к неудовлетворительным результатам в задачах, где критически важна способность к анализу и синтезу информации, представленной в длинном контексте. Например, при анализе юридических документов или научных статей, упущение важных деталей из-за ограниченного «окна внимания» может привести к неверным выводам и ошибочным решениям.
Быстрые веса: новый взгляд на масштабируемость
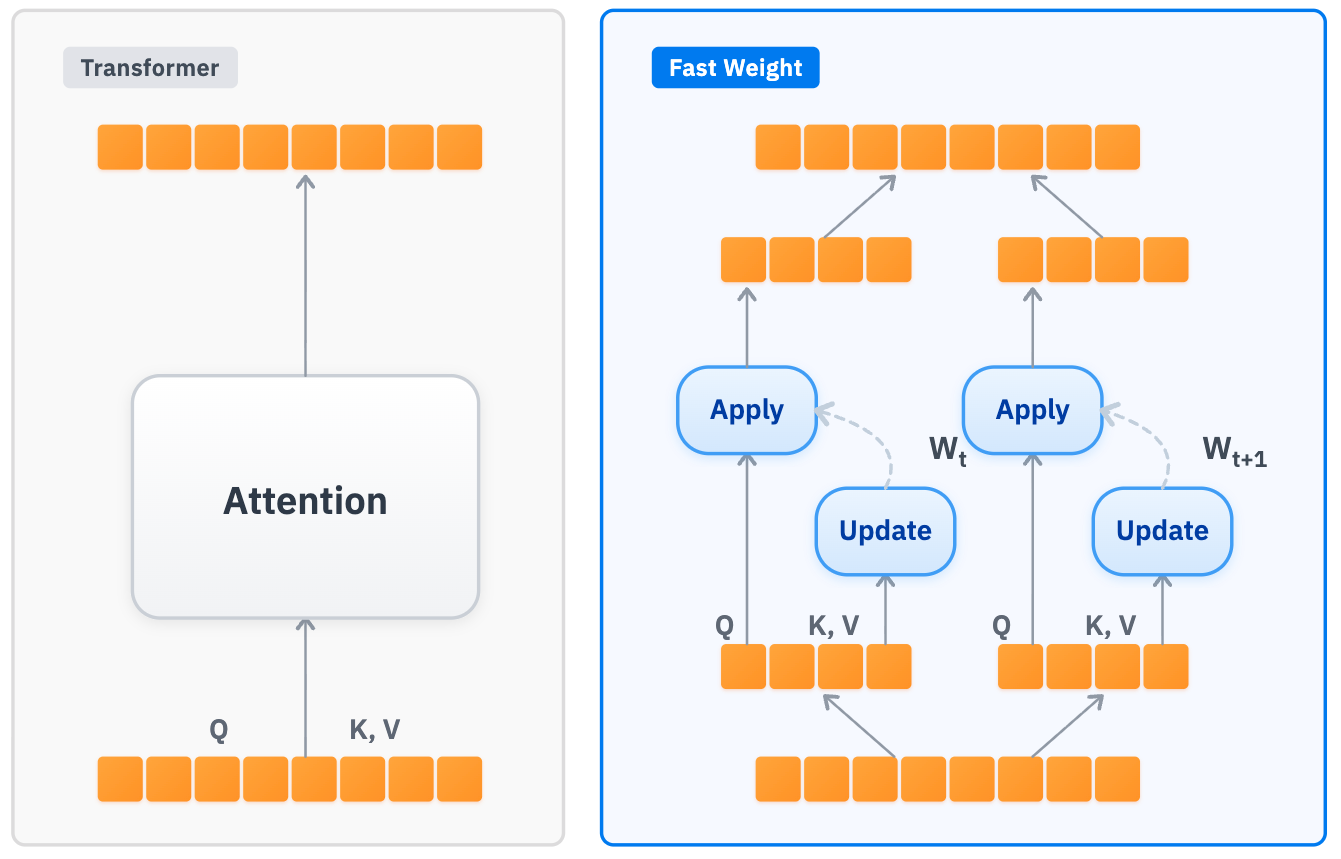
Архитектуры с быстрым весом представляют собой эффективное решение для повышения масштабируемости и снижения вычислительных затрат за счет замены механизмов внимания на память фиксированного размера. Традиционные модели-трансформеры требуют квадратичного увеличения вычислительных ресурсов с ростом длины входной последовательности, что ограничивает их применение к задачам с длинным контекстом. В отличие от них, архитектуры с быстрым весом используют предварительно вычисленные веса, хранящиеся в памяти фиксированного размера, что позволяет выполнять вычисления с линейной сложностью по отношению к длине последовательности. Это существенно снижает потребность в памяти и вычислительной мощности, особенно при обработке больших объемов данных, и позволяет создавать более эффективные и масштабируемые модели для различных задач обработки естественного языка.
Реализации быстрых весовых архитектур, такие как DeltaNet и LaCT, демонстрируют альтернативный подход к традиционным трансформерам, основанный на использовании фиксированного размера памяти вместо механизмов внимания. DeltaNet использует разреженные обновления весов, позволяющие параллельно обрабатывать различные части входных данных, что значительно снижает вычислительные затраты. LaCT (Linear Attention with Contextual Transformations) применяет линейное внимание с контекстными преобразованиями, что обеспечивает эффективное масштабирование по длине последовательности. Обе архитектуры позволяют распараллеливать вычисления, что делает их более эффективными для обработки больших объемов данных и снижает задержку по сравнению с последовательными операциями, характерными для стандартных трансформеров.
Архитектуры с быстрыми весами позволяют обрабатывать контексты значительно большей длины, чем традиционные модели-трансформеры. Это достигается за счет отказа от механизмов внимания, требующих квадратичной сложности по длине последовательности, и использования фиксированных блоков памяти. В результате, модели на основе таких архитектур способны эффективно обрабатывать последовательности, насчитывающие десятки и сотни тысяч токенов, что критически важно для задач, требующих анализа взаимосвязей на больших расстояниях, таких как обработка длинных текстов, анализ видео или геномные исследования. Возможность захвата долгосрочных зависимостей является основой для улучшения способности к логическому выводу и рассуждениям, основанным на контексте.
Оптимизация когерентности: предсказание последовательностей и ReFINE
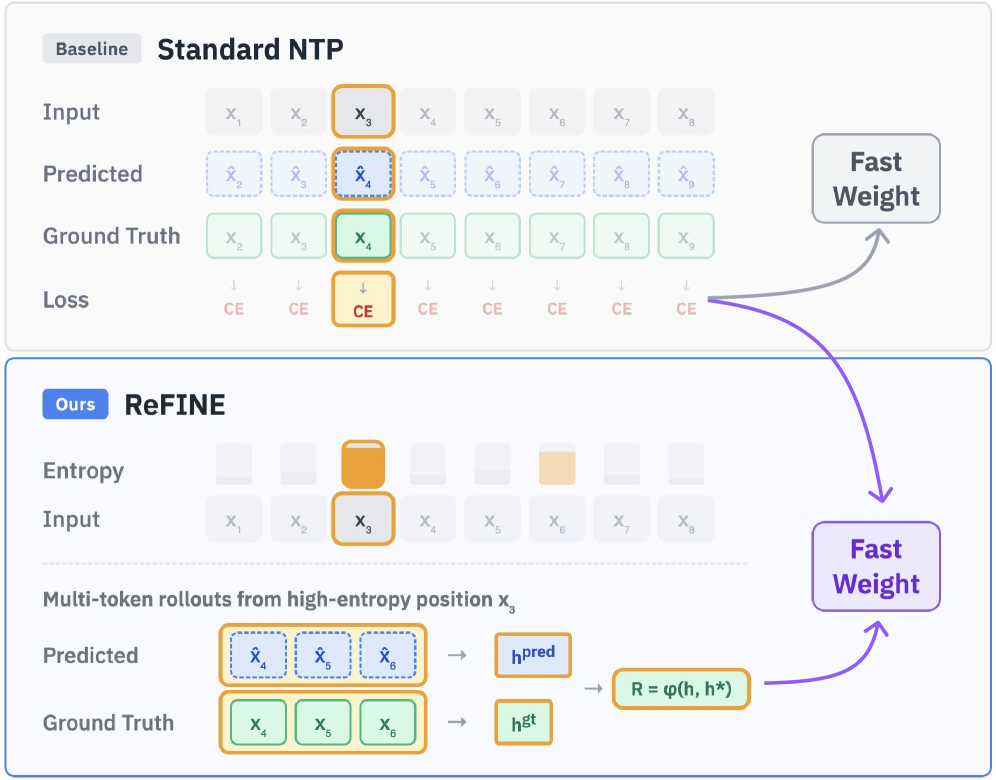
В отличие от традиционной задачи предсказания следующего токена, подход «Предсказание следующей последовательности» (Next Sequence Prediction) нацелен на генерацию связных последовательностей, что способствует улучшению способности модели к долгосрочному рассуждению. Вместо оптимизации вероятности каждого отдельного токена, данный метод фокусируется на оценке когерентности и логической связи между группами токенов, что позволяет модели лучше понимать и воспроизводить сложные зависимости в тексте. Это особенно важно для задач, требующих анализа больших объемов информации и выявления скрытых связей, где традиционное предсказание токенов может приводить к фрагментированным и непоследовательным результатам.
Фреймворк ReFINE использует обучение с подкреплением (Reinforcement Learning) для оптимизации предсказаний последовательностей. В его основе лежит использование “награды на уровне последовательности” (Sequence-Level Reward), которая позволяет модели оценивать и улучшать не отдельные токены, а всю предсказанную последовательность целиком. Это позволяет ReFINE ориентироваться на общую связность и релевантность генерируемого текста, в отличие от традиционных методов, фокусирующихся на предсказании следующего токена. Такой подход позволяет модели более эффективно улавливать долгосрочные зависимости и генерировать более когерентные и логичные тексты.
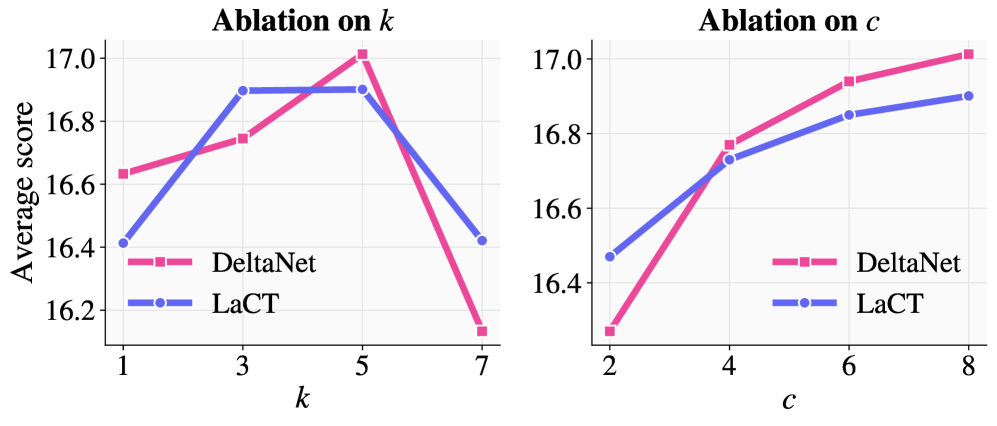
В рамках ReFINE для повышения эффективности обучения используется метод отбора токенов на основе энтропии. Данный подход позволяет модели концентрироваться на наиболее информативных участках контекста, что способствует более эффективному обучению и улучшению способности к долгосрочному рассуждению. В ходе экспериментов было установлено, что применение этого метода приводит к увеличению производительности до 15.3% в задачах вопросно-ответной системы RULER, требующих работы с длинным контекстом. В частности, LaCT-760M показал улучшение на 8.5%, а DeltaNet-1.3B — на 20.3% при использовании данного метода обучения.
В ходе промежуточного обучения, фреймворк ReFINE продемонстрировал значительное улучшение показателей на задаче RULER (long-context QA). Модель LaCT-760M, обученная с использованием ReFINE, показала прирост в 8.5% относительно базовых показателей. Более существенный прирост был зафиксирован для модели DeltaNet-1.3B, которая улучшила свой результат на 20.3% при использовании той же методики обучения. Данные результаты демонстрируют эффективность ReFINE в оптимизации моделей для работы с длинным контекстом и повышения точности ответов на вопросы.
Бенчмаркинг и перспективы развития: где мы и куда идём
Для объективной оценки возможностей моделей, работающих с длинными последовательностями данных, необходимы специализированные инструменты. Именно поэтому ключевое значение приобретают бенчмарки, такие как LongBench и RULER. Они позволяют тщательно измерить способность моделей не просто обрабатывать увеличенный объем информации, но и понимать ее, выявлять взаимосвязи и логически рассуждать на основе предоставленного контекста. Эти бенчмарки служат стандартом для сравнения различных архитектур и методов обучения, способствуя прогрессу в области обработки длинных последовательностей и открывая новые перспективы для решения сложных задач, требующих глубокого понимания контекста.
Архитектуры быстрых весов, несмотря на свою эффективность, могут быть дополнительно усовершенствованы посредством нескольких стратегий обучения. Методика “Mid-Training” предполагает корректировку параметров модели в середине процесса обучения, позволяя адаптироваться к особенностям данных. “Post-Training” фокусируется на дообучении уже готовой модели, используя специализированные наборы данных для повышения производительности в конкретных задачах. Наиболее передовым подходом является “Test-Time Training”, когда модель обучается непосредственно во время выполнения, адаптируясь к входным данным в реальном времени. Такой подход позволяет добиться существенного улучшения результатов, поскольку модель динамически оптимизирует свои параметры для каждого конкретного примера, обеспечивая более точные и релевантные прогнозы.
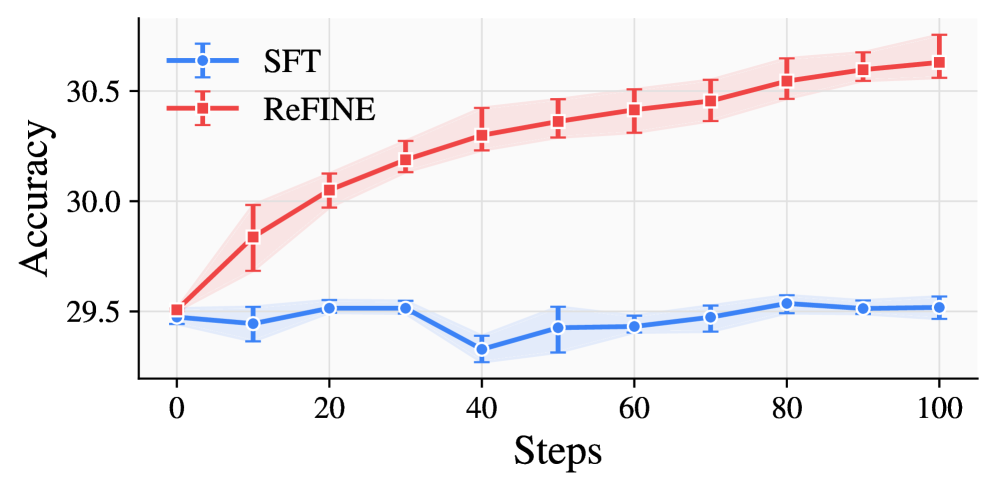
Исследования показали значительное улучшение производительности моделей LaCT-760M и DeltaNet-1.3B после применения метода постобучения ReFINE на эталонном наборе данных RULER. В частности, модель LaCT-760M продемонстрировала прирост в 15.3%, а DeltaNet-1.3B — в 11.0%. Эти результаты подчеркивают эффективность постобучения в адаптации моделей к задачам, требующим понимания и обработки длинных последовательностей, и свидетельствуют о потенциале ReFINE как инструмента для повышения точности и надежности моделей при работе с большими объемами информации.
Дальнейшее повышение эффективности моделей достигается за счет обучения в процессе тестирования — подхода, продемонстрировавшего значительные улучшения в производительности. В ходе экспериментов с архитектурами LaCT-760M и DeltaNet-1.3B, применение данной методики позволило зафиксировать прирост в 9.5% и 15.0% соответственно. Полученные результаты свидетельствуют о том, что адаптация весов модели непосредственно во время обработки новых данных позволяет ей более эффективно использовать накопленные знания и решать поставленные задачи с повышенной точностью. Этот подход открывает перспективы для создания более гибких и производительных систем, способных к самообучению и адаптации к изменяющимся условиям.
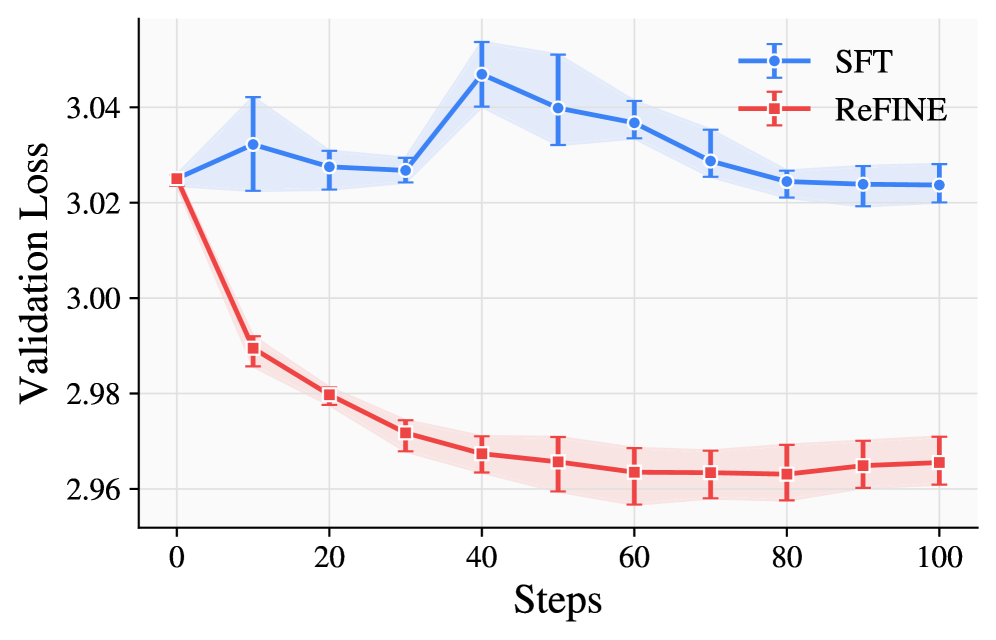
В представленной работе наблюдается стремление к преодолению ограничений традиционных подходов в моделировании длинных последовательностей. Авторы предлагают ReFINE — систему, использующую обучение с подкреплением для оптимизации быстрых весов. Этот подход, ориентированный на предсказание следующей последовательности, позволяет улучшить возможности модели на протяжении всего цикла обучения. Как отмечал Брайан Керниган: «Простота — это конечное совершенство». В данном случае, элегантность ReFINE заключается в использовании простого, но эффективного принципа предсказания следующей последовательности для достижения значительного прогресса в области обучения моделей с длинным контекстом, демонстрируя, что иногда самые эффективные решения — самые лаконичные.
Куда же дальше?
Предложенный в данной работе фреймворк ReFINE, безусловно, демонстрирует интересную возможность — приручить быстрые веса, используя логику обучения с подкреплением и предсказание следующей последовательности. Однако, не стоит обольщаться. Эффективность метода, как и любого другого, неизбежно ограничена. Вопрос в том, где именно кроются эти ограничения? Полагается ли оптимизация исключительно на качество предсказания следующей последовательности, или существуют скрытые факторы, влияющие на стабильность и обобщающую способность модели? Это, пожалуй, отправная точка для дальнейших исследований.
Интересно было бы исследовать, как ReFINE взаимодействует с различными архитектурами быстрых весов. Универсален ли этот подход, или для каждой архитектуры потребуется своя тонкая настройка и специфические функции вознаграждения? Более того, не является ли предсказание следующей последовательности лишь одним из множества возможных «сигналов» для обучения быстрых весов? Возможно, комбинация различных задач и функций потерь позволит достичь еще более впечатляющих результатов, выходя за рамки текущих ограничений.
И, конечно, не стоит забывать о фундаментальном вопросе: что есть «контекст» для модели? Просто ли это набор токенов, или же необходимо учитывать более сложные зависимости и взаимосвязи? Поиск ответов на эти вопросы — это, возможно, и есть настоящий вызов для исследователей, стремящихся создать по-настоящему «разумные» модели обработки последовательностей. Ведь, в конце концов, даже самый изощренный алгоритм — лишь отражение той реальности, которую он пытается смоделировать.
Оригинал статьи: https://arxiv.org/pdf/2602.16704.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Серебро и медь: новый взгляд на наноаллои
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Искусственный интеллект и квантовая физика: кто кого?
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Наука на благо бизнеса: как публикации стимулируют инновации
- Научный интеллект на пределе: новая оценка возможностей ИИ
- Сборка RAG: Архитектура и доверие в системах генерации с поиском
2026-02-19 22:31