Автор: Денис Аветисян
Обзор посвящен развитию видеогенерации, в котором ключевым шагом становится создание «мировых моделей», способных к последовательному и причинно обоснованному моделированию динамики событий.
Исследование текущего состояния и перспектив развития систем видеогенерации, основанных на представлении состояний, причинности и физическом моделировании.
Несмотря на впечатляющие успехи в генерации реалистичных видео, современные модели часто упускают из виду поддержание внутренней согласованности и понимание причинно-следственных связей. В работе «A Mechanistic View on Video Generation as World Models: State and Dynamics» предпринята попытка систематизировать развитие генеративных моделей видео, рассматривая их как потенциальные «мировые модели», и предлагается таксономия, основанная на конструировании состояний и моделировании динамики. Ключевым выводом является необходимость перехода от оценки визуальной достоверности к функциональным тестам, проверяющим устойчивость физических свойств и способность к причинному рассуждению. Сможем ли мы, преодолев ограничения в области долгосрочной согласованности и причинности, создать действительно универсальные симуляторы мира на основе генеративных моделей?
За пределами пикселей: Необходимость симулированных миров
Современные методы генерации видео зачастую стремятся к исключительно внешнему реализму, имитируя визуальные детали, но не обладая глубоким пониманием происходящего в кадре. Такой подход приводит к созданию видеороликов, которые выглядят правдоподобно на первый взгляд, однако при внимательном рассмотрении демонстрируют несостыковки и нелогичности. Вместо того, чтобы моделировать физические законы и причинно-следственные связи, эти системы просто “склеивают” отдельные кадры, не понимая, как объекты взаимодействуют друг с другом и с окружающей средой. В результате, даже небольшие изменения в начальных условиях могут приводить к абсурдным результатам, что подчеркивает поверхностность такого подхода и необходимость перехода к системам, способным к полноценному моделированию и предсказанию поведения сцены.
Для создания убедительных и последовательных видеороликов недостаточно простого склеивания отдельных кадров. Современные модели все чаще ориентируются на симуляцию и предсказание поведения окружающей среды. Вместо того чтобы фокусироваться исключительно на визуальной достоверности, системы стремятся понять, как объекты взаимодействуют друг с другом, как свет влияет на сцену и как физические законы определяют развитие событий. Такой подход позволяет создавать видео, в котором действия выглядят логичными и правдоподобными, даже при изменении угла обзора или освещения. Вместо «запоминания» изображений, модели учатся «понимать» мир, что открывает возможности для генерации динамичных и реалистичных видеороликов, лишенных типичных для традиционных методов артефактов и несоответствий.
Для создания правдоподобных и последовательных видеоизображений необходим переход к системам, способным к внутреннему представлению и логическому осмыслению окружающего мира, изображенного на видео. Это означает, что модели больше не должны просто «склеивать» отдельные кадры, а должны формировать внутреннюю модель среды, понимая физические законы, взаимосвязи между объектами и последствия действий. Такой подход позволяет предсказывать, как будет развиваться сцена, и генерировать реалистичные кадры, даже если они не были явно запечатлены на исходных данных. В результате, системы смогут не только отображать визуальную реальность, но и «понимать» ее, обеспечивая более высокую степень согласованности и правдоподобия в генерируемых видеоматериалах.
Интернализация реальности: Стратегии представления состояния
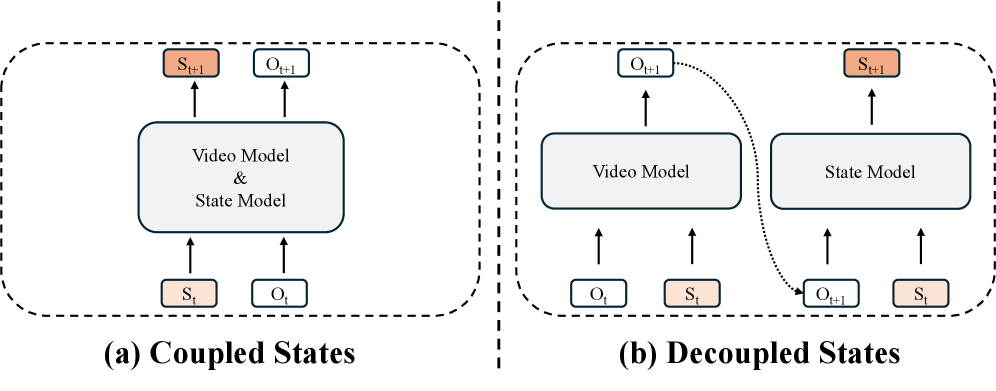
Способность модели генерировать связное видео напрямую зависит от того, как она представляет текущее состояние окружающей среды. Это представление является основой для предсказания будущих кадров, поскольку модель использует его для экстраполяции и создания последовательных визуальных данных. Неточное или неполное представление состояния приводит к несогласованности и визуальным артефактам в генерируемом видеопотоке. Таким образом, эффективная стратегия представления состояния является критически важным компонентом любой модели генерации видео, обеспечивая логическую последовательность и реалистичность генерируемого контента.
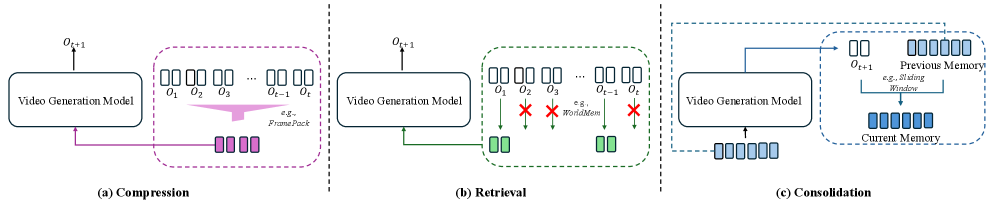
Существуют два основных подхода к представлению текущего состояния среды в моделях генерации видео. Первый — поддержание “неявного состояния” (implicit state), которое заключается в непосредственном хранении истории наблюдений. Этот метод прост в реализации, но требует значительных вычислительных ресурсов и памяти по мере увеличения длительности последовательности. Второй подход — построение “явного состояния” (explicit state) — сжатого, изученного представления, извлекающего существенную информацию из исторических данных. Явное состояние позволяет снизить вычислительную сложность и повысить масштабируемость модели, поскольку хранит не всю историю наблюдений, а лишь ее сжатое представление, полученное в процессе обучения.
Модели пространства состояний (StateSpaceModels) представляют собой подход к реализации явных состояний, обеспечивающий более эффективный и масштабируемый способ захвата существенной информации о моделируемом мире. В отличие от хранения полной истории наблюдений, модели пространства состояний обучаются сжимать входные данные в вектор состояния фиксированной размерности, который содержит наиболее релевантную информацию для прогнозирования будущих событий. Этот сжатый вектор позволяет модели эффективно обрабатывать длинные последовательности данных, избевая экспоненциального роста вычислительных затрат, характерного для методов, основанных на хранении полной истории. Оптимизация параметров модели пространства состояний позволяет добиться баланса между сжатием информации и точностью представления, что критически важно для генерации когерентного видео.
Эффективное представление состояния (StateRepresentation) играет ключевую роль в создании моделей, способных к последовательному прогнозированию и генерации данных. Сети памяти (MemoryNetworks) представляют собой один из подходов к построению и использованию таких внутренних моделей. Они позволяют модели хранить и извлекать информацию о прошлых наблюдениях, формируя компактное представление текущего состояния среды. В основе работы сетей памяти лежит механизм внимания, позволяющий модели динамически выбирать наиболее релевантную информацию из хранимой памяти для принятия решений и прогнозирования будущих состояний. Использование сетей памяти позволяет модели эффективно обрабатывать последовательности данных переменной длины и адаптироваться к изменяющимся условиям среды, что особенно важно для задач, требующих долгосрочного планирования и прогнозирования.
Прогностическая сила: Каузальное мышление в видео
Для генерации убедительного видео недостаточно просто предсказывать следующий кадр; необходим анализ причинно-следственных связей внутри сцены. Традиционные методы, основанные на непосредственном сопоставлении пикселей, часто не учитывают физические законы и логику взаимодействия объектов. Это приводит к визуально правдоподобным, но физически невозможным ситуациям. Например, модель может «увидеть», что объект падает, но не «понять», что причиной этого является гравитация, что затрудняет корректное предсказание траектории и взаимодействия с другими объектами в сцене. Таким образом, понимание причинно-следственных связей является ключевым для создания реалистичных и когерентных видеосимуляций.
Причинно-следственное рассуждение (Causal Reasoning) в контексте генерации видео позволяет моделям не просто фиксировать последовательность событий, но и устанавливать взаимосвязь между причинами и следствиями в смоделированной среде. Это означает, что модель способна предсказывать не только, что произойдет дальше, но и почему это произойдет, основываясь на физических законах и взаимодействии объектов. Такой подход обеспечивает создание более правдоподобных и когерентных симуляций, поскольку изменения в одной части сцены логически влияют на другие, а поведение объектов соответствует ожидаемым физическим принципам. В отличие от простого запоминания паттернов, причинно-следственное рассуждение позволяет модели адаптироваться к новым ситуациям и генерировать реалистичные результаты даже при незнакомых входных данных.
Все большее распространение получают большие мультимодальные модели (Large Multimodal Models) для улучшения понимания причинно-следственных связей в видео. Эти модели интегрируют информацию из различных источников, таких как визуальные данные, аудио, текстовые описания и данные о глубине, что позволяет им формировать более полное представление о происходящем в сцене. Объединение различных модальностей позволяет моделям не только распознавать объекты и действия, но и делать выводы о скрытых причинах и последствиях, что критически важно для создания реалистичных и правдоподобных видеосимуляций. Например, модель, получающая визуальную информацию о падающем объекте в сочетании со звуком удара, может более точно предсказать его траекторию и взаимодействие с окружающей средой.
Оценка способности модели к причинно-следственному мышлению требует проведения интервенционного тестирования — анализа реакции модели на изменения или вмешательства в симулируемую среду. На текущий момент, даже самые передовые модели демонстрируют результат всего в 24% по шкале Physics-IQ, что указывает на существенный разрыв между визуальной реалистичностью генерируемого видео и адекватным моделированием физических взаимодействий. Низкий показатель Physics-IQ подчеркивает, что модели часто способны генерировать правдоподобные изображения, но не понимают лежащие в их основе физические принципы, что приводит к неправдоподобному поведению при внесении изменений в сценарий.

Долгосрочная согласованность: Создание реалистичных симуляций
Долгосрочная согласованность является наивысшим критерием оценки для моделей генерации видео, определяющим их способность создавать реалистичные и связные последовательности на протяжении длительного времени. В отличие от моделей, способных генерировать впечатляющие короткие ролики, истинный успех заключается в поддержании логической последовательности событий, правдоподобности физических взаимодействий и визуальной непрерывности на протяжении сотен или даже тысяч кадров. Эта задача требует от модели не просто воспроизведения отдельных изображений, но и понимания причинно-следственных связей, сохранения идентичности объектов и поддержания целостности виртуального мира, что делает долгосрочную согласованность ключевым показателем зрелости и эффективности алгоритмов генерации видео.
Долгосрочная согласованность в генерации видео достигается благодаря сложному взаимодействию трех ключевых компонентов. Мировая модель, функционирующая как внутренняя симуляция окружения, позволяет предсказывать будущие состояния. Точность этой симуляции напрямую зависит от адекватного представления состояния, которое должно захватывать релевантную информацию об объектах и их взаимодействиях. Однако, даже точное представление недостаточно; необходим надежный причинно-следственный анализ, способный предсказывать, как действия повлияют на развитие событий в симулированном мире. В совокупности, эти компоненты обеспечивают модель возможности планировать, прогнозировать и создавать последовательности, которые выглядят реалистичными и логичными даже на протяжении длительного времени.
В рамках создания долгосрочно связных видео, использование обучения с подкреплением на основе моделей (Model-Based RL) играет ключевую роль в повышении реалистичности генерируемых последовательностей. Данный подход позволяет модели не просто генерировать кадры, но и планировать будущие действия и принимать решения в симулируемой среде, основываясь на внутреннем представлении мира. Модель, обученная с использованием Model-Based RL, способна предсказывать последствия своих действий, оптимизируя последовательность кадров для достижения долгосрочной согласованности и избежания логических несоответствий. Это существенно улучшает правдоподобие генерируемого видео, позволяя создавать более сложные и реалистичные сцены, в которых объекты взаимодействуют друг с другом предсказуемым образом, что особенно важно для длинных последовательностей, где поддержание целостности повествования является критически важным.
Современные архитектуры, ориентированные на поддержание устойчивости, демонстрируют способность генерировать реалистичные видеопоследовательности, сохраняя согласованность сцены на протяжении более 1800 кадров, что подтверждается использованием эталонного набора данных VBench-long. В отличие от них, многие другие модели испытывают “коллапс” — потерю связности и реалистичности — уже после примерно 600 кадров. Оценка качества получаемых симуляций осуществляется с помощью комплекса VideoQualityMetrics, позволяющего объективно измерить визуальную достоверность и согласованность генерируемых видео, подтверждая превосходство устойчивых архитектур в создании продолжительных и правдоподобных визуальных сцен.
К интерактивным мирам: Будущее видео
Переход к генерации видео на основе симулированных сред открывает путь к созданию интерактивных, а не пассивных впечатлений. Вместо простого просмотра готового контента, зритель получает возможность влиять на происходящее, взаимодействовать с виртуальным миром и формировать развитие событий. Такой подход принципиально отличается от традиционной видеопродукции, поскольку делает акцент на создании целой симулированной реальности, в которой каждое действие имеет последствия. В результате, зритель становится участником происходящего, а не просто наблюдателем, что значительно повышает уровень вовлеченности и создает принципиально новый формат развлечений и обучения. Данная технология позволяет создавать динамичные, адаптивные видео, которые реагируют на действия пользователя, стирая границы между виртуальным и реальным миром.
В основе создания динамичного и увлекательного контента лежит концепция замкнутого взаимодействия — ClosedLoopInteraction. Данный подход позволяет агентам, функционирующим внутри смоделированной среды, не просто реагировать на заданные стимулы, но и обучаться, адаптироваться и формировать собственное поведение. Агенты, взаимодействуя друг с другом и с окружением, способны генерировать непредсказуемые, но логически связанные события, что создает иллюзию живого, развивающегося мира. Такой подход значительно расширяет возможности традиционной генерации видео, открывая новые горизонты для интерактивного повествования и виртуальных миров.
Использование среды VideoWorld в качестве полигона для обучения позволяет моделям приобретать устойчивые навыки и успешно применять их в реальных условиях. Особенность подхода заключается в том, что модель, взаимодействуя с виртуальным миром, учится не просто генерировать последовательность изображений, но и понимать причинно-следственные связи, предсказывать последствия своих действий и адаптироваться к изменяющимся обстоятельствам. Такой подход значительно повышает надежность и обобщающую способность моделей, позволяя им справляться с более сложными и непредсказуемыми задачами, чем те, на которых они были изначально обучены.
Происходит фундаментальный сдвиг в подходе к созданию видеоконтента: вместо простой генерации последовательности кадров, разрабатываются полноценные симулированные реальности. Вместо пассивного просмотра, зритель получает возможность взаимодействия с виртуальным миром, где события разворачиваются по определенным, но динамически изменяющимся правилам. Ключевым аспектом этой трансформации является обеспечение внутренней логической непротиворечивости созданного мира, что достигается путем оценки с помощью метрики “World Consistency Score” (WCS). Высокий показатель WCS гарантирует, что объекты и события в симуляции взаимодействуют предсказуемо и реалистично, избегая аномалий и несоответствий, что делает взаимодействие более убедительным и захватывающим для пользователя.
Исследование демонстрирует переход от простого генерирования реалистичных видео к созданию полноценных «моделей мира», способных к последовательному представлению состояний и пониманию причинно-следственных связей. Этот подход требует от систем не просто воспроизведения визуальных деталей, но и способности к интерактивному моделированию и предсказанию. Как заметил Ян ЛеКун: «Машинное обучение — это, прежде всего, поиск закономерностей». В данном контексте, поиск закономерностей проявляется в стремлении к созданию моделей, способных улавливать глубинные принципы, управляющие динамикой видео, и использовать их для генерации последовательных и правдоподобных сцен. Это особенно важно для обеспечения долгосрочной согласованности генерируемого видеоряда, что является одной из ключевых проблем, обсуждаемых в работе.
Что Дальше?
Представленные построения, хотя и демонстрируют прогресс в генерации видео, неизбежно наталкиваются на фундаментальную проблему: достоверность модели мира не измеряется красотой рендеринга. До тех пор, пока алгоритмы ограничиваются имитацией поверхностных признаков, а не моделированием базовых причинно-следственных связей, они останутся уязвимыми к даже незначительным отклонениям от ожидаемого поведения. Асимптотически, подобный подход обречён на провал при попытке генерации последовательностей большой длины.
Истинным вызовом представляется разработка представлений состояний, инвариантных относительно шума и неточностей, и, что более важно, алгоритмов, способных доказуемо поддерживать эту инвариантность. Необходимо сместить акцент с «реалистичности» на «согласованность» — иными словами, на возможность предсказания будущего состояния системы на основе её прошлого, без апелляции к внешним данным. Простое увеличение объёма обучающих данных не решит эту проблему; требуется принципиально новый подход к моделированию динамики.
В конечном счёте, успех в данной области будет определяться не количеством сгенерированных кадров, а способностью системы к интерактивному моделированию — к симуляции, в которой изменения в начальных условиях приводят к предсказуемым и логичным последствиям. Это требует не просто генерации видео, но построения доказуемо корректных и эффективных алгоритмов причинно-следственного вывода.
Оригинал статьи: https://arxiv.org/pdf/2601.17067.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-27 15:37