Автор: Денис Аветисян
Исследователи предлагают инновационный метод представления видеоданных для моделей, объединяющих видео и язык, позволяющий значительно сократить объем используемых токенов.

В статье представлен CoPE-VideoLM — метод кодирования видео, использующий примитивы видеокодеков (векторы движения и остатки) для повышения эффективности и снижения вычислительных затрат.
Существующие видеоязыковые модели (VideoLM) сталкиваются с компромиссом между детализацией и вычислительной эффективностью при обработке видеоданных. В работе ‘CoPE-VideoLM: Codec Primitives For Efficient Video Language Models’ предложен новый подход, использующий примитивы видеокодеков — векторы движения и остатки — для компактного представления временной информации. Такой подход позволяет значительно снизить объем используемых токенов (до 93\%) и ускорить генерацию ответа (до 86\%) без потери качества на задачах видеопонимания. Возможно ли дальнейшее повышение эффективности и расширение возможностей VideoLM за счет более глубокой интеграции с современными технологиями видеокомпрессии?
Понимание Видео: Вызовы и Возможности
Современные модели, объединяющие возможности компьютерного зрения и обработки естественного языка, демонстрируют впечатляющий прогресс, однако анализ продолжительных видеопоследовательностей остается сложной вычислительной задачей. Несмотря на увеличение мощности графических процессоров и разработку более эффективных алгоритмов, обработка каждого кадра в длинном видео требует значительных ресурсов памяти и времени. Это связано с необходимостью учитывать временную зависимость между кадрами, что требует удержания в памяти информации о предыдущих событиях для понимания текущей ситуации. В результате, существующие модели часто сталкиваются с ограничениями при анализе видео большой продолжительности, что затрудняет решение задач, требующих понимания сложных временных взаимосвязей и долгосрочного контекста, таких как распознавание действий, происходящих на протяжении длительного периода времени, или понимание сюжетной линии фильма.
Традиционные методы анализа видео, такие как выбор ключевых кадров, хотя и позволяют снизить вычислительные затраты, зачастую приводят к потере важной временной информации. Вместо целостного восприятия динамики событий, алгоритмы фокусируются лишь на отдельных моментах, что существенно ограничивает возможности глубокого понимания видеоконтента. Подобный подход не позволяет правильно интерпретировать последовательность действий, причинно-следственные связи и намерения участников событий, что особенно критично для задач, требующих анализа сложных сценариев и предсказания будущих действий. В результате, способность системы к полноценному «видеопониманию» значительно снижается, поскольку упускается контекст, формирующийся во времени.
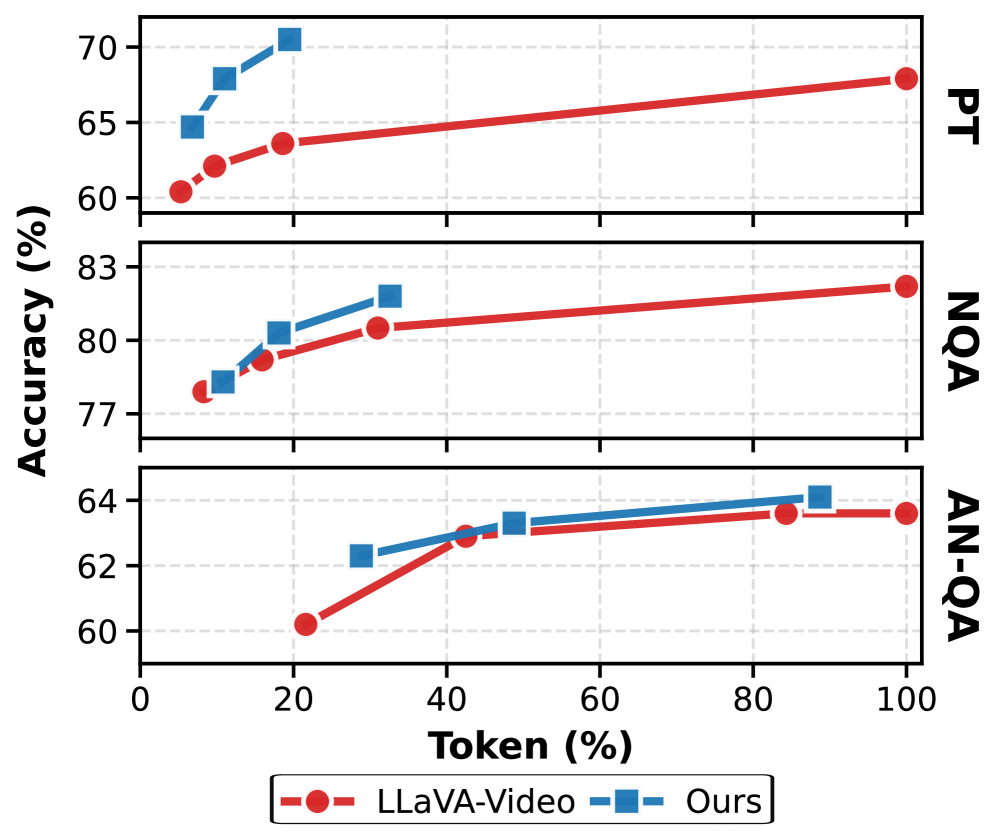
Для объективной оценки прогресса в области понимания видео необходимы надежные эталоны, такие как ActivityNet-QA, PerceptionTest и NextQA. Эти бенчмарки позволяют выйти за рамки простой идентификации объектов или действий и проверить способность моделей к истинному рассуждению о происходящем в видеоряде. ActivityNet-QA требует от моделей отвечать на вопросы, требующие понимания временных отношений и причинно-следственных связей, в то время как PerceptionTest фокусируется на оценке способности к восприятию тонких изменений и деталей. NextQA, в свою очередь, проверяет способность к предвидению будущих событий на основе наблюдаемой видеоинформации. Использование подобных комплексных эталонов крайне важно для развития систем, способных не просто “видеть” видео, но и действительно понимать его содержание и динамику.
Эффективность Видео: Использование Компрессии
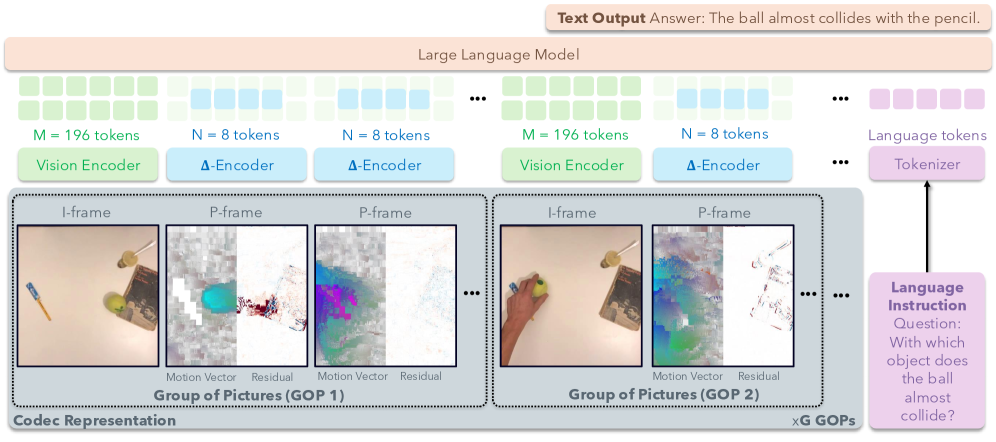
Техники видеокомпрессии, такие как определяющие структуру GOP (Group of Pictures), позволяют снизить объем данных видеофайла при сохранении существенной информации. Структура GOP определяет порядок и типы кадров в видеопотоке: ключевые кадры (I-frames) содержат полную информацию об изображении, а предсказанные кадры (P-frames) и двунаправленные предсказанные кадры (B-frames) содержат только изменения относительно ключевых или предыдущих кадров. Эффективное использование структуры GOP позволяет достичь высокого коэффициента сжатия, уменьшая требования к пропускной способности и объему хранилища, при этом сохраняя приемлемое качество воспроизводимого видео. Размер GOP и частота ключевых кадров напрямую влияют на степень сжатия и возможность быстрого поиска кадров в видео.
Видео кодируется с использованием различных типов кадров для оптимизации размера файла и сохранения качества. I-кадры (Intra-frames) представляют собой полные изображения, кодируемые независимо от других кадров, и служат опорными точками для декодирования. P-кадры (Predictive frames) содержат информацию об изменениях относительно предыдущего I- или P-кадра, что позволяет значительно снизить объем данных. B-кадры (Bi-directional predictive frames) используют информацию как от предыдущего, так и от последующего кадров, обеспечивая еще большую степень сжатия. Анализ структуры этих кадров позволяет извлекать ключевые визуальные характеристики и эффективно представлять видеоданные, что является основой для многих алгоритмов обработки и анализа видео.
CoPE-VideoLM представляет собой новый подход к кодированию видео, который отличается от традиционного сохранения информации в виде необработанных пикселей. Вместо этого, модель кодирует видео, используя векторы движения (Motion Vectors) и остатки (Residuals) — ключевые компоненты, формирующиеся в процессе сжатия видео по стандартам, таким как H.264 и H.265. Векторы движения описывают смещение блоков изображения между кадрами, а остатки представляют собой разницу между предсказанным и фактическим изображением. Такой подход позволяет значительно снизить объем данных, необходимых для представления видео, сохраняя при этом возможность его реконструкции.
Delta-Кодировщик и CoPE-VideoLM: Реализация Эффективности
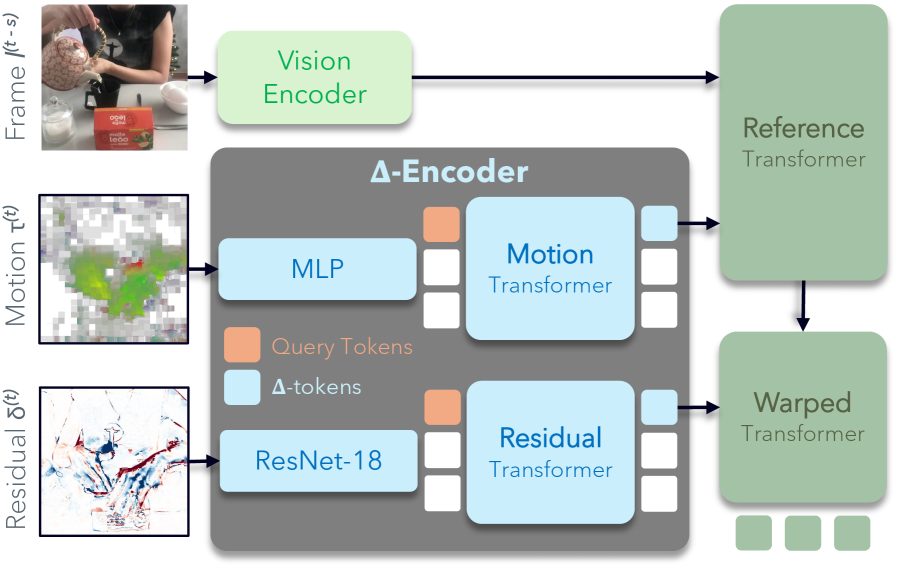
Дельта-кодировщик (Delta Encoder) представляет собой легковесный компонент, предназначенный для обработки векторов движения и остаточных значений (residuals) с целью их преобразования в компактные токены. Этот процесс направлен на минимизацию вычислительной нагрузки, за счет эффективного представления данных о движении и различиях между кадрами в более сжатом виде. Такой подход позволяет снизить требования к памяти и вычислительным ресурсам, необходимым для дальнейшей обработки видеоданных, без существенной потери информации.
Архитектура CoPE-VideoLM осуществляет интеграцию разработанного Delta Encoder с существующей архитектурой LLaVA-Video, используя её базовые компоненты SigLIP и Qwen2. Данный подход позволяет использовать преимущества LLaVA-Video в обработке видео, одновременно снижая вычислительные затраты за счет эффективного кодирования движения и остатков с помощью Delta Encoder. CoPE-VideoLM, таким образом, представляет собой расширение функциональности LLaVA-Video, а не принципиально новую архитектуру, что упрощает процесс внедрения и оптимизации.
Интеграция Delta Encoder с архитектурой LLaVA-Video привела к существенным улучшениям в эффективности токенизации и времени генерации первого токена. В ходе тестирования зафиксировано снижение времени до генерации первого токена до 86.2%, что означает более быструю реакцию модели. Кроме того, применение данного подхода позволило сократить количество необходимых токенов на 93%, что способствует снижению вычислительных затрат и требований к памяти при работе с видеоданными.
Влияние на Будущее Видео: Перспективы Развития
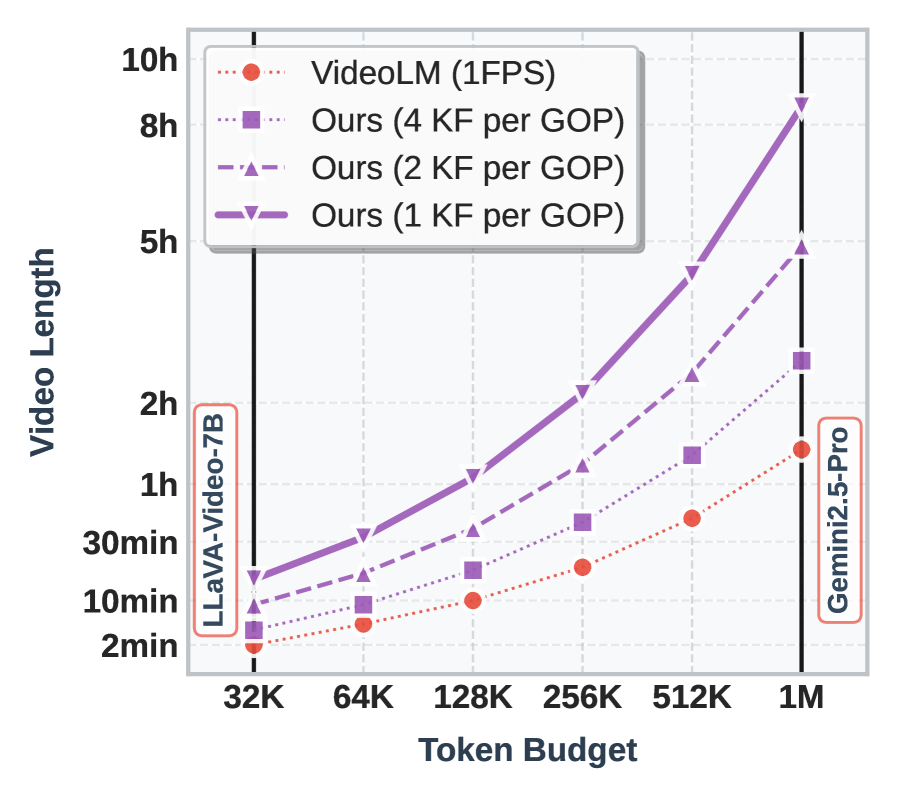
Разработанная модель CoPE-VideoLM открывает новые перспективы для создания более масштабируемых и эффективных видео-языковых моделей (VideoLMs). В основе подхода лежит согласование процесса кодирования видео с принципами сжатия данных, что позволяет значительно уменьшить вычислительные затраты и объём необходимой памяти. Вместо обработки каждого кадра в полном объеме, система фокусируется на наиболее значимой информации, эффективно представляя видеоданные в сжатом формате. Такое решение не только ускоряет обработку, но и потенциально улучшает способность модели к пониманию семантического содержания видео, позволяя ей более эффективно извлекать и анализировать ключевые моменты.
Предложенный подход не только существенно снижает вычислительные затраты, но и потенциально улучшает способность модели концентрироваться на семантически значимой информации в видеопотоке. Исследования показали, что оптимизация кодирования видео позволяет добиться впечатляющего ускорения обработки — на 56.01% по сравнению с базовыми методами, что открывает возможности для создания более быстрых и эффективных систем анализа видеоданных. Это достигается за счет выделения и приоритезации ключевых визуальных элементов, что позволяет модели игнорировать избыточную информацию и сосредоточиться на существенных деталях, влияющих на понимание происходящего.
Перспективы развития предложенного подхода выходят далеко за рамки обработки исключительно видеоданных. Исследователи рассматривают возможность адаптации данной схемы к другим мультимодальным типам информации, таким как комбинации текста, изображений и аудио. Расширение фреймворка на подобные данные позволит создавать более универсальные и мощные модели, способные комплексно анализировать и понимать окружающий мир. Подобная интеграция откроет новые возможности в областях, требующих понимания взаимосвязей между различными типами данных, включая робототехнику, автоматизированный анализ контента и разработку интеллектуальных систем поддержки принятия решений. Дальнейшие исследования в данном направлении могут значительно расширить область применения и влияние разработанной технологии.
Исследование, представленное в данной работе, демонстрирует глубокое понимание принципов эффективного представления видеоданных для моделей, работающих с языком и видео. Авторы, используя примитивы видеокодеков, такие как векторы движения и остатки, достигают значительного снижения количества токенов, необходимых для кодирования временной информации. Это особенно важно, учитывая растущие требования к вычислительным ресурсам при работе с мультимодальными моделями. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект — это не только алгоритмы, но и понимание того, как люди воспринимают мир». В данном случае, понимание принципов сжатия видео позволяет создать более эффективные и ресурсосберегающие модели, способные лучше понимать и интерпретировать визуальную информацию, что соответствует стремлению к созданию более человекоподобного ИИ.
Куда же дальше?
Представленная работа, подобно элегантной декомпозиции сложной системы, выявляет закономерности, ранее скрытые в кажущемся хаосе видеоданных. Использование примитивов кодеков — это, по сути, применение принципов сжатия информации для оптимизации работы языковых моделей, что напоминает эволюционные стратегии, где эффективность достигается за счет минимизации избыточности. Однако, остается открытым вопрос о границах применимости данного подхода. Действительно ли универсальность кодеков позволяет адекватно представить разнообразие временных зависимостей в видео, или же существуют специфические паттерны, требующие индивидуальных решений?
Подобно тому, как в физике фундаментальные константы определяют границы реальности, существуют пределы эффективности токенизации. Дальнейшие исследования должны быть направлены на поиск оптимального баланса между степенью сжатия и сохранением информации, необходимой для выполнения сложных задач анализа видео. Особый интерес представляет возможность адаптивного выбора примитивов кодека в зависимости от характеристик конкретной сцены, что могло бы значительно повысить гибкость и производительность системы.
В конечном счете, данная работа лишь открывает новую главу в истории взаимодействия между машинным зрением и обработкой естественного языка. Подобно тому, как нейронные сети имитируют структуру мозга, будущие модели могут научиться использовать принципы кодирования информации, лежащие в основе восприятия мира.
Оригинал статьи: https://arxiv.org/pdf/2602.13191.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Физика под контролем: Как «научить» модели понимать мир
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовые Заметки: От Праздничной Оптимизации до Глобального Хаба
- Законы масштабирования нейросетей: трещины в науке о материалах
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
2026-02-17 01:27