Автор: Денис Аветисян
Новое исследование демонстрирует, как ускорить алгоритмы имитации отжига, используя вероятностные биты и графические процессоры, и как компенсировать влияние вариативности в современных микросхемах.
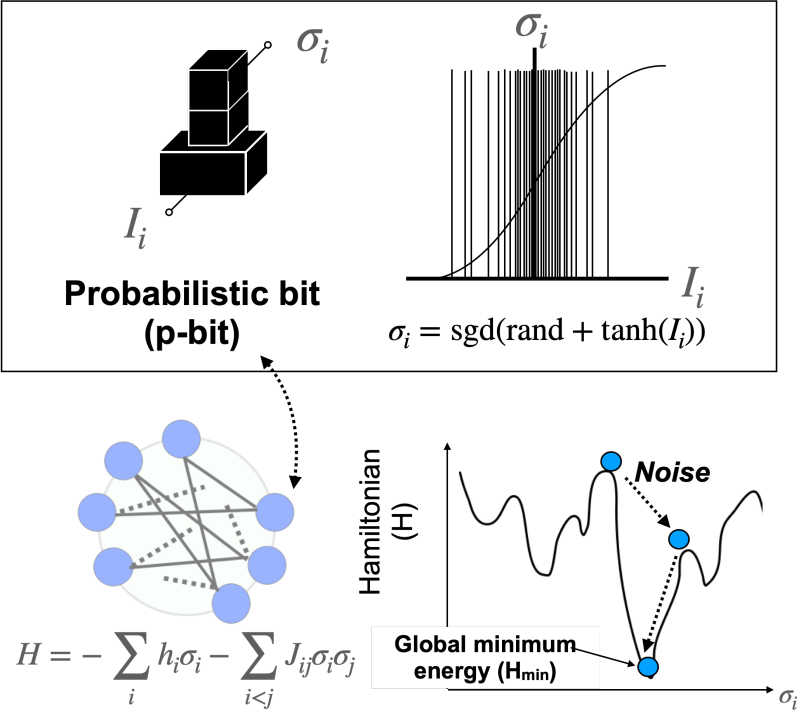
GPU-ускоренный симулятор отжига на основе p-битов показывает, что алгоритмы TApSA и SpSA устойчивее к вариативности чипов, а контролируемая нестабильность может улучшить производительность.
Несмотря на перспективность вероятностных вычислений, влияние вариативности устройств на их эффективность оставалось не до конца изученным. В данной работе, посвященной ‘GPU-accelerated simulated annealing based on p-bits with real-world device-variability modeling’, представлен GPU-ускоренный фреймворк для моделирования отжига на вероятностных битах (p-битах), демонстрирующий, что вариативность может не только ухудшать, но и улучшать производительность алгоритма за счет контроля временной изменчивости. Разработанная система, моделирующая ключевые факторы вариативности устройств, обеспечивает двухпорядковый прирост скорости по сравнению с CPU-реализациями на примере задачи MAX-CUT. Возможно ли дальнейшее повышение эффективности и расширение областей применения вероятностных вычислений за счет более глубокого понимания и управления вариативностью устройств?
За гранью бинарности: К проблеме неопределенности
Традиционные вычислительные системы основываются на битах, представляющих собой дискретные значения — 0 или 1. Такой подход, несмотря на свою эффективность в решении многих задач, имеет принципиальное ограничение в выражении неопределенности и вероятности. В реальном мире, напротив, большинство процессов характеризуются нечеткостью и вероятностным характером. Например, физические явления часто описываются статистическими распределениями, а биологические системы оперируют с вероятностными исходами. Ограничение классического бита лишь двумя состояниями не позволяет адекватно моделировать подобные явления, что создает трудности при решении сложных задач, требующих учета неопределенности и вероятностного характера данных. Данное ограничение затрудняет создание алгоритмов, способных эффективно справляться с неполной или зашумленной информацией, что актуально для таких областей, как машинное обучение, искусственный интеллект и моделирование сложных систем.
В отличие от классических битов, однозначно представляющих либо 0, либо 1, вероятностные биты предлагают более тонкий подход к кодированию информации. Вместо жесткого выбора, состояние вероятностного бита описывается распределением вероятностей, отражающим степень уверенности в том или ином значении. Этот принцип находит отражение в биологических системах, где процессы редко бывают абсолютно детерминированными, а скорее характеризуются вероятностными оценками и адаптацией. Например, активность нейрона не является просто «включенным» или «выключенным» состоянием, а скорее вероятностью передачи сигнала, зависящей от множества факторов. Такое вероятностное представление позволяет более эффективно моделировать сложные системы и решать задачи оптимизации, где традиционные алгоритмы сталкиваются с ограничениями, имитируя гибкость и адаптивность живых организмов.
Переход к вероятностным битам открывает новые возможности для разработки более эффективных алгоритмов, особенно при решении сложных задач оптимизации. Традиционные алгоритмы, основанные на классических битах, часто сталкиваются с ограничениями при работе с неопределенностью и необходимостью перебора множества вариантов. Вероятностные биты, напротив, позволяют алгоритмам оперировать с вероятностями различных состояний, что позволяет им более гибко адаптироваться к изменяющимся условиям и находить оптимальные решения, избегая жестких ограничений детерминированных подходов. Такой подход особенно перспективен в областях, где поиск оптимального решения требует учета множества факторов и вероятностных зависимостей, например, в машинном обучении, финансовом моделировании и логистике. Использование вероятностных битов позволяет создавать алгоритмы, которые способны не просто находить решение, но и оценивать степень его достоверности, что значительно повышает надежность и эффективность принимаемых решений.
Магнитные основы: Реализация вероятностных вычислений
Магнитные туннельные переходы (MTJ) представляют собой физическую основу для реализации вероятностных битов благодаря явлению туннельного магнитосопротивления (TMR). В MTJ два ферромагнитных слоя разделены тонким диэлектрическим барьером. Вероятность прохождения электронов через этот барьер, и, следовательно, сопротивление перехода, зависит от относительной магнитной ориентации слоев. Параллельное выравнивание намагниченностей приводит к низкому сопротивлению, а антипараллельное — к высокому. Изменяя вероятность переключения магнитной ориентации, можно добиться различных уровней сопротивления, которые непосредственно соответствуют вероятностным состояниям бита, обеспечивая физическую реализацию вероятностной логики и памяти.
Сопротивление магнитотуннельного перехода (МТП) напрямую связано с относительной ориентацией магнитных слоев, разделенных тонким непроводящим барьером. Параллельное выравнивание намагниченностей слоев приводит к низкому сопротивлению, а антипараллельное — к высокому. Вероятность нахождения МТП в одном из этих состояний определяется термодинамической стабильностью каждого состояния и может быть контролируема внешними факторами, такими как температура или приложенное магнитное поле. Таким образом, сопротивление МТП не является фиксированной величиной, а представляет собой вероятностное распределение, которое может быть интерпретировано как состояние вероятностного бита, где различные уровни сопротивления соответствуют различным вероятностям.
Использование магнитных туннельных переходов (MTJ) для реализации вероятностных битов позволяет создавать энергонезависимую вероятностную память и вычислительные системы. В отличие от традиционных систем, требующих постоянного энергопитания для сохранения данных, MTJ сохраняют состояние сопротивления, определяемое выравниванием магнитных слоев, даже при отключении питания. Это значительно снижает энергопотребление, особенно в приложениях, требующих частого сохранения и восстановления состояния, таких как системы машинного обучения и нейроморфные вычисления. Энергонезависимость, в сочетании с вероятностной природой вычислений, открывает возможности для разработки более эффективных и масштабируемых вычислительных архитектур, ориентированных на снижение энергозатрат.
Вероятностный отжиг: Мощный алгоритм для сложных задач
Имитация отжига (Simulated Annealing) является эффективным методом оптимизации, особенно полезным при решении задач, где традиционные алгоритмы терпят неудачу из-за сложной структуры пространства решений. Однако, производительность имитации отжига снижается при увеличении размерности задачи и сложности целевой функции. Это связано с тем, что алгоритм требует большого количества итераций для исследования всего пространства решений, особенно в случаях, когда оптимальная область ограничена и труднодоступна. В результате, время вычислений может значительно увеличиваться, делая метод непрактичным для задач, требующих оперативного решения, или задач с высокой вычислительной сложностью.
Вероятностный отжиг (pSA) улучшает стандартный алгоритм имитации отжига за счет использования вероятностных битов для представления и изменения состояний решения. Вместо детерминированного переключения битов, pSA использует вероятностные значения, определяющие вероятность изменения каждого бита. Это позволяет алгоритму исследовать пространство решений более эффективно, поскольку вероятность изменения каждого бита зависит от его вклада в целевую функцию, что обеспечивает более сбалансированное исследование и эксплуатацию, особенно в сложных задачах оптимизации. Использование вероятностных битов снижает вероятность застревания в локальных оптимумах и способствует более быстрому поиску глобального оптимума.
Варианты алгоритма Probabilistic Simulated Annealing (pSA), такие как Stalled и Time-Averaged pSA, оптимизируют процесс поиска решения за счет адаптации стратегии исследования пространства состояний. Stalled pSA приостанавливает поиск, когда улучшения становятся незначительными, и возобновляет его с измененными параметрами, избегая застревания в локальных оптимумах. Time-Averaged pSA усредняет результаты нескольких прогонов с различными случайными начальными точками, повышая стабильность и точность. Эти подходы демонстрируют улучшенную сходимость и более высокие результаты при решении задач, таких как Max-Cut и модели Изинга, по сравнению со стандартным Simulated Annealing.
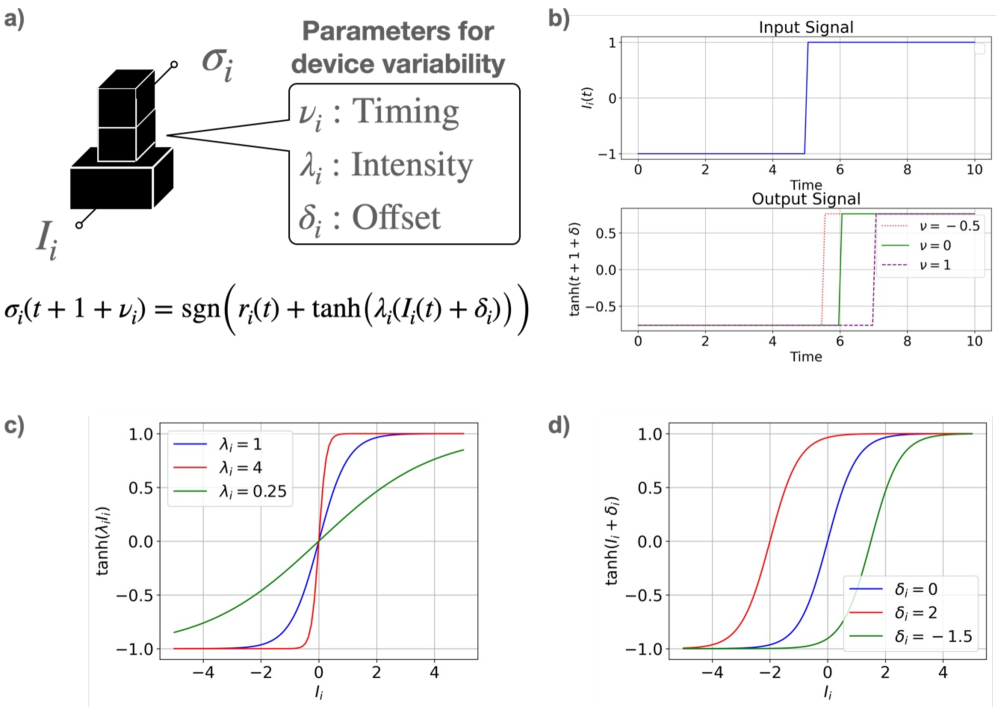
Учет вариативности устройств: Гарантия надежности и масштабируемости
Неоднородность аппаратного обеспечения, проявляющаяся в отклонениях по времени задержки, интенсивности сигнала и смещению, оказывает существенное влияние на точность вероятностных вычислений. Эти вариации, возникающие из-за технологических ограничений и случайных факторов при производстве электронных компонентов, приводят к погрешностям в результатах, особенно в сложных системах, где множество устройств работают параллельно. Игнорирование подобных отклонений может привести к снижению надежности и предсказуемости вычислений, что критично для приложений, требующих высокой точности и стабильности. Таким образом, учет и компенсация вариативности устройств является ключевой задачей при разработке надежных и масштабируемых вероятностных вычислительных систем.
Понимание и смягчение вариативности устройств имеет первостепенное значение для создания надежных и масштабируемых систем. Отклонения во времени, интенсивности и смещении параметров отдельных компонентов неизбежно возникают в реальных аппаратных реализациях, и игнорирование этих факторов может привести к существенным ошибкам в вероятностных вычислениях. Именно поэтому, при разработке сложных вычислительных архитектур, необходимо учитывать эти вариации и внедрять механизмы, компенсирующие их влияние. Такой подход позволяет гарантировать стабильную и предсказуемую работу системы, даже при наличии производственных отклонений или изменений условий эксплуатации, обеспечивая тем самым её надежность и масштабируемость.
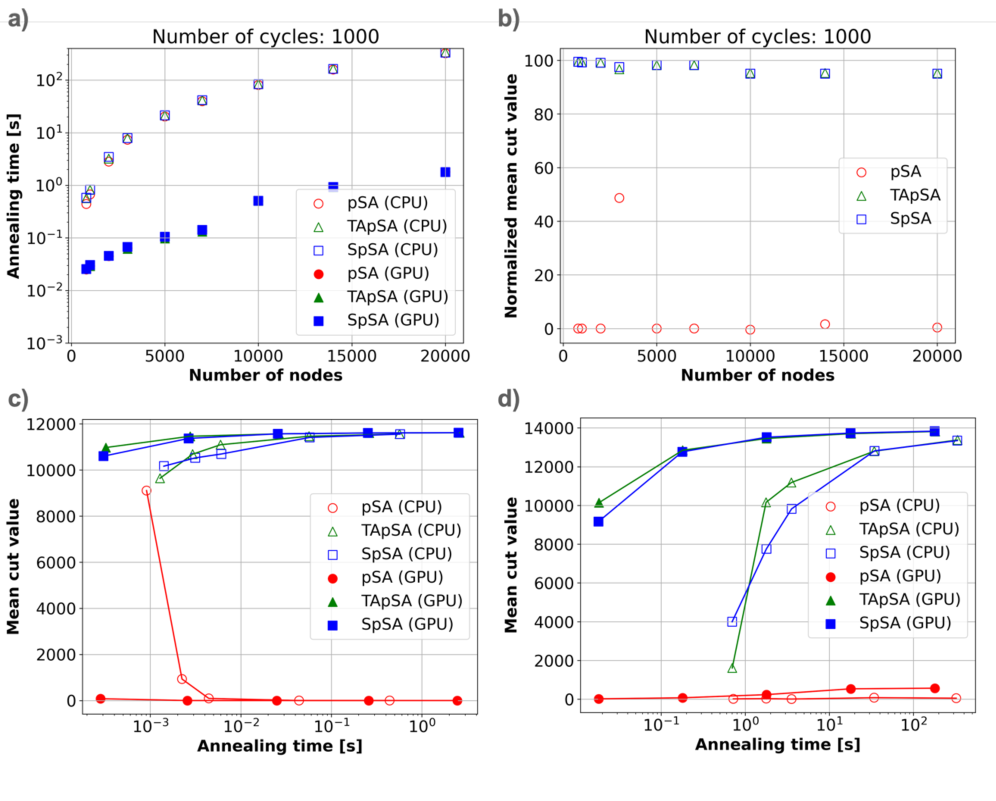
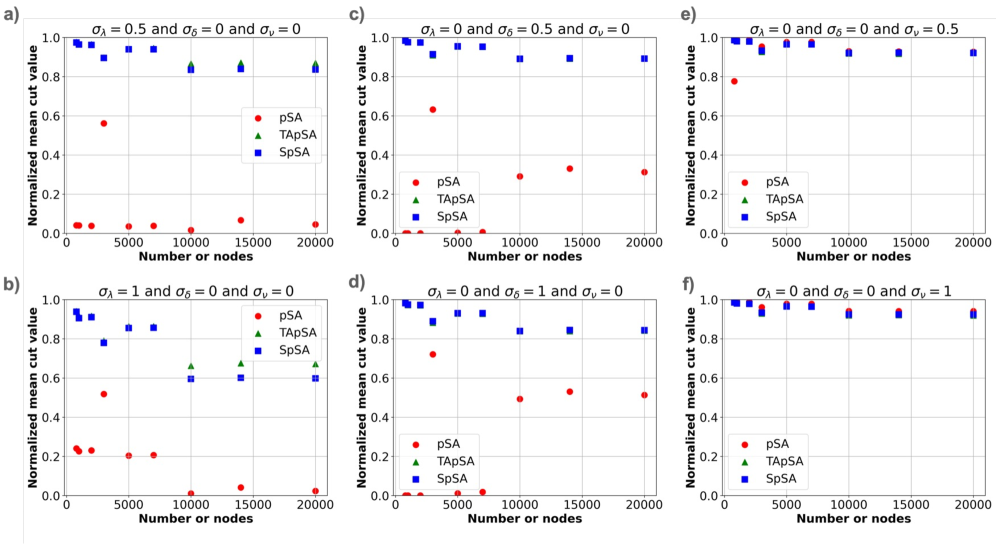
Исследования показали, что алгоритмы SpSA и TApSA демонстрируют устойчивость к вариативности устройств, сохраняя стабильно высокие значения нормализованного среднего среза, в то время как алгоритм pSA значительно страдает от подобных отклонений. Особого внимания заслуживает то, что при реализации SpSA и TApSA на графических процессорах (GPU) удалось добиться двукратного увеличения скорости работы по сравнению с традиционными CPU-симуляциями. Это существенное ускорение открывает новые возможности для масштабирования и применения вероятностных вычислений в системах, чувствительных к колебаниям характеристик аппаратного обеспечения.
Ускорение и перспективы: К новому поколению вычислений
Использование возможностей графических процессоров (GPU) посредством платформы CUDA позволяет значительно ускорить вычисления в алгоритмах pSA. Традиционно, сложные вероятностные вычисления требовали значительных временных затрат, однако, благодаря параллельной архитектуре GPU и оптимизированному коду CUDA, скорость обработки данных возрастает в разы. Это открывает новые перспективы для решения задач, ранее считавшихся невыполнимыми из-за вычислительных ограничений, особенно в таких областях, как машинное обучение, где требуется обработка огромных массивов данных, и материаловедение, где моделирование сложных процессов требует высокой точности и скорости вычислений. Такое ускорение не только сокращает время, необходимое для получения результатов, но и позволяет исследовать более сложные и реалистичные модели, что способствует научным открытиям и технологическим инновациям.
Использование ускорения на графических процессорах (GPU) открывает новые возможности для решения сложных задач оптимизации в различных областях науки и техники. В частности, это позволяет значительно продвинуться в машинном обучении, где поиск оптимальных параметров моделей требует огромных вычислительных ресурсов. Более того, в материаловедении, где необходимо моделировать поведение сложных материалов и предсказывать их свойства, ускорение вычислений становится критически важным для разработки новых, более эффективных материалов. Возможность обрабатывать значительно больший объем данных и проводить более сложные симуляции, благодаря GPU, позволяет ученым и инженерам решать задачи, которые ранее были недоступны из-за ограничений вычислительной мощности, тем самым ускоряя процесс инноваций и открывая путь к новым открытиям.
Исследования последовательно демонстрируют превосходство алгоритмов SpSA и TApSA над pSA, как по скорости вычислений, так и по устойчивости к изменениям в характеристиках устройств. Данное преимущество открывает возможности для решения более сложных оптимизационных задач в различных областях, включая машинное обучение и материаловедение. В настоящее время проводятся работы по разработке еще более надежных алгоритмов и специализированных аппаратных архитектур, направленные на создание нового поколения вероятностных вычислений, способных эффективно справляться с задачами, непосильными для традиционных систем. Ожидается, что дальнейшее развитие этих технологий позволит значительно расширить границы применимости вероятностных методов в самых разных областях науки и техники.
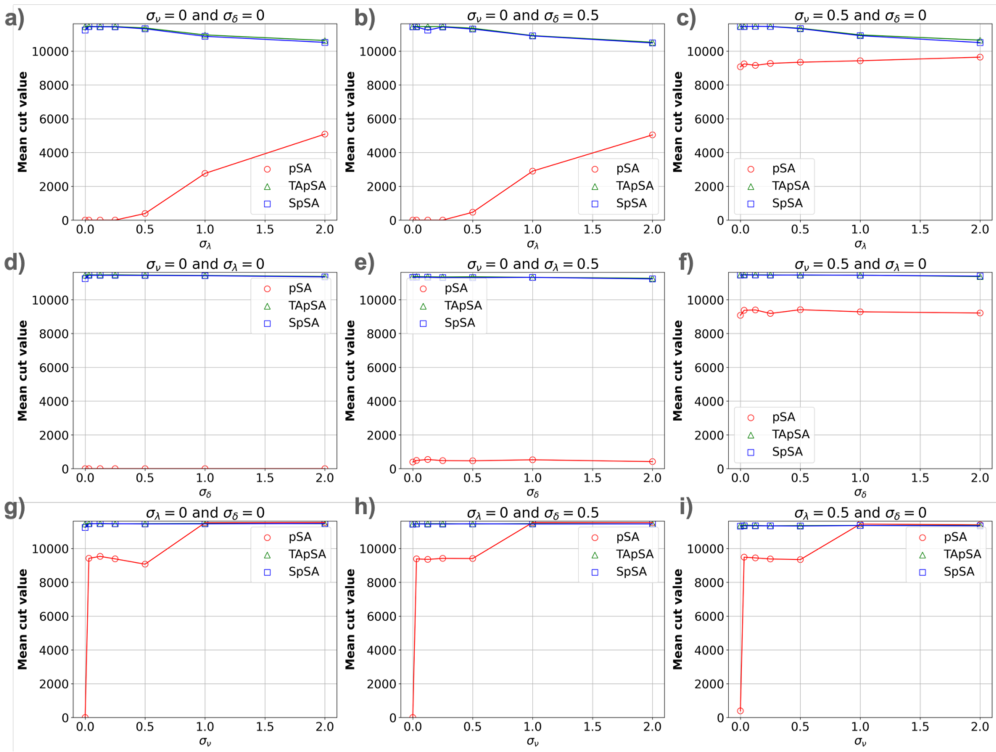
Исследование показывает, что даже самые изящные алгоритмы, вроде TApSA и SpSA, в конечном итоге сталкиваются с суровой реальностью вариативности устройств. Авторы демонстрируют, как контролируемая нестабильность может даже улучшить производительность, что вызывает тихую иронию. Вспомнится высказывание Блеза Паскаля: «Все великие дела требуют времени». Здесь же, кажется, требуется не только время, но и умение приручить хаос, ведь каждый «улучшенный» p-bit — это ещё один потенциальный источник ошибок, который продлевает страдания системы. Впрочем, что-то подсказывает, что это лишь ещё один релиз, где «всё было под контролем» — до первого сгоревшего кластера.
Что дальше?
Представленная работа демонстрирует, что ускорение симуляций отжига на GPU с использованием вероятностных битов (p-битов) — это не столько прорыв, сколько лишь очередной способ отложить неизбежное столкновение с физическими ограничениями. Алгоритмы TApSA и SpSA оказались более устойчивыми к вариативности устройств, что, впрочем, неудивительно — любое усложнение рано или поздно превращается в борьбу с собственными артефактами. Наблюдаемый эффект улучшения производительности за счёт контролируемой вариативности времени — любопытен, но прежде чем говорить о намеренном введении хаоса, стоит помнить: оптимизация — это всегда локальный максимум, а шум — лишь один из способов из него выбраться, пусть и не самый элегантный.
Не стоит забывать, что симуляции, какими бы быстрыми они ни были, остаются лишь приближением к реальности. Ключевым вопросом остаётся масштабируемость. Увеличение размера задачи неизбежно столкнётся с проблемами памяти и пропускной способности. Вероятно, будущие исследования будут направлены на разработку более эффективных алгоритмов представления данных и распределённых вычислений, чтобы обойти эти ограничения. И, конечно, стоит помнить, что «MVP — это просто способ сказать пользователю: подожди, мы потом исправим».
Если код выглядит идеально — значит, его никто не деплоил. Практическая реализация на реальном оборудении — это всегда компромисс между теорией и физическими ограничениями. В конечном итоге, ценность представленной работы заключается не в достигнутом ускорении, а в понимании того, что даже самые элегантные алгоритмы рано или поздно столкнутся с суровой реальностью «железа». И это, пожалуй, самое важное.
Оригинал статьи: https://arxiv.org/pdf/2601.14476.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
2026-01-22 23:00