Автор: Денис Аветисян
Исследование показывает, что модели генерации видео способны эффективно решать задачи пространственного планирования, превосходя текстовые подходы, и демонстрируют улучшение результатов с увеличением продолжительности генерируемого видео.

Модели генерации видео, использующие масштабирование во время тестирования, демонстрируют продвинутые возможности визуального рассуждения и превосходят традиционные методы.
Несмотря на успехи моделей, работающих с текстом и изображениями, сложные задачи визуального рассуждения, требующие пространственного планирования и понимания динамики, остаются сложными. В работе ‘Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning’ предложен новый подход, рассматривающий визуальное рассуждение как задачу генерации видео, где промежуточные кадры служат этапами логических выводов. Эксперименты показали, что такая модель демонстрирует высокую обобщающую способность и эффективно использует визуальный контекст, при этом увеличение продолжительности генерируемого видео улучшает результаты пространственного планирования. Может ли генерация видео стать основой для создания более гибких и надежных систем визуального интеллекта?
Пространственное мышление: Основа разумных действий
Эффективное рассуждение неразрывно связано с развитым пространственным мышлением, которое является одним из фундаментальных аспектов интеллекта. Исследования показывают, что способность мысленно манипулировать объектами, оценивать расстояния и представлять пространственные отношения играет ключевую роль в решении самых разнообразных задач — от простых бытовых ситуаций до сложных научных проблем. Пространственное понимание позволяет прогнозировать последствия действий, оптимизировать стратегии и находить оптимальные решения, что делает его необходимым компонентом когнитивных способностей. Более того, повреждения определенных областей мозга, отвечающих за пространственную ориентацию, часто приводят к нарушениям в процессах рассуждения и принятия решений, подтверждая критическую роль этой способности для общего интеллекта.
Геометрическое мышление и пространственное планирование являются фундаментальными способностями, необходимыми для эффективного взаимодействия с окружающим миром. Эти навыки позволяют не только ориентироваться в пространстве и предсказывать траектории движения объектов, но и решать сложные задачи, требующие визуализации и манипулирования образами. Например, способность мысленно вращать объекты или оценивать расстояния играет ключевую роль в архитектуре, инженерии и даже в повседневных ситуациях, таких как парковка автомобиля или сборка мебели. Более того, исследования показывают, что развитие этих способностей напрямую связано с когнитивными функциями, включая память, внимание и способность к решению проблем, что подчеркивает их значимость для общего интеллекта и адаптации к изменяющимся условиям.

Визуализация мысли: Контекст и применение
Решение задач, таких как сборка фигур из танграма и прохождение лабиринтов, демонстрирует взаимосвязь между пространственным мышлением и последовательным планированием. Пространственное мышление позволяет оценивать форму, размер и взаиморасположение элементов, в то время как последовательное планирование предполагает определение оптимальной последовательности действий для достижения цели. В задачах типа танграма необходимо мысленно вращать и перемещать фигуры, предвидя их взаимное расположение, что требует активного использования пространственного мышления. Аналогично, в лабиринтах требуется оценить пространственные отношения между различными участками пути и спланировать последовательность поворотов для достижения выхода. Успешное выполнение этих задач требует одновременной активации обоих когнитивных процессов и их координации.
Визуальный контекст играет ключевую роль в процессах рассуждения и эффективном решении задач. При решении задач, таких как головоломки или навигация в лабиринтах, предоставление информации в визуальной форме значительно улучшает когнитивные способности. Это связано с тем, что визуальные данные позволяют мозгу быстрее обрабатывать информацию и строить более точные ментальные модели ситуации. Отсутствие визуального контекста требует большего объема когнитивных ресурсов для создания и поддержания необходимой информации, что замедляет процесс решения и увеличивает вероятность ошибок. Исследования показывают, что использование визуальных представлений данных повышает точность и скорость принятия решений в различных областях, от инженерного проектирования до медицинской диагностики.
Визуальный контекст играет ключевую роль в процессе преобразования абстрактных мыслей в конкретные, воспринимаемые формы. Этот механизм позволяет соотносить абстрактные понятия с реальными объектами и явлениями, обеспечивая возможность их более эффективной обработки и понимания. В частности, визуальная информация предоставляет опорную точку для формирования ментальных репрезентаций, что облегчает решение задач, требующих пространственного мышления и планирования. Такая привязка к конкретному, воспринимаемому миру снижает когнитивную нагрузку и повышает точность рассуждений, поскольку абстрактные концепции становятся более осязаемыми и доступными для анализа.
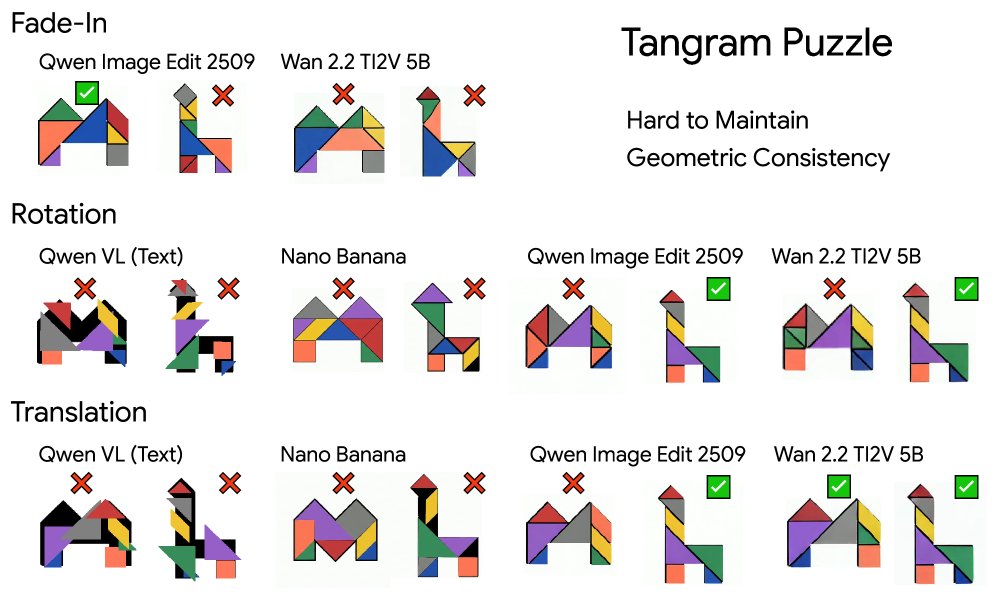
Генерация видео как механизм рассуждений
Модели генерации видео предоставляют новый подход к интеграции визуальной информации с последовательным планированием, позволяя моделировать вероятные исходы действий. В отличие от традиционных методов, требующих явного кодирования правил и ограничений, генеративные модели способны, основываясь на входных данных и обучении, самостоятельно синтезировать визуальные последовательности, демонстрирующие развитие событий. Этот процесс позволяет не только предсказывать результаты действий, но и исследовать различные сценарии и оптимизировать планы, учитывая визуальные последствия. Способность генерировать видео позволяет моделям «проигрывать» различные варианты развития событий в виртуальной среде, что особенно полезно в задачах робототехники, автономного вождения и планирования сложных операций.
Генерируя последовательности видео, модели неявно моделируют постоянство объектов и пространственные отношения. Это происходит за счет необходимости последовательно отображать объекты в течение времени, сохраняя их идентичность и положение в трехмерном пространстве. Модели, чтобы создать правдоподобную визуальную последовательность, должны учитывать, что объект, исчезнувший из поля зрения, продолжает существовать и может появиться снова. Следовательно, процесс генерации видео требует от модели понимания и реализации фундаментальных принципов восприятия, связанных с постоянством объектов и их пространственной организацией, даже если эти принципы не заданы явно в процессе обучения.
Мультимодальные большие языковые модели (MLLM), использующие генерацию видео, расширяют существующие лингвистические возможности, интегрируя обработку визуальной информации. Эти модели, обученные на совместном анализе текста и видео, способны не только понимать визуальный контент, но и генерировать описания, отвечать на вопросы, связанные с видео, и выполнять сложные задачи, требующие визуального рассуждения. В отличие от традиционных языковых моделей, оперирующих исключительно текстовыми данными, MLLM используют видеогенерацию как механизм для моделирования и понимания динамических визуальных сцен, что позволяет им осуществлять более точное и контекстуально-обоснованное взаимодействие с визуальным миром. Это достигается за счет способности модели предсказывать и генерировать последовательности кадров, отражающие физические законы и логические связи между объектами.
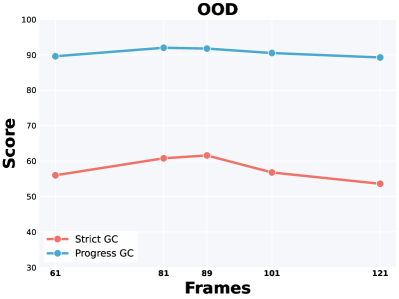
Масштабирование инференса для усиления рассуждений
Исследование демонстрирует наличие закона масштабирования во время тестирования (Test-Time Scaling Law) в визуальных задачах: увеличение количества генерируемых видеокадров непосредственно во время работы модели значительно повышает её эффективность при решении сложных задач последовательного планирования. Этот подход позволяет модели проводить более детальное “проигрывание” сценариев, что особенно важно для задач, требующих предвидения последствий действий и выбора оптимальной стратегии. Фактически, увеличение числа кадров создаёт иллюзию более продолжительной и всесторонней “симуляции”, позволяя алгоритму исследовать более широкий спектр возможных решений и улучшать качество принимаемых решений без необходимости переобучения модели или изменения её архитектуры.
В ходе исследований была продемонстрирована выдающаяся эффективность модели Wan 2.2 TI2V 5B в задачах навигации по лабиринтам. Модель достигла показателя точного соответствия (Exact Match) в 99.98%, что свидетельствует о способности находить оптимальный путь в сложных лабиринтах. Кроме того, был зафиксирован прогресс в 99.98%, подтверждающий устойчивость и надежность решения. Эти результаты подчеркивают потенциал модели в решении задач, требующих планирования и последовательного принятия решений в визуально сложных средах, а также указывают на высокую точность и эффективность алгоритмов, используемых в её архитектуре.
Исследования показывают, что расширение возможностей модели по «симуляции» — то есть увеличению количества генерируемых кадров или вариантов развития событий — позволяет ей значительно расширить область поиска оптимального решения. По сути, это создает больше возможностей для проверки различных стратегий и, как следствие, для более точного и обоснованного принятия решений. Более обширная «симуляция» даёт возможность модели не просто найти выход из сложной ситуации, но и оценить эффективность различных подходов, отсеивая неоптимальные и укрепляя наиболее перспективные, что приводит к повышению общей надежности и точности работы системы в задачах последовательного планирования.
Исследования показали, что масштабирование во время инференса, особенно при работе с визуальными данными, представляет собой экономически эффективный способ повышения интеллекта модели без необходимости её повторного обучения. Этот подход позволяет модели исследовать более широкое пространство решений, используя дополнительные вычислительные ресурсы исключительно на этапе применения, а не на этапе обучения. Вместо дорогостоящей переподготовки, модель может генерировать большее количество визуальных кадров или проводить более глубокий анализ существующих данных, что приводит к значительному улучшению результатов в сложных задачах, требующих последовательного планирования и рассуждений. Таким образом, масштабирование во время инференса открывает возможности для существенного повышения производительности существующих моделей, не требуя значительных инвестиций в новые обучающие данные или вычислительные мощности.
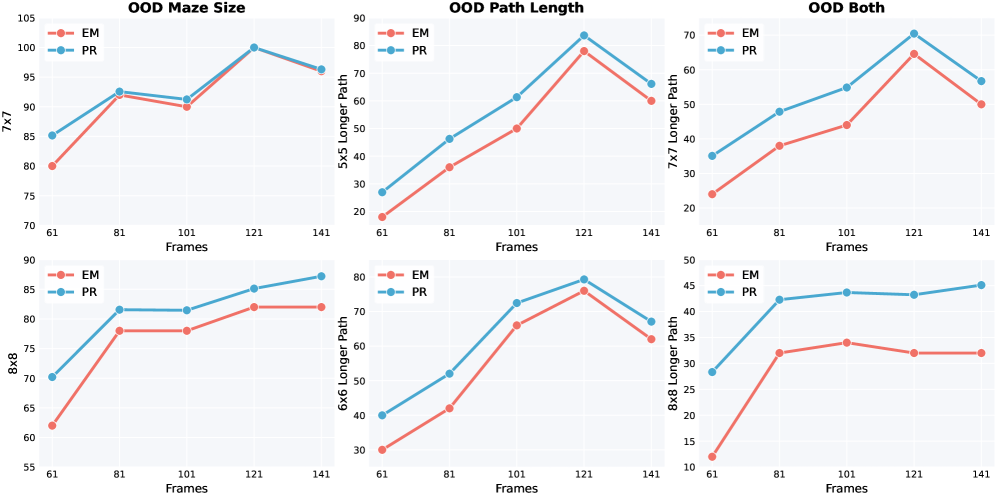
Исследование демонстрирует, что современные модели генерации видео способны эффективно решать задачи визуального мышления, превосходя текстовые подходы в планировании пространственных сценариев. Этот феномен подчеркивает важность контекста и временной последовательности в понимании видео, что соответствует концепции ‘test-time scaling’, где увеличение количества сгенерированных кадров повышает точность. В этом отношении, слова Винтона Серфа актуальны как никогда: «Интернет — это не технология, это способ организации информации». Подобно тому, как интернет структурирует информацию, модели генерации видео структурируют визуальные данные, создавая согласованные и логичные последовательности кадров, необходимые для эффективного визуального рассуждения.
Куда Ведет Время?
Представленная работа демонстрирует, что генеративные модели видео способны выполнять визуальное рассуждение, превосходя текстовые подходы в задачах пространственного планирования. Однако, кажущееся улучшение, связанное с увеличением количества сгенерированных кадров в процессе “test-time scaling”, скорее всего, иллюзия, временное отсрочивание неизбежного. Любое улучшение стареет быстрее, чем ожидалось. Увеличение количества кадров — это не решение проблемы, а лишь временное увеличение вычислительной стоимости поддержания видимости последовательности.
Остается открытым вопрос о природе визуального контекста, который, судя по всему, играет ключевую роль. Что именно определяет “геометрическую согласованность” и насколько она подвержена влиянию энтропии? Развитие моделей в направлении более глубокого понимания причинно-следственных связей в видеоряде представляется более перспективным, чем простое наращивание вычислительных ресурсов. Откат — это путешествие назад по стрелке времени, и игнорировать этот факт — значит обрекать систему на преждевременное устаревание.
В конечном счете, задача состоит не в создании моделей, способных генерировать все более длинные и сложные видео, а в разработке систем, способных адаптироваться к неизбежному разрушению информации, свойственному любой динамической системе. Истинное визуальное рассуждение требует не только понимания того, что видно, но и предвидения того, что будет потеряно.
Оригинал статьи: https://arxiv.org/pdf/2601.21037.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Эффективная настройка больших языковых моделей: совместная оптимизация и адаптация
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
2026-02-08 13:38