Автор: Денис Аветисян
Исследователи предлагают новый масштабный датасет и методологию для обучения мультимодальных моделей, способных понимать сложные видеоинструкции.
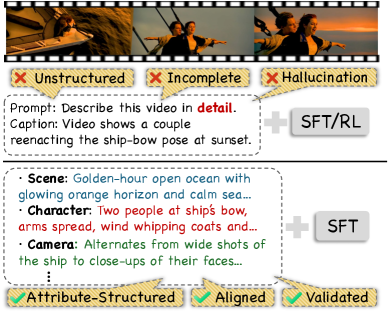
Представлен датасет ASID-1M с атрибутивно-структурированными видеоинструкциями и конвейер ASID-Verify для обеспечения высококачественной разметки данных.
Несмотря на прогресс в области мультимодальных больших языковых моделей, понимание видеоконтента остается сложной задачей из-за неполноты и отсутствия структурированности существующих обучающих данных. В работе ‘Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions’ представлен новый подход к решению этой проблемы, включающий создание набора данных ASID-1M, состоящего из миллиона структурированных аудиовизуальных инструкций с атрибутивным контролем, и конвейера ASID-Verify для обеспечения высокого качества аннотаций. Разработанная модель ASID-Captioner, обученная на ASID-1M, демонстрирует улучшение качества детальных подписей, снижение галлюцинаций и повышение точности следования инструкциям, достигая сопоставимых результатов с Gemini-3-Pro. Позволит ли подобный подход к созданию структурированных данных открыть новые горизонты в области универсального видеопонимания и мультимодального искусственного интеллекта?
Сквозь Хаос Видео: Вызовы Глубокого Понимания
Современные модели анализа видео зачастую испытывают трудности при обработке сложных, детализированных инструкций, что связано с недостаточным охватом семантических нюансов. Вместо глубокого понимания сцены и объектов, эти модели склонны к обобщениям и не способны точно интерпретировать последовательность действий или атрибуты, описанные в запросе. Например, инструкция «изменить цвет только верхней пуговицы на рубашке» может оказаться непосильной задачей, поскольку модель не выделяет конкретный объект и его характеристики с необходимой точностью. Такое ограничение объясняется тем, что существующие алгоритмы часто оперируют с широкими категориями и не учитывают тонкие различия в визуальных признаках, что существенно снижает эффективность анализа видео в задачах, требующих высокой степени детализации и композиционной точности.
Существующие наборы данных для анализа видео часто делают акцент на обобщенных категориях объектов и действий, упуская из виду детализированное понимание атрибутов и взаимосвязей. Это приводит к тому, что модели машинного обучения испытывают трудности при анализе видео, требующего точного определения характеристик объектов, например, цвета, материала или формы, а также понимания сложных отношений между ними. В результате, возможности систем анализа видео ограничиваются, что препятствует развитию приложений, нуждающихся в нюансированном восприятии визуальной информации, таких как автоматическое редактирование видеоконтента или создание интеллектуальных систем помощи для людей с ограниченными возможностями.
Ограничения в точности анализа видеоматериалов оказывают существенное влияние на развитие приложений, требующих детальной обработки визуальной информации. Например, в сфере видеомонтажа, автоматизированное вырезание и компоновка сцен, основанные на понимании конкретных действий и объектов, остаются сложной задачей. Аналогично, в разработке вспомогательных технологий для людей с ограниченными возможностями, точное распознавание жестов, выражений лица или объектов в окружающей среде критически важно для обеспечения эффективной коммуникации и навигации. Неспособность систем понимать нюансы визуальной информации снижает эффективность таких инструментов, ограничивая возможности автоматизации и персонализации в этих и других областях, где требуется глубокое понимание видеоконтента.
ASID-1M: Новая Веха в Детальном Видео Рассуждении
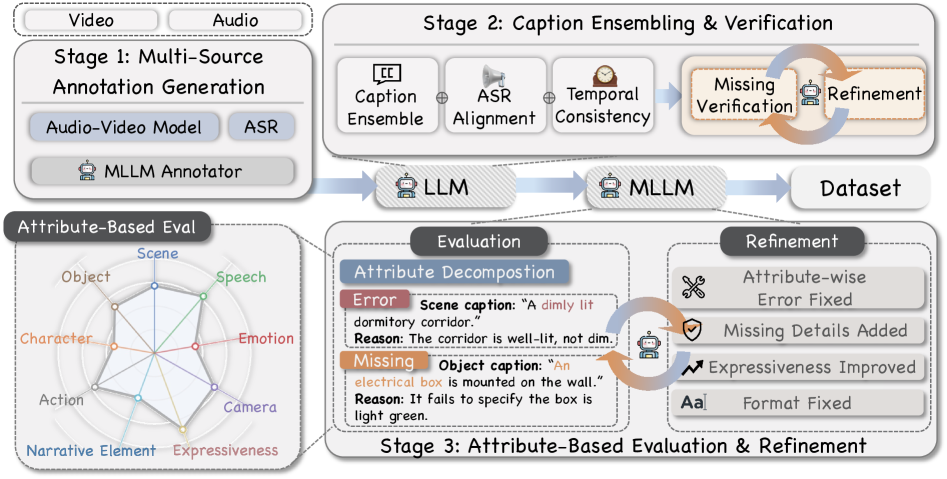
ASID-1M представляет собой масштабный набор данных, насчитывающий миллион аудиовизуальных инструкций, разработанный для оценки и обучения моделей в области детального понимания видео. Данный набор данных характеризуется композиционной структурой, позволяющей комбинировать различные инструкции для создания более сложных задач. Ключевой особенностью является структурирование атрибутов, то есть, каждая инструкция четко описывает визуальные и слуховые элементы, что требует от моделей явного рассуждения о конкретных деталях в видеоматериале. Это отличает ASID-1M от других наборов данных, ориентированных на более общие задачи понимания видео.
Набор данных ASID-1M построен на основе существующих ресурсов, таких как LLaVA-Video-178K и FineVideo, однако значительно расширяет их возможности благодаря детализированным аннотациям. В отличие от исходных наборов, ASID-1M не просто предоставляет видео и текстовые описания, но и включает структурированные атрибуты, описывающие визуальные элементы и действия, происходящие в видео. Это позволяет моделям не только понимать общую суть происходящего, но и точно идентифицировать и анализировать конкретные объекты и их характеристики, что существенно повышает точность и детализацию рассуждений.
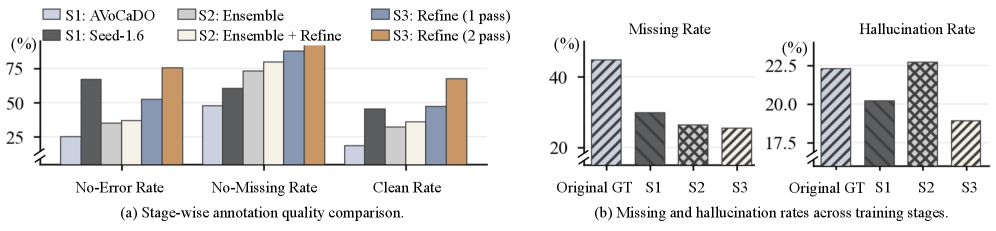
Ключевым элементом создания ASID-1M является конвейер ASID-Verify, предназначенный для обеспечения высокого качества данных и их дальнейшей доработки. Данный конвейер использует передовые методы аннотирования, включающие в себя многоступенчатую проверку и исправление ошибок, а также механизмы оценки согласованности между различными аннотаторами. ASID-Verify не только выявляет неточности в существующих аннотациях, но и позволяет проводить уточнение инструкций и визуальных признаков, что существенно повышает надежность и полезность датасета для обучения моделей, работающих с видео и требующих детального понимания происходящих событий. Применение данного конвейера позволило значительно снизить уровень шума в данных и обеспечить их соответствие высоким стандартам качества.
В основе разработки ASID-1M лежит концепция структурированного надзора на основе атрибутов, что требует от моделей явного анализа визуальных элементов. Вместо простого определения объекта на видео, модель должна идентифицировать и учитывать его характеристики — цвет, форму, материал, положение и взаимодействие с другими объектами. Такой подход подразумевает, что каждое задание содержит не только описание действия, но и детальные атрибуты вовлеченных объектов, что стимулирует модели к более глубокому пониманию визуальной информации и повышает точность рассуждений о происходящем на видео. Это отличает ASID-1M от традиционных наборов данных, где акцент делается на общей классификации или обнаружении объектов.
ASID-Captioner: Модель для Точного Описания Видео
Модель ASID-Captioner была обучена на наборе данных ASID-1M с использованием метода Supervised Fine-Tuning (SFT), который позволил адаптировать базовую модель Qwen2.5-Omni для задачи генерации описаний видео. Процесс SFT предполагает тонкую настройку предварительно обученной модели на размеченном наборе данных ASID-1M, что позволяет улучшить ее способность генерировать точные и релевантные описания видеоконтента, специфичные для данной задачи.
Обучение модели ASID-Captioner осуществляется поэтапно, начиная с обучения на основе отдельных атрибутов и постепенно переходя к использованию комплексного атрибутивного контроля. Такой подход позволяет оптимизировать процесс обучения, обеспечивая более эффективное усвоение информации на каждом этапе. Изначально модель обучается распознавать и описывать отдельные характеристики видео, после чего происходит усложнение задачи — обучение на основе комбинаций различных атрибутов. Это позволяет модели постепенно улучшать свою способность к комплексному анализу видеоконтента и генерации точных и информативных описаний.
Эффективность ASID-Captioner была всесторонне оценена на стандартных наборах данных, включая Video-SALMONN-2, UGC-VideoCap и Charades-STA. Результаты демонстрируют существенное улучшение в следовании инструкциям, что подтверждается снижением количества пропущенных объектов и галлюцинаций на Video-SALMONN-2 по сравнению с другими доступными моделями с открытым исходным кодом. Данные показатели подтверждают способность модели к более точному и полному описанию видеоконтента.
Для повышения качества обучения модели ASID-Captioner применялась курация данных, основанная на автоматическом распознавании речи (ASR) с использованием Whisper и последующей доработке аннотаций с помощью Seed-1.6. В результате, модель демонстрирует высокие показатели по всем метрикам на VidCapBench-AE, превосходя существующие открытые модели для генерации подписей и многоцелевые модели по точности ответов на вопросы в бенчмарках Daily-Omni и WorldSense. Использование ASR и автоматизированной доработки аннотаций позволило значительно улучшить качество обучающих данных и, как следствие, повысить производительность модели в задачах понимания и описания видео.

Значение и Перспективы Развития Видео Искусственного Интеллекта
Возможность модели ASID-Captioner генерировать подробные и насыщенные атрибутами описания открывает значительные перспективы для развития вспомогательных технологий, ориентированных на людей с нарушениями зрения. Благодаря детализированному анализу видео, система способна не просто идентифицировать объекты, но и описывать их характеристики — цвет, размер, положение в кадре, а также действия, которые они выполняют. Это позволяет создавать аудиоописания видеоконтента, значительно улучшающие его доступность и понимание для слабовидящих и незрячих пользователей. По сути, ASID-Captioner выступает в роли «виртуального ассистента», который предоставляет всестороннюю информацию о визуальной составляющей видео, делая ее доступной для тех, кто лишен возможности ее увидеть. Такой подход выходит за рамки простого перечисления объектов, предлагая полноценное описание происходящего, что критически важно для получения полного представления о содержании видеоматериала.
Разработка датасета ASID-1M и модели ASID-Captioner знаменует собой существенный прогресс в области видеомонтажа и создания контента. В отличие от традиционных методов, основанных на временных метках или визуальном анализе, данная система способна понимать семантическое содержание видео. Это позволяет осуществлять точную манипуляцию с видеоматериалами, например, выделять и редактировать фрагменты, содержащие определенные объекты или действия, основываясь на их значении, а не просто на их местоположении во времени. Возможность детального анализа и понимания происходящего на видео открывает новые горизонты для автоматизированного монтажа, создания динамичных видеоэффектов и адаптации контента под различные запросы и платформы, значительно упрощая и ускоряя процесс производства видеоматериалов.
Дальнейшие исследования сосредоточены на интеграции обучения с подкреплением (Reinforcement Learning) для усовершенствования поведения модели ASID-Captioner. Предполагается, что применение методов RL позволит системе не только генерировать описания, но и активно обучаться на основе получаемой обратной связи, вознаграждая точность и релевантность. Этот подход позволит модели адаптироваться к различным стилям описания и контекстам видео, существенно повышая качество и детализацию генерируемых подписей. Ожидается, что обучение с подкреплением позволит системе самостоятельно корректировать свои действия, оптимизируя процесс описания видео и достигая более высокой степени соответствия человеческому восприятию.
Принципы, лежащие в основе ASID-1M и ASID-Captioner, обладают значительным потенциалом для расширения возможностей в других мультимодальных областях. Разработанная методология позволяет создавать более интеллектуальные и универсальные системы искусственного интеллекта, способные эффективно обрабатывать и понимать информацию, поступающую из различных источников. Ручная проверка уточненных подписей к видео демонстрирует впечатляющую надежность — более 98% — и незначительные отклонения во времени — в пределах двух секунд, что подтверждает высокую точность и практическую применимость данной технологии в широком спектре задач, от автоматической обработки контента до создания продвинутых систем помощи и поддержки.

Работа над датасетом ASID-1M и пайплайном ASID-Verify демонстрирует, что даже самые сложные модели требуют качественных данных. Улучшение производительности ASID-Captioner не является магией, а следствием кропотливой работы над структурированием и верификацией инструкций. Как сказал Эндрю Ын: «Мы находимся в эпоху, когда данные стоят дороже алгоритмов». Это особенно верно для мультимодальных моделей, где точность аннотаций и временная согласованность играют ключевую роль. Данные — это не истина, а компромисс между багом и Excel, и ASID-1M — это попытка сдвинуть этот компромисс в сторону большей надёжности и детализации.
Куда же всё это ведёт?
Представленный набор данных, ASID-1M, и конвейер верификации, ASID-Verify, — это, безусловно, попытка усмирить хаос визуального мира, разложить его на атрибуты и придать смысл. Однако, стоит помнить: чем точнее мы пытаемся описать реальность, тем больше вероятность, что упускаем нечто важное. Идеальная корреляция в данных — почти всегда признак ошибки, а любая модель — это лишь временное перемирие с неопределённостью.
Настоящая проблема не в увеличении масштаба данных, а в понимании того, что они умалчивают. Следующий шаг — это не столько создание более сложных моделей, сколько разработка методов, позволяющих выявлять и учитывать неявные предположения, скрытые в данных. Возможно, стоит обратить внимание на те случаи, когда модель ошибается — именно там кроется истинное знание. Если гипотеза подтвердилась слишком легко — значит, мы не искали достаточно глубоко.
В конечном счёте, всё, что можно посчитать, не стоит доверия. Универсальное понимание видео — это не цель, а иллюзия. Задача исследователя — не построить идеальную модель, а научиться жить с её несовершенством, видеть в шуме закономерности, а в хаосе — красоту. И помнить, что каждое заклинание имеет свою цену.
Оригинал статьи: https://arxiv.org/pdf/2602.13013.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Звук в коде: новая эра токенизации аудио
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Адаптация алгоритмов: обучение с подкреплением для многокритериальной оптимизации
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
2026-02-16 20:20