Автор: Денис Аветисян
Исследование показывает, что эффективное понимание видео можно достичь, отказавшись от длинных цепочек рассуждений в пользу сжатия данных и обучения с подкреплением.
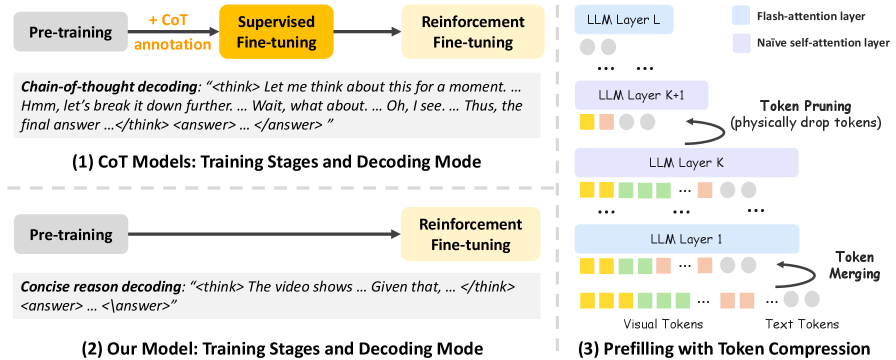
Эффективный вывод для мультимодальных моделей возможен благодаря комбинации сжатия токенов, обучения с подкреплением и лаконичного рассуждения, что позволяет оптимизировать понимание видео.
Несмотря на успехи мультимодальных больших языковых моделей в решении задач видео-рассуждений, существующие подходы зачастую требуют обработки большого объема визуальных данных и построения сложных, развернутых цепочек логических выводов. В статье ‘Rethinking Chain-of-Thought Reasoning for Videos’ предложен новый подход, демонстрирующий, что эффективное видео-рассуждение возможно благодаря сочетанию сжатия визуальных токенов и лаконичных умозаключений. Предложенная схема, основанная на обучении с подкреплением, позволяет достичь конкурентоспособной производительности при значительном снижении вычислительных затрат и без использования ручной разметки. Не является ли краткость действительно сестрой таланта, когда речь идет о понимании видеоконтента машинами?
За гранью логики: узкое место рассуждений в больших моделях
Трансформерные модели, несмотря на впечатляющие успехи в различных задачах обработки естественного языка, сталкиваются с существенными трудностями при решении сложных задач, требующих логических умозаключений. Ограничения связаны, прежде всего, с вычислительными затратами, которые экспоненциально возрастают с увеличением длины последовательности и сложности рассуждений. Масштабирование моделей для обработки более объемных и детализированных задач приводит к резкому увеличению потребления памяти и времени вычислений, что делает их применение в реальном времени проблематичным. Несмотря на архитектурные усовершенствования, фундаментальные ограничения в способности эффективно обрабатывать большие объемы информации и поддерживать контекст в течение длительных цепочек рассуждений остаются серьезным препятствием для достижения полноценного искусственного интеллекта.
Несмотря на доказанную эффективность метода “Цепочка рассуждений” (Chain-of-Thought Reasoning) в решении сложных задач, его применение сопряжено со значительными вычислительными издержками. Каждая итерация рассуждений требует последовательной обработки информации, что приводит к увеличению времени ответа и существенному росту потребляемых ресурсов. Этот “инференсный оверхед” особенно критичен для приложений, требующих работы в режиме реального времени, таких как чат-боты или системы быстрого анализа данных. В результате, несмотря на способность модели генерировать логически обоснованные ответы, практическое применение метода в ситуациях, где важна скорость реакции, оказывается затруднительным и требует поиска более эффективных альтернатив для снижения вычислительной нагрузки.
Современные методы искусственного интеллекта, несмотря на впечатляющие успехи в обработке естественного языка, сталкиваются с трудностями при построении длинных цепочек рассуждений. Основная проблема заключается в неэффективной обработке информации и поддержании контекста на протяжении всего процесса. По мере увеличения длины цепочки, модели теряют способность связывать между собой отдельные шаги, что приводит к ошибкам и нелогичным выводам. Эта сложность обусловлена экспоненциальным ростом вычислительных затрат и необходимостью хранения большого объема информации о предыдущих шагах рассуждений. В результате, даже относительно простые задачи, требующие последовательного анализа и сопоставления данных, могут оказаться непосильными для существующих систем, что ограничивает их применение в областях, где важна надежность и точность выводов.
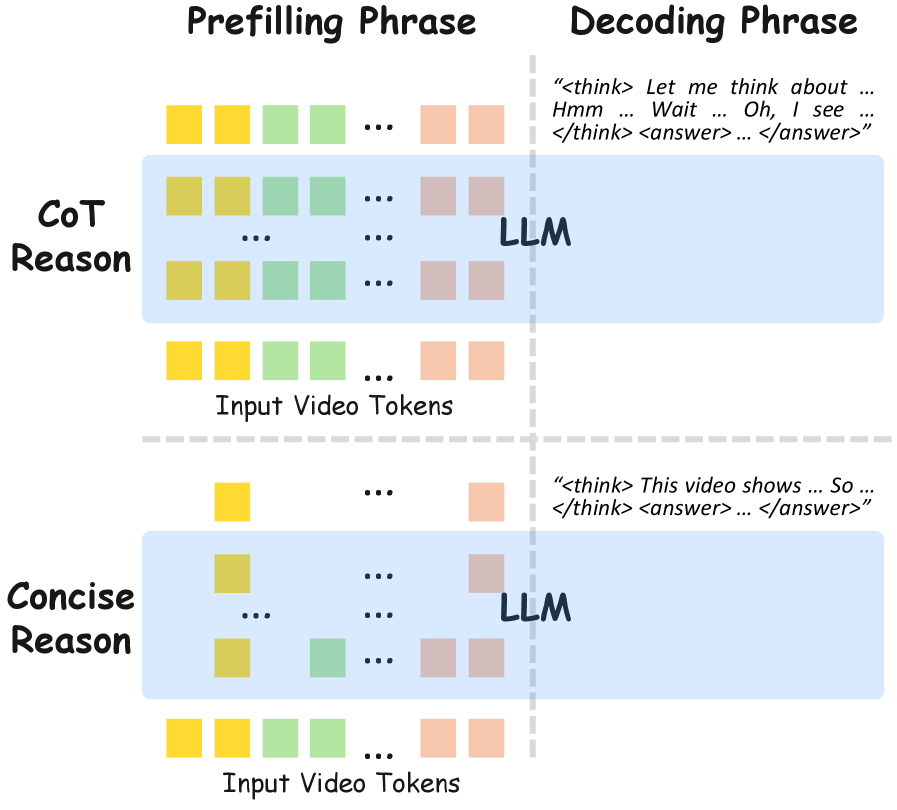
Лаконичность как ключ: более эффективный подход к рассуждениям
В отличие от метода “Цепочки рассуждений” (Chain-of-Thought), требующего развернутых последовательностей, метод “Краткого рассуждения” (Concise Reasoning) генерирует более лаконичные и сфокусированные цепочки логических шагов. Это достигается за счет отсечения избыточной информации и концентрации на ключевых этапах решения задачи. Сокращение длины цепочки рассуждений напрямую влияет на снижение вычислительных затрат, поскольку уменьшается количество операций, необходимых для генерации ответа, что делает данный подход более эффективным для ресурсоограниченных сред и задач, требующих высокой скорости обработки.
Подход Concise Reasoning использует возможности предварительно обученных моделей, избегая необходимости их масштабной переподготовки. Вместо этого, он адаптирует существующие знания, оптимизируя процесс рассуждений для повышения эффективности. Это достигается за счет фокусировки на ключевых этапах логической цепочки и минимизации избыточных вычислений, что позволяет снизить вычислительные затраты без значительной потери в качестве решения задач. Таким образом, Concise Reasoning предоставляет возможность применения мощных языковых моделей в условиях ограниченных ресурсов и повышенных требований к скорости обработки данных.
Метод Concise Reasoning стремится к достижению сопоставимой производительности с Chain-of-Thought, но с существенным снижением вычислительных затрат. Это достигается за счет приоритизации только ключевых этапов логического вывода, исключая из рассмотрения избыточные или нерелевантные шаги. Вместо генерации длинных последовательностей рассуждений, как в Chain-of-Thought, Concise Reasoning фокусируется на минимальном наборе необходимых действий для получения ответа, что позволяет снизить требования к вычислительным ресурсам и времени обработки без значительной потери в точности. Такой подход особенно актуален для задач, требующих высокой скорости обработки и ограниченных вычислительных мощностей.

Обучение с подкреплением: мультимодальное рассуждение и его тонкости
Перенос методов краткого рассуждения на мультимодальные контексты, в частности, на Видео Мультимодальные Большие Языковые Модели (Video Multimodal Large Language Models), требует применения надежных техник обучения, таких как обучение с подкреплением (Reinforcement Learning). Традиционные методы обучения, оптимизированные для текстовых данных, часто оказываются недостаточно эффективными при обработке и интеграции информации из различных модальностей, включая видео и текст. Обучение с подкреплением позволяет модели активно взаимодействовать с окружающей средой, получать обратную связь в виде наград и корректировать свои действия для достижения оптимальной стратегии рассуждения в мультимодальном пространстве. Это особенно важно для задач, требующих понимания временных зависимостей и визуального контекста, что делает обучение с подкреплением ключевым компонентом современных мультимодальных систем.
Для тонкой настройки моделей, используемых в задачах мультимодального рассуждения, применяется алгоритм Group Relative Policy Optimization (GRPO). В процессе обучения GRPO использует сигналы вознаграждения для направления процесса рассуждения. В частности, используется Reward за точность (Accuracy Reward), который оценивает правильность ответа, и Reward за формат (Format Reward), который контролирует соответствие ответа заданному формату. Комбинация этих сигналов позволяет модели оптимизировать не только правильность, но и структуру генерируемых ответов, что критически важно для сложных мультимодальных задач.
В процессе обучения моделей, использующих обучение с подкреплением для мультимодального рассуждения, расхождение Кульбака-Лейблера ($KL$-дивергенция) применяется как регуляризующий член. Это позволяет стабилизировать процесс обучения и предотвратить катастрофическое забывание ранее усвоенных знаний. В частности, $KL$-дивергенция измеряет разницу между распределением вероятностей, предсказываемым моделью, и исходным распределением, что способствует сохранению важных характеристик и предотвращению чрезмерной адаптации к новым данным. Использование $KL$-дивергенции в качестве штрафа в функции потерь ограничивает отклонение параметров модели от начальных значений, обеспечивая более устойчивое и предсказуемое поведение.
Предложенная схема обучения демонстрирует передовые результаты в задачах мультимодального рассуждения. Экспериментальные данные показывают улучшение точности на $5.7\%$ в бенчмарке VideoMME и на $8.1\%$ в бенчмарке MLVU по сравнению с моделью Video-R1. Данные улучшения подтверждают эффективность предложенного подхода к обучению мультимодальных больших языковых моделей с использованием методов обучения с подкреплением.
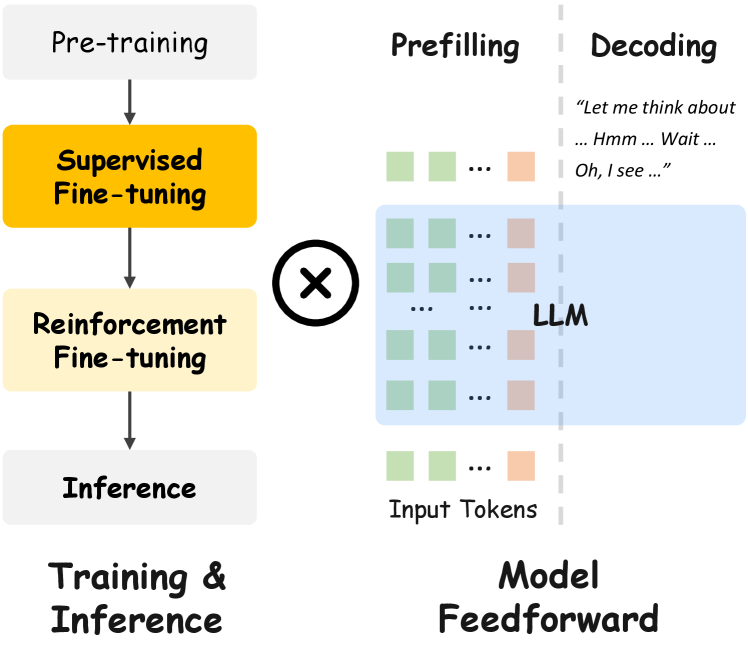
Оптимизация эффективности: сжатие токенов и горизонты возможностей
Для успешного внедрения видео-мультимодальных больших языковых моделей (VLLM) в практические приложения, критически важным является снижение вычислительных затрат, связанных с обучением и использованием этих моделей. Огромный объем данных и сложность архитектур VLLM приводят к значительному увеличению времени обучения и потребляемым ресурсам при выводе. Поэтому, оптимизация как затрат на обучение, так и на инференс, является ключевым фактором для расширения области применения VLLM, позволяя обрабатывать более длинные видео, увеличивать скорость обработки и снижать общую стоимость развертывания. Эффективные стратегии оптимизации открывают возможности для анализа больших объемов видеоданных в реальном времени и реализации сложных мультимодальных задач, которые ранее были недоступны из-за вычислительных ограничений.
Техники сжатия токенов, особенно применительно к визуальным токенам, демонстрируют значительное снижение вычислительных затрат без потери производительности. Суть подхода заключается в эффективном представлении визуальной информации, позволяющем уменьшить объем данных, обрабатываемых моделью, без ущерба для качества распознавания и понимания. Вместо обработки каждого пикселя или детали изображения, алгоритмы сжатия выделяют наиболее значимые признаки и кодируют их в более компактном формате. Это приводит к ускорению процессов обучения и инференса, а также снижает требования к объему памяти и вычислительной мощности оборудования. В результате, становится возможным развертывание мультимодальных моделей, работающих с видео, на менее ресурсоемких платформах, открывая путь к более широкому спектру приложений, требующих эффективной обработки визуальной информации.
Успешное внедрение стратегий оптимизации открывает перспективы для анализа длинных видеороликов и расширяет возможности мультимодального рассуждения в различных областях. Повышенная эффективность обработки видеоданных позволяет моделям понимать и интерпретировать сложные визуальные повествования, что особенно важно для приложений, требующих глубокого контекстного анализа, таких как автоматическое создание резюме видео, интеллектуальный видеопоиск и расширенное взаимодействие с видеоконтентом. Возможность эффективной обработки больших объемов видеоинформации снимает ограничения, связанные с вычислительными ресурсами, и делает передовые мультимодальные модели доступными для более широкого круга задач и пользователей, способствуя развитию новых инновационных приложений, использующих возможности анализа видео и текста.
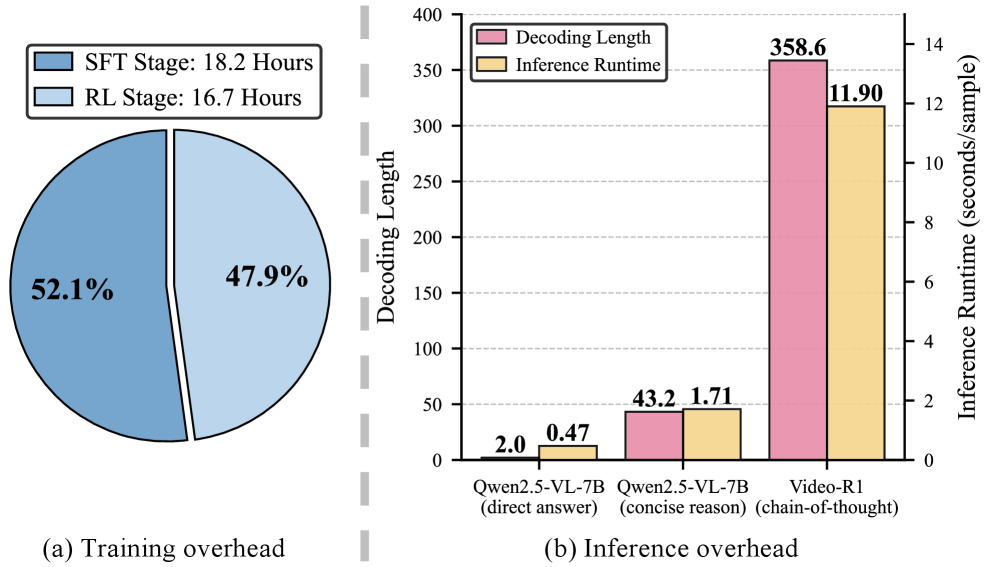
Внедрение компрессии токенов непосредственно в процесс обучения модели демонстрирует существенное повышение ее эффективности. Исследования показывают, что подобный подход позволяет добиться прироста точности на $1.1\%$ в задаче VideoMME и на $4.1\%$ в задаче MLVU. Данный результат свидетельствует о том, что оптимизация представления данных на ранних этапах обучения способствует более эффективному извлечению признаков и улучшению обобщающей способности модели, что, в свою очередь, положительно сказывается на ее производительности в различных мультимодальных задачах.
Разработанный подход позволяет существенно снизить затраты на обучение видео-мультимодальных больших языковых моделей за счет отказа от этапа контролируемой тонкой настройки (Supervised Fine-Tuning, SFT) с использованием дорогостоящих аннотаций Chain-of-Thought (CoT). Традиционно, SFT требует значительных ресурсов для ручной разметки данных, что ограничивает масштабируемость и доступность подобных моделей. Предложенная методика, за счет оптимизации процесса обучения и эффективного использования токенов, позволяет достичь сопоставимых, а в некоторых случаях и превосходящих результатов, без необходимости в трудоемкой и дорогостоящей разметке. Это открывает возможности для более широкого внедрения и применения видео-мультимодальных моделей в различных областях, требующих эффективного анализа и понимания видеоконтента.
Исследование, представленное в статье, подтверждает давнюю истину: элегантность решения часто кроется в простоте. Авторы демонстрируют, что для эффективного понимания видео не всегда необходимы сложные цепочки рассуждений и огромные наборы визуальных токенов. Этот подход к сжатию информации и обучению с подкреплением позволяет добиться значительных результатов, избегая излишней сложности. Как заметил Джеффри Хинтон: «Я считаю, что самый большой прогресс в машинном обучении будет достигнут, когда мы научимся строить действительно простые модели». Иными словами, погоня за длиной рассуждений часто оказывается тупиковой, когда можно добиться аналогичных результатов, используя более лаконичные методы. В конечном итоге, практика, как всегда, вносит коррективы в теорию, и «дорогие способы всё усложнить» уступают место эффективным решениям.
Что дальше?
Представленная работа, безусловно, демонстрирует, что сжатие рассуждений и обучение с подкреплением могут снизить аппетит к бесконечно растущим последовательностям токенов. Однако, стоит помнить, что каждая элегантная схема оптимизации рано или поздно сталкивается с суровой реальностью: требования к вычислительным ресурсам всегда найдут способ вырасти. Попытки заменить «длинные» цепочки рассуждений на «краткие» выглядят как возвращение к старым идеям, только с новым лейблом. Вопрос не в длине цепочки, а в её содержании, и пока искусственный интеллект не научится действительно понимать видео, все эти ухищрения — лишь временное облегчение симптомов.
Очевидным направлением дальнейших исследований представляется не столько поиск более эффективных алгоритмов сжатия, сколько разработка методов верификации рассуждений. Если тесты показывают зелёный свет, это не значит, что система действительно рассуждает, а лишь указывает на то, что тестовые данные недостаточно разнообразны. Пока не будет надёжного способа убедиться в корректности логических выводов, все разговоры о масштабируемости и эффективности — лишь самообман.
Вполне вероятно, что через несколько лет все эти «инновационные» подходы будут рассматриваться как очередной этап в бесконечной гонке за вычислительными ресурсами. Удивительно, как быстро «революционные» технологии превращаются в технический долг. И, вероятно, кто-то снова изобретёт «цепь рассуждений», но уже под другим названием.
Оригинал статьи: https://arxiv.org/pdf/2512.09616.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-12-11 20:38