Автор: Денис Аветисян
Исследователи предлагают метод стабилизации обучения с подкреплением для больших языковых моделей, основанный на ограничении изменений в глобальном распределении стратегий.
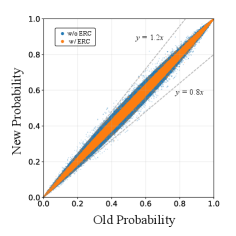
Предлагаемый метод, Entropy Ratio Clipping, позволяет повысить стабильность и эффективность обучения с подкреплением, ограничивая изменения энтропии стратегий.
Обучение с подкреплением для больших языковых моделей часто сталкивается с проблемой нестабильности, вызванной расхождением между текущей и предыдущей политиками. В работе «Entropy Ratio Clipping as a Soft Global Constraint for Stable Reinforcement Learning» предложен новый механизм — отсечение отношения энтропий (ERC), который обеспечивает более стабильное обучение за счет контроля глобального распределения политик. ERC, встраиваемый в алгоритмы DAPO и GPPO, позволяет смягчить влияние невыборки действий и компенсировать ограничения классического PPO-Clip. Сможет ли предложенный подход стать основой для создания более надежных и эффективных стратегий обучения с подкреплением для языковых моделей?
Неустойчивость Обучения с Подкреплением: Теория и Реальность
Обучение с подкреплением (RL) представляет собой перспективный подход к согласованию и улучшению больших языковых моделей, однако его применение сопряжено с существенными проблемами нестабильности. Несмотря на теоретический потенциал в оптимизации поведения сложных систем, практическая реализация RL часто сталкивается с трудностями, выражающимися в непредсказуемости и ухудшении производительности в процессе обучения. Эти проблемы препятствуют надежному внедрению RL в критически важные приложения, требующие стабильной и воспроизводимой работы, и стимулируют активные исследования в области методов стабилизации и повышения надежности алгоритмов обучения с подкреплением.
Обучение с подкреплением, несмотря на свой потенциал в совершенствовании больших языковых моделей, часто сталкивается с серьезными проблемами нестабильности. В частности, явления, известные как энтропийная нестабильность и нестабильность нормы градиента, способны существенно нарушить процесс обучения, приводя к непредсказуемым результатам и снижению производительности. Энтропийная нестабильность возникает из-за чрезмерного или недостаточного исследования пространства действий, в то время как нестабильность нормы градиента проявляется в резких колебаниях весов нейронной сети. Оба этих фактора могут привести к тому, что алгоритм обучения не сможет сойтись к оптимальному решению, и модель будет демонстрировать неустойчивое поведение, требуя дополнительных усилий по настройке и стабилизации процесса обучения. Проблема усугубляется тем, что эти явления часто возникают непредсказуемо и трудно поддаются диагностике, что требует разработки новых методов контроля и предотвращения.
Нестабильность обучения с подкреплением часто проявляется в виде отклонения от доверительной области, что существенно затрудняет процесс оптимизации. Вместо плавного и предсказуемого улучшения политики, обновления становятся хаотичными и непредсказуемыми, приводя к колебаниям и невозможности достижения стабильного решения. Это явление происходит из-за того, что алгоритм стремится к слишком большим изменениям в политике на каждом шаге, выходя за рамки безопасной области, где гарантируется улучшение. В результате, процесс обучения становится непредсказуемым и требует тщательной настройки гиперпараметров, чтобы предотвратить расхождение и обеспечить надежную сходимость к оптимальному решению. По сути, алгоритм теряет контроль над обновлениями политики, что делает его менее эффективным и затрудняет его применение к сложным задачам.
Ранние Подходы к Ограничению Обновлений: Шаг Назад
Ранние методы, такие как PPO-Clip, стремились уменьшить нестабильность обучения с подкреплением, ограничивая коэффициент важности (importance sampling ratio). Это достигалось путём обрезания (clipping) вероятностных отношений между новой и старой политиками. Ограничение коэффициента важности предотвращало слишком большие изменения в политике на каждом шаге, что могло привести к резким колебаниям и ухудшению производительности. Обрезание эффективно ограничивало влияние новых действий, основываясь на предположении, что чрезмерно отличающиеся действия, вероятно, менее надежны, и их вклад в обновление политики должен быть уменьшен. Таким образом, PPO-Clip пытался обеспечить более стабильный и контролируемый процесс обучения, избегая резких скачков в политике.
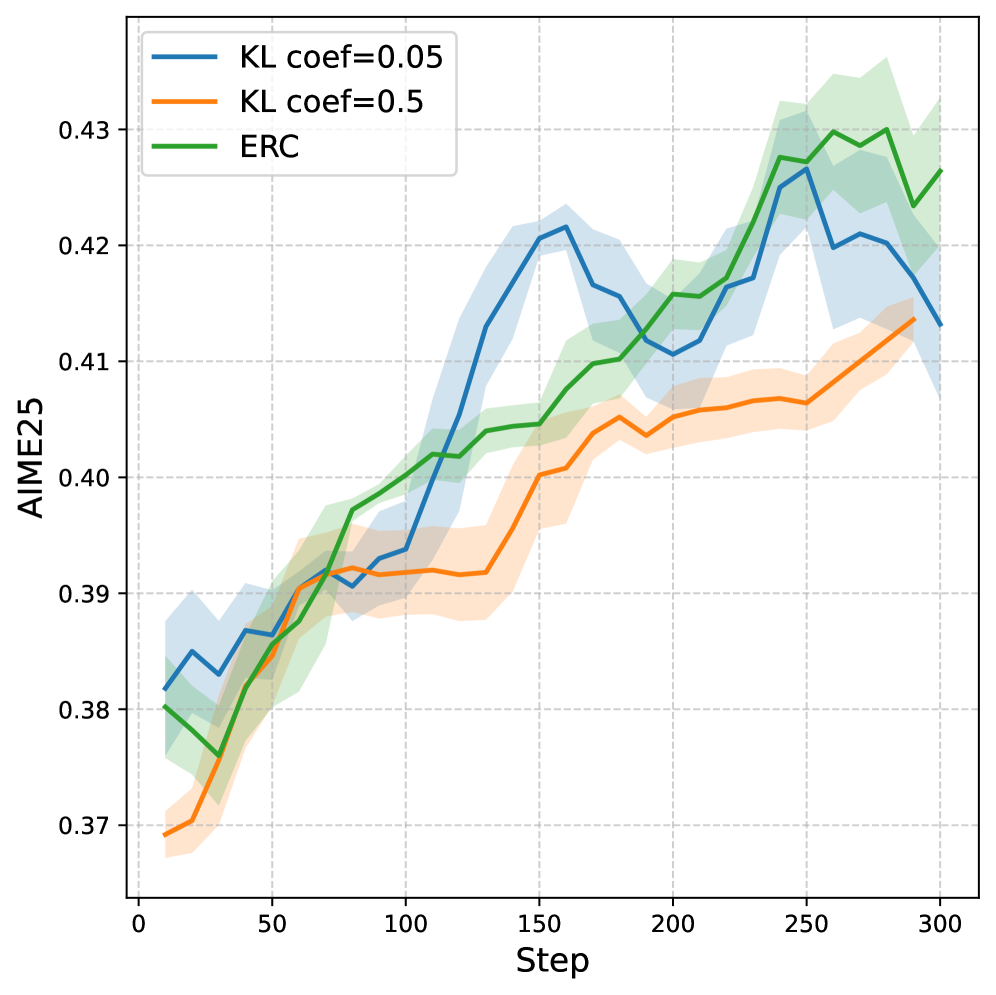
Метод PPO-Penalty использует расхождение Кульбака-Лейблера (KL-дивергенцию) для штрафования значительных отклонений между старой и новой политиками. Цель данного подхода — обеспечить более плавные переходы в процессе обучения с подкреплением. Штраф, основанный на $D_{KL}$(πθ||πθold), добавляется к функции потерь, ограничивая изменения политики и предотвращая резкие скачки в поведении агента. Величина штрафа регулируется коэффициентом, определяющим степень ограничения изменений, что позволяет контролировать баланс между улучшением политики и поддержанием стабильности обучения.
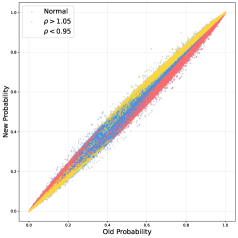
Несмотря на попытки ограничить изменения политики, ранние методы, такие как PPO-Clip и PPO-Penalty, часто демонстрируют ограниченную эффективность в сложных средах. Ограничение коэффициента важности в PPO-Clip составляет приблизительно 0.02%, что существенно снижает его способность предотвращать значительные отклонения от доверительной области. Это приводит к феномену Trust Region Deviation, когда политика может изменяться слишком резко, что негативно сказывается на стабильности обучения и сходимости. В отличие от этого, методы, использующие Entropy Ratio Clipping, показывают более высокую эффективность в ограничении отклонений и поддержании стабильности обучения, поскольку позволяют более гибко адаптировать изменения политики к сложности среды.
Отсечение Отношения Энтропии: Принцип Простоты и Эффективности
Ограничение отношения энтропии напрямую решает проблему нестабильности в обучении, обрезая градиенты при превышении заданного порогового значения изменением энтропии между старой и новой политиками. Данный механизм предотвращает неконтролируемое исследование пространства действий и поддерживает стабильную динамику обучения. При превышении порога, величина градиента уменьшается, что ограничивает масштаб изменений в политике и снижает вероятность отклонения от доверительной области. Эффективность метода заключается в адаптивном контроле величины обновления политики, основанном на изменении энтропии, что способствует более предсказуемому и устойчивому процессу обучения.
Механизм отсечения коэффициента энтропии предотвращает неконтролируемое исследование (runaway exploration) и поддерживает стабильную динамику обучения, смягчая отклонение в области доверия (Trust Region Deviation). Это достигается путем ограничения градиентов, когда изменение энтропии между старой и новой политиками превышает заданный порог, что позволяет избежать резких изменений в политике и поддерживает более предсказуемое поведение агента во время обучения. Стабильность, обеспечиваемая этим механизмом, особенно важна в задачах обучения с подкреплением, где чрезмерное исследование может привести к нестабильному обучению и снижению производительности.
В отличие от последовательного отсечения градиентов, отсечение отношения энтропии обеспечивает более принципиальный подход к управлению градиентами, что способствует улучшению сходимости и производительности. Предложенный метод отсечения отношения энтропии достигает приблизительного коэффициента отсечения в 20%, что позволяет эффективно ограничивать величину обновления политики и предотвращать нестабильность обучения. Данный коэффициент отсечения позволяет сохранять информативность градиента, избегая чрезмерного подавления полезных сигналов, в то время как последовательное отсечение может привести к потере важной информации, содержащейся в последовательности.
Усовершенствованные Алгоритмы и Перспективы Развития: Куда Ведет Стабильность?
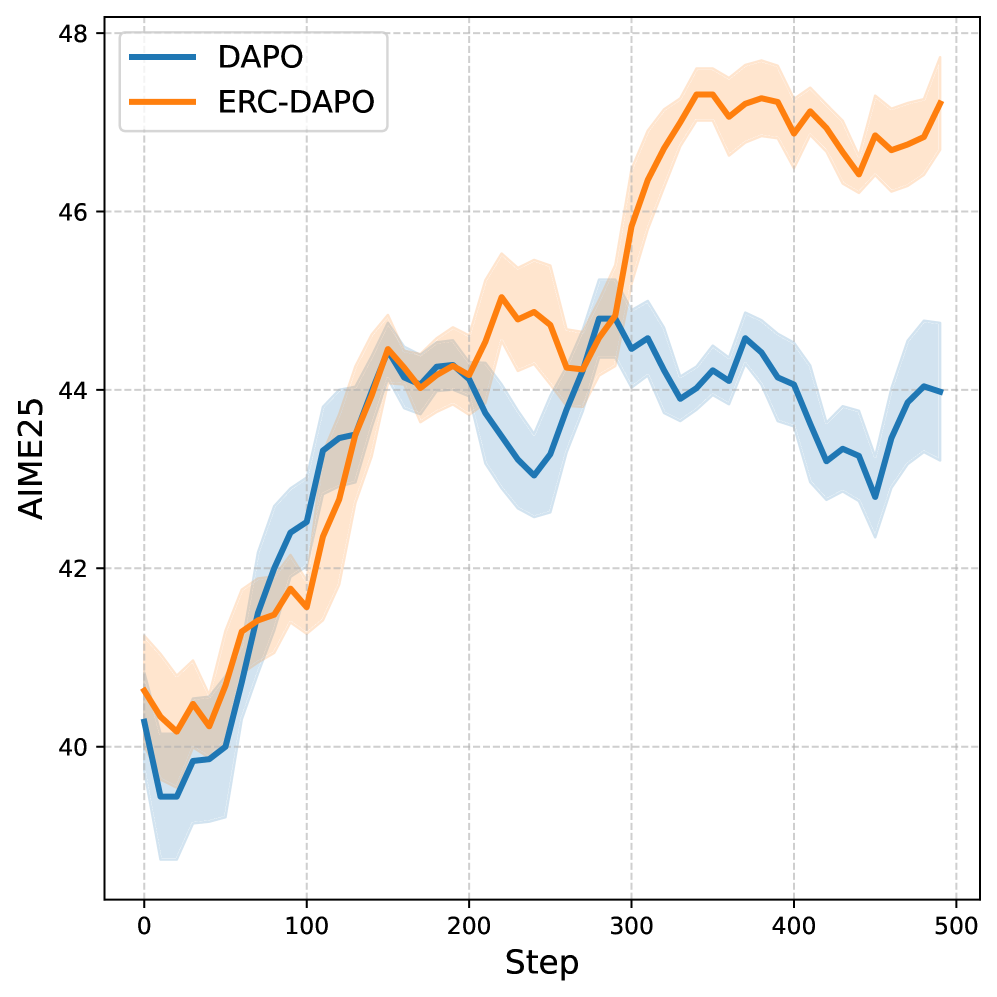
Алгоритмы, такие как DAPO и GPPO, представляют собой усовершенствование метода отсечения отношения энтропии, предлагая асимметричные границы отсечения и динамическую фильтрацию выборок для повышения стабильности обучения с подкреплением. В отличие от традиционных подходов, которые применяют фиксированные границы, DAPO и GPPO адаптируют эти границы в процессе обучения, что позволяет более эффективно исследовать пространство действий и избегать застревания в локальных оптимумах. Динамическая фильтрация выборок позволяет алгоритмам концентрироваться на наиболее информативных данных, отбрасывая те, которые вносят незначительный вклад в процесс обучения или могут привести к нестабильности. Такой подход позволяет существенно улучшить производительность в сложных средах, где традиционные алгоритмы испытывают трудности с конвергенцией и стабильностью.
Исследования показали значительные улучшения в производительности алгоритмов обучения с подкреплением в сложных средах, благодаря применению регуляризации на основе энтропии. Методы, такие как DAPO и GPPO, демонстрируют стабильное повышение эффективности на стандартных бенчмарках AIME24 и AIME25, причем положительный эффект наблюдается при использовании моделей различных масштабов. Данные результаты подтверждают, что контроль энтропии позволяет алгоритмам более эффективно исследовать пространство состояний и находить оптимальные стратегии, даже в условиях высокой сложности и неопределенности окружающей среды. Наблюдаемое улучшение производительности свидетельствует о перспективности использования энтропийной регуляризации как ключевого компонента в разработке более надежных и эффективных алгоритмов обучения с подкреплением.
Перспективные исследования в области обучения с подкреплением направлены на адаптацию алгоритмов, таких как DAPO и GPPO, для сценариев обучения вне политики (off-policy). Особое внимание уделяется использованию важностной выборки ($Importance\ Sampling$) с повышенной стабильностью. Это позволит применять накопленный опыт из прошлых взаимодействий с окружающей средой, значительно повышая эффективность обучения, особенно в сложных и ресурсоемких задачах. Разработка методов, гарантирующих стабильность важностной выборки при использовании этих алгоритмов, является ключевой задачей, поскольку нестабильность может привести к искажению оценки ценности и ухудшению производительности. Ожидается, что такие усовершенствования позволят значительно расширить область применения алгоритмов, основанных на энтропийной регуляризации, и добиться лучших результатов в различных задачах обучения с подкреплением.
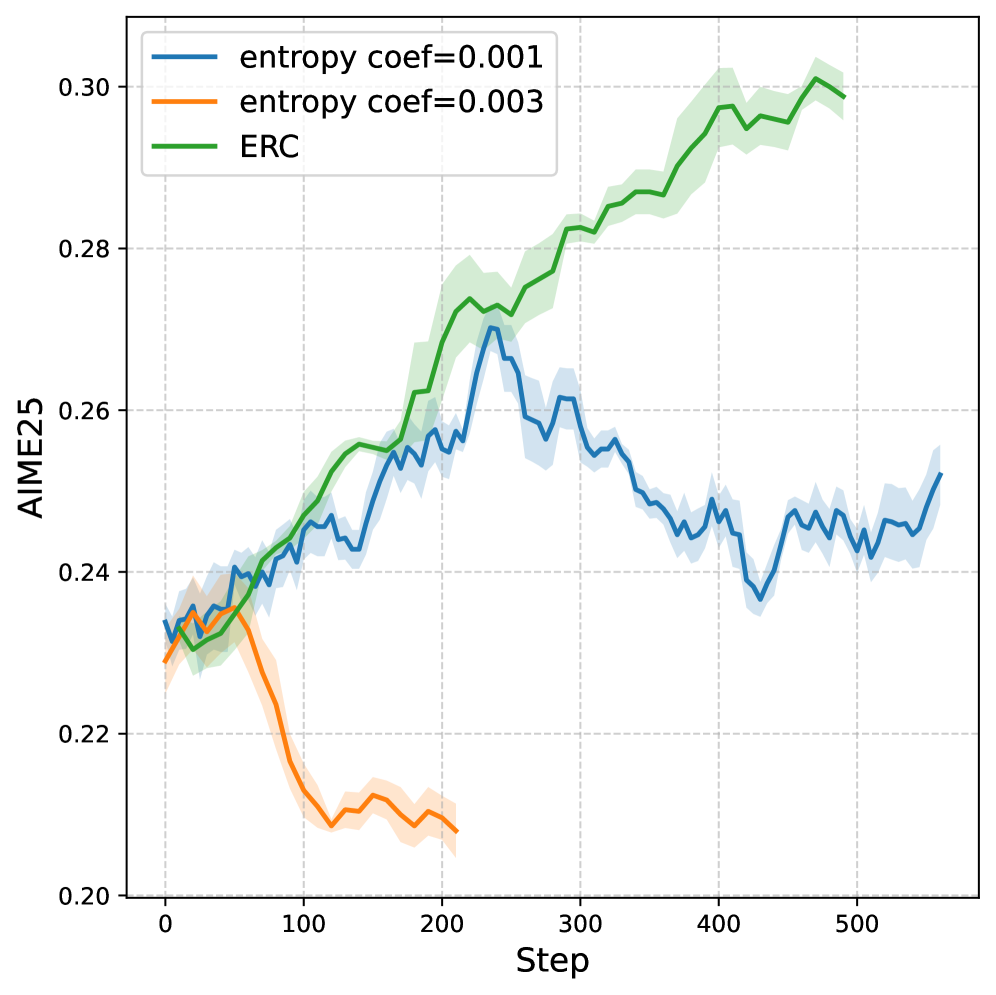
Работа демонстрирует, что даже самые изящные алгоритмы, такие как оптимизация политики с доверительной областью, не застрахованы от проблем, возникающих при сдвиге распределений. Авторы предлагают метод Entropy Ratio Clipping (ERC), который, по сути, является очередным способом обуздать неуправляемый рост энтропии, неизбежно возникающий в процессе обучения больших языковых моделей. Впрочем, не стоит обольщаться — это лишь временная мера, как и все прочие. Как однажды заметил Винтон Серф: «Мы полагаем, что можем создать что-то новое, но обычно мы просто переизобретаем старое». ERC — это ещё один костыль, который позволяет отсрочить неминуемый технический долг, но не отменить его.
Что дальше?
Предложенный метод обрезки отношения энтропии, безусловно, добавляет ещё один уровень сложности в и без того непростую задачу обучения с подкреплением для больших языковых моделей. Однако, как показывает практика, любое «улучшение» рано или поздно превращается в технический долг. Стабилизация обучения — это хорошо, но возникает вопрос о цене этой стабильности. Пока что неясно, насколько хорошо этот подход масштабируется на ещё более крупные модели и более сложные среды. Предположение о глобальном ограничении, основанное на изменении энтропии, выглядит элегантно, но в реальном мире продукшн всегда найдёт способ сломать даже самую красивую теорию.
Очевидным направлением для дальнейших исследований является изучение взаимодействия между обрезкой отношения энтропии и другими методами стабилизации, такими как trust region optimization. Важно понять, можно ли объединить эти подходы для достижения ещё большей устойчивости и производительности. Также, необходимо более тщательно исследовать влияние параметров обрезки на конечный результат. Если код выглядит идеально — значит, его ещё никто не деплоил, и, следовательно, реальные ограничения остаются за кадром.
В конечном итоге, задача обучения с подкреплением для языковых моделей остаётся открытой. Предложенный метод — это ещё один шаг в правильном направлении, но не стоит забывать, что революции редко происходят так, как мы их планируем. Скорее всего, следующая «революционная» технология окажется лишь ещё одним временным решением, которое потребует дальнейшей оптимизации и доработки.
Оригинал статьи: https://arxiv.org/pdf/2512.05591.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-08 13:40