Автор: Денис Аветисян
Новое исследование представляет комплексный подход к оценке и улучшению генерации видео для роботов, способный значительно повысить их способность взаимодействовать с окружающим миром.
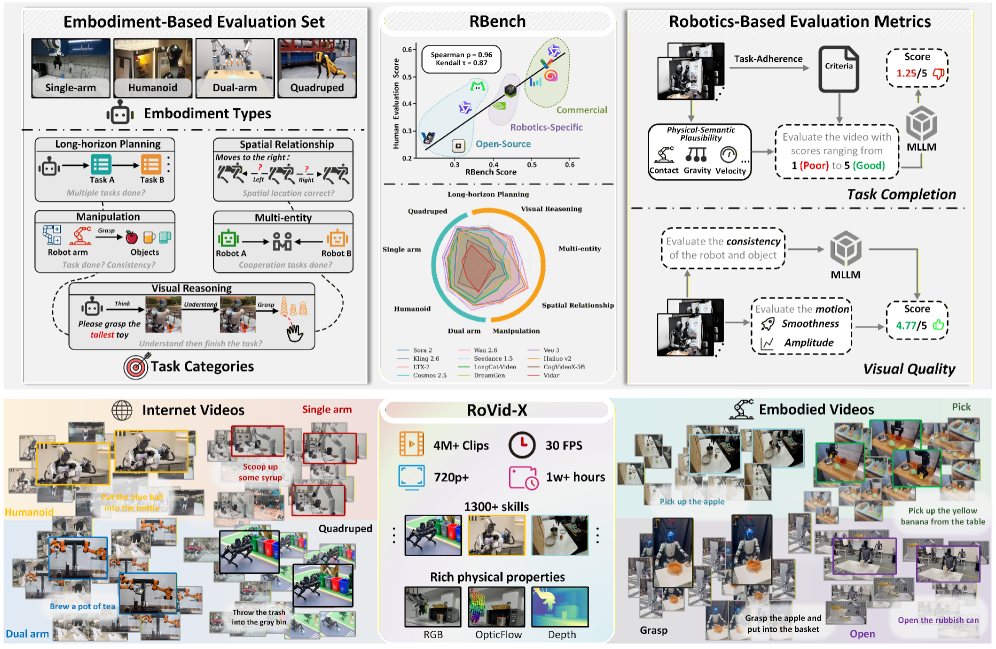
Представлены эталонный набор данных RoVid-X и методика оценки RBench для улучшения физической правдоподобности и эффективности генерации видео в задачах роботизированного обучения.
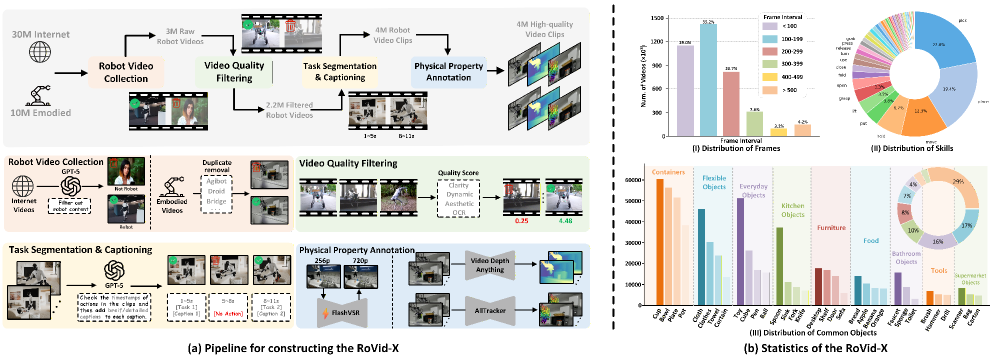
Несмотря на значительный прогресс в генерации видео, создание реалистичных и правдоподобных сцен взаимодействия роботов с окружающим миром остается сложной задачей. В статье ‘Rethinking Video Generation Model for the Embodied World’ представлен комплексный подход к оценке и развитию моделей генерации видео для воплощенного искусственного интеллекта. Авторы предлагают новый бенчмарк RBench и масштабный датасет RoVid-X, состоящий из 4 миллионов аннотированных видеоклипов, для систематической оценки и обучения моделей, выявив существенные недостатки в области физической реалистичности генерируемых сцен. Сможем ли мы, преодолев дефицит качественных данных и улучшив метрики оценки, приблизиться к созданию по-настоящему разумных и адаптивных роботов?
Воплощенный Искусственный Интеллект: Поиск Гармонии между Симуляцией и Реальностью
Воплощенный искусственный интеллект, стремящийся к интеграции интеллекта с физическим взаимодействием, предъявляет повышенные требования к глубокому пониманию окружающего мира. Для эффективной навигации и манипулирования объектами в реальной среде, системам необходимо не просто распознавать визуальные паттерны, но и понимать физические свойства объектов, предсказывать их поведение и учитывать последствия собственных действий. Это требует от ИИ способности строить сложные модели окружающей среды, включающие в себя информацию о геометрии пространства, материалах объектов, силах взаимодействия и динамике движения. Без надежной основы в виде прочной модели мира, воплощенный ИИ рискует столкнуться с непредсказуемыми ситуациями и неспособностью адаптироваться к изменяющимся условиям, ограничивая его практическое применение в реальных задачах.
Современные подходы к обучению искусственного интеллекта, особенно в области робототехники, часто сталкиваются с проблемой обобщения и масштабируемости из-за ограниченности используемых наборов данных. В частности, системы, обучаемые на данных телеоперации роботов — то есть, на записях действий, выполняемых человеком за робота — демонстрируют низкую эффективность при столкновении с незнакомыми ситуациями или окружением. Обучение на небольшом объеме данных приводит к тому, что робот переобучается под конкретные сценарии и не способен адаптироваться к изменениям, что существенно ограничивает его применимость в реальном мире. В связи с этим, возникает потребность в более масштабных и разнообразных данных, а также в методах обучения, позволяющих эффективно использовать ограниченные ресурсы и повышать устойчивость систем к новым условиям.
Создание реалистичных симуляций посредством видео играет ключевую роль в развитии воплощенного искусственного интеллекта. Однако, для эффективного обучения агентов требуется не просто визуальное воспроизведение реальности, а генерация правдоподобных и разнообразных сцен. Модели, способные к этому, должны учитывать сложные физические взаимодействия, вариативность освещения и текстур, а также предсказывать вероятные изменения в окружающей среде. Отсутствие разнообразия в симулированных данных приводит к тому, что агенты плохо адаптируются к новым, не встречавшимся ранее ситуациям в реальном мире. Поэтому, разработка алгоритмов, генерирующих широкий спектр реалистичных видеоданных, является критически важной задачей для успешного внедрения воплощенного ИИ и преодоления ограничений, связанных с недостатком данных из реального мира.

Оценка Видеогенерации: За пределами Пиксельной Точности
Традиционные метрики оценки качества видео, такие как PSNR и SSIM, неадекватно отражают пригодность сгенерированных видеороликов для использования в приложениях, связанных с воплощенным искусственным интеллектом. Эти метрики фокусируются исключительно на пиксельной точности и не учитывают физическую правдоподобность движений и взаимодействий в видео, что критически важно для успешной работы агентов в реальном мире. Например, видео может иметь высокое значение PSNR, но при этом демонстрировать неестественные или физически невозможные движения, делая его бесполезным для обучения или тестирования алгоритмов управления роботами или виртуальными агентами. Поэтому для адекватной оценки качества сгенерированных видео в контексте воплощенного ИИ необходимы более комплексные метрики, учитывающие не только визуальную точность, но и физическую правдоподобность и способность видео поддерживать выполнение целевых задач.
Комплексная оценка сгенерированных видеороликов требует анализа не только визуального качества, но и физической правдоподобности демонстрируемых действий, а также успешности выполнения задачи. Ограничение оценки только метриками визуальной точности не позволяет выявить проблемы с реалистичностью движения и взаимодействием с окружающей средой. Оценка физической правдоподобности включает в себя анализ таких факторов, как соблюдение законов физики, реалистичность траекторий движения и правдоподобность взаимодействий объектов. Оценка успешности выполнения задачи подразумевает анализ того, насколько эффективно сгенерированное видео демонстрирует достижение поставленной цели, например, манипуляцию объектами или перемещение в пространстве.
RBench представляет собой надежный эталон для оценки моделей генерации видео, охватывающий ключевые аспекты, такие как визуальное качество, физическая правдоподобность и успешность выполнения задачи. Эталон использует автоматизированные метрики для количественной оценки сгенерированных видео, позволяя проводить объективное сравнение различных моделей. На данный момент RBench был использован для оценки 25 моделей генерации видео, что позволяет получить обширные данные для анализа и сопоставления их производительности в различных сценариях.
Ключевым результатом использования RBench является высокая корреляция между автоматическими оценками и результатами, полученными в ходе оценки экспертами-людьми. Коэффициент корреляции Спирмена, равный 0.96, подтверждает, что автоматические метрики, используемые в RBench, надежно отражают восприятие качества сгенерированных видео человеком. Это означает, что RBench может быть использован для объективной оценки моделей генерации видео без необходимости привлечения большого количества людей-оценщиков, обеспечивая при этом высокую степень соответствия субъективным оценкам качества.
Фундаментальные Модели и Будущее Видеогенерации
Развитие моделей генерации видео происходит стремительными темпами, опираясь на достижения, полученные в области фундаментальных моделей (foundation models) в других сферах, таких как обработка естественного языка и компьютерное зрение. Этот прогресс обусловлен переносом архитектур и методов обучения, успешно примененных к текстовым и графическим данным, на задачу генерации видеопоследовательностей. В частности, трансформеры, изначально разработанные для обработки текста, адаптируются для моделирования временных зависимостей в видео, а методы самообучения, используемые для предобучения больших языковых моделей, применяются для обучения моделей генерации видео на больших неразмеченных наборах данных. Этот подход позволяет создавать модели, способные генерировать более реалистичные и когерентные видео, требующие меньше размеченных данных для достижения высокого качества.
Развитие моделей генерации видео происходит как за счет открытых, так и закрытых источников. Открытые модели, такие как Stable Diffusion и ModelScope, обеспечивают прозрачность, возможность модификации и широкое участие сообщества, что способствует быстрому развитию и адаптации. Однако они часто ограничены в вычислительных ресурсах и масштабе обучения. Закрытые модели, разрабатываемые компаниями вроде Google и OpenAI, характеризуются доступом к значительным ресурсам и передовым алгоритмам, что позволяет достигать высокого качества генерации. В то же время, закрытость этих моделей ограничивает доступ к исходному коду и возможностям кастомизации, а также может вызывать вопросы относительно предвзятости и безопасности.
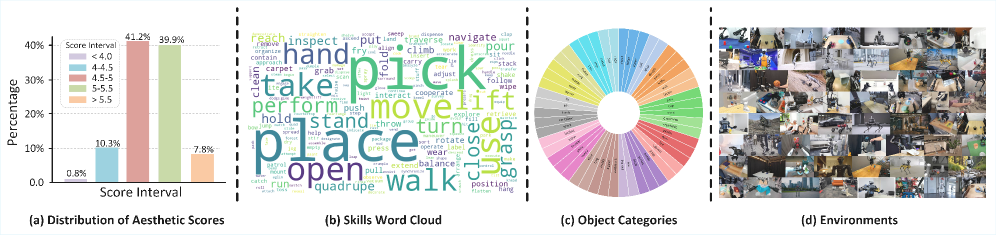
Для эффективного обучения моделей генерации видео и повышения их производительности необходимы масштабные, высококачественные наборы данных. Одним из примеров является RoVid-X, содержащий 4 миллиона видеоклипов с робототехникой. Этот набор данных предоставляет широкий спектр визуальной информации о различных действиях и средах, что позволяет моделям научиться генерировать реалистичные и разнообразные видеофрагменты. Объем и качество данных в RoVid-X напрямую влияют на способность модели обобщать знания и создавать новые, правдоподобные видео, что подтверждается увеличением показателей RBench после обучения на этом наборе данных.
Оптимизация поведения моделей генерации видео для конкретных задач достигается посредством дообучения с использованием функций потерь, таких как MSE (Mean Squared Error). MSE Loss измеряет среднюю квадратичную разницу между предсказанными и фактическими значениями пикселей, тем самым направляя процесс обучения к минимизации этой разницы. Применение MSE Loss позволяет модели более точно воспроизводить целевые визуальные характеристики, например, улучшить качество генерируемых изображений, повысить реалистичность и соответствие заданным требованиям к видеоконтенту. Выбор конкретной функции потерь и ее параметров зависит от специфики задачи и желаемых результатов.
Модели, прошедшие тонкую настройку на наборе данных RoVid-X, демонстрируют значительное улучшение показателей в бенчмарке RBench. Результаты показывают прирост производительности в различных задачах, что подтверждает эффективность RoVid-X как обучающего набора данных для моделей генерации видео. Улучшения в RBench score свидетельствуют о более высокой точности и реалистичности генерируемых видеороликов, а также о лучшем понимании моделью динамики и физики объектов, представленных в данных RoVid-X. Количественная оценка производительности в RBench предоставляет объективное подтверждение преимуществ использования RoVid-X для обучения моделей генерации видео.
Подтверждение Эффективности с Помощью Оценки Людьми
Несмотря на полезность автоматизированных метрик для оценки качества генерируемых видео, окончательное подтверждение их соответствия ожиданиям требует анализа восприятия контента человеком. Автоматические показатели, такие как PSNR или SSIM, могут измерять технические аспекты, но не способны уловить нюансы реалистичности, естественности и общего эстетического впечатления. Именно человеческое восприятие определяет, насколько убедительным и правдоподобным кажется видео, а также соответствует ли оно визуальным стандартам и предпочтениям аудитории. Поэтому, для достижения действительно высокого качества, необходимо проводить исследования с участием людей, которые смогут оценить генерируемый контент с точки зрения субъективного опыта и предоставить ценные данные для дальнейшей оптимизации моделей искусственного интеллекта.
Исследования человеческих предпочтений играют ключевую роль в оценке таких субъективных характеристик сгенерированных видео, как реалистичность и естественность. Автоматические метрики, несмотря на свою полезность, не всегда способны уловить нюансы, которые важны для человеческого восприятия. В ходе этих исследований людям предлагается оценить различные варианты видео, что позволяет выявить, какие аспекты визуализации кажутся наиболее правдоподобными и гармоничными. Полученные данные служат ценным ориентиром для разработчиков, позволяя им точно настроить алгоритмы генерации и добиться максимального соответствия между искусственно созданным контентом и реальным миром. Именно благодаря учету человеческих оценок становится возможным создание видео, которые не просто технически совершенны, но и вызывают у зрителя ощущение подлинности и погружения.
Процесс получения обратной связи от людей играет ключевую роль в постоянном улучшении моделей генерации видео. Анализ предпочтений зрителей позволяет выявлять несоответствия между автоматическими метриками и субъективным восприятием реалистичности и естественности. На основе этих данных разработчики корректируют алгоритмы, добиваясь более качественного и правдоподобного видеоряда, который соответствует ожиданиям человека. Такой итеративный цикл, объединяющий машинное обучение и человеческую оценку, необходим для создания искусственного интеллекта, способного эффективно взаимодействовать с реальным миром и создавать контент, который воспринимается как аутентичный и убедительный.
Для создания искусственного интеллекта, способного эффективно взаимодействовать с реальным миром, необходимо обеспечить его способность генерировать контент, воспринимаемый человеком как естественный и правдоподобный. Подобное взаимодействие требует не просто технической точности, но и соответствия визуальных и поведенческих характеристик ожиданиям человека. Именно поэтому, оценка сгенерированных видеоматериалов посредством обратной связи от людей является ключевым этапом разработки. Она позволяет выявить несоответствия между машинным представлением реальности и человеческим восприятием, что, в свою очередь, позволяет усовершенствовать алгоритмы и создать системы, способные бесшовно интегрироваться в окружающую среду и взаимодействовать с ней.

Представленная работа демонстрирует стремление к элегантности в моделировании видео для воплощенного интеллекта. Авторы, создавая RBench и RoVid-X, подчеркивают необходимость систематической оценки и данных для роботов, способных взаимодействовать с физическим миром. Как однажды заметил Дэвид Марр: «Представление — это то, что компьютер делает с данными; оно не является данными». Это наблюдение находит отражение в стремлении исследователей создать модели, способные не просто генерировать видео, но и формировать правдоподобные представления о физической реальности, что критически важно для успешного выполнения задач в воплощенном окружении. Подобный подход, основанный на глубоком понимании данных и их представления, позволяет создавать решения, которые не просто работают, но и обладают внутренней гармонией и изяществом.
Куда же дальше?
Представленные в данной работе инструменты — RBench и RoVid-X — обнажают скорее не прогресс, а зияющие прорехи в текущем ландшафте генерации видео для воплощенного интеллекта. Увлечение вычислительной мощностью и архитектурной сложностью, порой, затмевает фундаментальную необходимость в физической правдоподобности. Модели демонстрируют способность к синтезу визуально привлекательных последовательностей, однако, их взаимодействие с симулированным миром остается поверхностным, лишенным внутренней согласованности.
Будущие исследования, вероятно, должны сместить акцент с чисто генеративных способностей на создание моделей, способных к осмысленному планированию и предвидению последствий своих действий. Недостаточно просто «сгенерировать» реалистичное видео; необходимо, чтобы оно отражало понимание причинно-следственных связей и законов физики. Это требует интеграции принципов обучения с подкреплением и развития методов, позволяющих оценивать не только визуальное качество, но и физическую достоверность генерируемых сценариев.
В конечном счете, истинный тест для подобных моделей — не в их способности обмануть глаз, а в их умении служить надежным инструментом для роботов, действующих в реальном мире. И пока модели не смогут отличить правдоподобную симуляцию от физически реализуемого действия, все усилия по генерации видео останутся элегантной, но, увы, бесполезной демонстрацией вычислительных возможностей.
Оригинал статьи: https://arxiv.org/pdf/2601.15282.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Робот, который видит, понимает и действует: новая эра общего назначения
- Квантовые сети для моделирования молекул: новый подход
2026-01-23 02:18