Автор: Денис Аветисян
Исследователи представили инновационную систему, способную понимать и связывать информацию из нескольких изображений, используя возможности больших языковых моделей и методы обучения с подкреплением.
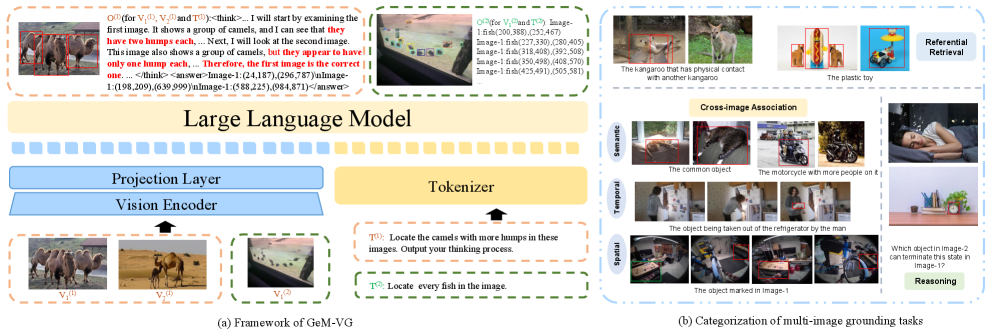
Работа посвящена разработке GeM-VG — мультимодальной большой языковой модели для обобщенной задачи визуального связывания информации по нескольким изображениям.
Несмотря на значительный прогресс в области мультимодальных больших языковых моделей, обобщенное понимание и локализация объектов на нескольких изображениях остается сложной задачей. В данной работе, ‘GeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models’, предложена модель GeM-VG, способная к обобщенному мульти-изображенческому визуальному заземлению благодаря новой стратегии обучения с подкреплением и расширенному набору данных MG-Data-240K. Эксперименты демонстрируют превосходство предложенного подхода, обеспечивая значительное улучшение результатов на стандартных бенчмарках, таких как MIG-Bench и MC-Bench. Какие перспективы открываются для дальнейшего развития моделей, способных к комплексному анализу и взаимодействию с мультимодальными данными?
Понимание Визуального Мира: Вызовы и Перспективы
Традиционные методы визуального связывания сталкиваются со значительными трудностями при анализе нескольких изображений одновременно. Они зачастую не способны эффективно обрабатывать сложные взаимосвязи между объектами, представленными в различных визуальных источниках, что ограничивает их применение в реальных задачах. Например, для робота, ориентирующегося в пространстве, необходимо не просто распознать объект на отдельном изображении, но и отследить его перемещение и взаимодействие с другими объектами на последовательности изображений. Аналогичные сложности возникают в системах видеонаблюдения, где требуется анализ событий, происходящих в разных частях сцены, зафиксированных несколькими камерами. Ограниченность существующих подходов препятствует созданию интеллектуальных систем, способных к комплексному пониманию визуальной информации и принятию обоснованных решений в динамичной среде.
Существующие подходы к обработке изображений часто сталкиваются с трудностями при объединении информации из различных визуальных источников, что негативно сказывается на точности локализации и идентификации объектов. Проблема заключается в том, что модели, как правило, анализируют каждое изображение изолированно, не учитывая контекст и взаимосвязи между ними. Это приводит к неверной интерпретации сцены и затрудняет распознавание объектов, особенно в сложных ситуациях, где требуется учитывать перспективу, освещение и перекрытия. Неспособность эффективно интегрировать визуальную информацию ограничивает возможности систем компьютерного зрения в задачах, требующих целостного понимания окружающей среды, таких как навигация роботов или анализ видеопотоков с камер наблюдения.
Разработка моделей, способных к комплексному пониманию множественных изображений, представляется критически важной для широкого спектра современных приложений. В частности, в робототехнике подобный подход позволит устройствам ориентироваться и взаимодействовать с окружающей средой, основываясь на полной визуальной картине, а не на отдельных фрагментах. Системы видеонаблюдения, оснащенные подобными алгоритмами, смогут более эффективно обнаруживать и отслеживать объекты, анализируя данные, полученные с нескольких камер одновременно. Кроме того, комплексный анализ множественных изображений открывает новые возможности в области анализа сложных сцен, например, при реконструкции трехмерных моделей или автоматическом распознавании событий, требующих понимания контекста и взаимосвязей между различными визуальными элементами.

GeM-VG: Новая Архитектура для Визуального Обоснования
Архитектура GeM-VG использует в качестве основы мощную модель Qwen2-VL-7B, что позволяет ей наследовать её сильные стороны в задачах визуального определения местоположения объектов на одиночных изображениях и понимания содержимого нескольких изображений. Qwen2-VL-7B предварительно обучена на большом объеме данных, что обеспечивает высокую точность и надежность в задачах визуального анализа. Использование данной модели в качестве основы позволяет GeM-VG эффективно решать сложные задачи, требующие понимания контекста и взаимосвязей между объектами на изображениях, а также обобщать полученные знания на новые, ранее не встречавшиеся сценарии.
Архитектура GeM-VG разработана для обобщенного мульти-изображенческого визуального обоснования, что позволяет ей эффективно решать разнообразные задачи и обрабатывать сцены с переменным количеством целевых объектов. В отличие от систем, ориентированных на фиксированное число объектов или узкий спектр задач, GeM-VG способна динамически адаптироваться к различным сценариям, определяя и локализуя несколько объектов на изображениях, независимо от их количества или типа. Это достигается за счет использования механизма, позволяющего модели обрабатывать произвольное число входных объектов и генерировать соответствующие выходные данные, что делает ее применимой к широкому кругу задач, включая поиск объектов, интерактивные сценарии и анализ сложных визуальных сцен.
Архитектура GeM-VG использует два основных подхода к генерации ответов: цепочку рассуждений (Chain-of-Thought, CoT) и прямое предсказание ответа. Метод CoT позволяет модели генерировать промежуточные логические шаги, объясняющие процесс нахождения целевого объекта, что повышает надежность и интерпретируемость результата. Прямое предсказание ответа обеспечивает более быструю генерацию ответов в ситуациях, когда детальное объяснение не требуется. Комбинация этих двух подходов обеспечивает гибкость и эффективность системы, позволяя выбирать оптимальный метод в зависимости от сложности задачи и требований к скорости ответа.
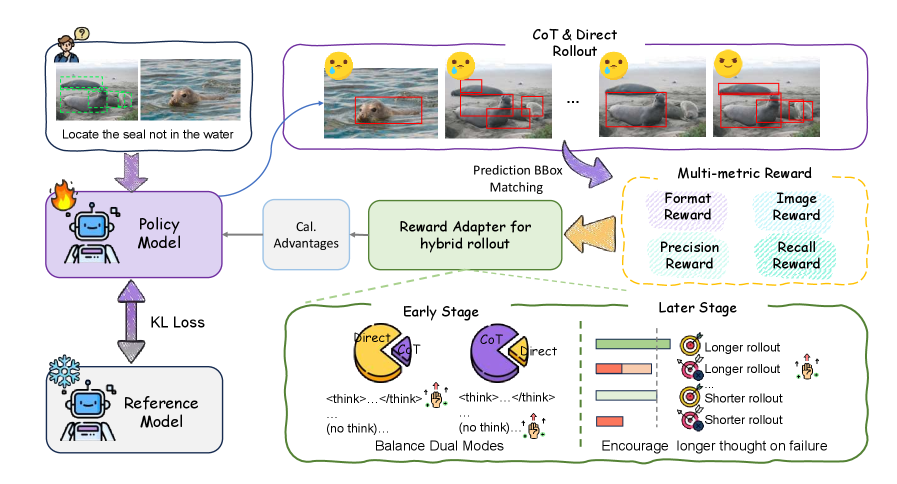
Оптимизация GeM-VG с Использованием Обучения с Подкреплением
Для улучшения возможностей сопоставления с реальностью (grounding) и оптимизации процесса принятия решений в модели GeM-VG был использован метод обучения с подкреплением (Reinforcement Learning), а именно алгоритм GRPO (Guided ReParameterized Policy Optimization). Алгоритм GRPO позволяет модели обучаться на основе получаемых вознаграждений за корректное сопоставление визуальных данных с текстовыми запросами и последующее формирование ответа. В процессе обучения модель настраивает свою политику действий, стремясь максимизировать кумулятивное вознаграждение, что приводит к повышению точности и эффективности при решении задач, требующих понимания визуальной информации и логических рассуждений.
Для повышения точности и эффективности GeM-VG была реализована гибридная стратегия дообучения. Данный подход объединяет преимущества рассуждений на основе цепочки мыслей (Chain-of-Thought, CoT) и прямого предсказания ответов. CoT обеспечивает более глубокий анализ и обоснование ответов, что особенно важно для сложных вопросов. Прямое предсказание ответов, напротив, позволяет сократить время обработки и вычислительные затраты для простых вопросов. Гибридная стратегия динамически переключается между этими двумя режимами, выбирая наиболее оптимальный подход в зависимости от сложности входных данных, что обеспечивает более высокую общую производительность системы.
Для повышения устойчивости и надежности работы GeM-VG была внедрена модуляция вознаграждения. Данный механизм позволяет динамически корректировать сигнал вознаграждения в процессе обучения с подкреплением в зависимости от соотношения различных режимов ответа модели. Это достигается путем учета пропорции ответов, сгенерированных разными способами (например, ответы, основанные на цепочке рассуждений и прямые ответы), и соответствующей корректировки величины вознаграждения. Такой подход позволяет избежать перекоса в сторону одного режима ответа и обеспечить более сбалансированную и надежную работу модели в различных сценариях.
Комплексная Оценка и Результаты на Эталонных Наборах Данных
Комплексная оценка модели GeM-VG проводилась на общепринятых эталонных наборах данных, включающих MC-Bench, MIG-Bench, ODINW-13 и MuirBench, что позволило продемонстрировать её высокую производительность в различных сценариях. Данные тесты охватывают широкий спектр задач, связанных с визуальным обоснованием и пониманием изображений, позволяя объективно оценить возможности модели в решении сложных проблем. Результаты показывают, что GeM-VG демонстрирует стабильную и надежную работу, успешно справляясь с разнообразными типами запросов и изображений, что подтверждает её эффективность и универсальность в области компьютерного зрения.
Обучение модели GeM-VG на масштабном наборе данных MG-Data-240K, предназначенном для задач сопоставления изображений и текстовых запросов, значительно расширило её способность к обобщению. Этот крупномасштабный набор данных позволил модели освоить более широкий спектр визуальных концепций и языковых выражений, что привело к повышению её устойчивости к новым, ранее не встречавшимся сценариям. В результате, GeM-VG демонстрирует улучшенную производительность при решении разнообразных задач, связанных с пониманием и интерпретацией визуальной информации, и способна эффективно применять полученные знания к новым данным, что делает её более надежной и универсальной в различных приложениях.
Результаты всестороннего тестирования демонстрируют, что GeM-VG достигает передового уровня производительности в задаче мультимодального сопоставления изображений и текста. В частности, модель превзошла существующие аналоги на ключевых бенчмарках: на MIG-Bench зафиксировано улучшение на 2.0%, а на MC-Bench — на 9.7%. Примечательно, что на MC-Bench GeM-VG значительно опережает Migician на 9.7% и Qwen2VL-7B на 12.6%, что подтверждает ее способность к более точному и эффективному пониманию визуальной информации и ее связи с текстовыми запросами. Данные показатели свидетельствуют о значительном прогрессе в области мультимодальных моделей и открывают новые возможности для решения сложных задач, требующих интеграции визуального и текстового контента.
Исследования показали значительное улучшение производительности GeM-VG на эталонных наборах данных ODINW-13 и MuirBench. В частности, при тестировании на ODINW-13, GeM-VG продемонстрировал в среднем на 9.1% более высокие результаты по сравнению с базовой моделью, что свидетельствует о существенном прогрессе в задачах визуального обоснования. Более того, в рамках MuirBench Counting Score, GeM-VG превзошел Migician на 5.55%, подтверждая его способность к более точной идентификации и подсчету объектов на изображениях. Эти результаты подчеркивают эффективность GeM-VG в сложных сценариях визуального анализа и открывают новые возможности для развития систем, требующих надежного понимания изображений.

Исследование, представленное в данной работе, демонстрирует значительный прогресс в области мультимодального понимания изображений. Авторы предлагают GeM-VG, модель, использующую обучение с подкреплением для решения задач визуального заземления на нескольких изображениях. Эта стратегия позволяет модели не просто идентифицировать объекты, но и устанавливать ассоциации между ними на разных изображениях, что является ключевым аспектом визуального мышления. Как однажды заметил Ян Лекун: «Машинное обучение — это, прежде всего, обучение представлений». GeM-VG успешно воплощает эту идею, создавая эффективные представления для сложных задач мультимодального анализа, что подтверждается достижением передовых результатов на специализированном наборе данных.
Что дальше?
Представленная работа, демонстрируя впечатляющие результаты в задаче мульти-образного визуального заземления, неизбежно поднимает вопрос о границах достигнутого. Несмотря на успешное применение обучения с подкреплением и создание нового набора данных, остаётся открытым вопрос о генерализации полученных моделей к совершенно иным, не представленным в обучающей выборке, типам визуальной информации. Ведь, как показывает практика, каждая тщательно сконструированная «реальность» в наборе данных — лишь бледное отражение хаотичной сложности окружающего мира.
Более того, понимание «заземления» в контексте нескольких изображений требует не просто идентификации объектов, но и выявления тонких связей между ними. Предлагаемая архитектура, безусловно, делает шаг в этом направлении, однако остается неясным, способна ли она уловить сложные причинно-следственные связи или, скажем, иронию, заложенную в композиции нескольких визуальных элементов. Разработка метрик для оценки подобных «когнитивных» способностей представляется не менее важной задачей, чем повышение численных показателей точности.
В перспективе, представляется плодотворным исследование возможности интеграции моделей, подобных GeM-VG, с системами активного обучения, позволяющими им самостоятельно формулировать вопросы и проводить эксперименты для уточнения понимания визуального мира. Возможно, только так удастся преодолеть неизбежные ограничения, присущие любому конечному набору данных, и приблизиться к созданию действительно «обобщенного» интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2601.04777.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2026-01-11 19:05