Автор: Денис Аветисян
Исследователи предлагают принципиально новый метод анализа видео, основанный на активном поиске релевантной информации, а не на пассивном просмотре всего контента.
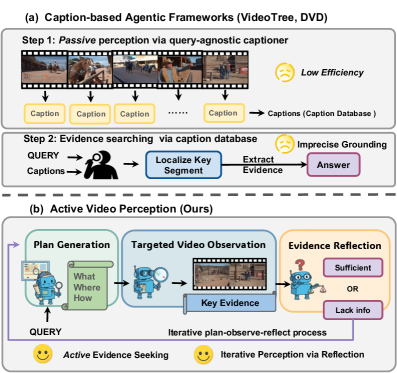
Представлена концепция Active Video Perception (AVP) — агентной системы, использующей итеративное планирование и многомодальные языковые модели для эффективного понимания длинных видео.
Понимание длинных видеозаписей затруднено из-за огромного объема избыточной информации и редких, но ключевых сигналов, необходимых для ответа на конкретные вопросы. В работе под названием ‘Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding’ предлагается новый подход, основанный на активном восприятии, где агент самостоятельно решает, какие фрагменты видео анализировать. Предложенная система AVP (Active Video Perception) значительно повышает точность и эффективность анализа длинных видео, активно планируя процесс наблюдения и извлекая только релевантные данные. Сможет ли подобный подход кардинально изменить способы обработки и понимания видеоинформации в будущем?
Когда Революция Становится Техдолгом: Вызов Длинного Видео
Традиционные методы анализа видео сталкиваются с серьезными трудностями при обработке контента большой продолжительности и сложности. Огромный объем данных, содержащийся в длинных видеороликах, создает узкие места в информационных потоках, препятствуя эффективному извлечению значимых деталей. Попытки последовательного анализа каждого кадра или сегмента требуют колоссальных вычислительных ресурсов и времени, что делает обработку таких видео непрактичной. В результате, важные события, закономерности и контекст могут быть упущены из-за перегрузки системы и невозможности оперативно обработать весь объем информации. Эта проблема особенно актуальна в таких областях, как видеонаблюдение, анализ спортивных трансляций и обработка пользовательского контента, где длинные видеоролики являются нормой.
Традиционные методы анализа видео часто сталкиваются с проблемой вычислительной сложности при обработке длинных видеозаписей. Существующие подходы, как правило, предполагают последовательную обработку каждого кадра или сегмента, что требует значительных вычислительных ресурсов и времени. Эта необходимость в полной обработке ограничивает возможность масштабирования систем анализа видео, особенно при работе с большими объемами данных или в режиме реального времени. В результате, обработка длинных видеозаписей становится дорогостоящей и неэффективной, препятствуя широкому применению технологий видеоаналитики в различных областях, таких как видеонаблюдение, автоматическое редактирование и интеллектуальный поиск.
Для эффективного анализа длинных видеороликов требуется переход к более активным и селективным стратегиям обработки информации. Традиционные методы, обрабатывающие видео целиком, становятся непомерно затратными и неэффективными при работе с продолжительным контентом. Вместо этого, современные исследования направлены на разработку систем, способных выделять наиболее значимые фрагменты, фокусируясь на ключевых событиях и отбрасывая избыточную информацию. Такой подход предполагает использование алгоритмов, имитирующих человеческое внимание, позволяющих динамически отслеживать наиболее релевантные участки видеопотока и концентрировать вычислительные ресурсы именно на них. Это позволяет существенно снизить нагрузку на систему и повысить скорость анализа, открывая новые возможности для понимания сложных повествований и извлечения ценной информации из продолжительных видеозаписей.

Активная Видеоперцепция: Когда Машина Начинает «Смотреть»
Активное восприятие видео (AVP) рассматривает анализ длительных видеозаписей как взаимодействие со средой, аналогичное процессу исследования и обучения, происходящему у автономных агентов в реальном мире. В отличие от пассивного анализа, AVP предполагает активное формирование запросов к видеопотоку для получения релевантной информации. Это достигается путем моделирования видео как интерактивной среды, где агент может целенаправленно выбирать, какие фрагменты видео просматривать, и на основе полученных данных корректировать свою стратегию анализа. Такой подход позволяет существенно сократить объем обрабатываемой информации и повысить эффективность извлечения полезных сведений из длительных видеозаписей.
В основе подхода Active Video Perception (AVP) лежит процесс «Планирование-Наблюдение-Размышление», заимствованный из теории активного восприятия. Этот процесс позволяет агенту целенаправленно собирать доказательства, необходимые для достижения поставленных целей. На этапе планирования агент формирует гипотезы и определяет, какие аспекты видео необходимо изучить. Затем, на этапе наблюдения, агент выборочно анализирует видеопоток, фокусируясь на релевантных фрагментах. Наконец, на этапе размышления, агент интерпретирует собранные данные и корректирует свои планы, обеспечивая эффективное и целенаправленное исследование видеоконтента.
Предлагаемый агентский подход к анализу видео расширяет существующие агентские фреймворки, обеспечивая более эффективный и целенаправленный процесс анализа. В результате проведенных экспериментов, данная система демонстрирует повышение средней точности на 5.7% по сравнению с алгоритмом DeepVideoDiscovery. Это улучшение обусловлено способностью системы активно выбирать наиболее релевантные фрагменты видео для анализа, что снижает вычислительные затраты и повышает точность распознавания событий и объектов.
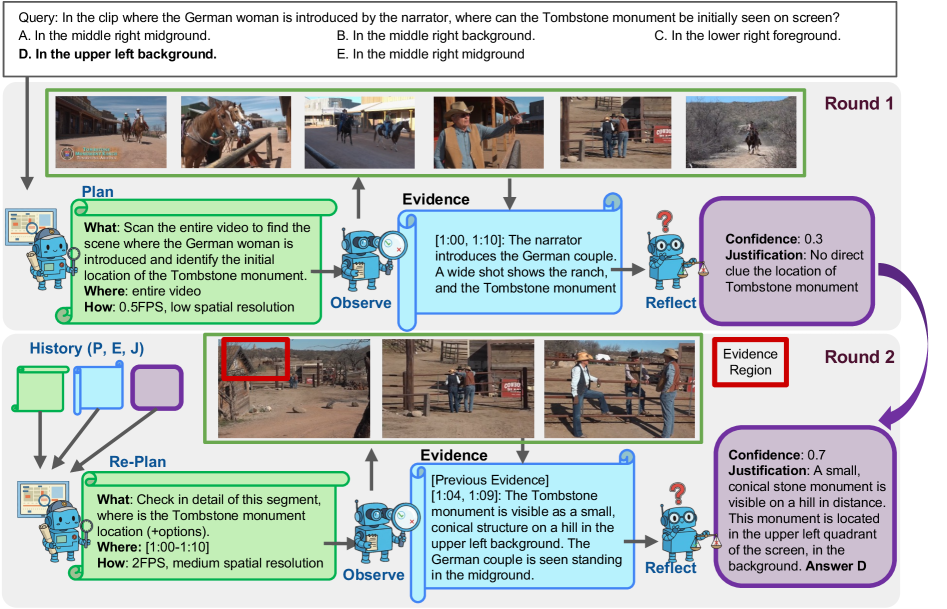
Разбираем Цикл «Планирование-Наблюдение-Оценка»: Как Машина «Думает»
Метод ‘Query-Conditioned Action Planning’ в архитектуре AVP формирует планы наблюдения, исходя из конкретного заданного вопроса. Это означает, что система не производит слепое сканирование видеопотока, а фокусируется на извлечении информации, релевантной для ответа на поставленную задачу. Вместо общего анализа, система динамически определяет, какие действия (например, выбор углов обзора, временных интервалов) необходимо предпринять для сбора данных, непосредственно относящихся к запросу. Такой подход позволяет значительно повысить эффективность процесса наблюдения, исключая обработку избыточной информации и оптимизируя использование вычислительных ресурсов.
Целенаправленное видео-наблюдение извлекает релевантные доказательства, соответствующие поставленному запросу, посредством оптимизации параметров, таких как частота кадров (Frame Rate) и пространственное разрешение (Spatial Resolution). Выбор этих параметров напрямую влияет на эффективность сбора данных: более высокая частота кадров обеспечивает фиксацию быстро меняющихся событий, в то время как увеличение пространственного разрешения позволяет детально рассмотреть объекты и их взаимодействие. Оптимизация этих параметров осуществляется в соответствии с конкретным типом запроса и характеристиками видеопотока, что позволяет минимизировать избыточность данных и повысить точность извлечения необходимой информации.
Этап “Оценка доказательств” анализирует собранные видеоданные для определения, достаточно ли информации для ответа на исходный вопрос. Алгоритм оценивает релевантность и полноту доказательств, принимая решение о необходимости продолжения наблюдения или переходе к следующему этапу обработки. В ходе тестирования было установлено, что применение данного этапа позволило сократить время, необходимое для получения выводов, в 5.44 раза по сравнению с системой DeepVideoDiscovery, что свидетельствует о значительной оптимизации процесса анализа видеоинформации.

AVP в Действии: Тесты и Подтверждение Эффективности
Система AVP продемонстрировала впечатляющие результаты в задачах анализа длинных видео, успешно пройдя тестирование на нескольких авторитетных бенчмарках, включая MINERVA, LongVideoBench, Video-MME, LVBench и MLVU. Достигнутая точность в 92% подтверждает эффективность подхода и открывает новые возможности для автоматизированного понимания видеоконтента. Такие результаты свидетельствуют о значительном прогрессе в области компьютерного зрения и обработки видео, позволяя решать сложные задачи, связанные с анализом больших объемов визуальной информации и извлечением значимых данных.
В основе системы функционирования AVP лежат мощные мультимодальные большие языковые модели, в частности Gemini-2.5-Pro, обеспечивающие ключевые возможности рассуждения и логического вывода. Использование подобных моделей позволяет системе не просто обрабатывать визуальную и звуковую информацию, но и понимать контекст происходящего, выявлять взаимосвязи между событиями и делать обоснованные заключения. Gemini-2.5-Pro служит своеобразным «мозгом» системы, позволяя ей эффективно анализировать длинные видеофрагменты, извлекать релевантную информацию и предоставлять точные ответы на поставленные вопросы. Такой подход значительно повышает эффективность анализа видеоданных и открывает новые возможности для автоматизации задач, требующих понимания сложного визуального контента.
Дальнейшее совершенствование AVP осуществляется посредством фреймворков, таких как DeepVideoDiscovery, что демонстрирует значительный потенциал инструментального поиска для повышения эффективности сбора доказательств при анализе видео. Внедрение данных инструментов не только упрощает процесс извлечения релевантной информации, но и оптимизирует использование ресурсов, снижая объем входных токенов на 12.4% по сравнению с базовым DeepVideoDiscovery. Такое уменьшение нагрузки позволяет обрабатывать более длинные видеоматериалы и повышает общую производительность системы, открывая новые возможности для глубокого анализа визуального контента и извлечения ценных данных.
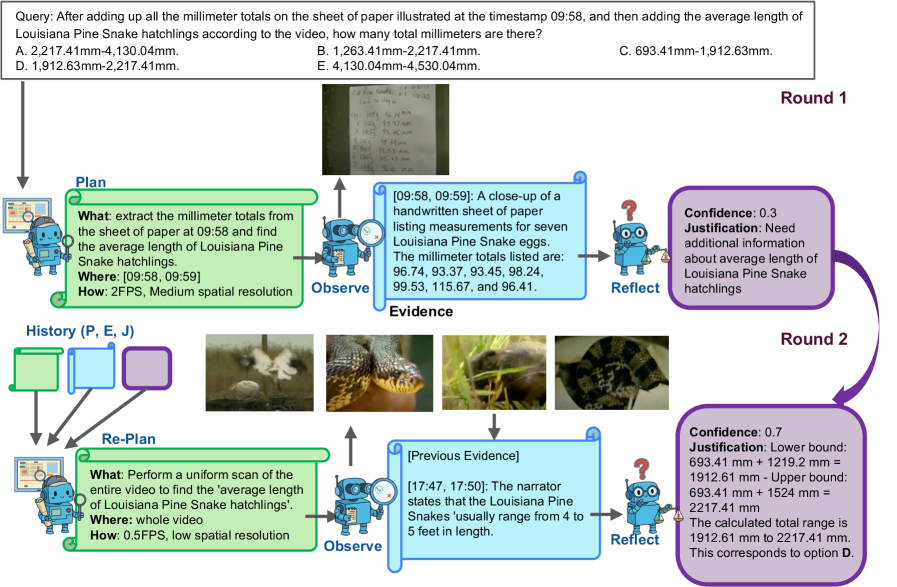
Будущее: К Воплощенному Видеоинтеллекту
Агентный подход, реализованный в AVP, закладывает основу для создания действительно воплощенного видеоинтеллекта, способного взаимодействовать и обучаться в динамичных средах. В отличие от пассивного анализа видеоданных, AVP действует как автономный агент, формируя планы, наблюдая за результатами и рефлексируя над своим опытом. Это позволяет системе не просто понимать происходящее на видео, но и активно влиять на окружающую среду, адаптироваться к изменениям и решать поставленные задачи в режиме реального времени. Такой подход открывает перспективы для создания роботов и виртуальных ассистентов, способных к самостоятельному обучению и адаптации в сложных и непредсказуемых условиях, что существенно расширяет возможности применения видеоаналитики за пределы традиционного наблюдения и обработки информации.
Дальнейшие исследования направлены на оптимизацию цикла «Планирование-Наблюдение-Оценка», являющегося ключевым компонентом системы AVP. Ученые стремятся повысить скорость и эффективность каждого этапа этого цикла, что позволит агенту быстрее адаптироваться к изменяющимся условиям и принимать более обоснованные решения. Параллельно ведется работа по расширению спектра задач, которые может решать AVP, включая более сложные сценарии взаимодействия с окружающей средой и освоение новых видов деятельности. Успешная реализация этих направлений позволит создать более универсальную и интеллектуальную систему, способную к автономному обучению и адаптации в динамичных условиях, открывая новые возможности для применения в различных областях, от робототехники до анализа видеоданных.
Интеграция технологий автоматического создания подписей к видео значительно расширяет возможности понимания длинных видеороликов и делает их более доступными для широкого круга пользователей. Автоматически сгенерированные подписи не только облегчают поиск конкретных моментов в видео, но и позволяют людям с нарушениями слуха или говорящим на других языках получать доступ к визуальному контенту. Более того, подписи, содержащие ключевую информацию о происходящем, могут служить дополнительным источником данных для алгоритмов машинного обучения, улучшая точность и эффективность анализа видео. Перспективные исследования направлены на создание подписей, учитывающих контекст и намерения, что позволит создавать более информативные и полезные описания видеоконтента, делая взаимодействие с ним интуитивно понятным и эффективным.
Изучение принципов активного восприятия видео, как представлено в данной работе, неизбежно наводит на мысль о цикличности технологических инноваций. Система, активно планирующая, что именно наблюдать, а не пассивно переваривающая гигабайты данных, — это, конечно, прогресс. Но это лишь очередная попытка заставить железо думать, а не просто выполнять команды. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы находимся в опасности из-за того, что мы слишком сильно полагаемся на большие данные и слишком мало на модели, которые могут обобщать». Активное планирование наблюдений, в конечном счёте, лишь маскирует тот факт, что даже самые сложные алгоритмы нуждаются в чётких инструкциях. Иначе система стабильно падает — по крайней мере, последовательно.
Что Дальше?
Представленный подход к активному восприятию видео, безусловно, добавляет ещё один слой абстракции между машиной и реальностью. Вместо пассивного поглощения гигабайтов видеоряда, агент теперь «планирует», что смотреть. Это, конечно, элегантно, пока CI не начнёт жаловаться на новые векторы ошибок, возникающие из-за неверных планов. Ведь каждый «умный» планировщик в конечном итоге столкнётся с необходимостью обрабатывать непредсказуемость мира — и тогда всё вернётся к ручному исправлению багов.
Очевидно, что истинный вызов заключается не в создании более сложных алгоритмов планирования, а в построении системы, способной адекватно оценивать стоимость наблюдения. Каждый запрос — это потенциальная дыра в бюджете вычислительных ресурсов. И, вероятно, вся эта «активность» обернётся лишь оптимизацией для конкретных датасетов, разработанных в лабораторных условиях. Документация, как всегда, будет отставать от изменений в коде, и каждый новый исследователь будет вынужден заново изобретать велосипед.
В конечном итоге, вся эта гонка за «интеллектуальным» видеопониманием напоминает строительство Вавилонской башни. Каждый новый уровень абстракции увеличивает хрупкость системы. И, как и в любом другом проекте, рано или поздно придётся столкнуться с необходимостью технического долга, который потребует огромных усилий для погашения.
Оригинал статьи: https://arxiv.org/pdf/2512.05774.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-09 01:28