Автор: Денис Аветисян
Исследователи представили SnapMLA — систему, оптимизирующую процесс декодирования в моделях Multi-Head Latent Attention для эффективной работы с большими объемами данных.
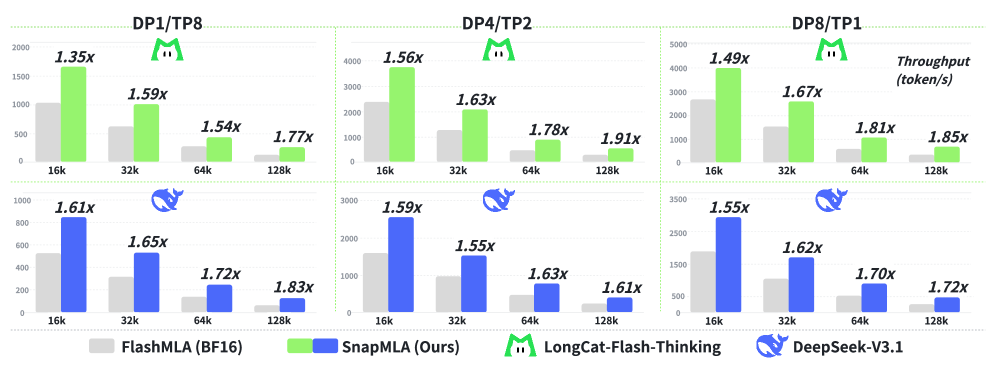
SnapMLA использует FP8 квантование и аппаратную оптимизацию для значительного увеличения скорости обработки длинных контекстов в моделях машинного обучения.
Несмотря на перспективность использования 8-битного представления с плавающей точкой (FP8) для повышения эффективности внимания, его интеграция в этап декодирования архитектуры Multi-head Latent Attention (MLA) сталкивается со значительными трудностями. В данной работе представлена система SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining, оптимизированный фреймворк для декодирования MLA с использованием FP8, который обеспечивает существенное увеличение пропускной способности при работе с длинными контекстами. Реализованные аппаратные и алгоритмические улучшения, включая адаптивную квантизацию и оптимизацию потока данных, позволяют добиться прироста производительности до 1.91x без потери точности. Какие дальнейшие шаги необходимы для адаптации подобных методов к еще более сложным задачам и аппаратным платформам?
Время и контекст: вызовы больших языковых моделей
Современные большие языковые модели (БЯМ) все чаще демонстрируют зависимость от обработки обширных объемов данных — так называемого “длинного контекста” — для достижения производительности, сопоставимой с человеческой. Эта тенденция обусловлена необходимостью понимания сложных взаимосвязей в тексте, анализа больших документов и поддержания последовательности в длинных диалогах. Способность эффективно обрабатывать длинный контекст позволяет БЯМ решать задачи, ранее недоступные, такие как суммирование объемных научных статей, ответы на вопросы по сложным юридическим документам или генерация связных повествований, требующих запоминания деталей из начала текста. По мере развития искусственного интеллекта, умение оперировать длинным контекстом становится ключевым фактором, определяющим возможности и применимость БЯМ в различных областях знаний и практической деятельности.
Традиционные механизмы внимания, лежащие в основе работы крупных языковых моделей, сталкиваются с серьезными ограничениями при обработке длинных последовательностей текста. Эти механизмы используют так называемый “KV-кэш” — хранилище ключей и значений, необходимое для вычисления весов внимания. Однако, объем этого кэша растет линейно с увеличением длины входной последовательности. Это означает, что обработка удвоенного объема текста требует удвоенного объема памяти и вычислительных ресурсов, что быстро становится непосильным для современных аппаратных средств. В результате, производительность моделей значительно снижается, а возможность эффективно анализировать и извлекать информацию из длинных документов или повествований существенно ограничивается. Данное ограничение является ключевой проблемой в развитии языковых моделей, способных понимать и обрабатывать сложные тексты, приближаясь к человеческому уровню понимания.
Ограничение, связанное с масштабируемостью механизма внимания, существенно затрудняет способность больших языковых моделей эффективно анализировать и делать выводы на основе развернутых повествований или сложных документов. При обработке длинных текстов, модели испытывают трудности с удержанием важной информации в контексте, что приводит к снижению точности ответов и ухудшению качества рассуждений. Это особенно заметно при решении задач, требующих понимания взаимосвязей между событиями, описанными в различных частях текста, или при поиске конкретных деталей в объёмном массиве информации. В результате, несмотря на впечатляющие успехи в обработке коротких текстов, способность к глубокому и осмысленному анализу длинных документов остается серьезным вызовом для современных больших языковых моделей.
Многоголовое скрытое внимание: сокращение следа в памяти
Многоголовое скрытое внимание (Multi-Head Latent Attention) снижает требования к памяти за счет применения компрессии с помощью низкорангового представления к KV-кэшу. Вместо хранения полных матриц ключей (Key) и значений (Value), алгоритм использует разложение матриц на компоненты меньшего размера, что позволяет значительно уменьшить объем необходимой памяти. Это достигается за счет аппроксимации исходных матриц с использованием матриц меньшей размерности, сохраняя при этом достаточную точность для эффективного вычисления внимания. Степень сжатия регулируется параметром ранга, позволяя находить баланс между снижением потребления памяти и сохранением качества модели. Применение данного метода особенно эффективно при обработке длинных последовательностей, где размер KV-кэша становится критическим фактором.
Архитектура Multi-Head Latent Attention эффективно сжимает состояния внимания (attention states) за счет использования низкоранговых приближений. Это позволяет значительно снизить объем памяти, требуемый для хранения и обработки промежуточных результатов при работе с длинными последовательностями. Вместо хранения полных матриц Q, K, V, система сохраняет сжатые представления, что напрямую влияет на масштабируемость модели. Степень сжатия контролируется рангом аппроксимации, позволяя находить компромисс между снижением потребления памяти и сохранением точности вычислений. Данный подход особенно актуален при обработке длинных текстов, изображений высокого разрешения и других типов данных, где размер KV-кэша становится ограничивающим фактором.
Многоголовое латентное внимание (Multi-Head Latent Attention) расширяет возможности традиционного механизма внимания, предоставляя основу для более эффективной обработки длинных контекстов. В отличие от стандартного внимания, требующего хранения всех промежуточных состояний ключей и значений (KV Cache) для каждого токена во входной последовательности, данная архитектура позволяет сократить объем необходимой памяти. Это достигается за счет применения методов сжатия, что особенно важно при работе с последовательностями большой длины, где требования к памяти быстро растут. Снижение потребления памяти позволяет обрабатывать более длинные последовательности при том же объеме доступной памяти или, альтернативно, использовать меньшие вычислительные ресурсы для обработки последовательностей той же длины, что делает его перспективным решением для задач, требующих анализа больших объемов данных.
SnapMLA: аппаратная оптимизация и совместная настройка
SnapMLA — это новый фреймворк для совместной оптимизации алгоритмов и ядер оборудования, разработанный для существенного повышения эффективности декодирования MLA в задачах работы с длинными контекстами. В основе SnapMLA лежит подход, ориентированный на использование 8-битного формата с плавающей точкой (FP8) и адаптацию к специфике аппаратной платформы. Этот подход позволяет добиться значительного ускорения вычислений и снижения потребления памяти по сравнению с традиционными методами, особенно при обработке последовательностей большой длины. Фреймворк предназначен для оптимизации как алгоритмической части, так и низкоуровневых ядер, используемых для реализации алгоритма, что обеспечивает максимальную производительность на целевом оборудовании.
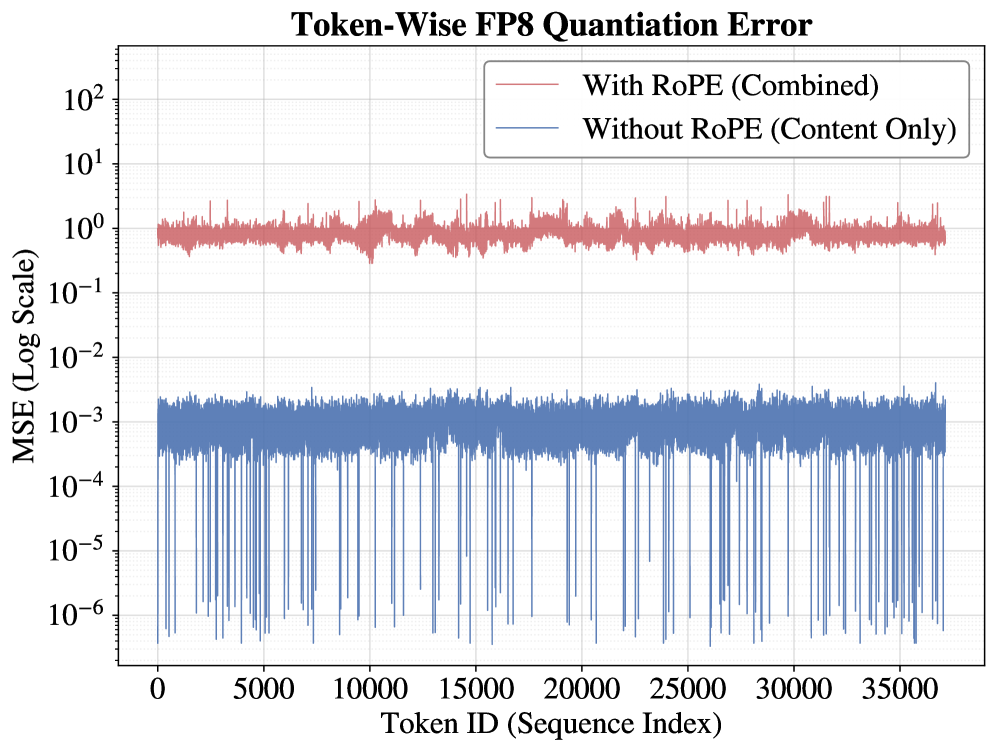
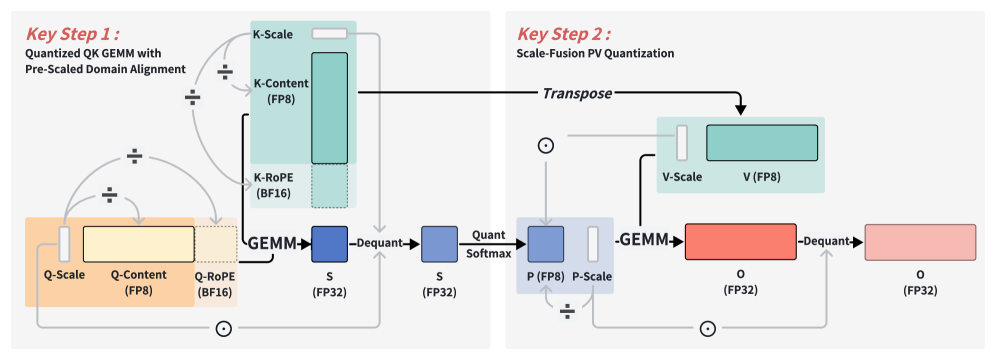
SnapMLA использует метод ‘RoPE-Aware Per-Token Quantization’ для решения проблемы числовой чувствительности компонента ‘RoPE’ (Rotary Positional Embedding) при квантовании. Традиционное квантование, применяемое к весам и активациям, может привести к значительной потере точности в компоненте ‘RoPE’, поскольку он опирается на синусоидальные и косинусоидальные функции, чувствительные к изменениям масштаба и точности. Данный метод квантует каждый токен индивидуально, учитывая особенности представления позиционной информации в ‘RoPE’, что позволяет минимизировать потерю точности при переходе к пониженной точности представления данных (например, FP8) и поддерживать высокую производительность при декодировании длинных последовательностей.
Ключевым фактором эффективности SnapMLA является реконструкция конвейера вычислений PV после квантования, направленная на устранение несоответствия масштабов в операциях GEMM (General Matrix Multiplication). В процессе квантования, особенно при снижении точности, возникают расхождения в диапазонах значений, что приводит к потере информации и снижению точности вычислений. Реконструкция конвейера PV включает в себя перемасштабирование и нормализацию промежуточных результатов GEMM операций, обеспечивая согласованность масштабов между квантованными тензорами и предотвращая накопление ошибок округления. Это позволяет сохранить производительность и точность при работе с квантованными моделями, особенно в задачах декодирования длинных контекстов.
Аппаратное ускорение и сквозная оптимизация
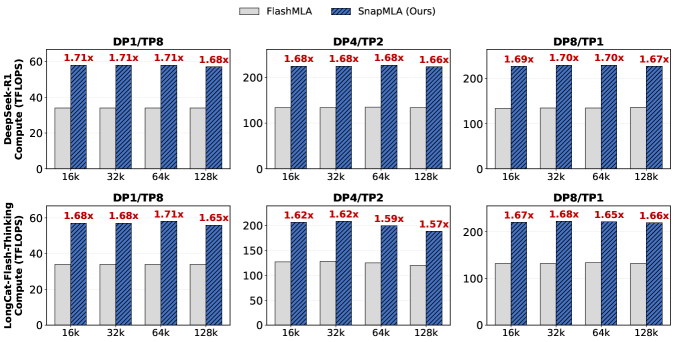
SnapMLA разработана с учетом архитектуры NVIDIA Hopper и ее тензорных ядер, что позволяет значительно ускорить операции матричного умножения. В основе лежит принцип максимального использования специализированных аппаратных ресурсов для выполнения ключевых вычислений, характерных для современных моделей машинного обучения. Такой подход позволяет добиться существенного прироста производительности по сравнению с традиционными методами, поскольку тензорные ядра оптимизированы для параллельной обработки больших объемов данных, что критически важно для эффективной работы с нейронными сетями. Благодаря этой интеграции, SnapMLA способна эффективно использовать вычислительные возможности графических процессоров NVIDIA для решения сложных задач, требующих интенсивных матричных вычислений.
Квантование до формата FP8 играет ключевую роль в максимизации производительности тензорных ядер NVIDIA Hopper. Вместо использования более традиционных форматов, таких как BF16, FP8 позволяет значительно увеличить пропускную способность вычислений, поскольку требует меньшего объема памяти и обеспечивает более эффективное использование аппаратных ресурсов. Этот подход позволяет обрабатывать большие объемы данных быстрее и с меньшими затратами энергии, что особенно важно для задач глубокого обучения и искусственного интеллекта, требующих интенсивных матричных вычислений. Благодаря FP8, тензорные ядра могут выполнять больше операций за единицу времени, что приводит к существенному ускорению всей вычислительной системы.
Оптимизация сквозного потока данных в SnapMLA достигается за счет комплексного применения техник параллелизма. В частности, параллелизм данных позволяет распределить обработку отдельных пакетов данных между различными вычислительными узлами, значительно ускоряя общую скорость вычислений. Дополнительно, используется тензорный параллелизм, который разбивает сами тензорные операции на части, распределяя их между ядрами и максимизируя использование доступных ресурсов. Такой подход не только ускоряет обработку, но и существенно снижает задержки, связанные с запуском ядер, что особенно важно при работе с большими объемами данных и сложными моделями. В результате, достигается значительное повышение производительности и эффективности работы системы.
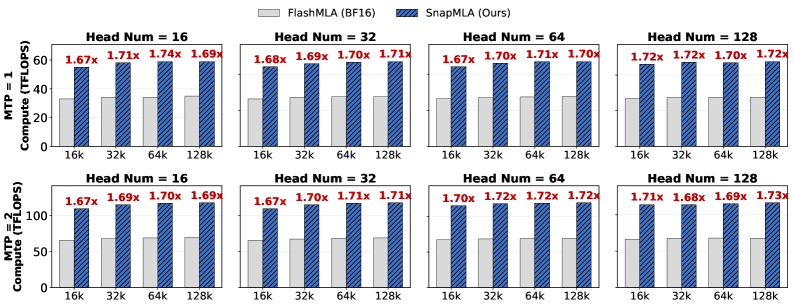
FlashMLA: ускорение декодирования MLA на Hopper
Разработанный специализированный программный модуль, получивший название ‘FlashMLA’, значительно ускоряет процесс декодирования ‘Multi-Head Latent Attention’ (MLA) на графических процессорах Hopper. Этот модуль представляет собой оптимизированное ядро, которое эффективно использует архитектурные особенности Hopper, включая улучшенный поток данных и вычислительные ресурсы. В отличие от стандартных реализаций MLA, ‘FlashMLA’ позволяет добиться существенного прироста производительности при обработке больших объемов данных, что критически важно для современных языковых моделей. Благодаря оптимизации вычислений и использованию специфических возможностей Hopper, ‘FlashMLA’ открывает новые перспективы для увеличения скорости и эффективности обработки информации в задачах искусственного интеллекта.
Ядро FlashMLA спроектировано с учетом особенностей архитектуры Hopper, что позволяет максимально эффективно использовать её вычислительные ресурсы и оптимизированный поток данных. В отличие от традиционных подходов, FlashMLA адаптируется к специфике Hopper, минимизируя перемещение данных между памятью и процессором. Это достигается за счет организации вычислений таким образом, чтобы максимально использовать возможности параллельной обработки Hopper и снизить задержки, связанные с передачей информации. В результате, ядро FlashMLA не просто ускоряет процесс декодирования MLA, но и позволяет более эффективно использовать доступные ресурсы, открывая путь к созданию более мощных и производительных языковых моделей.
Сочетание SnapMLA и FlashMLA открывает принципиально новые перспективы для больших языковых моделей (LLM), позволяя им обрабатывать значительно более обширные контексты. Это расширение контекстного окна не просто увеличивает объем информации, доступной модели, но и качественно меняет ее возможности в области рассуждений, понимания и генерации текста. Способность учитывать большее количество предшествующих данных позволяет LLM строить более сложные и логичные цепочки умозаключений, глубже понимать нюансы языка и создавать более связные и осмысленные тексты. Таким образом, данные оптимизации позволяют преодолеть ограничения, связанные с длиной контекста, и приближают к созданию LLM, способных решать задачи, требующие глубокого анализа и комплексного понимания информации.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации систем искусственного интеллекта не ради мгновенного результата, а ради их устойчивости во времени. SnapMLA, сфокусированный на эффективном выводе моделей MLA с использованием квантования FP8, отражает понимание того, что любая абстракция несет груз прошлого, а медленные, продуманные изменения — залог долговечности. Блез Паскаль некогда заметил: «Все великие вещи требуют времени». Эта фраза перекликается с подходом, реализованным в SnapMLA, где акцент сделан на аппаратную оптимизацию и снижение вычислительной нагрузки для обеспечения стабильной работы моделей при обработке длинных контекстов. Данный подход позволяет создавать системы, способные адаптироваться к изменяющимся требованиям, а не устаревать под давлением времени.
Куда же дальше?
Представленная работа, оптимизируя Multi-Head Latent Attention через квантование FP8, демонстрирует, что даже в эпоху стремительной гонки за производительностью, у каждого упрощения есть своя цена. Ускорение вычислений — не самоцель, а лишь способ отсрочить неизбежное: экспоненциальный рост сложности систем обработки информации. Внедрение SnapMLA — это, скорее, локальное облегчение, чем фундаментальное решение проблемы масштабируемости. Вопрос в том, насколько долго удастся поддерживать приемлемый уровень точности при дальнейшем снижении разрядности, не превратив систему в эхо-камеру собственных ошибок.
Очевидно, что дальнейшие исследования потребуют выхода за рамки оптимизации отдельных слоев. Необходимо переосмыслить архитектуру LLM в целом, учитывая не только вычислительные ресурсы, но и энергетическую эффективность, а также устойчивость к искажениям данных. Игнорирование “технического долга” — то есть, накопления упрощений, которые в будущем потребуют дорогостоящей переработки — приведет лишь к более хрупким и непредсказуемым системам.
Вероятно, будущее за гибридными подходами, сочетающими преимущества различных методов квантования и оптимизации, а также за адаптивными системами, способными динамически изменять свою структуру в зависимости от контекста и доступных ресурсов. Время, как среда, в которой существуют системы, неизбежно потребует от них большей гибкости и устойчивости, чем просто скорости вычислений.
Оригинал статьи: https://arxiv.org/pdf/2602.10718.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Разреженность и масштаб: семейство языковых моделей Trinity
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
- Быстрый поиск по геному: Новые алгоритмы для spaced k-mers
- Квантовые машины Больцмана для обучения с подкреплением: новый подход
- Раскрывая потенциал языковых моделей: новый взгляд на оценку
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Квантовый скачок и финансовая бездна
- Понимание сложных систем: новый взгляд на агентные модели
- Квантовые Игры и Цифровое Сотрудничество: Взгляд изнутри
- Юридический интеллект на турецком: Новые модели для понимания права
2026-02-13 05:02