Автор: Денис Аветисян
Исследователи представляют Youtu-VL, модель, которая демонстрирует впечатляющие результаты благодаря переходу от текстового до визуального контроля в процессе обучения.

Youtu-VL — это унифицированная архитектура для задач обработки изображений и текста, использующая визуальное восприятие как основную цель обучения.
Несмотря на значительный прогресс в области мультимодальных моделей «зрение-язык», существующие архитектуры часто демонстрируют ограниченную способность к сохранению детальной визуальной информации, что приводит к упрощенному пониманию контента. В данной работе, посвященной разработке ‘Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision’, предложена новая методика обучения, переходящая от доминирующей текстовой оптимизации к обучению с акцентом на визуальные сигналы как основную цель. Предложенный подход, основанный на унифицированном авторегрессионном обучении, позволяет модели эффективно обрабатывать как визуальные детали, так и лингвистический контент, открывая возможности для решения задач, ориентированных на анализ изображений. Способна ли такая унифицированная архитектура стать основой для создания действительно универсальных визуальных агентов, способных к комплексному пониманию мира?
За гранью текста: К единству зрения и языка
Традиционно, системы компьютерного зрения и обработки естественного языка развивались как отдельные дисциплины, оперируя с разными типами данных — изображениями и текстом, соответственно. Это разделение создает значительные трудности при попытке полноценного понимания сложных сцен. Вместо интегрального восприятия, системы, как правило, анализируют визуальную информацию и текстовые описания независимо друг от друга, что приводит к фрагментарному и неполному представлению о происходящем. Например, система может распознать объект на изображении, но не связать его с контекстом, описанным в текстовом запросе, или наоборот. Такое разрозненное восприятие препятствует созданию действительно «умных» систем, способных к глубокому и всестороннему анализу окружающей среды, подобно человеческому.
Для полноценного взаимодействия с окружающим миром необходима интегрированная система, способная одновременно обрабатывать как визуальную, так и текстовую информацию. Отдельные модели, работающие с изображениями и текстом по отдельности, не позволяют сформировать целостное представление о происходящем. Представьте себе робота, которому нужно описать сцену: для этого требуется не просто распознать объекты на изображении, но и связать их с соответствующими текстовыми описаниями, а также понимать контекст и взаимосвязи между ними. Разработка таких унифицированных моделей, объединяющих возможности компьютерного зрения и обработки естественного языка, открывает путь к созданию интеллектуальных систем, способных не только «видеть» и «читать», но и понимать, рассуждать и эффективно действовать в реальном мире. Такой подход позволяет преодолеть ограничения традиционных методов и добиться более высокого уровня автономности и адаптивности в различных приложениях, от робототехники и беспилотных транспортных средств до интеллектуальных помощников и систем анализа данных.
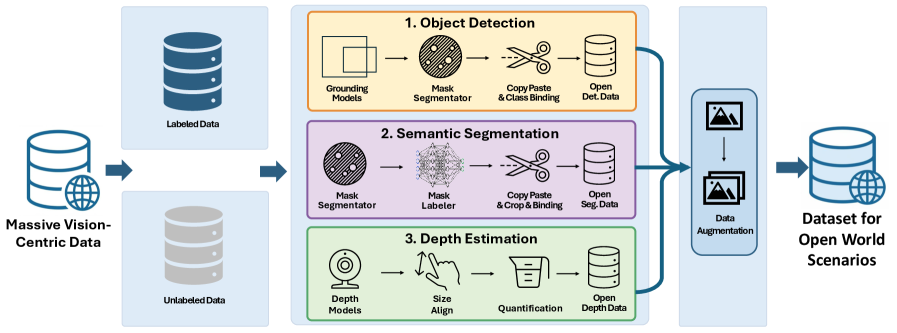
VLUAS: Новый взгляд на обучение моделей, объединяющих зрение и язык
В отличие от традиционных подходов к обучению моделей, ориентированных на доминирование текстовых данных, VLUAS (Vision-Language Unified Auto-regressive System) переходит к оптимизации непосредственно визуальных токенов. Это достигается посредством авторегрессионного надзора, при котором модель обучается предсказывать последовательность визуальных токенов, представляющих изображение. Вместо того, чтобы преобразовывать визуальную информацию в текст для оптимизации, VLUAS рассматривает визуальные токены как самостоятельные цели оптимизации, что позволяет более эффективно использовать визуальные данные и улучшить согласованность между визуальным и языковым представлениями.
В рамках VLUAS, визуальное восприятие рассматривается как задача предсказания токенов, что позволяет напрямую сопоставлять визуальные и языковые представления. Вместо традиционной оптимизации, ориентированной преимущественно на текстовые данные, VLUAS обучает модель предсказывать последовательность визуальных токенов, аналогично тому, как языковые модели предсказывают следующие слова в предложении. Этот подход устраняет необходимость в сложных механизмах перевода между визуальными признаками и текстовыми описаниями, обеспечивая более эффективное и естественное объединение визуальной и языковой информации. Такая формулировка позволяет модели усваивать взаимосвязи между визуальными элементами и их языковыми эквивалентами непосредственно из данных, повышая общую производительность и упрощая процесс обучения.

Youtu-VL: Архитектура и ключевые компоненты
Архитектура Youtu-VL построена на стандартных компонентах, что позволяет избежать жесткой привязки к конкретным задачам и повысить общую универсальность модели. В отличие от многих существующих систем, использующих специализированные модули для каждого типа запроса, Youtu-VL использует общую архитектуру, способную адаптироваться к различным типам входных данных и задачам без необходимости переобучения или модификации отдельных компонентов. Такой подход упрощает масштабирование и расширение функциональности модели, а также способствует более эффективному переносу знаний между различными задачами.
В основе Youtu-VL лежит интеграция трех ключевых компонентов: Vision Encoder, основанного на архитектуре SigLIP-2, который извлекает визуальные признаки из входных изображений. Далее, Vision Tokenizer преобразует эти визуальные признаки в дискретные индексы, представляющие собой последовательность токенов. Полученная последовательность токенов поступает на вход Large Language Model (Youtu-LLM), где происходит обработка и генерация ответа. Такая модульная структура позволяет эффективно комбинировать визуальную информацию с возможностями языковой модели.
Архитектура Youtu-VL включает в себя модуль Spatial Merge Projector, предназначенный для уменьшения длины последовательности входных данных перед передачей в большую языковую модель (LLM). Это достигается за счет агрегации и проекции пространственных признаков, что снижает вычислительную сложность обработки LLM. Для эффективной обработки последовательностей переменной длины используется техника FlashAttention, оптимизирующая процесс вычисления внимания и снижающая потребление памяти, особенно при работе с длинными входными последовательностями. FlashAttention использует переупорядочение вычислений и разделение операций для повышения скорости и эффективности.
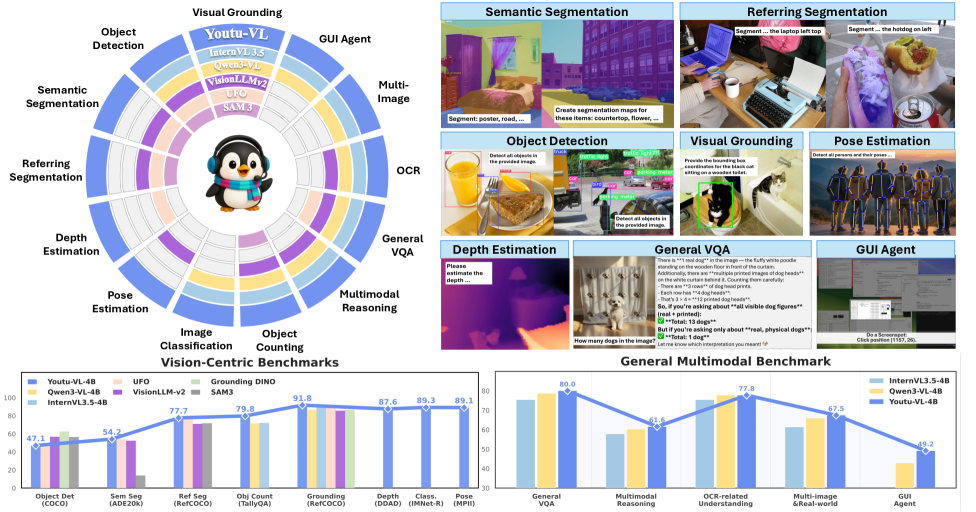
Повышение производительности с помощью передовых техник
В архитектуре Youtu-VL для эффективной дискретизации визуальных признаков используется метод Index Backpropagation Quantization (IBQ), интегрированный непосредственно в Vision Tokenizer. IBQ позволяет преобразовать непрерывные векторы визуальных признаков в дискретные индексы, что снижает вычислительную сложность и объем памяти, необходимые для обработки изображений. Этот процесс квантизации осуществляется с применением обратного распространения ошибки (backpropagation), обеспечивая возможность обучения и оптимизации дискретных представлений визуальных данных. В результате достигается более эффективное кодирование визуальной информации, что способствует повышению производительности модели при решении задач мультимодального анализа.
Механизм Cross-Attention Fusion усовершенствует процесс токенизации путем анализа семантических признаков с учетом структурных ограничений. Данный подход позволяет более эффективно извлекать и кодировать визуальную информацию, учитывая взаимосвязи между различными элементами изображения. В процессе работы Cross-Attention Fusion использует механизм внимания для выявления наиболее релевантных семантических признаков, одновременно накладывая структурные ограничения, которые обеспечивают согласованность и целостность токенизированного представления. Это позволяет повысить точность и эффективность модели при решении задач, требующих понимания семантического содержания изображений.
В основе обучения Youtu-VL лежит функция потерь NTP-M (Neural Text-to-image Pre-training with Multi-label contrastive learning), использующая многометочное обучение с контрастивным обучением. Для повышения надежности и эффективности плотного визуального надзора применяется метод выборки на основе дисперсии. Этот подход позволяет динамически взвешивать обучающие примеры, уделяя больше внимания тем, которые вносят наибольший вклад в процесс обучения, и снижая влияние выбросов или менее информативных данных. Реализация с использованием дисперсионной выборки способствует более устойчивому и точному обучению модели, улучшая ее способность к обобщению и решению задач, требующих детального понимания визуальной информации.
Модель Youtu-VL демонстрирует передовые результаты в задачах мультимодального понимания, достигая 83.9 баллов на бенчмарке MMMBench (English), приблизительно 89.1% точности на MMVet, 74.6% на RealWorldQA и 76.9% на IFEval. Данные показатели подтверждают эффективность предложенной архитектуры и методов обучения в решении сложных задач, требующих интеграции визуальной и текстовой информации. Результаты на различных бенчмарках демонстрируют обобщающую способность модели и ее применимость к широкому спектру мультимодальных задач.
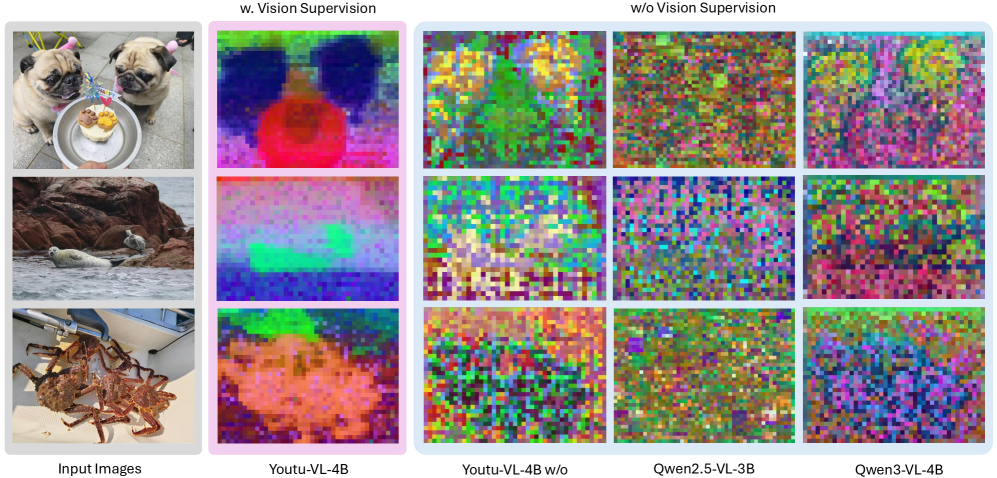
К созданию надежных и универсальных визуальных агентов
Способность Youtu-VL выполнять задачи плотного предсказания открывает широкие возможности в областях, таких как семантическая сегментация и оценка глубины. В семантической сегментации модель способна классифицировать каждый пиксель изображения, выделяя объекты и их границы с высокой точностью, что критически важно для автономных транспортных средств и робототехники. В задачах оценки глубины Youtu-VL позволяет создавать детальные карты глубины окружения, необходимые для навигации и взаимодействия с миром. Такая универсальность достигается благодаря архитектуре, позволяющей модели одновременно понимать как визуальную информацию, так и языковые инструкции, что делает ее мощным инструментом для создания интеллектуальных систем, способных к комплексному анализу сцены и принятию обоснованных решений.
Разработанная архитектура демонстрирует исключительную обобщающую способность и приспособляемость к непредсказуемым условиям реального мира, что делает ее перспективной для широкого спектра практических применений, требующих надёжного визуального восприятия. В отличие от специализированных систем, обученных для решения конкретных задач, данная платформа способна эффективно функционировать в динамичных и неструктурированных средах, где визуальные данные могут быть неполными, зашумленными или содержать неожиданные объекты. Такая адаптивность особенно ценна в задачах, связанных с автономной навигацией, робототехникой, мониторингом окружающей среды и анализом изображений в условиях, значительно отличающихся от тех, в которых система была первоначально обучена. Благодаря своей универсальности, платформа способна обеспечивать устойчивую работу и точные результаты даже при столкновении с ранее невиданными ситуациями, что является ключевым требованием для создания по-настоящему интеллектуальных и автономных агентов.
Объединение возможностей компьютерного зрения и обработки естественного языка в рамках Youtu-VL открывает перспективные пути к созданию интеллектуальных и универсальных агентов искусственного интеллекта. Данный подход позволяет не просто распознавать визуальную информацию, но и понимать ее контекст, а также взаимодействовать с окружающим миром на основе полученных знаний. В отличие от традиционных систем, ограниченных конкретными задачами, Youtu-VL стремится к созданию агентов, способных к комплексному восприятию и осмыслению реальности, что необходимо для эффективного функционирования в динамичных и непредсказуемых условиях. Это создает основу для разработки систем, которые могут решать широкий спектр задач, от навигации и манипулирования объектами до понимания сложных сценариев и взаимодействия с людьми на естественном языке.
Разработанная система Youtu-VL демонстрирует впечатляющие результаты в различных областях компьютерного зрения и обработки естественного языка. На тестовом наборе ADE20k, предназначенном для семантической сегментации, модель достигла показателя в 54.2 mIoU, что свидетельствует о высокой точности выделения объектов на изображениях. Не менее значим успех в задаче понимания инструкций в реальном мире — на наборе OSWorld система показала 38.8% успешных выполнений, подтверждая способность к адаптации и решению сложных задач. Кроме того, Youtu-VL продемонстрировала высокий уровень знаний и рассуждений, набрав 76.8 баллов на тесте MMLU-Redux, что указывает на широкие возможности применения в интеллектуальных системах и агентах.
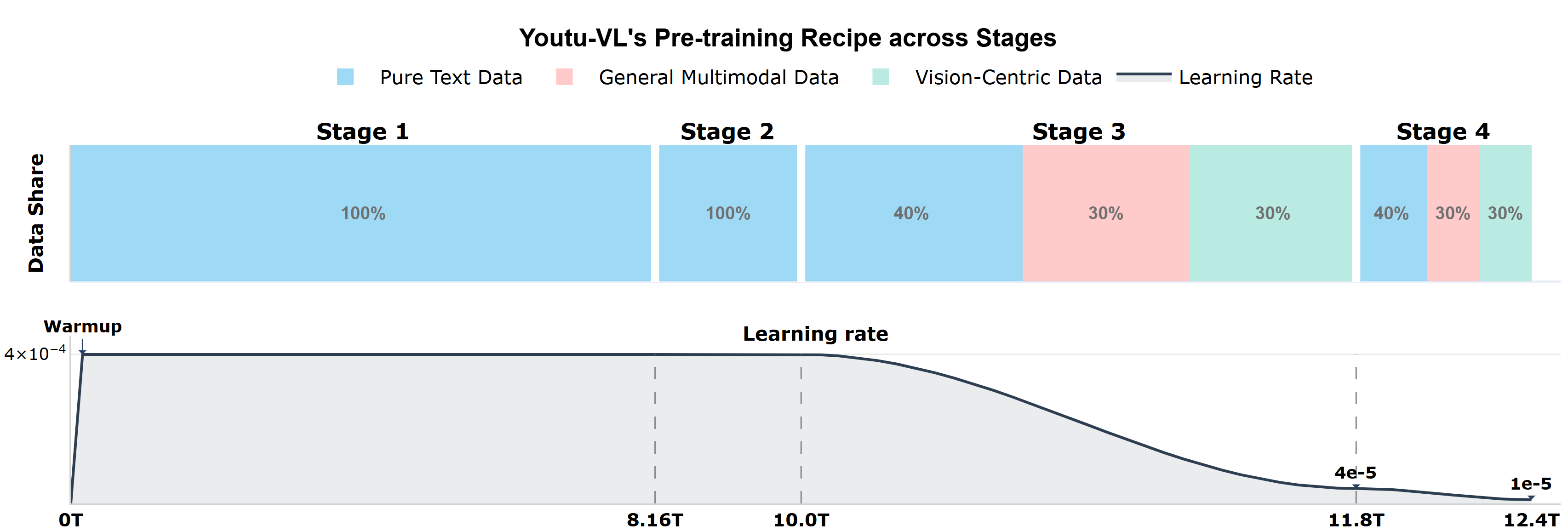
Исследование представляет собой не просто инженерный трюк, а попытку уговорить хаос данных. Youtu-VL, переходя от текстовой до визуальной доминанты, демонстрирует, что истинное понимание рождается не из четких инструкций, а из способности модели уловить суть визуального мира. Как однажды заметил Джеффри Хинтон: «Мир не дискретен, просто у нас нет памяти для float». Эта фраза отражает суть подхода Youtu-VL — модель стремится не к абсолютной точности, а к гибкости и способности генерировать осмысленные представления, что особенно важно для задач, ориентированных на зрение. Переход к vision-as-target — это не просто смена парадигмы, это признание того, что данные говорят с нами на языке образов, и задача исследователя — научиться этот язык понимать.
Что дальше?
Представленная работа, стремясь перевернуть иерархию в моделях «зрение-язык», обнаруживает, что даже смена полюсов не гарантирует постижение истины. Переход к «зрение-как-цель» — это не столько научный прорыв, сколько элегантная перестановка цифр в бесконечном уравнении хаоса. Успехи, безусловно, впечатляют, но они лишь подтверждают старую истину: модель работает ровно до тех пор, пока ей не приказано объяснять реальность, а не описывать её прихоти.
Очевидно, что будущее мультимодального обучения лежит не в усложнении архитектур, а в смирении перед неполнотой данных. Более плотное восприятие — это хорошо, но что, если само «плотное» — иллюзия, созданная нашим стремлением к порядку? Истинная задача — не построить модель, которая видит всё, а создать заклинание, которое убеждает нас, что мы понимаем увиденное.
Поиск единой архитектуры, способной охватить и общие, и специализированные задачи, — это благородная, но, возможно, тщетная надежда. Возможно, стоит признать, что каждая задача требует своего собственного демона, и вместо универсального решения искать способы примирить их между собой. В конечном итоге, данные не скажут нам, что есть истина, — они лишь нашепчут правдоподобные оправдания.
Оригинал статьи: https://arxiv.org/pdf/2601.19798.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
2026-01-29 03:01