Автор: Денис Аветисян
Новое исследование анализирует влияние различных технологий виртуализации на сетевые задержки и загрузку процессора в облачных средах.
Анализ данных экспериментов с KVM, Docker и LXC, а также машинное обучение для оптимизации облачной инфраструктуры.
Виртуализация, лежащая в основе современных облачных инфраструктур, обеспечивает гибкость, но одновременно усложняет прогнозирование сетевой производительности. В данной работе, ‘Data analysis of cloud virtualization experiments’, представлен детальный анализ влияния различных технологий виртуализации (KVM, Docker, LXC) на ключевые сетевые метрики, такие как задержка и загрузка процессора. Проведенные измерения и разработанные модели позволяют оценить влияние виртуализации на время кругового обхода пакетов и оптимизировать конфигурацию облачной среды. Не станет ли представленный датасет основой для разработки интеллектуальных систем управления облачными ресурсами, способных к самооптимизации и адаптации к изменяющимся условиям?
Основы: Виртуализация и Облачные Технологии
Современные сетевые технологии в значительной степени зависят от облачных вычислений, что диктует необходимость в эффективном распределении и управлении ресурсами. Облачные платформы позволяют организациям масштабировать инфраструктуру по требованию, оптимизируя затраты и повышая гибкость. Это требует передовых алгоритмов планирования, автоматического масштабирования и мониторинга использования ресурсов, чтобы гарантировать оптимальную производительность приложений и сервисов. Особенно важно эффективно управлять такими ресурсами, как вычислительная мощность, хранилище данных и пропускная способность сети, чтобы избежать узких мест и обеспечить бесперебойную работу даже при пиковых нагрузках. Именно поэтому разработка и внедрение интеллектуальных систем управления ресурсами являются ключевым направлением развития облачных технологий.
Виртуализация является фундаментальным принципом современной сетевой инфраструктуры, позволяющим создавать изолированные вычислительные среды для различных приложений. Эта технология позволяет эффективно использовать ресурсы одного физического сервера, разделяя его на несколько виртуальных машин, каждая из которых функционирует как независимая система. Благодаря виртуализации, разработчики и системные администраторы получают возможность запускать несколько операционных систем и приложений одновременно, оптимизируя использование аппаратного обеспечения и снижая затраты. Изоляция, обеспечиваемая виртуализацией, также повышает безопасность и надежность, предотвращая конфликты между приложениями и обеспечивая стабильную работу системы даже в случае сбоя одного из виртуальных окружений. Таким образом, виртуализация не просто оптимизирует использование ресурсов, но и обеспечивает гибкость, масштабируемость и безопасность, необходимые для современных облачных вычислений.
По мере усложнения виртуализированных и облачных инфраструктур, становится критически важным внедрение эффективных стратегий мониторинга и оптимизации производительности. Современные системы характеризуются высокой динамичностью и масштабируемостью, что затрудняет традиционные методы анализа. Необходим постоянный сбор и анализ метрик, охватывающих ресурсы ЦП, память, дисковое пространство, сетевой трафик и время отклика приложений. Автоматизированные инструменты мониторинга позволяют выявлять узкие места и аномалии в режиме реального времени, что дает возможность оперативно корректировать конфигурацию системы и предотвращать сбои. Оптимизация, в свою очередь, включает в себя такие методы, как балансировка нагрузки, автоматическое масштабирование ресурсов и интеллектуальное управление энергопотреблением, направленные на максимизацию эффективности и снижение затрат.
Создание Тестовой Среды: Виртуальное Пространство
Для систематического анализа производительности была построена виртуальная тестовая среда (Testbed), использующая различные технологии виртуализации, включая KVM, LXC и Docker. Выбор данных технологий обусловлен необходимостью обеспечить разнообразие сценариев и возможность оценки влияния различных подходов к виртуализации на ключевые показатели производительности системы. В рамках Testbed реализована возможность запуска и управления виртуальными машинами и контейнерами, а также сбора и анализа метрик, необходимых для проведения сравнительных тестов и выявления узких мест в производительности.
Драйвер VirtIO значительно повышает производительность виртуальных машин на базе KVM, особенно в центрах обработки данных с высокой интенсивностью операций ввода-вывода. Благодаря оптимизированной архитектуре и прямому доступу к аппаратным ресурсам, VirtIO позволяет добиться минимальной задержки (RTT) при передаче данных, приближающейся к нулю. Это достигается за счет паравиртуализации, когда гостевая операционная система взаимодействует с гипервизором напрямую, обходя эмуляцию устройств, что существенно снижает накладные расходы и повышает общую эффективность системы.
В ходе тестирования Docker демонстрировал стабильно более высокую производительность по сравнению с LXC практически во всех рассмотренных сценариях. Анализ показал, что Docker характеризуется сниженным потреблением ресурсов центрального процессора (CPU) в сравнении с другими технологиями виртуализации, что делает его более эффективным решением для сред с ограниченными вычислительными ресурсами. Данное преимущество связано с архитектурой Docker, основанной на использовании общего ядра операционной системы и легковесных контейнеров, что снижает накладные расходы, связанные с виртуализацией.
![Представленная экспериментальная установка, адаптированная из работы [6], используется для проведения испытаний.](https://arxiv.org/html/2602.05792v1/x1.png)
Измерение Производительности: Сбор и Предобработка Данных
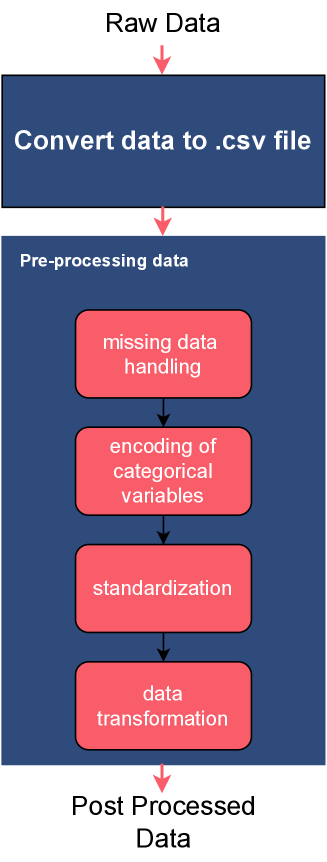
Для точного измерения времени кругового обмена (Round-Trip Time, RTT) и загрузки центрального процессора (CPU Usage) в тестовой среде использовались инструменты Ping и mpstat. Инструмент Ping позволял определить RTT путем отправки ICMP-запросов и измерения времени ответа, в то время как mpstat собирал статистику использования CPU, включая время, затраченное на выполнение задач в режиме пользователя и ядра. Метрики, полученные с помощью этих инструментов, собирались с высокой частотой для обеспечения детального анализа производительности и выявления потенциальных узких мест в системе.
Сырые данные, полученные в ходе измерений, подверглись тщательной предобработке для обеспечения их качества и совместимости с алгоритмами машинного обучения. В частности, применялось One-Hot Encoding для преобразования категориальных признаков в числовой формат, что позволило избежать проблем с интерпретацией категорий алгоритмами. Кроме того, использовалась Z-Score Standardization (стандартизация по Z-оценке) для нормализации числовых признаков путем вычитания среднего значения и деления на стандартное отклонение. Это привело к приведению данных к единому масштабу и улучшению сходимости и производительности моделей машинного обучения. Z = (X - \mu) / \sigma, где X — исходное значение, μ — среднее значение, а σ — стандартное отклонение.
В ходе исследований было установлено, что увеличение частоты отправки пакетов для измерения времени кругового обмена (RTT) приводит к снижению зарегистрированного значения RTT. Это объясняется тем, что более частые измерения позволяют более точно зафиксировать минимальное время прохождения пакета, уменьшая влияние сетевых задержек и колебаний. Получение данных с более высокой частотой также обеспечивает более детальное представление о динамике сетевой производительности, что позволяет выявлять кратковременные изменения и аномалии, недоступные при менее частых измерениях. Таким образом, повышение частоты сбора данных RTT способствует более точному и детализированному анализу сетевой производительности.
Анализ Взаимосвязей: Результаты и Корреляции
Для прогнозирования задержки передачи данных (RTT) и загрузки центрального процессора (CPU Usage) в виртуализированных средах были применены модели машинного обучения, в частности, случайный лес (Random Forest) и регрессор на деревьях решений (Decision Tree Regressor). Эти модели были обучены на основе различных параметров виртуализации, позволяя установить взаимосвязь между настройками виртуальной машины и ее производительностью. Использование алгоритмов машинного обучения позволило автоматизировать процесс выявления закономерностей и предсказания ключевых показателей, что открывает возможности для оптимизации ресурсов и повышения эффективности виртуализированной инфраструктуры. Полученные модели способны не только предсказывать значения RTT и CPU Usage, но и выявлять наиболее значимые параметры виртуализации, влияющие на производительность.
Статистический анализ, выполненный с использованием корреляции рангов Спирмена и метода главных компонент, выявил существенные взаимосвязи между исследуемыми метриками. В частности, обнаружена тесная корреляция между временем отклика (RTT) и загрузкой центрального процессора (CPU Usage), что позволяет предположить, что увеличение вычислительной нагрузки напрямую влияет на задержку сетевых запросов. Применение метода главных компонент позволило выделить наиболее значимые параметры, определяющие общую производительность системы, и упростить интерпретацию результатов, демонстрируя, что некоторые параметры тесно связаны и могут рассматриваться как единый фактор, влияющий на общую эффективность виртуализированной среды. Полученные данные позволяют более точно прогнозировать поведение системы и оптимизировать ее ресурсы для достижения максимальной производительности.
Модели регрессии, разработанные для прогнозирования задержки передачи данных (RTT) и использования центрального процессора, продемонстрировали значительное улучшение производительности по большинству оцениваемых параметров после проведения тонкой настройки гиперпараметров. Этот процесс оптимизации позволил выявить оптимальные конфигурации моделей, что привело к повышению точности прогнозов и снижению ошибок. Полученные результаты подтверждают эффективность предложенного подхода к моделированию и указывают на возможность его применения для оптимизации производительности виртуализированных сред. Улучшение показателей свидетельствует о том, что правильно подобранные гиперпараметры играют ключевую роль в достижении высокой точности и эффективности регрессионных моделей, используемых для анализа и прогнозирования системных метрик.
Влияние на 5G и Будущие Сети
Полученные в ходе анализа данные имеют непосредственное применение для оптимизации архитектуры 5G, в значительной степени зависящей от виртуальных сетевых функций (VNF). Эффективное управление ресурсами и снижение задержек в VNF критически важно для обеспечения высокой производительности и масштабируемости сетей нового поколения. Исследование позволяет более точно настраивать параметры виртуализации, такие как выделение CPU и пропускная способность сети, для каждой VNF, что приводит к улучшению общей эффективности сети 5G и более быстрому реагированию на изменяющиеся потребности пользователей. Оптимизация VNF способствует снижению энергопотребления и повышению надежности сети, что является ключевым для поддержки широкого спектра приложений, от мобильной связи до интернета вещей.
Понимание взаимосвязи между временем кругового обхода (RTT), загрузкой центрального процессора (CPU) и технологиями виртуализации имеет решающее значение для обеспечения производительности и масштабируемости будущих сетей. Исследования показывают, что увеличение RTT напрямую влияет на потребление ресурсов CPU в виртуализированных сетевых функциях (VNF). Оптимизация этих параметров требует комплексного подхода, учитывающего как сетевые задержки, так и вычислительные возможности хост-систем. Эффективное управление ресурсами CPU, основанное на мониторинге RTT, позволяет снизить латентность и повысить пропускную способность сети, особенно в условиях высокой нагрузки. Таким образом, глубокий анализ взаимодействия этих факторов является ключевым для разработки и внедрения адаптивных сетевых решений, способных удовлетворять растущим требованиям к скорости и надежности связи.
Данное исследование закладывает основу для разработки интеллектуальных стратегий распределения ресурсов и автоматизированных инструментов оптимизации для облачно-нативных приложений. Полученные результаты позволяют создавать системы, способные динамически адаптироваться к изменяющимся нагрузкам и потребностям приложений, эффективно используя доступные вычислительные мощности. Автоматизация процессов оптимизации, основанная на анализе взаимосвязи между задержкой сети, загрузкой процессора и технологиями виртуализации, открывает возможности для значительного повышения производительности и масштабируемости облачных сервисов, а также снижения эксплуатационных расходов. В перспективе, подобные инструменты могут стать неотъемлемой частью инфраструктуры 5G и будущих сетевых архитектур, обеспечивая стабильную и эффективную работу критически важных приложений.
Исследование, представленное в статье, демонстрирует стремление к упрощению сложной системы виртуализации. Авторы, анализируя данные экспериментов с KVM, Docker и LXC, выявляют ключевые факторы, влияющие на производительность сети. Этот подход к выявлению закономерностей и оптимизации конфигураций перекликается с мыслями Марвина Минского: «Искусственный интеллект — это не создание машин, думающих как люди, а создание машин, которые думают». Подобно тому, как алгоритмы машинного обучения позволяют автоматизировать процесс анализа данных о задержках и загрузке процессора, Минский подчеркивал важность создания систем, способных к рациональному мышлению и решению сложных задач, что особенно актуально в контексте оптимизации облачной инфраструктуры.
Куда же дальше?
Представленная работа, тщательно отсеяв избыточное, обнажает суть проблемы: виртуализация — не панацея, а компромисс. Замеры времени задержки и загрузки процессора, пусть и полезные, лишь касаются поверхности. Истинный вопрос не в том, чтобы зафиксировать эти показатели, а в том, чтобы понять, какие аспекты архитектуры виртуализации неизбежно вносят искажения, и как эти искажения влияют на более сложные вычислительные задачи.
Предложенный набор данных и модели машинного обучения — это, скорее, отправная точка, чем конечная цель. Они позволяют оптимизировать существующие конфигурации, но не предлагают принципиально новых решений. Будущие исследования должны сосредоточиться на динамической адаптации виртуальной среды к меняющимся требованиям приложений, а также на разработке метрик, отражающих не только производительность, но и предсказуемость поведения системы. Иначе говоря, не просто «быстро», а «быстро и надёжно».
Очевидно, что упрощение — это иллюзия. Но в погоне за совершенством необходимо помнить, что каждая добавленная функция — это потенциальный источник проблем. Поэтому, возможно, наиболее перспективным направлением является не создание всё более сложных систем, а поиск способов минимизировать сложность, сохраняя при этом необходимый уровень функциональности. Иногда, чтобы увидеть лес, нужно убрать деревья.
Оригинал статьи: https://arxiv.org/pdf/2602.05792.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Многокритериальная оптимизация: взгляд на народные методы
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Графы и действия: новый подход к планированию для роботов
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальное мышление машин: проверка на прочность
- Искусственный интеллект в медицине: новый уровень самостоятельности
2026-02-08 12:09