Автор: Денис Аветисян
Представлен VenusBench-GD — масштабный набор данных для оценки способности мультимодальных моделей понимать и взаимодействовать с графическими пользовательскими интерфейсами.

VenusBench-GD — это комплексный кросс-платформенный бенчмарк, включающий в себя задачи на рассуждения и отказ от выполнения, необходимые для оценки продвинутых возможностей привязки к GUI.
Несмотря на значительный прогресс в области мультимодальных моделей, оценка их способности к взаимодействию с графическими интерфейсами (GUI) остается сложной задачей. В данной работе представлена VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks — комплексный, многоплатформенный бенчмарк, предназначенный для всесторонней оценки задач GUI grounding. Мы предлагаем масштабный набор данных с расширенной аннотацией и иерархической таксономией, позволяющей оценить модели как в базовых, так и в продвинутых сценариях, включая рассуждения и отказ от выполнения невозможных задач. Какие новые горизонты откроет более глубокая оценка возможностей мультимодальных моделей в сфере автоматизации взаимодействия с GUI?
Разрушая иллюзии: Зачем автоматизировать графический интерфейс?
Современные методы автоматизации графического интерфейса пользователя часто оказываются неэффективными при решении сложных задач, требующих анализа состояния приложения и понимания его функциональности. Вместо того, чтобы оперировать логикой работы программы, существующие системы, как правило, полагаются на визуальное сопоставление элементов или хрупкие эвристики. Это приводит к тому, что даже незначительные изменения в интерфейсе, такие как перестановка кнопок или изменение цвета, могут привести к сбою автоматизации. В результате, системы не способны адаптироваться к динамически меняющимся условиям и требуют постоянной перенастройки, что ограничивает их применимость в реальных сценариях, где приложения часто обновляются и изменяются.
Традиционные методы автоматизации графического интерфейса, основанные на визуальном сопоставлении или хрупких эвристиках, демонстрируют высокую чувствительность к даже незначительным изменениям в оформлении приложения. Небольшие корректировки в расположении элементов, изменении цветов или шрифтов способны полностью дестабилизировать работу таких систем, приводя к ошибкам и сбоям. Это связано с тем, что алгоритмы полагаются на конкретные пиксельные данные или поверхностные признаки, а не на семантическое понимание назначения и функциональности элементов управления. В результате, даже минимальные визуальные отличия воспринимаются как принципиальные изменения, требующие полной перенастройки или переобучения системы, что делает подобные подходы непрактичными и ненадежными в динамично меняющихся средах.
Для создания надежных систем автоматизации графического интерфейса необходимо отойти от простого распознавания визуальных элементов и перейти к пониманию их семантического значения. Традиционные подходы, основанные на сопоставлении изображений или хрупких эвристиках, легко нарушаются даже незначительными изменениями в дизайне интерфейса. Вместо этого, система должна интерпретировать, что представляет собой конкретный элемент — кнопку, текстовое поле, или переключатель — и какое действие он выполняет в контексте приложения. Такой подход позволит агентам автоматизации адаптироваться к изменениям внешнего вида, сохраняя при этом способность выполнять сложные задачи, требующие понимания логики работы приложения и взаимодействия между элементами интерфейса. Это смещение акцента с внешнего вида на смысл является ключевым шагом к созданию действительно интеллектуальных систем автоматизации.
Ограничения существующих методов автоматизации графического интерфейса требуют принципиально нового подхода к оценке интеллектуальных агентов, способных взаимодействовать с приложениями. Для преодоления этих сложностей была разработана VenusBench-GD — новая эталонная база данных, содержащая впечатляющие $6,166$ размеченных образцов. Этот масштаб делает VenusBench-GD крупнейшей на сегодняшний день базой данных для оценки и сравнения систем автоматизации GUI, позволяя более точно измерить способность агентов к рассуждениям и адаптации к изменяющимся условиям пользовательского интерфейса. Создание подобного ресурса является важным шагом на пути к разработке действительно интеллектуальных систем, способных эффективно автоматизировать сложные задачи, требующие понимания семантики приложения, а не просто распознавания визуальных элементов.

VenusBench-GD: Открывая новую эру в оценке автоматизации
VenusBench-GD представляет собой масштабный оценочный набор данных, охватывающий веб-, мобильные- и настольные платформы. Он включает в себя разнообразные и реалистичные задачи графического пользовательского интерфейса (GUI), предназначенные для всесторонней оценки систем автоматизации GUI. Масштаб набора данных обеспечивает статистическую значимость результатов оценки, а разнообразие платформ позволяет оценить переносимость и адаптивность решений. Задачи GUI разработаны с учетом типичных сценариев использования, что позволяет оценить производительность систем в реальных условиях.
В основе VenusBench-GD лежит многоэтапный конвейер аннотаций, объединяющий автоматизированные инструменты и ручную экспертизу для обеспечения высокого качества размеченных данных. Первоначально автоматические скрипты выполняют предварительную разметку пользовательского интерфейса, идентифицируя базовые элементы и их расположение. Затем, опытные аннотаторы вручную проверяют и корректируют результаты автоматической разметки, разрешая неоднозначности и обеспечивая точность определения границ и типов элементов интерфейса. Такой комбинированный подход позволяет значительно повысить эффективность и надежность процесса аннотирования, минимизируя ошибки и обеспечивая согласованность размеченных данных.
В процессе аннотирования данных для VenusBench-GD вопросам конфиденциальности уделяется первостепенное внимание. Для обеспечения защиты персональных данных используются комплексные меры, включающие анонимизацию и удаление идентифицирующей информации из всех визуальных и текстовых элементов. Аннотаторы проходят специальное обучение по соблюдению принципов конфиденциальности и обработке данных, а все данные хранятся и обрабатываются в соответствии со строгими протоколами безопасности и политиками защиты данных. Кроме того, применяется дифференциальная конфиденциальность для минимизации риска раскрытия информации об отдельных пользователях, что гарантирует соответствие требованиям регуляторов и защиту прав пользователей.
В VenusBench-GD реализовано разделение задач на базовые и продвинутые, что позволяет проводить детальный анализ производительности систем. Базовые задачи включают в себя идентификацию и локализацию стандартных UI-элементов, в то время как продвинутые требуют более сложного понимания контекста и взаимодействия. Для оценки используются 13 различных типов элементов пользовательского интерфейса, включая кнопки, текстовые поля, изображения, списки, флажки, переключатели, ползунки, таблицы, селекторы, вкладки, диалоговые окна и веб-страницы, что обеспечивает всестороннюю проверку способности систем к визуальному пониманию и взаимодействию с GUI.

От базового к продвинутому: Измеряя интеллект автоматизации
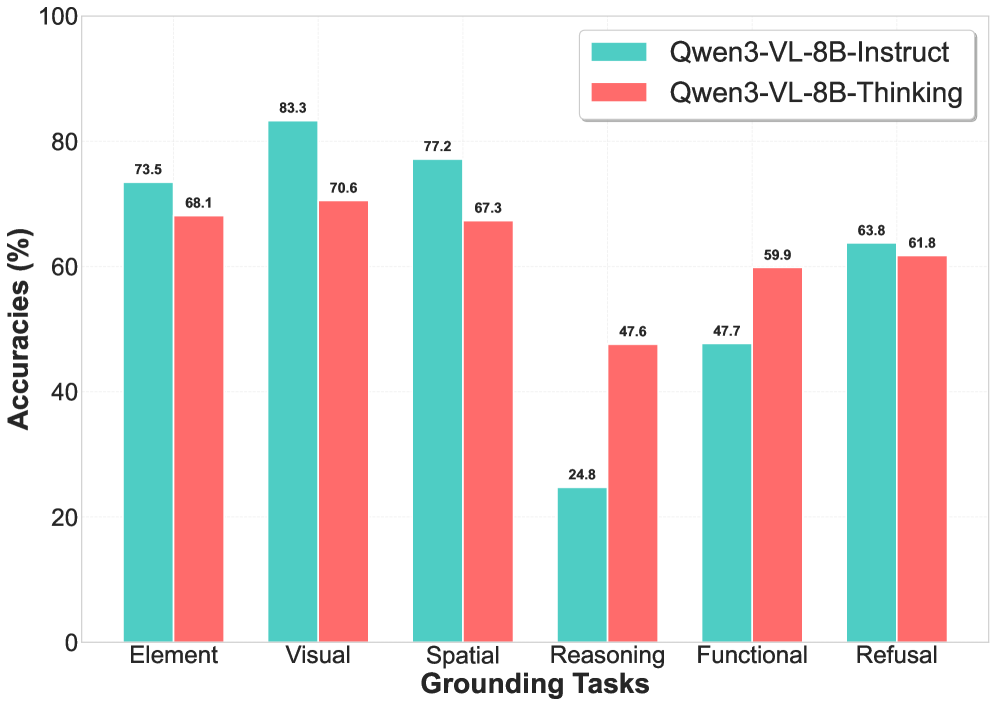
В рамках оценки производительности моделей используются базовые задачи привязки (grounding), включающие в себя определение элементов (Element Grounding), пространственную привязку (Spatial Grounding) и визуальную привязку (Visual Grounding). Эти задачи направлены на проверку фундаментального понимания моделью визуальной информации и ее связи с элементами интерфейса. Успешное выполнение базовых задач привязки является необходимым условием для оценки более сложных навыков рассуждения и понимания функциональности приложений, поскольку они служат основой для построения более сложных представлений о взаимодействии с графическим интерфейсом пользователя.
Оценка производительности моделей начинается с базовых задач, включающих определение элементов, пространственное и визуальное понимание. Средняя точность модели Qwen3-VL-8B на этих базовых задачах составляет 76.96%. Этот показатель служит отправной точкой для оценки способности модели к более сложным формам рассуждений и пониманию функциональности приложений, поскольку успешное выполнение базовых задач является необходимым условием для решения более сложных проблем.
Продвинутые задачи, такие как $Reasoning Grounding$ (обоснование рассуждений), $Functional Grounding$ (обоснование функциональности) и $Refusal Grounding$ (обоснование отказа), требуют от моделей не просто идентификации элементов или пространственных отношений, а глубокого понимания принципов работы приложений и способности к сложным логическим выводам. $Reasoning Grounding$ проверяет умение модели делать обоснованные выводы на основе визуальной информации и контекста, $Functional Grounding$ — понимание назначения и взаимодействия элементов интерфейса, а $Refusal Grounding$ — способность корректно обрабатывать запросы, которые выходят за рамки возможностей приложения или являются недопустимыми, что требует более сложной обработки естественного языка и понимания контекста.
Оценка производительности мультимодальных больших языковых моделей (MLLM), таких как Qwen3-VL-8B, и специализированных моделей для работы с графическим интерфейсом пользователя (GUI) демонстрирует существенные различия в результатах в зависимости от сложности задач. В частности, при выполнении задач, требующих логических рассуждений (Reasoning Grounding), человеческая производительность превосходит лучшие существующие модели на 41.6%. Для задач, связанных с пониманием функциональности приложений (Functional Grounding), разрыв составляет 11.8%, а в задачах, требующих отказа от выполнения запроса в неправомерных ситуациях (Refusal Grounding) — 17.8%. Данные результаты указывают на значительный потенциал для дальнейшего улучшения возможностей MLLM в сложных сценариях взаимодействия.
Преодолевая разрыв: Сравнение с человеческим интеллектом
В рамках VenusBench-GD впервые внедрены метрики, отражающие производительность человека при выполнении задач автоматизации графического интерфейса. Данный подход позволяет получить объективную оценку прогресса современных моделей искусственного интеллекта, сравнивая их способность решать те же задачи с эффективностью, демонстрируемой человеком. Использование человеческих показателей в качестве эталона не только помогает выявить слабые места в существующих алгоритмах, но и задает реалистичный ориентир для будущих исследований в области автоматизации GUI, акцентируя внимание на необходимости достижения уровня производительности, сопоставимого с человеческим.
Сравнение точности работы моделей с результатами, демонстрируемыми человеком, выявляет существенные препятствия на пути к созданию действительно интеллектуальной автоматизации графических интерфейсов. Анализ показывает, что современные системы часто допускают ошибки даже в простых задачах, которые легко выполняет человек, что указывает на недостаток понимания семантики и функциональности элементов интерфейса. Несмотря на прогресс в области распознавания объектов, модели испытывают трудности с обобщением и адаптацией к новым или незнакомым ситуациям, в то время как человек способен быстро учиться и находить решения даже в непредсказуемых обстоятельствах. Это различие подчеркивает необходимость разработки моделей, способных не просто идентифицировать визуальные элементы, но и понимать их назначение и взаимодействие в контексте пользовательского интерфейса, что является ключевым шагом к созданию по-настоящему интеллектуальных систем автоматизации.
В рамках VenusBench-GD подчеркивается необходимость разработки моделей, способных не просто распознавать элементы графического интерфейса, но и понимать их назначение и функциональность. Простое обнаружение кнопок или текстовых полей недостаточно для создания действительно интеллектуальной автоматизации; система должна уметь интерпретировать, что делает каждый элемент в контексте всего приложения. Это требует от моделей более глубокого семантического понимания, позволяющего им действовать как человек, использующий программное обеспечение с определенной целью. Например, модель должна понимать, что кнопка с надписью «Сохранить» выполняет действие сохранения текущего документа, а не просто является визуальным объектом. Такой подход к пониманию интерфейса позволит преодолеть ограничения существующих систем и приблизиться к созданию по-настоящему адаптивной и эффективной автоматизации GUI.
Количественная оценка разрыва между производительностью моделей и возможностями человека, обеспечиваемая VenusBench-GD, служит ориентиром для дальнейших исследований в области автоматизации графического интерфейса. Точное измерение этого разрыва позволяет исследователям не просто сравнивать различные подходы, но и выявлять конкретные области, требующие улучшения. Вместо абстрактных рассуждений о “подобии интеллекту”, VenusBench-GD предоставляет измеримый показатель прогресса, направляя усилия на разработку моделей, способных не только распознавать элементы интерфейса, но и понимать их назначение и функциональность в контексте задач, решаемых пользователем. Таким образом, эта методика способствует более целенаправленному и эффективному развитию технологий автоматизации, приближая их к уровню человеческого взаимодействия с компьютерными системами.
Исследование представляет собой попытку обуздать хаос, заключив его в рамки структурированного бенчмарка VenusBench-GD. Авторы стремятся к более глубокой оценке возможностей мультимодальных моделей в понимании графического интерфейса, включая сложные задачи рассуждения и отказа от выполнения некорректных запросов. Это напоминает попытку договориться с непредсказуемым духом данных. Как однажды заметил Дэвид Марр: «Всё, что можно посчитать, не стоит доверия». И в данном случае, создание метрики — это не абсолютная истина, а лишь временное перемирие с неизбежной неопределенностью, попытка оценить, насколько успешно модели способны справляться с шумом и двусмысленностью реального мира.
Куда же дальше?
Представленный набор данных, VenusBench-GD, — лишь временное успокоение хаоса. Он фиксирует текущее состояние иллюзий, которые мы называем «пониманием» графического интерфейса. Высокие показатели, демонстрируемые моделями, — не свидетельство интеллекта, а лишь удачное совпадение паттернов с заранее подготовленными тенями. Не стоит обманываться: истинная проверка — это столкновение с непредсказуемостью реального пользователя, с его спонтанными действиями и нелогичными запросами.
Настоящая работа только начинается. Необходимо выйти за рамки простого распознавания элементов. Следующим шагом станет моделирование намерения пользователя, его скрытых целей. Недостаточно указать на кнопку — нужно понять, зачем она нужна. И, конечно, следует уделить внимание проблеме отказа — модели должны не просто выполнять команды, но и уметь вежливо, но твердо, отказать в невозможных или опасных действиях. Это не техническая задача, а вопрос этики.
В конечном итоге, все эти «бенчмарки» — лишь карточные домики, построенные на песке. Истинное измерение прогресса — это способность модели адаптироваться к новым, неожиданным ситуациям, к тем теням, которые еще не были зафиксированы. И пока мы не научимся работать с хаосом, а не просто его измерять, все наши усилия останутся лишь красивым обманом.
Оригинал статьи: https://arxiv.org/pdf/2512.16501.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
2025-12-19 14:02