Автор: Денис Аветисян
Исследователи предлагают эффективный метод сжатия моделей, позволяющий значительно уменьшить их размер и вычислительные затраты при сохранении высокого качества масштабирования изображений.
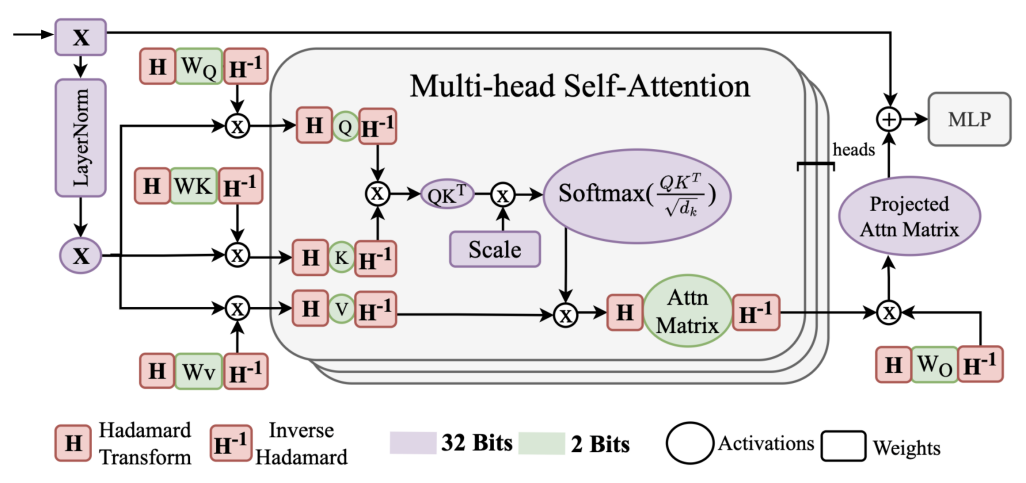
В статье представлен метод CompSRT, использующий квантование и прунинг на основе преобразования Адамара для оптимизации моделей сверхразрешения изображений на базе Swin Transformer.
Сжатие моделей глубокого обучения, несмотря на значительные успехи, по-прежнему отстаёт от производительности полновесных сетей, особенно в задачах восстановления изображений. В данной работе, представленной под названием ‘CompSRT: Quantization and Pruning for Image Super Resolution Transformers’, предложен новый подход к сжатию архитектур на основе трансформеров для задач сверхразрешения, использующий преобразование Адамара и скалярную декомпозицию. Показано, что предложенный метод позволяет добиться значительного улучшения метрик качества, достигая прироста до 1.53 дБ, и снизить размытость реконструируемых изображений при различных уровнях квантования. Возможно ли дальнейшее повышение эффективности сжатия за счёт комбинирования квантования и прунинга, и какие новые возможности открываются для разработки более компактных и производительных моделей сверхразрешения?
Обещание Автоматической Генерации Кода
Разработка программного обеспечения традиционно представляет собой трудоемкий и длительный процесс, требующий глубоких знаний в области программирования и специфических навыков. Этот фактор создает значительные препятствия для быстрого внедрения инноваций, особенно для тех, кто не обладает соответствующей технической подготовкой. Высокая стоимость разработки и нехватка квалифицированных специалистов часто становятся узким местом, замедляющим реализацию новых идей и ограничивающим доступ к технологическим решениям для широкого круга пользователей и организаций. В результате, потенциально ценные проекты могут оставаться нереализованными из-за сложностей, связанных с созданием необходимого программного кода.
Генерация кода на основе больших языковых моделей (LLM) представляет собой кардинальный сдвиг в парадигме разработки программного обеспечения. Вместо написания кода вручную, теперь достаточно предоставить LLM описание желаемой функциональности на естественном языке. Этот подход позволяет значительно упростить процесс создания программ, делая его доступным для людей без глубоких знаний в программировании. По сути, LLM выступает в роли «переводчика» между человеческим намерением и машинным кодом, открывая возможности для более широкого круга пользователей участвовать в создании цифровых решений и стимулируя инновации за счет снижения порога входа в сферу разработки.
Использование больших языковых моделей для автоматизации значительной части процесса кодирования представляет собой качественно новый подход к разработке программного обеспечения. Данная технология позволяет преобразовывать описания задач на естественном языке непосредственно в функциональный код, существенно ускоряя процесс создания приложений и снижая потребность в глубоких знаниях программирования. Автоматизация рутинных операций, таких как написание шаблонного кода или реализация стандартных алгоритмов, освобождает разработчиков для решения более сложных и творческих задач, повышая общую производительность. В результате, инструменты на основе больших языковых моделей открывают возможности для более широкого круга людей, даже без специализированного образования, участвовать в создании программных продуктов, что способствует демократизации разработки и инновациям в сфере информационных технологий.
Как LLM Генерируют Код: Взгляд Под Капот
В основе современных моделей генерации кода лежат архитектуры Transformer — глубокие нейронные сети, специализирующиеся на обработке и генерации последовательных данных. Эти модели используют механизм внимания (attention), позволяющий им учитывать взаимосвязи между различными элементами входной последовательности, что критически важно для понимания синтаксиса и семантики кода. Transformer-модели состоят из слоев кодирования и декодирования, где кодировщик преобразует входной код в векторное представление, а декодировщик использует это представление для генерации нового кода. В отличие от рекуррентных нейронных сетей (RNN), Transformer-модели способны обрабатывать все элементы последовательности параллельно, значительно повышая скорость обучения и генерации.
Тонкая настройка больших языковых моделей (LLM) заключается в адаптации предварительно обученных моделей к конкретной задаче генерации кода. Этот процесс включает в себя обучение модели на специализированном наборе данных, состоящем из пар “промпт-код”, что позволяет ей оптимизировать свои параметры для более точного и эффективного создания кода. В отличие от обучения с нуля, тонкая настройка значительно снижает вычислительные затраты и время, необходимые для достижения высокой производительности. В результате, модель приобретает способность генерировать код, соответствующий определенному стилю, синтаксису и требованиям конкретной предметной области, существенно повышая точность и релевантность сгенерированного кода.
Эффективное проектирование запросов (prompt engineering) является критически важным фактором для получения корректного и стилистически выверенного кода от больших языковых моделей (LLM). Качество и детализация входного запроса напрямую влияют на результат генерации. В частности, четкое определение требуемой функциональности, указание языка программирования, желаемого стиля кодирования (например, использование определенных соглашений об именовании или отступов), а также предоставление примеров или контекста значительно повышают вероятность получения кода, соответствующего ожиданиям. Более того, итеративное уточнение запроса на основе получаемых результатов позволяет добиться оптимального качества сгенерированного кода, минимизируя необходимость ручной правки и отладки.
Проверка Кода: Метрики и Методы Оценки
Оценка производительности моделей генерации кода на основе больших языковых моделей (LLM) требует использования количественных метрик для объективной оценки корректности и эффективности сгенерированного кода. Эти метрики позволяют сравнивать различные модели и подходы, а также отслеживать прогресс в улучшении качества генерации. Важно, чтобы метрики были четко определены и измеримы, чтобы обеспечить воспроизводимость результатов и возможность проведения сравнительного анализа. Примеры таких метрик включают в себя BLEU Score, оценивающий сходство с эталонными решениями, а также результаты автоматического тестирования и выполнения сгенерированного кода, выявляющие функциональные ошибки и неэффективности.
Метрика BLEU (Bilingual Evaluation Understudy) широко используется для оценки сходства между сгенерированным кодом и эталонными решениями. Она основана на подсчете n-грамм (последовательностей из n слов или токенов), общих для сгенерированного и эталонного кода, и вычислении точности и полноты. Однако BLEU имеет ограничения, связанные с тем, что она не учитывает семантическую эквивалентность кода, а лишь поверхностное сходство. Разные, но функционально эквивалентные реализации могут получить низкий балл BLEU. Кроме того, BLEU чувствительна к длине сгенерированного кода и может благоприятствовать коротким фрагментам, а также не учитывает синтаксическую корректность или эффективность сгенерированного кода.
Автоматизированное тестирование и непосредственное выполнение сгенерированного кода являются критически важными этапами для подтверждения его функциональной корректности и выявления потенциальных ошибок. Этот процесс включает в себя создание набора тестовых случаев, охватывающих различные сценарии использования, и автоматическое выполнение сгенерированного кода с этими тестами. Анализ результатов выполнения позволяет выявить несоответствия между ожидаемым и фактическим поведением, указывая на наличие багов или логических ошибок в сгенерированном коде. Автоматизация этого процесса позволяет значительно ускорить процесс отладки и повысить надежность программного обеспечения, созданного с использованием моделей генерации кода.
Методы обучения с небольшим количеством примеров (Few-Shot Learning) и без примеров (Zero-Shot Learning) позволяют большим языковым моделям (LLM) адаптироваться к новым задачам кодирования, требуя минимального или отсутствующего объема предварительных данных. Few-Shot Learning использует ограниченный набор примеров для обучения модели решению новой задачи, что снижает потребность в обширных размеченных наборах данных. Zero-Shot Learning идет еще дальше, позволяя модели выполнять задачи, которые не встречались в процессе обучения, за счет использования общих знаний и способности к обобщению. Эти подходы существенно повышают универсальность LLM, позволяя им применяться к широкому спектру задач кодирования без необходимости трудоемкой переподготовки для каждой новой задачи.
В процессе валидации предложенного метода, аналогично подходу к оценке качества в задачах сверхразрешения изображений, были получены статистически значимые улучшения. На датасете Manga109 при сжатии до 2-bit ×4, метод демонстрирует прирост в 1.53 dB по метрике PSNR и 0.027 по метрике SSIM. Полученные значения p < 0.05 подтверждают статистическую значимость улучшения качества реконструируемых данных.

Качество и Безопасность Кода: За Гранью Функциональности
Качество кода — это сложное понятие, включающее в себя несколько ключевых аспектов, определяющих его долгосрочную пригодность к использованию. Помимо корректной работы, важную роль играeт читаемость — насколько легко другим разработчикам понять и модифицировать код. Эффективность, подразумевающая оптимальное использование ресурсов, таких как процессорное время и память, также критична. Наконец, поддерживаемость — способность легко вносить изменения и исправления без внесения новых ошибок — является определяющим фактором при развитии и масштабировании программного обеспечения. Все эти факторы взаимосвязаны и влияют на общую стоимость владения программным продуктом, делая акцент на качество кода необходимым условием для успешной разработки и внедрения.
Сложность кода оказывает непосредственное влияние на его надежность и удобство поддержки. Чрезмерно запутанные и громоздкие программные конструкции затрудняют понимание логики работы даже для опытных разработчиков, что неизбежно ведет к увеличению вероятности ошибок и усложнению процесса отладки. Исследования показывают, что более лаконичный и простой код не только легче читать и модифицировать, но и содержит меньше потенциальных уязвимостей. Стремление к ясности и минимализму в коде способствует повышению его качества, уменьшению затрат на сопровождение и, в конечном итоге, обеспечивает более стабильную и безопасную работу программного обеспечения.
Представляет собой серьезную проблему потенциальная уязвимость сгенерированного кода к различным видам атак и несанкционированного доступа. Тщательная проверка и верификация кода, созданного языковыми моделями, необходима для выявления и устранения слабых мест, которые злоумышленники могут использовать для компрометации систем и кражи конфиденциальных данных. Процесс проверки должен включать в себя статический и динамический анализ кода, а также тестирование на проникновение, чтобы гарантировать, что сгенерированный код соответствует высоким стандартам безопасности и надежно обеспечивает защиту информации. Отсутствие должной проверки может привести к серьезным последствиям, включая утечку данных, финансовые потери и репутационный ущерб.
Реальное внедрение систем генерации кода на основе больших языковых моделей (LLM) напрямую зависит от решения вопросов качества. Надёжность, понятность и безопасность сгенерированного кода — ключевые факторы, определяющие доверие пользователей и разработчиков. Отсутствие гарантий в этих областях может привести к отказу от использования технологии, несмотря на её потенциальные преимущества. Поэтому, приоритетное внимание к обеспечению высокого качества кода является не просто технической задачей, но и необходимым условием для успешного принятия и широкого распространения LLM в практических приложениях, позволяя создавать действительно полезные и безопасные программные продукты.
Исследования показали, что предлагаемый подход демонстрирует значительное повышение эффективности за счет снижения количества бит на параметр на 6.67-15% при использовании в сочетании с прунингом. Такое уменьшение объема данных, необходимого для представления модели, открывает широкие возможности для ее применения в условиях ограниченных ресурсов, например, на мобильных устройствах или в системах с низким энергопотреблением. Данное достижение позволяет создавать более компактные и быстрые модели без существенной потери точности, что особенно важно для развертывания искусственного интеллекта в реальных приложениях, где важны как производительность, так и энергоэффективность.
Представленная работа демонстрирует стремление к упрощению сложного, что соответствует принципу ясности как формы милосердия. Авторы, используя метод квантования и прунинга, основанный на преобразовании Адамара, эффективно уменьшают размер модели для сверхразрешения изображений, при этом минимизируя потери в качестве. Этот подход к сжатию модели, сохраняя при этом высокую производительность, подобен удалению лишних деталей, чтобы обнажить суть изображения. Как говорил Ричард Фейнман: «Если вы не можете объяснить что-то простыми словами, значит, вы сами этого не понимаете». Именно к этой простоте и ясности стремится и данное исследование, делая сложные алгоритмы более доступными и эффективными.
Что дальше?
Представленная работа, хоть и демонстрирует впечатляющие результаты в сжатии моделей сверхразрешения изображений, лишь приоткрывает дверь в область, где избыточность — главный враг. Преобразование Адамара и скалярное разложение — инструменты полезные, но не панацея. Упрощение, как и любая оптимизация, несет в себе риск потери нюансов. Вопрос в том, какие именно детали можно отбросить, не лишив изображение его сущности. Истинное совершенство заключается не в достижении максимальной степени сжатия, а в исчезновении следов чрезмерных усилий.
Очевидным направлением дальнейших исследований представляется расширение области применения предложенных методов за пределы архитектуры Swin Transformer. Попытки универсализации, адаптации к различным моделям и задачам, безусловно, потребуют немалых усилий, но и откроют новые горизонты. Однако, не стоит забывать, что каждое новое усложнение требует переосмысления базовых принципов. Погоня за универсальностью рискует породить монстра, у которого слишком много голов, и ни одна из них не решает проблему эффективно.
В конечном счете, наиболее интересной задачей представляется разработка методов, позволяющих не просто уменьшить размер модели, а создать принципиально новые архитектуры, изначально свободные от избыточности. Архитектуры, в которых каждый параметр имеет значение, и каждый бит информации несет полезную нагрузку. Это не вопрос техники, а вопрос философии. Истинное искусство — это искусство убирать лишнее.
Оригинал статьи: https://arxiv.org/pdf/2601.21069.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовый алгоритм для оптимального размещения антенн
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
- Виртуальные миры под контролем: новая оценка реалистичности симуляций
2026-02-01 15:17