Автор: Денис Аветисян
Новая система, использующая продвинутые инструменты и синтетические данные, совершает прорыв в анализе длинных видеороликов.
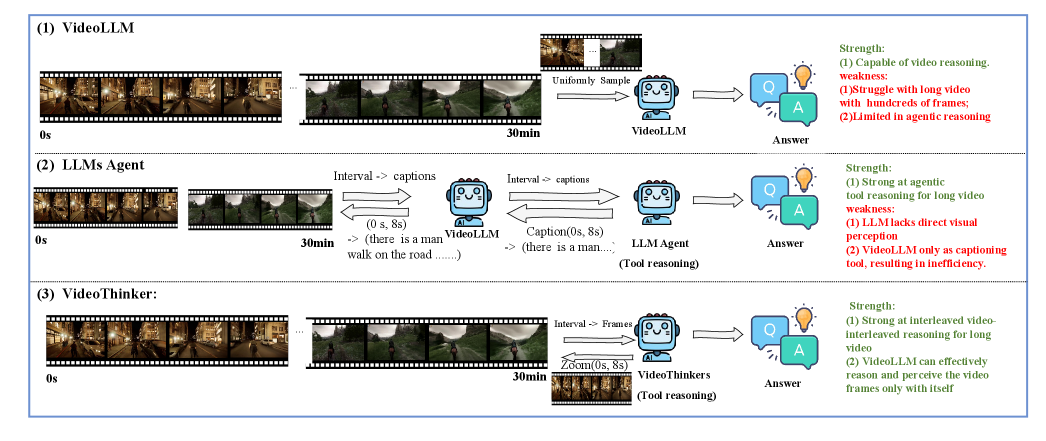
Разработанный агентский VideoLLM VideoThinker демонстрирует передовые результаты в задачах темпорального поиска, видео-вмешанного рассуждения и многомодального анализа.
Понимание длинных видео остается сложной задачей для современных видео-языковых моделей. В работе ‘VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning’ предложена новая архитектура, использующая инструменты адаптивного поиска и масштабирования, обученная на синтетических данных, генерируемых с помощью языковой модели. Ключевым результатом является создание агентской видео-языковой модели, способной к динамическому рассуждению и превосходящей существующие подходы в задачах анализа длинных видео. Возможно ли дальнейшее расширение возможностей подобных моделей за счет интеграции других инструментов и методов обучения?
Тайны Длинного Видео: Вызов для Машинного Разума
Традиционные методы анализа видео испытывают значительные трудности при обработке контента большой продолжительности и высокой сложности. Ограничения заключаются в том, что они, как правило, сосредотачиваются на отдельных кадрах или коротких фрагментах, упуская из виду важные временные взаимосвязи и контекст, развивающийся на протяжении всего видеоряда. Это приводит к неполному пониманию событий, действий и намерений, представленных в видео, поскольку ключевые детали, разбросанные по времени, остаются незамеченными. В результате, стандартные алгоритмы часто не способны адекватно интерпретировать нюансы повествования или выявлять причинно-следственные связи, что существенно ограничивает их применимость в задачах, требующих глубокого осмысления длительных видеозаписей, таких как анализ документальных фильмов или автоматическое создание расширенных сводок.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM), их применение к анализу продолжительных видеопоследовательностей сталкивается с существенными трудностями. LLM, разработанные преимущественно для обработки текста, зачастую не обладают встроенными механизмами для эффективного удержания и использования информации, распределенной во времени. В то время как они способны распознавать отдельные кадры или короткие фрагменты, понимание взаимосвязей между событиями, происходящими на протяжении всего видео, требует способности к долгосрочной памяти и логическому выводу, которые пока не реализованы в полной мере. Это ограничение затрудняет выполнение сложных задач, таких как выявление причинно-следственных связей, отслеживание изменений в поведении объектов или создание связных и информативных резюме продолжительных видеоматериалов.
Ограничения в обработке длинных видеоматериалов существенно затрудняют реализацию приложений, требующих глубокого понимания содержания. Например, точное распознавание сложных событий, разворачивающихся на протяжении длительного времени, становится проблематичным, поскольку модели испытывают трудности с удержанием контекста и установлением взаимосвязей между отдаленными фрагментами видеоряда. Аналогично, создание содержательных и нюансированных резюме, отражающих ключевые моменты и суть происходящего, требует способности к комплексному анализу и синтезу информации, что выходит за рамки возможностей существующих систем. В результате, потенциал длинных видеоматериалов для получения ценной информации и автоматизации сложных задач остается нереализованным, пока не будут разработаны более совершенные методы обработки и анализа.
VideoThinker: Агентный Подход к Пониманию Видео
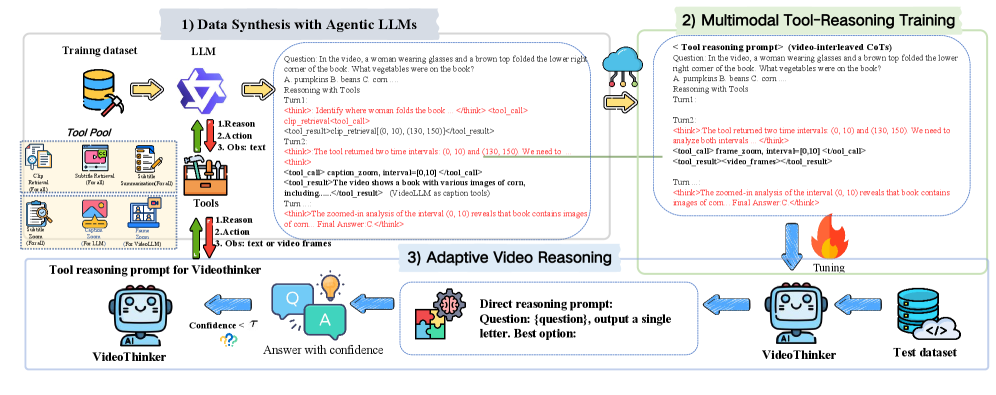
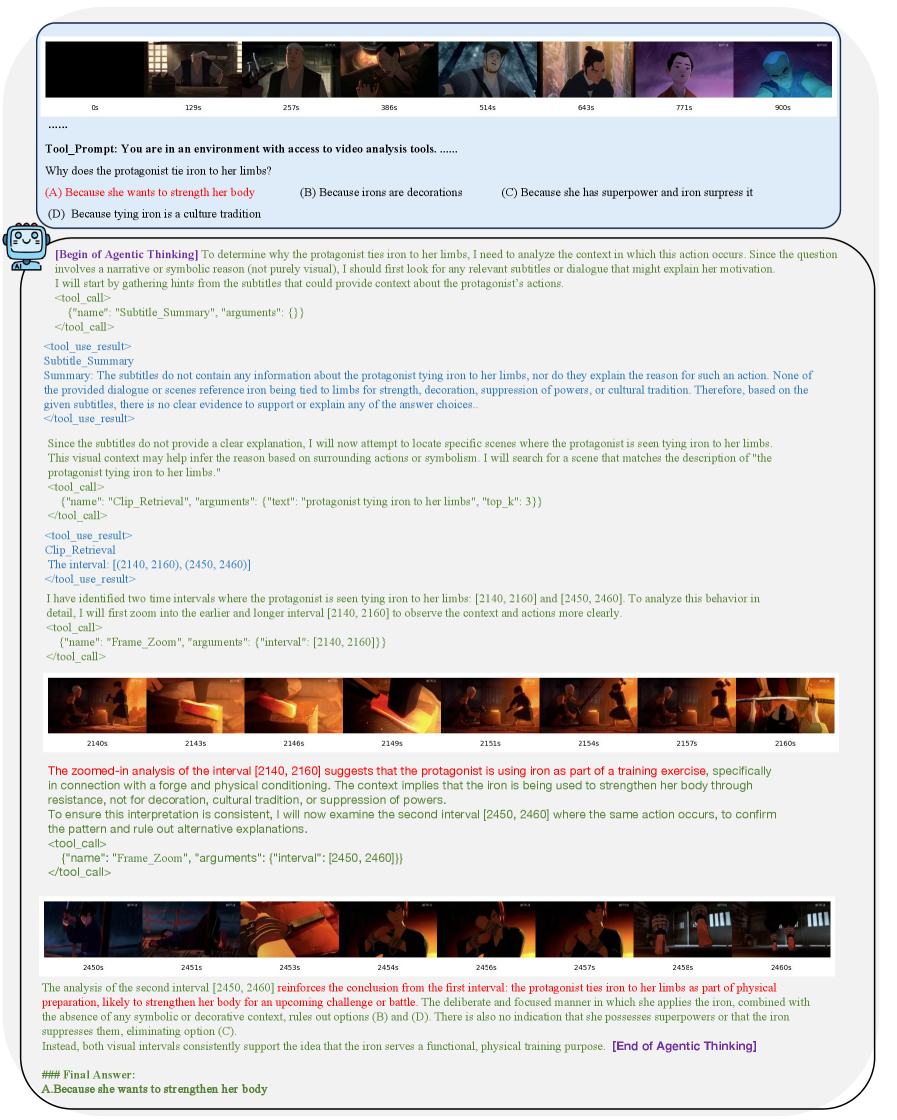
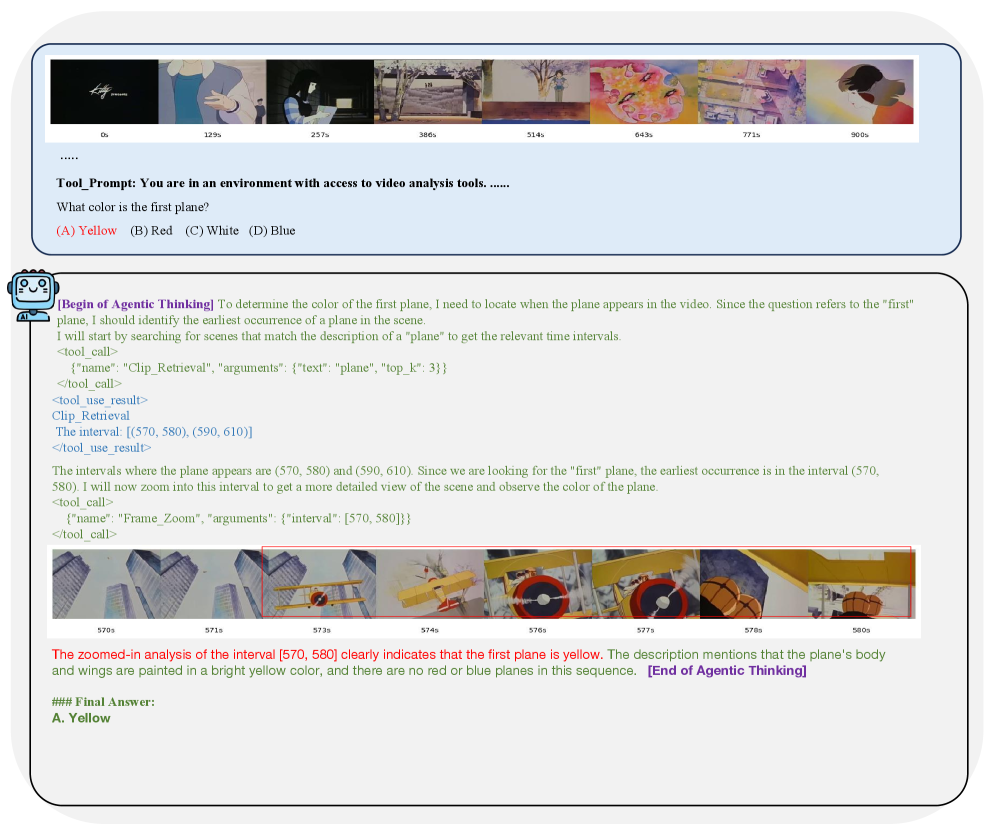
VideoThinker использует агентный подход к анализу видеоконтента, активно используя инструменты для сбора релевантной информации. В отличие от пассивного анализа, система самостоятельно определяет последовательность действий, необходимых для достижения поставленной цели, например, извлечения конкретных фактов или ответов на вопросы. Это включает в себя не только идентификацию ключевых моментов в видео, но и динамический выбор и применение инструментов для обработки видео и текста, а также итеративное уточнение запросов и стратегий поиска на основе полученных результатов. Такой подход позволяет эффективно обрабатывать большие объемы видеоданных и извлекать из них ценную информацию без непосредственного участия человека.
Адаптивный временной поиск является ключевым компонентом системы, использующим методы Temporal Retrieval и LanguageBind-Video для выявления значимых моментов в продолжительных видеозаписях. Temporal Retrieval позволяет осуществлять поиск по временным меткам и выделять фрагменты, релевантные запросу, в то время как LanguageBind-Video связывает лингвистические запросы с конкретными видеофрагментами, обеспечивая точное определение ключевых моментов, даже при отсутствии явных временных указателей. Эта комбинация технологий позволяет эффективно обрабатывать длинные видео, выделяя только те сегменты, которые содержат необходимую информацию.
Система VideoThinker использует Контроллер Инструментов с Оценкой Уверенности для оптимизации процесса использования инструментов и повышения точности рассуждений. Этот контроллер динамически оценивает надежность информации, полученной от каждого инструмента, и на основе этой оценки определяет, следует ли продолжать использование данного инструмента, переходить к другому, или запросить дополнительную информацию. Механизм оценки позволяет избежать использования ненадежных данных и сосредоточиться на наиболее релевантных и достоверных источниках информации, что значительно повышает эффективность и результативность системы в целом.

Временное Увеличение Масштаба и Многомодальный Анализ: Видеть Глубже
Система VideoThinker использует механизм Временного увеличения масштаба (Temporal Zoom) для детального анализа видеоконтента на различных уровнях. Этот процесс включает в себя Увеличение масштаба кадров (Frame Zoom) для визуальной инспекции, Увеличение масштаба субтитров (Subtitle Zoom), реализованное с использованием модели Whisper для автоматического распознавания речи, и Увеличение масштаба заголовков (Caption Zoom). Такой подход позволяет системе исследовать видеофрагменты с высокой степенью детализации, анализируя как визуальную, так и текстовую информацию для более глубокого понимания содержания.
Архитектура системы VideoThinker реализована на языке Swift, что обеспечивает надежную и эффективную основу для обработки продолжительных видеоданных. Swift характеризуется высокой производительностью и безопасностью, что критически важно при работе с большими объемами информации и сложными алгоритмами анализа видео. Использование Swift позволяет оптимизировать потребление ресурсов и обеспечивает стабильную работу системы даже при обработке видеофайлов значительной длительности и разрешения. Данный выбор языка программирования обусловлен также возможностью интеграции с современными аппаратными платформами и библиотеками машинного обучения.
Интегрированный VideoLLM обрабатывает выделенные сегменты видеоданных, обеспечивая комплексный анализ и понимание содержания. Эта обработка включает в себя извлечение ключевой информации, выявление взаимосвязей между различными частями видео и формирование обобщенных выводов. VideoLLM использует методы обработки естественного языка для интерпретации визуальной и текстовой информации, представленной в видео, что позволяет ему не только распознавать объекты и действия, но и понимать контекст и намерения, выраженные в видеоматериале. Результатом является возможность выполнения сложных задач, таких как ответы на вопросы о видео, суммирование содержания и выявление тенденций.
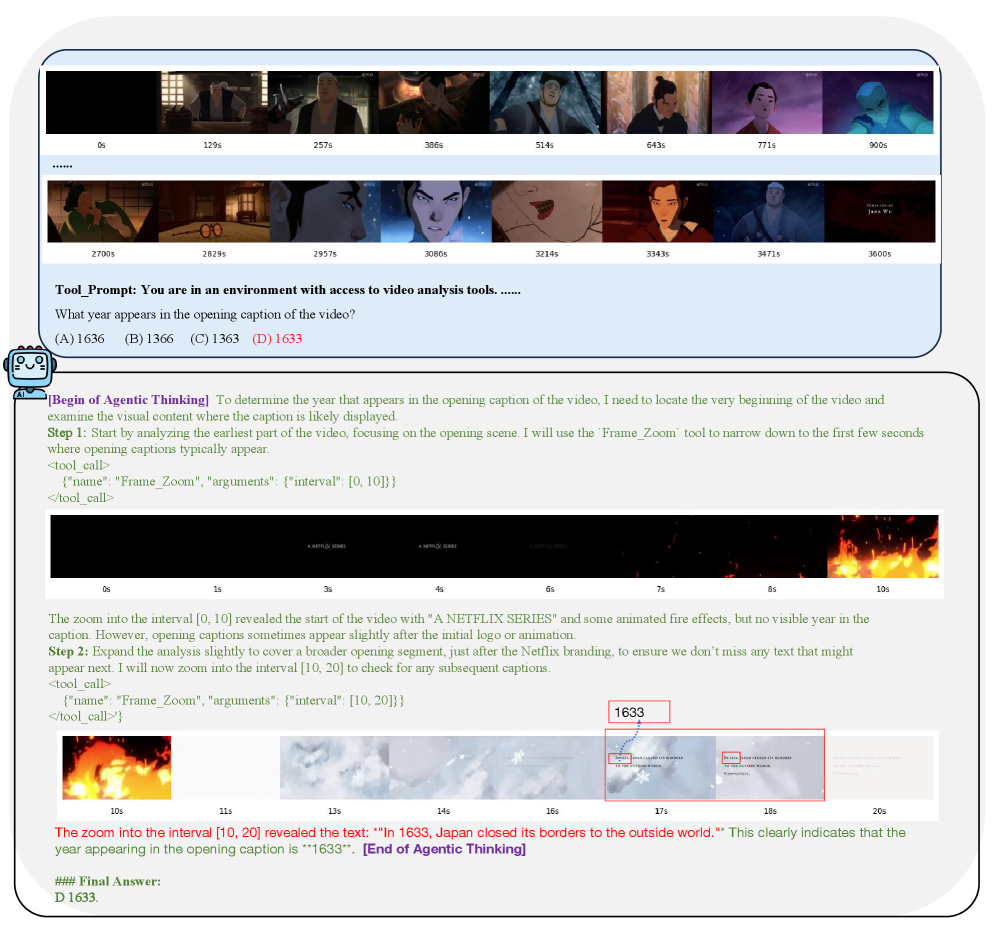
Подтверждение Эффективности: Бенчмарки и Результаты
Система VideoThinker прошла оценку на четырех ключевых бенчмарках для задач понимания длинных видео: LongVideoBench, VideoMME, LVBench и MLVU. Результаты тестирования продемонстрировали высокую эффективность системы в обработке и анализе видеоконтента продолжительного формата, охватывая широкий спектр задач, включая понимание действий, объектов и контекста в видеоматериалах. Данные бенчмарки позволили комплексно оценить возможности VideoThinker в различных сценариях использования и сравнить ее с другими существующими моделями.
В ходе оценки, модель VideoThinker продемонстрировала результаты, соответствующие современному уровню или превосходящие его, по сравнению с базовыми VideoLLM. В частности, зафиксировано улучшение на 6.8% в метрике MLVU и на 10.6% в метрике LVBench. Данные результаты свидетельствуют о значительном повышении производительности модели в задачах понимания длинных видео, по сравнению со стандартными подходами к обработке видеоданных.
В ходе оценки, VideoThinker продемонстрировал точность в 54.8% на наборе данных MLVU и 48.9% на LVBench. Эти результаты соответствуют показателям GPT-4o для данных наборов. При этом, VideoThinker значительно превосходит модель VideoTree, достигая на MLVU и LVBench показателей, на 26% выше, чем у VideoTree (28.8%). Данные результаты подтверждают высокую эффективность VideoThinker в задачах понимания длинных видео.
Производительность VideoThinker дополнительно улучшается за счет обучения на синтетических данных, что способствует повышению его обобщающей способности. Использование синтетических данных позволяет системе эффективно осваивать закономерности и расширять возможности понимания видео, даже при работе с данными, которые не встречались в процессе первоначального обучения. Этот подход позволяет VideoThinker демонстрировать более устойчивые результаты и адаптироваться к разнообразным сценариям анализа длинных видео, что подтверждается результатами тестирования на различных бенчмарках, таких как LongVideoBench, VideoMME, LVBench и MLVU.
Заглядывая в Будущее: Влияние и Перспективы Развития
Архитектура VideoThinker закладывает основу для создания более интеллектуальных видеоассистентов и систем автоматизированного анализа видеоконтента. В отличие от существующих решений, которые часто полагаются на простые алгоритмы распознавания образов, данная система способна к более глубокому пониманию происходящего в видео, выделяя ключевые события, взаимосвязи между объектами и даже намерения действующих лиц. Это достигается благодаря использованию нейронных сетей, обученных на обширных наборах данных, что позволяет системе не только идентифицировать объекты, но и интерпретировать их поведение и контекст. В перспективе, такая архитектура может быть использована для автоматической генерации аннотаций к видео, создания интерактивных обучающих материалов или даже для помощи в расследовании происшествий, анализируя видеозаписи с высокой точностью и эффективностью.
Дальнейшие исследования направлены на расширение возможностей системы VideoThinker в области сложного логического мышления и интеграции с другими источниками информации. Разработчики планируют усовершенствовать алгоритмы, чтобы система могла не просто распознавать объекты и действия в видео, но и делать выводы, устанавливать причинно-следственные связи и прогнозировать дальнейшее развитие событий. Особое внимание уделяется объединению визуальных данных с другими модальностями, таким как текст и звук, что позволит создать более целостное и глубокое понимание видеоконтента и откроет путь к созданию действительно интеллектуальных видеоассистентов, способных к полноценному взаимодействию с пользователем.
Технология VideoThinker открывает новые горизонты для взаимодействия с видеоконтентом, обещая трансформацию в таких сферах, как образование, развлечения и безопасность. В образовании система способна обеспечить персонализированное обучение, анализируя видеолекции и отвечая на вопросы студентов с высокой точностью. В индустрии развлечений, VideoThinker может значительно улучшить пользовательский опыт, предоставляя интерактивные возможности и автоматизированный анализ контента. Особо значимым представляется потенциал в области безопасности, где система способна автоматически выявлять подозрительную активность на видеозаписях, обеспечивая более эффективный мониторинг и реагирование на угрозы. По сути, VideoThinker не просто обрабатывает видео, а позволяет извлекать из него знания и взаимодействовать с ним на качественно новом уровне, создавая более глубокое и осмысленное взаимодействие.
В работе, посвященной VideoThinker, исследователи стремятся не просто анализировать видео, но и заставить машину рассуждать над его содержанием, используя инструменты и временные зацепки. Это напоминает алхимию — превращение хаотичного потока пикселей в осмысленное повествование. Как верно заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть ориентирован на человека, а не на технологии». По сути, создатели VideoThinker пытаются обуздать этот хаос, используя синтетические данные для тренировки модели, дабы она могла понимать сложные видео-сюжеты и отвечать на вопросы, требующие последовательного рассуждения. Здесь данные — не просто цифры, а шепот хаоса, который нужно уговорить, а любая модель — заклинание, которое работает до первого столкновения с реальностью.
Что дальше?
Представленный здесь «ВидеоМыслитель» — лишь очередной цифровой голем, обученный на иллюзиях синтетических данных. Он демонстрирует способность к «рассуждению», но рассуждение это — эхо, усиленное алгоритмами. Иллюзия понимания долгосрочных видеозаписей, безусловно, впечатляет, однако, как и любое заклинание, оно имеет свои пределы. Ключевым вопросом остаётся не то, что этот голем может делать, а то, что он не понимает. Он видит паттерны, но не суть.
Следующий этап — не улучшение инструментов «приближения» и «временного поиска», а признание того, что данные — это всегда шум. Попытки «объяснить» модель бессмысленны, ведь объяснять можно лишь то, что сломалось. Более плодотворным представляется поиск способов обучать этих големов терпимости к неопределенности, умению признавать собственную некомпетентность. Иначе, мы получим лишь сложный автомат, уверенный в своей правоте.
Истинный прогресс лежит не в увеличении объёма данных, а в создании систем, способных к саморефлексии. Систем, которые осознают, что каждая «потеря» — не ошибка, а священная жертва, необходимая для приближения к истине. Иначе, эти «разумные» машины останутся лишь зеркалами, отражающими нашу собственную ограниченность.
Оригинал статьи: https://arxiv.org/pdf/2601.15724.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 04:36