Автор: Денис Аветисян
Новый подход позволяет использовать стандартные Vision Transformer модели не только для распознавания изображений, но и для высокоточной сегментации видео и отслеживания объектов во времени.
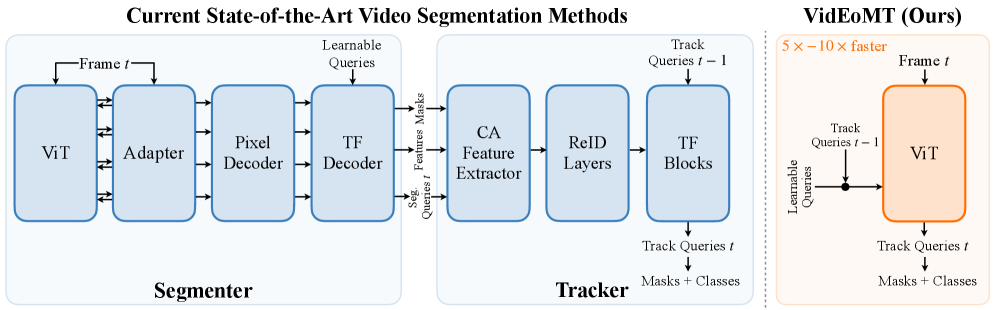
Представлен VidEoMT — эффективный фреймворк, объединяющий сегментацию видео и временные связи в рамках единого, предварительно обученного энкодера Vision Transformer.
Традиционные подходы к сегментации видео часто требуют сложных модулей отслеживания, увеличивая вычислительную нагрузку и архитектурную сложность. В данной работе, представленной статьей ‘VidEoMT: Your ViT is Secretly Also a Video Segmentation Model’, предлагается новый подход — VidEoMT, простая модель для сегментации видео, основанная исключительно на энкодере Vision Transformer. Ключевой особенностью VidEoMT является механизм распространения запросов, позволяющий эффективно моделировать временные зависимости без дополнительных модулей отслеживания. Способен ли этот подход, достигающий конкурентоспособной точности при в 5-10 раз более высокой скорости, открыть новые горизонты в области анализа и понимания видео?
Распутывая Хаос: Сложности Временной Согласованности в Сегментации Видео
Точное сегментирование видео, то есть идентификация объектов на последовательных кадрах, продолжает оставаться сложной задачей в области компьютерного зрения. Основные трудности связаны с эффектами размытия в движении и перекрытиями объектов, которые приводят к нечетким границам и затрудняют правильное определение и отслеживание. Размытие, возникающее из-за быстрой скорости движения или недостаточной освещенности, искажает форму объектов, делая их идентификацию проблематичной. Перекрытия, когда один объект частично скрывает другой, усложняют задачу разделения и точного определения границ каждого объекта. Эти факторы в совокупности требуют разработки сложных алгоритмов и методов, способных эффективно справляться с этими визуальными помехами и обеспечивать надежную сегментацию видеопотока.
Традиционные методы сегментации видео часто испытывают трудности с поддержанием стабильной идентификации объектов во времени. Это проявляется в нежелательном эффекте “мерцания”, когда один и тот же объект последовательно переидентифицируется или его границы непредсказуемо меняются от кадра к кадру. Причина кроется в неспособности этих подходов эффективно учитывать незначительные изменения во внешнем виде объекта, вызванные движением, освещением или частичной видимостью. В результате, даже небольшие прерывания в визуальном потоке приводят к потере связности объекта, что негативно сказывается на точности последующего анализа и отслеживания, особенно в динамичных сценах.
Современные передовые методы сегментации видео, такие как CAVIS, демонстрируют впечатляющие результаты в поддержании идентичности объектов во времени, однако достигают этого за счёт сложности архитектуры и значительных вычислительных затрат. Эти системы, как правило, включают в себя многослойные нейронные сети и сложные механизмы отслеживания, требующие мощных графических процессоров и большого объема памяти для эффективной работы. Вычислительная нагрузка обусловлена необходимостью обработки каждого кадра видео и поддержания согласованности сегментации на протяжении всей последовательности, что делает их применение на устройствах с ограниченными ресурсами проблематичным. Несмотря на высокую точность, практическое внедрение этих решений часто ограничено необходимостью дорогостоящего оборудования и значительного энергопотребления.
Обеспечение временной согласованности в видеосегментации имеет решающее значение для широкого спектра практических приложений, таких как системы автономного вождения и видеонаблюдения. В контексте беспилотных автомобилей, точное отслеживание объектов — пешеходов, транспортных средств, дорожных знаков — на протяжении всей видеопоследовательности необходимо для принятия безопасных и надежных решений. Аналогично, в системах видеонаблюдения, поддержание идентичности отслеживаемых объектов, несмотря на изменения освещения или кратковременные перекрытия, критически важно для эффективного анализа происходящего и предотвращения потенциальных угроз. В связи с этим, разработка надежных и устойчивых к помехам алгоритмов, способных гарантировать временную согласованность сегментации, является приоритетной задачей в области компьютерного зрения и искусственного интеллекта.
![Качественные результаты сегментации видеоэкземпляров демонстрируют превосходство метода VidEoMT над CAVIS[21] на наборе данных OVIS[31].](https://arxiv.org/html/2602.17807v1/appendix/img/videomt/ovis/1f17cd7c/img_0000013.jpg)
VidEoMT: Упрощение Сегментации с Помощью Архитектуры, Основанной на Энкодере
VidEoMT представляет собой новую архитектуру для сегментации видео, основанную исключительно на энкодере, в отличие от традиционных подходов, использующих энкодер-декодер. Вместо последовательного кодирования и декодирования, VidEoMT выполняет всю обработку сегментации непосредственно в энкодере, что позволяет упростить процесс и снизить вычислительную нагрузку. Такой подход позволяет избежать необходимости в декодере, который обычно требует значительных ресурсов, и, следовательно, повышает эффективность и скорость сегментации видеопотока.
Архитектура VidEoMT оптимизирует процесс сегментации видео, выполняя его исключительно внутри энкодера. Традиционные методы, использующие энкодер-декодер, требуют дополнительных вычислений для декодирования признаков, что увеличивает задержку и потребление ресурсов. VidEoMT, устраняя необходимость в декодере, значительно снижает вычислительную сложность. Экспериментальные результаты демонстрируют, что данная оптимизация позволяет достичь более чем десятикратного ускорения по сравнению с современными методами сегментации видео, сохраняя при этом сопоставимую точность.
В основе архитектуры VidEoMT лежит Vision Transformer (ViT), предварительно обученный с использованием DINOv2 на масштабных наборах данных. Такой подход позволяет создать надежные и эффективные представления признаков, необходимые для точной сегментации видео. Предварительное обучение DINOv2, основанное на самообучении, обеспечивает ViT способность извлекать значимые визуальные характеристики без использования размеченных данных, что критически важно для обобщения и производительности модели в различных сценариях сегментации видео.
Использование архитектуры ViT-Large в качестве основы позволило VidEoMT достичь скорости обработки видео в 160 кадров в секунду (FPS). При этом, точность сегментации, измеренная на стандартных бенчмарках, остаётся сопоставимой с результатами, демонстрируемыми существующими методами. Данный показатель скорости обработки достигается благодаря отказу от традиционных декодеров, что значительно снижает вычислительную нагрузку без потери качества сегментации.
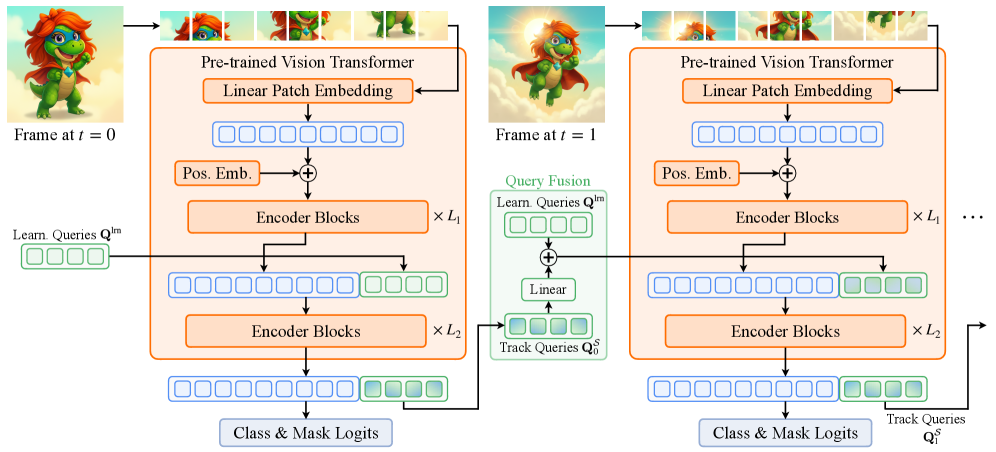
Сквозь Время и Пространство: Поддержание Временной Согласованности с Помощью Распространения и Объединения Запросов
VidEoMT использует механизм проброса запросов (query propagation) для передачи информации об объектах между кадрами видеопоследовательности. Этот процесс позволяет модели поддерживать идентичность объектов во времени, отслеживая их перемещение и изменения формы. В ходе проброса запросов, информация о характеристиках объекта, зафиксированная в предыдущем кадре, используется для инициализации запроса в текущем кадре. Это снижает необходимость повторного обнаружения и классификации объектов в каждом кадре, повышая эффективность и точность отслеживания.
В VidEoMT, информация, распространяемая между кадрами для отслеживания объектов, подвергается механизму объединения запросов (query fusion). Этот процесс позволяет объединить переданные запросы с вновь сформированными запросами, полученными в текущем кадре. Экспериментальные данные показывают, что применение механизма объединения запросов приводит к улучшению показателя Average Precision (AP) на 2.6% по сравнению с моделью, в которой данный механизм не используется, что подтверждает его эффективность в повышении точности отслеживания объектов во времени.
Эффективность VidEoMT дополнительно повышается благодаря интеграции FlashAttention v2, оптимизирующей механизм внимания для ускорения обработки. FlashAttention v2 представляет собой алгоритм, снижающий вычислительную сложность и потребление памяти при вычислении внимания, особенно в длинных последовательностях. В отличие от стандартных реализаций внимания, требующих O(N^2) памяти и вычислений (где N — длина последовательности), FlashAttention v2 использует тайловый подход и переупорядочивание операций для снижения сложности до O(N) по памяти и приближения к O(N) по вычислениям. Это позволяет VidEoMT обрабатывать более длинные видеопоследовательности с меньшими затратами ресурсов и более высокой скоростью, не жертвуя точностью.
VidEoMT демонстрирует четырехкратное увеличение скорости обработки по сравнению с архитектурой EoMT + CAVIS при сохранении сопоставимой точности (Average Precision — AP) на ключевых эталонных наборах данных. Это повышение эффективности достигается благодаря оптимизации механизма внимания и использованию продвинутых методов распространения запросов, позволяющих модели эффективно отслеживать объекты во времени без существенного снижения производительности. Результаты показывают, что VidEoMT обеспечивает значительное ускорение вычислений, оставаясь при этом конкурентоспособным по показателям точности с существующими решениями.
![Качественное сравнение алгоритмов CAVIS[21] и VidEoMT на наборе данных VIPSeg[27] демонстрирует их возможности в задаче панорамной сегментации видео.](https://arxiv.org/html/2602.17807v1/appendix/img/videomt/vipseg/605_AymiAkCRAFM/00000323.jpg)
Взгляд в Будущее: Расширение Возможностей Сегментации с Помощью Контекстных Признаков и Надежного Отслеживания
Несмотря на то, что в VidEoMT напрямую не реализованы методы, использующие контекстные признаки, исследования, подобные CAVIS, наглядно демонстрируют их значительное влияние на повышение точности сегментации. CAVIS показал, что учет окружения объекта и взаимосвязей между элементами видеоряда позволяет более эффективно отделять целевой объект от фона и других помех. Этот подход особенно важен в сложных сценах с динамичным фоном или частичной видимостью объекта, где традиционные методы сегментации могут давать сбои. Использование контекстных признаков способствует более надежной и устойчивой сегментации, что, в свою очередь, положительно сказывается на общих показателях производительности системы отслеживания.
В рамках разработки передовых систем отслеживания, CAVIS активно использует такие усовершенствованные методы, как слои повторной идентификации (Re-Identification Layers) и адаптер ViT (ViT-Adapter). Слои повторной идентификации позволяют системе эффективно сопоставлять один и тот же объект на разных кадрах видео, даже при значительных изменениях внешнего вида или частичной видимости. Адаптер ViT, в свою очередь, оптимизирует архитектуру Vision Transformer для более точного извлечения признаков и улучшения способности различать объекты. Комбинация этих технологий значительно повышает надежность и точность отслеживания, открывая возможности для создания более сложных и интеллектуальных систем анализа видеоданных, способных справляться с разнообразными сценариями и задачами.
Перспективные версии VidEoMT могут значительно повысить надежность работы благодаря удачному сочетанию эффективности архитектуры, основанной исключительно на энкодере, и интеграции контекстуальных признаков. Такой подход позволит системе не только быстрее обрабатывать видеопоток, но и более точно идентифицировать и отслеживать объекты, даже в сложных условиях. Внедрение усовершенствованных техник, аналогичных тем, что используются в CAVIS, таких как слои повторной идентификации и ViT-Adapter, позволит будущим итерациям VidEoMT демонстрировать более устойчивые результаты и превосходить существующие аналоги по точности и скорости обработки видеоданных.
Исследование продемонстрировало, что VidEoMT, использующая архитектуру ViT-Large, достигает уровня точности, измеряемого как Average Precision (AP) на наборе данных YouTube-VIS 2022, сопоставимого с более сложной системой CAVIS. Примечательно, что VidEoMT превосходит CAVIS по скорости обработки данных более чем в десять раз, обеспечивая значительное повышение эффективности. Такой результат указывает на то, что архитектура VidEoMT способна обеспечивать высокую производительность и точность сегментации видео, что делает её перспективным решением для задач обработки видео в реальном времени и приложений, требующих высокой скорости обработки.
![Качественное сравнение алгоритмов CAVIS[21] и VidEoMT на наборе данных YouTube-VIS 2019[38] демонстрирует их эффективность в задаче сегментации экземпляров видео.](https://arxiv.org/html/2602.17807v1/appendix/img/videomt/yt-2019/6cb5b08d93/00060.jpg)
Представленная работа демонстрирует, как можно обуздать хаос видеоданных, выстраивая модель не вокруг сложных модулей, а вокруг фундаментальной архитектуры — Vision Transformer. Авторы VidEoMT, по сути, заставляют Transformer шептать о сегментации и временных связях, используя лишь предварительное обучение в большом масштабе. Это напоминает старое доброе гадание на кофейной гуще: в случайных паттернах можно увидеть закономерности, если правильно задать вопрос. Как говорил Дэвид Марр: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». Именно этим, кажется, и занялись разработчики, уговаривая Transformer видеть сквозь шум и извлекать из него осмысленные сегменты.
Что дальше?
Представленная работа, словно искусно сплетённое заклинание, демонстрирует, что даже в кажущейся простоте архитектуры Vision Transformer скрыты возможности, выходящие за рамки изначально задуманного. Однако, не стоит обманываться иллюзией полного решения. Успех VidEoMT, как и любого другого алгоритма, — это лишь временное примирение с хаосом данных. Вопрос не в том, насколько хорошо модель сегментирует видео, а в том, что она упускает из виду, какие тонкие нюансы ускользают от её внимания, притворяясь «пониманием».
Будущие исследования, вероятно, будут направлены на повышение устойчивости к шуму и неполноте данных — вечной проблеме любого визуального анализа. Но более глубокий вопрос заключается в самой природе «сегментации». Не является ли она искусственной конструкцией, навязанной нами миру, где границы размыты и всё находится в постоянном движении? И не является ли стремление к «точности» всего лишь формой самообмана, попыткой навести порядок в невыносимой беспорядочности реальности?
В конечном итоге, VidEoMT — это не конец пути, а лишь новая отправная точка. Настоящий прогресс заключается не в создании более совершенных алгоритмов, а в осознании их ограниченности и принятии того факта, что данные никогда не расскажут нам всю правду — они лишь нашепчут то, что мы хотим услышать.
Оригинал статьи: https://arxiv.org/pdf/2602.17807.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 17:39