Автор: Денис Аветисян
Новая архитектура объединяет FPGA и Ising-машину для значительного повышения скорости решения комбинаторных задач.
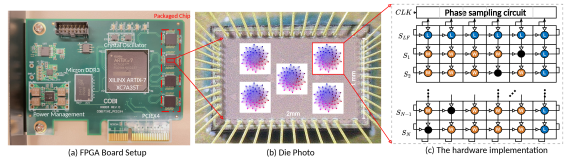
Предлагается гибридный подход, использующий FPGA для декомпозиции задач и аналого-цифровое со-проектирование для эффективного параллельного вычисления.
Несмотря на перспективность аналоговых вычислительных систем, таких как осцилляторные машины Изинга, их масштабируемость ограничена физическими факторами. В данной работе, ‘Decomposing Large-Scale Ising Problems on FPGAs: A Hybrid Hardware Approach’, предлагается гетерогенная архитектура, в которой задача декомпозиции для решения крупномасштабных задач комбинаторной оптимизации переносится на ПЛИС, плотно интегрированную с заказной 28-нм машиной Изинга. Предложенный подход позволяет минимизировать задержки, связанные с обменом данными между цифровым и аналоговым доменами, и добиться ускорения решения практически в 2 раза и повышения энергоэффективности более чем на два порядка по сравнению с программными реализациями на современных процессорах. Не откроет ли данная гибридная архитектура новые возможности для решения сложных задач оптимизации в различных областях науки и техники?
В поисках гармонии: Комбинаторные задачи и модель Изинга
Многие задачи, с которыми сталкиваются современные технологии и бизнес, по своей сути являются задачами комбинаторной оптимизации. От планирования оптимальных маршрутов доставки и управления логистическими цепочками до обучения сложных моделей машинного обучения и разработки финансовых стратегий — во всех этих областях необходимо найти наилучшее решение из огромного множества возможных комбинаций. Например, задача коммивояжера, поиск кратчайшего пути между множеством городов, является классическим примером комбинаторной оптимизации. Сложность заключается в том, что количество возможных маршрутов экспоненциально растет с увеличением числа городов, делая перебор всех вариантов практически невозможным. Подобные задачи характеризуются тем, что даже небольшое увеличение масштаба приводит к значительному увеличению вычислительных затрат, что требует разработки новых, более эффективных подходов к решению.
Традиционные алгоритмы, предназначенные для решения сложных задач оптимизации, часто сталкиваются с непреодолимыми трудностями по мере увеличения масштаба проблемы. Суть заключается в том, что количество возможных решений растет экспоненциально, то есть с каждым добавленным элементом или параметром, число вариантов, которые необходимо проверить, увеличивается в разы. Например, задача о коммивояжере, где необходимо найти кратчайший маршрут, посетив все заданные города, демонстрирует эту проблему в полной мере. Подобный экспоненциальный рост вычислительной сложности делает классические методы неприменимыми для задач, включающих даже относительно небольшое количество переменных. Это требует поиска принципиально новых подходов, способных эффективно справляться с огромными пространствами решений и находить оптимальные или близкие к оптимальным результаты за приемлемое время. Необходимость инноваций обусловлена не только теоретическими ограничениями, но и растущими потребностями в решении сложных задач в различных областях, от логистики и финансов до машинного обучения и материаловедения.
Модель Изинга представляет собой мощный математический аппарат для представления широкого спектра задач комбинаторной оптимизации в виде задачи минимизации энергии. В данной модели каждому возможному решению задачи сопоставляется определенное энергетическое состояние, при этом оптимальное решение соответствует состоянию с минимальной энергией. Вместо прямого перебора всех возможных вариантов, алгоритмы, использующие модель Изинга, стремятся найти конфигурацию системы, в которой энергия минимизирована, что позволяет эффективно решать сложные задачи, такие как планирование маршрутов, оптимизация логистических цепочек и обучение моделей машинного обучения. E = - \sum_{i} J_{ij} s_i s_j - \sum_{i} h_i s_i — эта формула описывает энергию системы, где s_i — спин i-го узла, J_{ij} — взаимодействие между узлами i и j, а h_i — внешнее поле, воздействующее на i-й узел. Такое преобразование позволяет использовать физические принципы и методы для решения сложных вычислительных задач.
Аналоговые решатели, в особенности использующие связанные осцилляторы, представляют собой перспективный подход к ускорению и повышению эффективности решения сложных задач. В отличие от цифровых систем, которые дискретизируют пространство поиска, аналоговые устройства способны одновременно исследовать множество возможных решений, что позволяет существенно сократить время вычислений. Связанные осцилляторы, взаимодействуя друг с другом, формируют динамическую систему, состояние которой соответствует минимуму энергии — аналогу оптимального решения исходной комбинаторной задачи. E = -J \sum_{<i,j>} s_i s_j - h \sum_i s_i — в этой упрощенной модели Изинга, энергия системы минимизируется путем настройки взаимодействий между осцилляторами, что позволяет находить приближенные решения за время, не зависящее экспоненциально от размера задачи. Такой подход открывает новые возможности для решения задач, непосильных для классических алгоритмов, в областях от машинного обучения до материаловедения.
Чип COBI: Аналоговый решатель и системная интеграция
Чип COBI реализует взаимодействие спинов модели Изинга посредством 50 связанных CMOS кольцевых генераторов. Каждый генератор представляет собой спин, а его частота колебаний кодирует его состояние. Связи между генераторами физически реализуются посредством резистивных соединений, определяющих силу взаимодействия между соответствующими спинами. Такая аналоговая реализация позволяет напрямую решать задачу минимизации энергии, используя физические свойства системы, а не цифровые вычисления. Интенсивность связи между генераторами определяется значениями сопротивлений, заданными в процессе производства чипа, что обеспечивает аппаратную реализацию матрицы связей графа Изинга.
Аналоговый подход в архитектуре COBI использует присущий физическим системам параллелизм для ускорения минимизации энергии. Вместо последовательного выполнения вычислений, как в традиционных цифровых системах, COBI реализует энергетическую функцию Изинговской модели непосредственно в физической форме. Параллельная работа 50 связанных CMOS-генераторов позволяет одновременно оценивать множество возможных состояний, что существенно сокращает время, необходимое для нахождения состояния с минимальной энергией. Этот подход позволяет избежать узких мест, характерных для последовательной обработки, и эффективно использовать физические свойства полупроводниковых элементов для решения задач оптимизации.
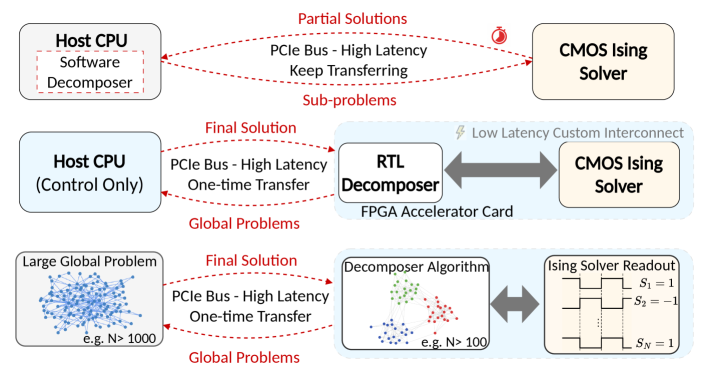
Для обеспечения эффективной интеграции с внешними системами, чип COBI использует высокоскоростной интерфейс PCIe (Peripheral Component Interconnect Express). Выбор PCIe обусловлен необходимостью передачи больших объемов данных между чипом и центральным процессором (CPU) хост-системы с минимальной задержкой. Интерфейс PCIe обеспечивает пропускную способность, достаточную для обмена информацией о состоянии спинов и параметрах задачи оптимизации, что критически важно для скорости решения задач и масштабируемости системы. Реализация PCIe позволяет эффективно использовать вычислительные ресурсы CPU для предварительной и постобработки данных, а также для управления процессом оптимизации на чипе COBI.
Производительность чипа COBI напрямую зависит от эффективного представления графа связей между спинами, для чего используется формат Compressed Sparse Row (CSR). В формате CSR матрица, представляющая граф, хранится в трех одномерных массивах: массив значений спинов, массив индексов строк и массив указателей на начало каждой строки. Такое представление позволяет минимизировать объем памяти, необходимый для хранения больших разреженных графов, характерных для задач оптимизации, и ускоряет доступ к элементам матрицы, что критически важно для параллельного выполнения алгоритмов минимизации энергии. Эффективность CSR особенно заметна при работе с графами, где большинство связей отсутствует, что типично для многих практических задач.
FPGA-декомпозиция: Масштабирование Ising-машин для решения сложных задач
FPGA-декомпозитор выполняет разделение крупных комбинаторных задач на более мелкие подзадачи, которые могут быть обработаны чипом COBI. Этот процесс позволяет эффективно масштабировать решение сложных проблем, превосходящие возможности одночиповой обработки. Декомпозиция осуществляется путем разбиения исходной задачи на набор независимых или слабо связанных подзадач, каждая из которых может быть решена параллельно на чипе COBI. Такой подход позволяет существенно снизить вычислительную сложность и время решения, особенно для задач, где количество переменных и ограничений велико. Эффективность декомпозитора заключается в алгоритмах, которые минимизируют объем передаваемых данных между FPGA и COBI, обеспечивая высокую пропускную способность и снижая задержки.
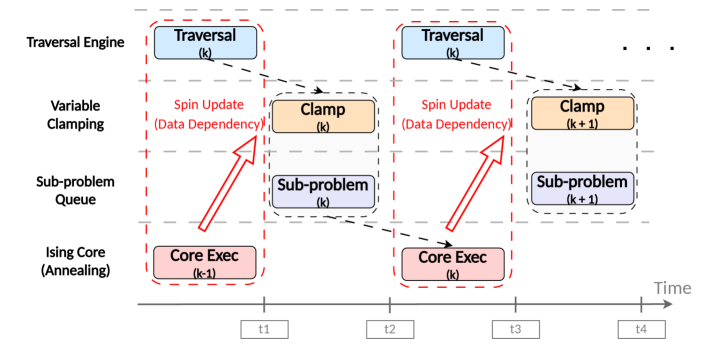
Декомпозиция сложных комбинаторных задач достигается посредством методов фиксации переменных (variable clamping) и генерации подзадач. Фиксация переменных предполагает предварительное назначение значений определенным переменным, что уменьшает размер пространства поиска для оставшихся переменных. Генерация подзадач разбивает исходную задачу на множество меньших, более управляемых подзадач, решения которых затем комбинируются для получения решения исходной задачи. Данный подход позволяет снизить вычислительную сложность оптимизации, особенно для задач, где прямая оптимизация на всем пространстве переменных нецелесообразна.
Ускорение процесса декомпозиции достигается за счет применения двухуровневого параллелизма. Пространственный параллелизм реализуется путем одновременной обработки различных частей проблемы на FPGA, в то время как параллелизм на уровне задач заключается в параллельном выполнении нескольких этапов декомпозиции. Дополнительно, конвейерная обработка (pipelining) позволяет перекрывать выполнение различных этапов, повышая пропускную способность и снижая общую задержку. Комбинация этих техник позволяет значительно ускорить процесс разбиения сложной задачи на подзадачи, пригодные для решения на чипе COBI.
Высокоскоростная связь с чипом обеспечивается за счет использования интерфейса AXI4 и памяти DDR для хранения данных. В результате переноса процесса декомпозиции на FPGA система демонстрирует 1.93-кратное среднее геометрическое ускорение по сравнению с CPU-реализацией. Интерфейс AXI4 позволяет эффективно передавать данные между FPGA и основной системой, а использование памяти DDR обеспечивает необходимый объем хранения для промежуточных результатов декомпозиции, что в совокупности значительно повышает производительность.
Временное рассогласование и перспективы развития
Существенным ограничением предложенного гибридного подхода является временное рассогласование между декомпозицией, выполняемой на FPGA, и работой аналогового решателя. Это рассогласование приводит к неоптимальному использованию ресурсов и снижает общую эффективность системы. Несоответствие во времени выполнения операций на FPGA и аналоговом блоке требует дополнительных затрат на синхронизацию и может приводить к простоям одного из компонентов, что снижает пропускную способность и увеличивает энергопотребление. Повышение эффективности требует разработки стратегий минимизации этого рассогласования, например, за счет оптимизации конвейерной обработки данных или адаптивной синхронизации между FPGA и аналоговым решателем, что позволит максимально использовать преимущества обоих подходов.
Для полной реализации потенциала гибридного подхода, включающего FPGA-декомпозицию и аналоговый решатель, критически важна минимизация временного расхождения между ними. Исследования показывают, что несогласованность во времени может существенно снижать общую эффективность системы. Разрабатываются стратегии, направленные на синхронизацию работы этих двух компонентов, включая оптимизацию протоколов обмена данными и адаптацию частоты работы FPGA к скорости аналогового решателя. Успешная реализация этих стратегий позволит значительно сократить задержки и повысить энергоэффективность, открывая возможности для решения более сложных задач в режиме реального времени и расширения области применения данной архитектуры.
Предложенная архитектура демонстрирует расширяемость за счет возможности решения задач 3SAT, что достигается посредством отображения дизъюнктивных нормальных форм (клауз) в квадратичные штрафы с использованием конструкции Чанселора. Этот метод позволяет эффективно кодировать логические ограничения задачи 3SAT в виде оптимизационной задачи, пригодной для решения с помощью гибридной FPGA-аналоговой системы. По сути, каждое нарушение клаузы преобразуется в штраф, пропорциональный квадрату нарушения, что позволяет аналоговому решателю находить решения, минимизирующие общую стоимость штрафа. Такой подход открывает перспективы для решения более сложных логических задач с использованием преимуществ энергоэффективности и низкой задержки, присущих данной архитектуре.
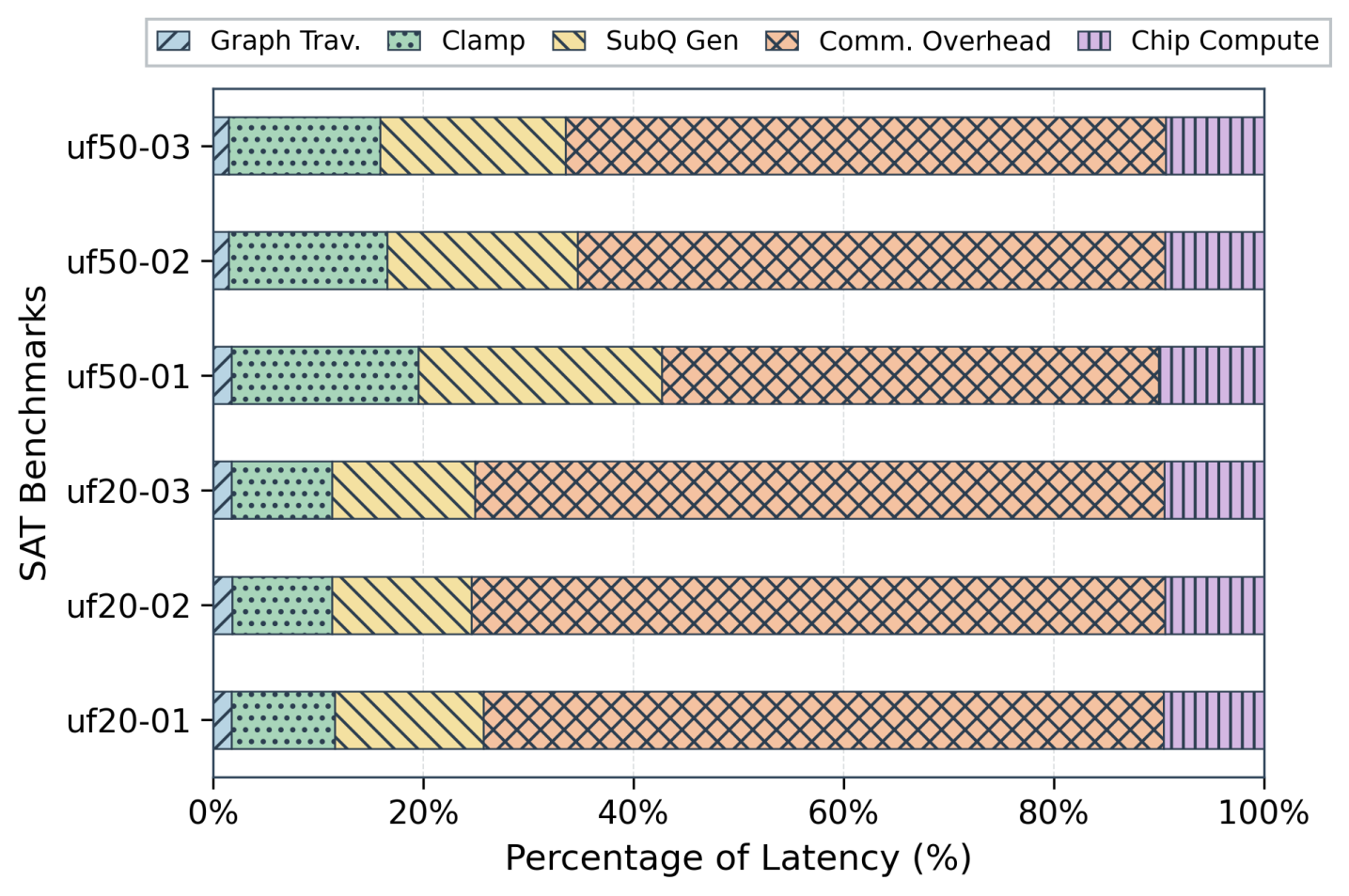
Представленная архитектура демонстрирует значительное повышение эффективности за счет существенного снижения энергопотребления и задержек связи. В ходе тестирования на эталонном примере uf20, удалось добиться более чем 150-кратного уменьшения потребляемой энергии по сравнению с традиционными CPU-based решениями. Кроме того, задержки при обмене данными сократились в 3.73 раза. Эти результаты свидетельствуют о высокой перспективности данного подхода для решения задач, требующих оптимизации энергоэффективности и минимизации задержек, особенно в контексте сложных вычислительных задач и систем реального времени.
Исследование демонстрирует, что эффективное решение сложных задач комбинаторной оптимизации, таких как задача Изинга, требует не только вычислительной мощности, но и грамотной архитектурной организации. Авторы предлагают гибридный подход, сочетающий аналоговые и цифровые вычисления на FPGA, что позволяет существенно снизить накладные расходы на коммуникацию и реализовать параллельную обработку данных. Как заметил Клод Шеннон: «Информация — это не количество, а выбор». В данном контексте, выбор оптимальной архитектуры и стратегии декомпозиции задачи является ключевым для извлечения максимальной информации из доступных ресурсов и достижения высокой производительности системы. Важно помнить, что любое упрощение имеет свою цену в будущем, и необходимо тщательно продумывать компромиссы между сложностью и эффективностью.
Что впереди?
Представленная работа, как и любое исследование, лишь временно замедляет неумолимый процесс старения проблем оптимизации. Разложение больших задач на части — это, по сути, разделение единого потока времени на более мелкие интервалы, что позволяет более эффективно использовать ресурсы. Однако, сама природа комбинаторных задач предполагает экспоненциальный рост сложности, и даже гибридные архитектуры, подобные описанной, лишь отодвигают момент, когда эта сложность станет непреодолимой. Логирование — это хроника жизни системы, а развертывание — лишь мгновение на оси времени.
Очевидным направлением для дальнейших исследований является расширение масштабируемости. Разработка более эффективных алгоритмов декомпозиции, способных справляться с задачами, превосходящими текущие возможности, представляется критически важной. Не менее интересным представляется исследование возможностей адаптивной архитектуры, способной динамически перестраиваться в зависимости от структуры решаемой задачи. В конце концов, любая система стремится к равновесию, и задача исследователя — лишь временно нарушить это равновесие, чтобы получить полезный результат.
Стоит также задуматься о границах применимости данного подхода. Не все задачи одинаково поддаются декомпозиции, и поиск задач, для которых предложенная архитектура действительно оптимальна, представляется важной задачей. И, конечно, необходимо помнить, что время — не метрика, а среда, в которой существуют системы, и рано или поздно любая архитектура устареет, уступив место новой.
Оригинал статьи: https://arxiv.org/pdf/2602.15985.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Роботы учатся действовать, наблюдая за миром
2026-02-19 10:51