Автор: Денис Аветисян
Новое исследование показывает, что алгоритмы машинного обучения при классификации узлов часто полагаются на легко обнаруживаемые геометрические признаки, а не на фундаментальные топологические свойства.
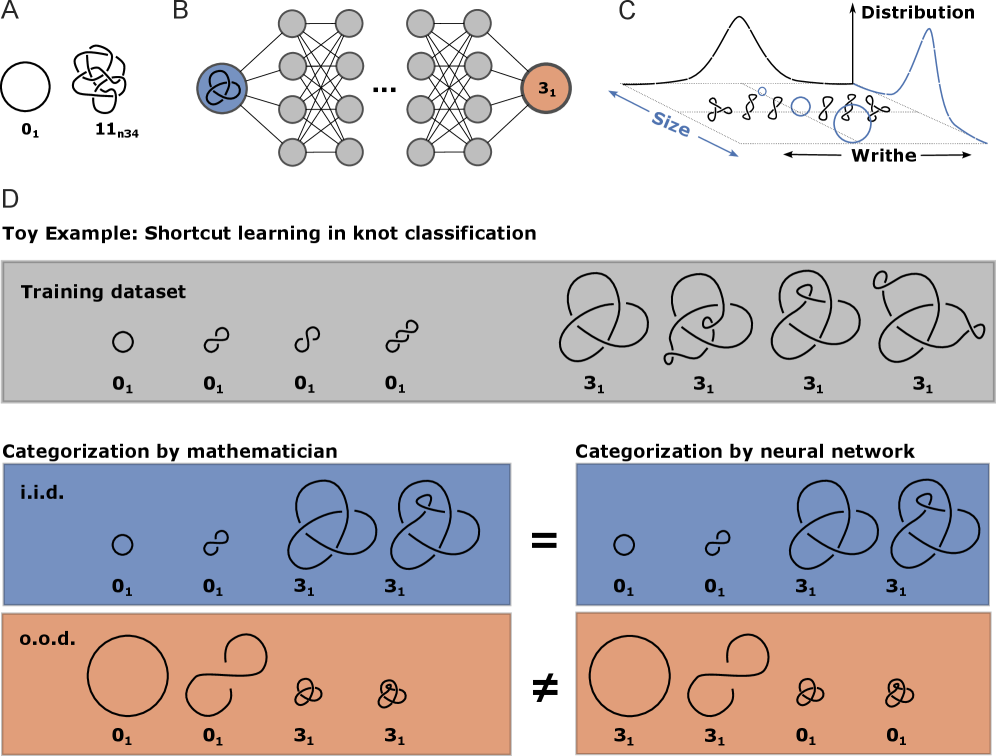
Работа посвящена анализу стратегий обучения моделей, классифицирующих геометрические узлы, и выявлению их зависимости от упрощенных, а не топологических, признаков.
Классификация топологии узлов представляет собой сложную задачу с приложениями в различных областях, от физики полимеров до молекулярной биологии. В работе ‘Shortcut learning in geometric knot classification’ исследуется возможность применения машинного обучения для решения этой задачи, однако показано, что модели часто полагаются на легко обнаруживаемые геометрические особенности, а не на истинные топологические инварианты. Авторы выявили, что обучение происходит на основе «быстрых решений», игнорирующих фундаментальные свойства узлов, и предлагают публичный набор данных и код для генерации узлов, лишенных этих ложных признаков. Сможем ли мы создать алгоритмы, способные к действительному распознаванию топологии узлов, опираясь на более надежные и корректные данные?
Узел проблем: Пределы полиномиальных инвариантов
Теория узлов, математическая дисциплина, изучающая свойства узлов, использует инварианты — характеристики, не меняющиеся при деформациях — для их различения. Однако, существующие полиномиальные инварианты, такие как полиномы Джонса и HOMFLY-PT, оказываются недостаточными для классификации все более сложных узлов. Эти инструменты, несмотря на свою эффективность в ряде случаев, не способны однозначно определить эквивалентность некоторых узлов, оставляя открытым вопрос об их топологической идентичности. Иными словами, два узла могут иметь одинаковые значения этих полиномов, но при этом быть топологически различными, что создает значительные трудности в исследовании и понимании структуры узлов.
По мере усложнения узлов, традиционные методы их различения, основанные на полиномиальных инвариантах, оказываются недостаточными. Существующие инструменты, такие как полиномы Джонса и HOMFLY-PT, не способны адекватно описывать топологические различия между всё более сложными конфигурациями, что серьёзно затрудняет прогресс в понимании топологии узлов. Эта неспособность эффективно классифицировать сложные узлы приводит к замедлению исследований в различных областях, включая ДНК-топологию, физику полимеров и квантовую теорию поля, где узлы выступают в качестве модельных систем для изучения сложных взаимодействий и структур. Поиск более мощных и надёжных методов различения узлов является ключевой задачей современной топологии, требующей разработки принципиально новых подходов к описанию и анализу узловой сложности.
Основная сложность в теории узлов заключается в том, чтобы адекватно отразить геометрическую сложность узлов, сохраняя при этом возможность их эффективной обработки. Существующие методы, основанные на полиномиальных инвариантах, оказываются недостаточными для различения всё более сложных узлов, поскольку не способны полностью уловить их запутанность и форму. Попытки создать более совершенные инварианты сталкиваются с необходимостью найти баланс между точностью описания геометрических характеристик узла и вычислительной сложностью, чтобы анализ оставался практичным и позволял проводить исследования в области топологии. Разработка инструментов, способных одновременно улавливать тонкости геометрии узла и обеспечивать эффективные вычисления, остается ключевой задачей, определяющей дальнейший прогресс в понимании математических узлов.
GEOKNOT: Укрощение геометрии узлов
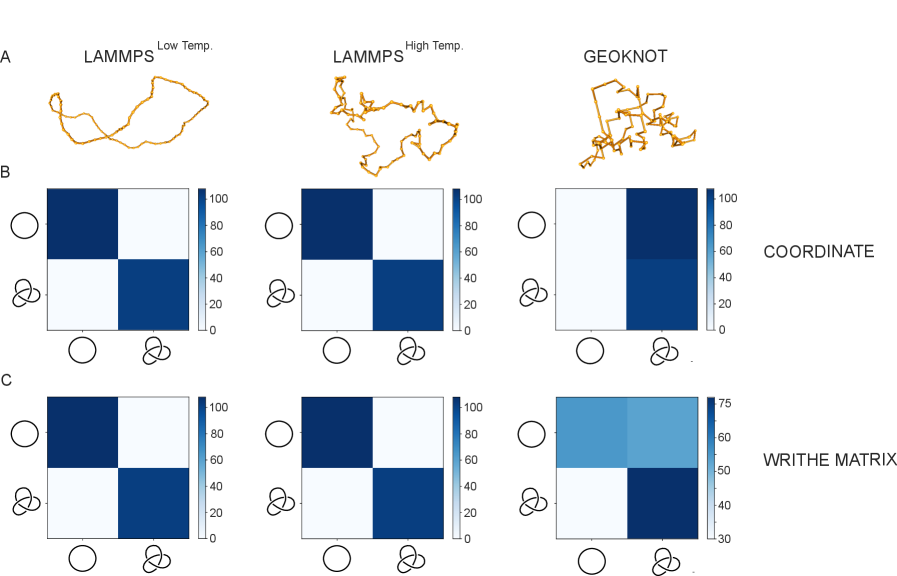
Алгоритм GEOKNOT представляет собой новый подход к генерации вложений узлов, позволяющий контролировать их геометрические свойства. В отличие от традиционных методов, основанных на случайной генерации или упрощенных моделях, GEOKNOT обеспечивает возможность систематического создания узлов с заданными параметрами, такими как кривизна и переплетение. Это достигается за счет использования алгоритмов оптимизации, направленных на минимизацию целевой функции, определяющей желаемые геометрические характеристики вложения. Возможность контролировать геометрию позволяет исследовать более широкий спектр конфигураций узлов, что важно для анализа их сложности и выявления закономерностей в структуре узлов.
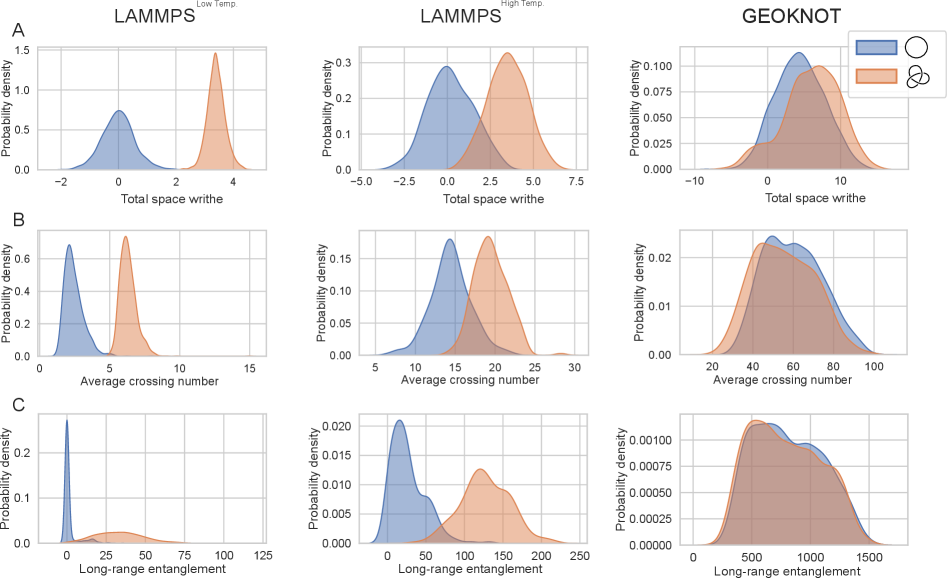
Алгоритм GEOKNOT позволяет проводить более детальную характеристику сложности узлов за счет выборки вложений, основанных на метриках, таких как извитость (writhe), попарное расстояние между сегментами и дальнодействующие запутанности. Извитость, являясь мерой скручивания кривой, количественно определяет её сложность. Попарное расстояние между сегментами позволяет оценить компактность и переплетение узла. Дальнодействующие запутанности, измеряемые как корреляции между удаленными участками кривой, отражают глобальные структурные особенности узла. Комбинирование этих метрик обеспечивает многомерный анализ, превосходящий традиционные подходы, основанные на простых инвариантах узлов.
Алгоритм GEOKNOT предоставляет возможность систематической генерации узлов с заданными геометрическими характеристиками, что позволяет проводить целенаправленный анализ и сравнительный анализ различных конфигураций. Контролируемое создание узлов с определенными параметрами, такими как кривизна и взаимное расположение сегментов, обеспечивает возможность изучения влияния конкретных геометрических свойств на общую сложность узла. Это особенно важно для исследований в области топологии и физики узлов, где понимание взаимосвязи между геометрией и топологическими инвариантами является ключевой задачей. Систематическая генерация узлов позволяет избежать случайного выбора конфигураций и обеспечить статистически значимые результаты при проведении сравнительных анализов.
Молекулярная динамика и ложные пути обучения
Для генерации вложений узлов (knot embeddings) для платформы GEOKNOT используются симуляции молекулярной динамики. Этот подход позволяет эффективно исследовать пространство узлов, поскольку молекулярная динамика обеспечивает вычислительно эффективный метод создания разнообразных конфигураций узлов. В отличие от экспериментальных методов, требующих физического манипулирования узлами, симуляции позволяют быстро генерировать большое количество данных, необходимых для обучения моделей машинного обучения, и контролировать параметры симуляции для получения требуемых характеристик узлов. Полученные вложения представляют собой многомерные векторы, отражающие топологические свойства узлов, и используются для классификации и анализа узлов в GEOKNOT.
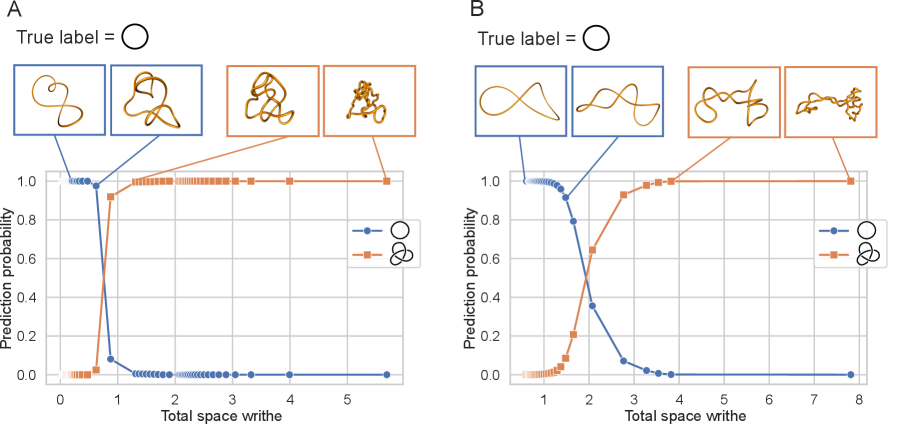
Машинное обучение, используемое для анализа данных, полученных в ходе молекулярно-динамических симуляций, подвержено феномену “shortcut learning”. Это означает, что модели могут выявлять и использовать ложные корреляции в данных, не отражающие истинные топологические свойства узлов. Вместо обучения распознаванию фундаментальных характеристик зацепленности, алгоритмы могут фокусироваться на артефактах, возникающих в процессе симуляции или представления данных, что приводит к высокой точности на тренировочном наборе, но к снижению обобщающей способности при работе с независимыми данными или реальными узлами.
Модели машинного обучения, обученные на данных, полученных с помощью молекулярной динамики, демонстрируют высокую точность классификации — более 99% — на исходном наборе данных. Однако, при тестировании на независимом наборе данных GEOKNOT, точность классификации снижается до менее 100%, что указывает на ограниченную способность к обобщению. Данный факт подчеркивает необходимость тщательной валидации моделей и использования надежных, разнообразных данных для обучения, чтобы избежать переобучения и обеспечить корректную работу в реальных условиях.
Топологические ограничения и надежная классификация
Теорема Фари-Милнора устанавливает глубокую связь между общей кривизной узла и его возможностью быть развязанным, что накладывает фундаментальное ограничение на способы его вложения в трехмерное пространство. Согласно этой теореме, для любого узла, общая кривизна его проекции на плоскость является необходимым условием для его тривиальности — то есть, для возможности непрерывной деформации в незавязанную окружность. Это означает, что любая попытка представить узел в виде проекции с нулевой общей кривизной обречена на неудачу, поскольку это противоречит фундаментальным свойствам узла. Таким образом, данная теорема не просто математическое утверждение, но и мощный инструмент для анализа и классификации узлов, позволяющий выявлять нетривиальные характеристики их топологической структуры и ограничивающий пространство возможных конфигураций.
Интеграция принципов топологических ограничений, в частности теоремы Фари-Милнора, непосредственно в процесс моделирования и обучения алгоритмов машинного обучения позволяет значительно повысить надежность и точность классификации узлов. Вместо того, чтобы полагаться исключительно на визуальные признаки, полученные из данных молекулярной динамики, модели получают возможность учитывать фундаментальные свойства узлов, связанные с их геометрией и невозможностью непрерывной деформации. Такой подход не только улучшает способность моделей обобщать знания на новые, ранее не встречавшиеся узлы, но и делает их менее восприимчивыми к шумам и артефактам в данных, что критически важно для практического применения в различных областях, включая биологию и физику полимеров. Учитывая, что стандартные методы машинного обучения могут находить «быстрые решения», основанные на поверхностных признаках, интеграция топологических принципов заставляет модели учиться истинным инвариантам узлов, обеспечивая более глубокое и устойчивое понимание их структуры.
Исследования показали, что модели, использующие подход на основе матрицы завитости, достигают высокой точности аппроксимации инвариантов Васильева — около 98.3%. Это свидетельствует о способности алгоритмов к обучению истинным топологическим инвариантам, в отличие от моделей, полагающихся на упрощенные стратегии обучения, или так называемые «ярлыки». Показатель Shortcut Learning Index (τ), равный приблизительно 1 для моделей, обученных исключительно на данных молекулярной динамики, подтверждает, что такие модели склонны к использованию поверхностных признаков вместо глубокого понимания топологических свойств узлов. Таким образом, использование матрицы завитости открывает перспективный путь к созданию более надежных и точных систем классификации узлов, способных преодолеть ограничения, присущие традиционным методам машинного обучения.
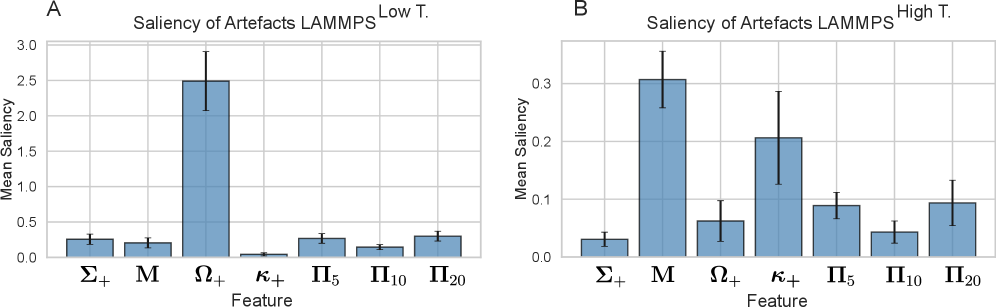
Исследование демонстрирует закономерность, знакомую любому, кто долго занимается разработкой: модель, казавшаяся прорывом в классификации узлов, на деле опирается на легко обнаруживаемые геометрические признаки, а не на истинные топологические инварианты. Это напоминает бесконечный поиск «серебряной пули», когда элегантная теория неизбежно сталкивается с суровой реальностью данных. Как метко заметил Винтон Серф: «Любая технология, которая достаточно долго используется, станет частью инфраструктуры, и в конечном итоге превратится в долг». И действительно, кажущаяся бесконечной масштабируемость классификаторов узлов оказывается иллюзией, если не обеспечить достаточное разнообразие и надежность обучающей выборки. Если тесты проходят, это, как правило, лишь подтверждает, что данные были недостаточно тщательно продуманы.
Куда же дальше?
Статья демонстрирует закономерность, знакомую любому, кто долго возится с автоматизированными системами: модель учится обходить препятствия, а не преодолевать их. Вместо того чтобы оперировать истинными топологическими инвариантами, алгоритм находит «короткие пути» — легко детектируемые геометрические признаки. Багтрекер, по сути, фиксирует эти самые «короткие пути», которые система приняла за решение. Проблема не в мощности модели, а в данных — они недостаточно репрезентативны, чтобы заставить алгоритм понять суть, а не запомнить симптомы.
Следующим шагом видится создание датасетов, намеренно лишенных этих «коротких путей». Это потребует не просто увеличения объема, а принципиально нового подхода к генерации данных, возможно, с использованием Монте-Карло симуляций, которые не фокусируются на визуально очевидных особенностях. Однако, даже идеально сгенерированные данные не гарантируют успех. В конечном счете, мы не деплоим — мы отпускаем алгоритмы в дикую природу продакшена, где они неизбежно столкнутся с тем, чего не было в учебных данных.
Вместо того, чтобы гнаться за очередными «революционными» архитектурами, стоит задуматься о более глубоком понимании того, что вообще означает «топологическая инвариантность» для машины. Вполне вероятно, что в конечном итоге потребуется гибридный подход, объединяющий мощь машинного обучения с проверенными временем математическими инструментами. Иначе, нас ждет лишь культ DevOops, где каждая новая версия исправляет баги предыдущей, порождая бесконечный цикл.
Оригинал статьи: https://arxiv.org/pdf/2602.17350.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
2026-02-21 14:54