Автор: Денис Аветисян
Исследователи представили модель VideoMaMa, использующую генеративные сети для точного и реалистичного выделения объектов на видео.

Предложена диффузионная модель для видеомонтажа с использованием псевдо-разметки и крупномасштабного датасета MA-V, обеспечивающая высокую временную согласованность.
Несмотря на значительные успехи в области компьютерного зрения, обобщение моделей выделения объектов на видео для реальных сцен остается сложной задачей из-за нехватки размеченных данных. В данной работе, представленной под названием ‘VideoMaMa: Mask-Guided Video Matting via Generative Prior’, предлагается модель VideoMaMa, преобразующая грубые сегментационные маски в точные альфа-маты, используя предварительно обученные диффузионные модели для видео. Разработанная методика демонстрирует сильную способность к обобщению даже при обучении исключительно на синтетических данных, а также позволила создать крупномасштабный датасет MA-V, содержащий более 50 тысяч видео с высококачественными аннотациями для выделения объектов. Не является ли создание подобных масштабных, псевдо-размеченных датасетов ключом к дальнейшему развитию исследований в области видео-маттинга и преодолению разрыва между синтетическими и реальными данными?
Сложность Реалистичного Видео-Мэттинга
Создание реалистичных видеомасок — точного отделения переднего плана от фона — по-прежнему представляет собой сложную задачу, обусловленную сложностью реальных сцен и эффектом размытия в движении. Несмотря на значительный прогресс в области компьютерного зрения, алгоритмы часто сталкиваются с трудностями при обработке видеоматериалов, содержащих детализированные объекты, полупрозрачные материалы или быстрые перемещения. Размытие, возникающее из-за движения камеры или объектов, приводит к нечетким границам и артефактам в полученных масках, что снижает визуальное качество и достоверность результата. Поэтому разработка методов, способных эффективно справляться с этими проблемами, остается актуальной и востребованной задачей в сфере обработки видео и создания визуальных эффектов.
Одной из ключевых проблем в области реалистичного выделения объектов на видео является недостаток качественных и масштабных обучающих данных. Существующие наборы данных часто оказываются слишком малы и не способны охватить всё разнообразие сложных сцен и движений, что приводит к неточностям и заметным артефактам в результатах работы алгоритмов. В частности, реальные видеоданные для обучения, как правило, значительно уступают по объёму синтетическим, что ограничивает возможности создания надежных и точных моделей. Новый набор данных MA-V призван решить эту проблему, предлагая масштаб, превышающий аналогичные существующие решения почти в 50 раз, и обеспечивая, таким образом, более эффективное обучение и повышение качества выделения объектов на видео.

MA-V: Новый Масштабный Датасет для Реалистичного Мэттинга
Набор данных MA-V представляет собой первый крупномасштабный и высококачественный ресурс для видео-мэттинга, состоящий из 50 541 видео, снятых в реальных условиях. Данный набор разработан для обеспечения необходимого объема и реалистичности данных, необходимых для обучения и оценки современных моделей видео-мэттинга. В отличие от существующих наборов данных, MA-V предлагает значительно больший масштаб, позволяя создавать более точные и надежные алгоритмы выделения объектов на видео.
В основе создания MA-V лежит датасет SA-V, который был использован в качестве фундамента для дальнейшего расширения обучающей выборки. Для эффективного увеличения объема данных применялись методы генерации псевдо-меток (pseudo-labeling). Этот подход позволяет автоматически формировать метки для новых видеофрагментов, используя обученные модели, что значительно снижает затраты на ручную разметку и позволяет быстро наращивать объем данных для обучения и оценки моделей видео-мэттинга.
Набор данных MA-V обеспечивает необходимый масштаб и реалистичность для эффективного обучения и оценки современных моделей видео-маскировки. Он содержит 50 541 видео, что почти в 50 раз превышает размер существующих наборов данных, основанных на реальных видеозаписях. Такой объем данных позволяет создавать модели, способные более точно выделять объекты на видео, учитывая сложные сцены и динамическое изменение фона, что критически важно для широкого спектра приложений, включая редактирование видео, дополненную реальность и компьютерное зрение.
![Набор данных MA-V обеспечивает более точные альфа-маски для различных сценариев, как показано на примере качественных визуализаций, превосходящие оригинальные маски SA-V[30].](https://arxiv.org/html/2601.14255v1/x4.png)
VideoMaMa: Диффузионный Подход к Реалистичному Мэттингу
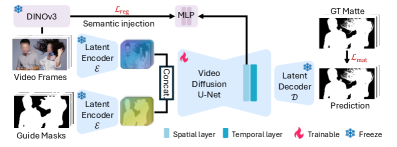
VideoMaMa представляет собой новую модель, основанную на диффузионных процессах, предназначенную для генерации реалистичных аннотаций видеомаскирования (matte) из бинарных сегментационных масок. В отличие от традиционных методов, VideoMaMa использует принципы диффузии для создания более детализированных и правдоподобных масок, что позволяет точно отделять передний план от фона в видеоматериале. Модель принимает на вход бинарную маску, указывающую области, которые необходимо выделить, и генерирует соответствующую карту альфа-канала (alpha matte), определяющую степень прозрачности каждого пикселя. Это позволяет создавать реалистичные композиции и эффекты, такие как наложение объектов на видео или изменение фона.
В основе VideoMaMa лежит модель Stable Video Diffusion (SVD), дополненная механизмом внедрения семантических знаний с использованием DINOv3. DINOv3, предварительно обученная модель визуального признания, позволяет извлекать семантические признаки из входного видеокадра. Эти признаки затем используются для улучшения понимания границ между объектом и фоном при генерации альфа-матов. Инъекция семантических знаний помогает модели более точно определять сложные границы, особенно в случаях, когда объект имеет сложную форму или находится на зашумленном фоне, что существенно повышает реалистичность сгенерированных альфа-матов.
Обучение VideoMaMa осуществляется в два этапа для оптимизации как пространственных, так и временных слоев модели. Первый этап фокусируется на оптимизации пространственных слоев, что позволяет добиться высокой детализации и точности маскирования на каждом кадре. Второй этап оптимизирует временные слои, что обеспечивает согласованность маскирования во времени и минимизирует временные артефакты. Такой подход позволяет добиться стабильного и реалистичного выделения объектов на протяжении всего видео, что критически важно для задач редактирования и композитинга видеоматериалов.
Результаты экспериментов демонстрируют значительное превосходство VideoMaMa над существующими методами генерации реалистичных альфа-матов. Модель достигла передовых результатов на стандартных бенчмарках, включая улучшения в метриках, оценивающих точность выделения границ и реалистичность сгенерированных матов. Сравнение с другими подходами, такими как RIFE и MODNet, показывает, что VideoMaMa обеспечивает более четкие и согласованные результаты, особенно в сложных сценах с мелкими деталями и динамическими изменениями. Достигнутые улучшения подтверждаются как количественными показателями, так и визуальной оценкой экспертов.
Эффективность и Перспективы Дальнейших Исследований
Модель SAM2-Matte, представляющая собой усовершенствованную версию SAM2, дообученную на наборе данных MA-V, демонстрирует впечатляющую устойчивость в задачах видео-мэттинга. Этот подход позволил добиться значительных успехов в выделении объектов на видео, обеспечивая точное и эффективное разделение переднего плана от фона. Успех SAM2-Matte подтверждает перспективность использования предварительно обученных моделей в сочетании со специализированными наборами данных для решения сложных задач компьютерного зрения, особенно в контексте обработки видеоматериалов. Данная разработка открывает новые возможности для приложений, требующих точного и надежного выделения объектов в динамичных сценах.
Оценка качества полученных матов с использованием метрик, таких как Gradient Error и MAD (Mean Absolute Difference), однозначно подтверждает превосходство разработанной модели в точности и реалистичности по сравнению с существующими подходами к матированию с использованием масок. Низкие значения этих метрик свидетельствуют о минимальных погрешностях в градиентах и высокой степени соответствия между сгенерированным матом и реальным объектом, что позволяет получать более четкие и правдоподобные результаты. Данные показатели демонстрируют значительное улучшение качества по сравнению с другими алгоритмами, что делает предложенный метод особенно эффективным для задач, требующих высокой точности выделения объектов на видео.
Эффективность разработанной модели была тщательно проверена на различных наборах данных, включая V-HIM60 и YouTubeMatte Dataset, что подтверждает ее способность к обобщению и адаптации к новым условиям. Результаты тестирования показали значительное улучшение производительности на VOS J&F, конкретно на сложном наборе данных DAVIS, что свидетельствует о высокой точности и надежности алгоритма в задачах выделения движущихся объектов и сегментации видео. Такая универсальность позволяет предполагать успешное применение модели в широком спектре приложений, от профессионального видеомонтажа до систем компьютерного зрения.
Дальнейшие исследования направлены на повышение временной согласованности генерируемых матов, что критически важно для реалистичного отображения динамичных сцен в видео. Разработчики планируют усовершенствовать алгоритмы обработки последовательностей кадров, чтобы избежать визуальных артефактов и обеспечить плавные переходы между ними. Кроме того, ведется работа по расширению возможностей модели для обработки более сложных сценариев, включающих взаимодействие с разнообразными объектами, сложные световые условия и значительные изменения в позах и движениях. Улучшение устойчивости к шумам и окклюзиям также является приоритетной задачей, что позволит применять данную технологию в широком спектре приложений, от профессионального видеомонтажа до создания визуальных эффектов и дополненной реальности.

Исследование, представленное в данной работе, демонстрирует элегантность подхода к задаче видео матирования. Авторы, подобно математикам, стремящимся к доказательству, а не к эмпирической проверке, создали модель VideoMaMa и датасет MA-V, опираясь на генеративные априорные знания и псевдо-маркировку. Как заметил Дэвид Марр: «Вычислительная теория разума должна объяснить, как физические системы, такие как мозг, могут генерировать ментальные состояния». Аналогично, данная работа показывает, как вычислительные модели, используя принципы диффузии, могут генерировать реалистичные результаты в задаче видео матирования, преодолевая разрыв между синтетическими и реальными данными. Особое внимание к временной согласованности является ключевым аспектом, обеспечивающим математическую чистоту и корректность получаемых результатов.
Куда Ведет Этот Путь?
Представленная работа, несомненно, представляет собой шаг вперед в области видео матинга, однако истинный математик не склонен к самодовольству. Создание синтетического набора данных MA-V посредством псевдо-маркировки — элегантное решение, но оно неизбежно вносит систематическую ошибку, природу которой необходимо тщательно исследовать. Достаточность этого подхода для обобщения на произвольные, непредсказуемые условия остается открытым вопросом. Асимптотическое поведение модели при увеличении сложности сцен и разрешений видео требует детального анализа.
Следующим логичным шагом представляется разработка метрик, способных оценивать не просто пиксельную точность, а семантическую корректность выделенных объектов. Простое совпадение границ недостаточно; необходимо доказать, что алгоритм способен различать объекты, имеющие схожие визуальные характеристики, и учитывать контекст сцены. Более того, необходимо исследовать возможности интеграции с другими модальностями данных — например, с аудио или данными о глубине — для повышения робастности и точности.
В конечном счете, задача видео матинга, как и любая другая задача компьютерного зрения, сводится к построению математически корректной модели мира. До тех пор, пока мы не достигнем этой цели, все наши достижения останутся лишь приближениями, пусть и элегантными.
Оригинал статьи: https://arxiv.org/pdf/2601.14255.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 15:25