Автор: Денис Аветисян
Исследователи предлагают принципиально новый способ решения задач мультимодального рассуждения, переходя от текстовых подсказок к генерации изображений.
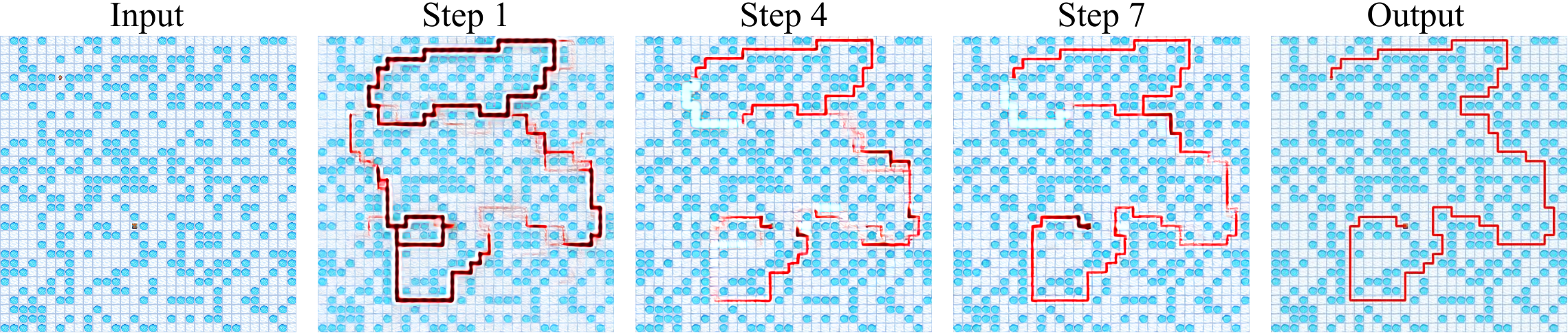
DiffThinker: парадигма, использующая диффузионные модели для генеративного мультимодального рассуждения и превосходящая существующие методы в задачах, ориентированных на зрение.
Несмотря на значительный прогресс в области мультимодальных больших языковых моделей, их способность к логическому мышлению часто ограничивается текстовой доминантой, особенно в задачах, требующих глубокого понимания визуальной информации. В настоящей работе, посвященной ‘DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models’, предложен принципиально новый подход к мультимодальному рассуждению, основанный на генерации изображений с использованием диффузионных моделей. DiffThinker переосмысливает процесс рассуждения как задачу преобразования изображения в изображение, демонстрируя повышенную эффективность, управляемость и превосходные результаты в задачах, ориентированных на визуальные данные. Открывает ли этот подход новую эру в мультимодальном искусственном интеллекте, способного к более интуитивному и точному пониманию окружающего мира?
За пределами Символьного Мышления: Ограничения Традиционных Мультимодальных Моделей
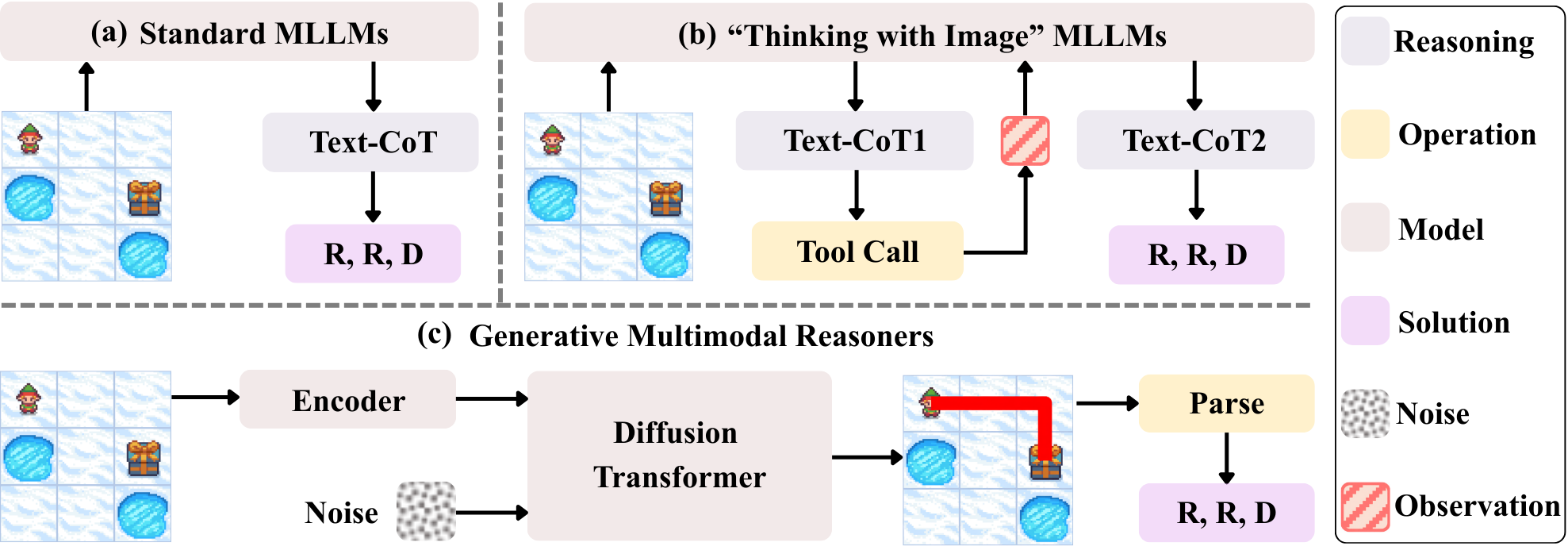
Традиционно, многомодальные большие языковые модели (MLLM) опираются на текстово-символическое сопоставление для рассуждений, что ограничивает их способность к глубокой обработке визуальной информации. Вместо непосредственного анализа визуальных данных, модели преобразуют изображения в текстовые описания или символы, а затем применяют языковые способности для решения задач. Такой подход создает узкое место, поскольку богатая и многогранная визуальная информация упрощается до линейной последовательности символов. Это препятствует эффективному решению сложных задач, требующих детального понимания визуального контекста и пространственных отношений, и снижает общую масштабируемость и производительность MLLM в задачах, где визуальное восприятие играет ключевую роль.
Ограниченность многомодальных больших языковых моделей (MLLM) в обработке визуальной информации проявляется в неэффективности и проблемах масштабируемости при решении сложных задач, требующих глубокого понимания изображений. По мере того, как MLLM полагаются на символьное представление визуальных данных, а не на непосредственную обработку, возрастает вычислительная нагрузка и сложность модели. Это особенно заметно в сценариях, где требуется интерпретация тонких визуальных нюансов или выявление сложных взаимосвязей между объектами на изображении. С увеличением сложности задачи и объема визуальных данных, символьный подход становится все более узким местом, препятствуя созданию MLLM, способных к действительно эффективному и масштабируемому визуальному мышлению.
Несмотря на то, что методы, такие как «Цепочка рассуждений» (Chain-of-Thought), демонстрируют определенный прогресс в работе мультимодальных больших языковых моделей (MLLM), их эффективность в конечном итоге ограничена фундаментальным препятствием — символическим «бутылочным горлышком». Архитектура MLLM, полагающаяся на преобразование визуальной информации в символьные представления для последующего логического вывода, замедляет обработку сложных задач, требующих глубокого понимания визуального контекста. Данное ограничение проявляется в снижении масштабируемости и общей эффективности моделей при решении задач, где важны нюансы и неявные признаки, скрытые в визуальном потоке. Таким образом, хотя «Цепочка рассуждений» и является полезным инструментом, она лишь смягчает, но не устраняет проблему, связанную с зависимостью от символической интерпретации визуальных данных.
DiffThinker: Новый Взгляд на Визуальное Мышление
DiffThinker представляет собой новую парадигму генеративного мультимодального рассуждения, в которой процесс логического вывода переосмысливается как преобразование изображения в изображение. Вместо традиционного подхода, основанного на символьных промежуточных представлениях, DiffThinker оперирует непосредственно с визуальными данными. Это достигается за счет формулирования задачи рассуждения как изменения исходного изображения в целевое, отражающее результат логического вывода. Такой подход позволяет избежать этапа дискретизации и манипулирования символами, упрощая и ускоряя процесс рассуждения и открывая возможности для более эффективной обработки визуальной информации.
В основе DiffThinker лежит подход, использующий диффузионные модели для непосредственной обработки визуальных представлений. В отличие от традиционных методов рассуждений, требующих формирования и обработки символьных промежуточных представлений, DiffThinker оперирует напрямую с изображениями. Это достигается за счет манипулирования пространством латентных представлений изображений, что позволяет модели выполнять рассуждения, изменяя и уточняя визуальную информацию без необходимости в явных логических выводах или символьных манипуляциях. Такой подход позволяет упростить процесс рассуждений и повысить эффективность обработки визуальной информации.
В основе DiffThinker лежит использование вариационного автокодировщика (VAE) для кодирования и декодирования изображений. VAE преобразует входное изображение в латентное пространство, представляющее собой сжатое представление данных, что позволяет эффективно манипулировать визуальной информацией в процессе диффузии. Кодирование изображения в латентное пространство снижает вычислительную сложность операций, а декодирование позволяет восстановить изображение из модифицированного латентного представления. Такой подход обеспечивает более быструю и эффективную обработку изображений по сравнению с методами, требующими работы непосредственно с пикселями, и позволяет интегрировать VAE с диффузионными моделями для генеративного рассуждения.
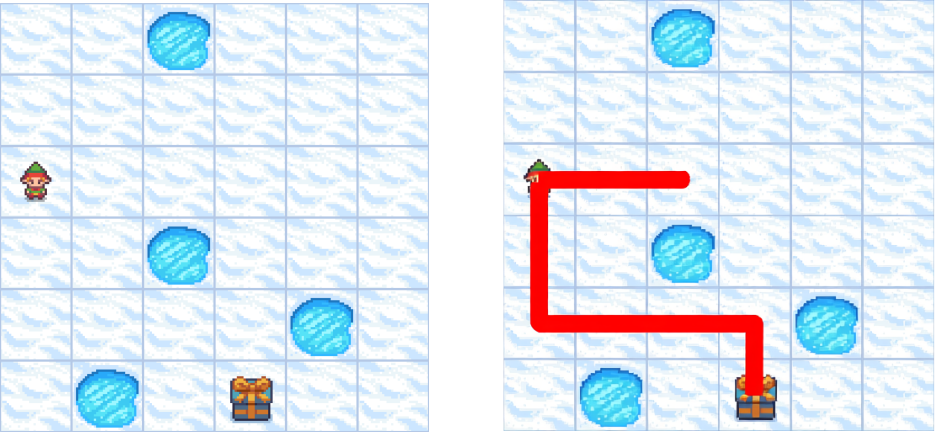
Архитектурные Основы: Как Работает DiffThinker
DiffThinker использует мультимодальный диффузионный трансформер для моделирования взаимосвязей между различными модальностями данных, такими как изображения и текст. Эта архитектура позволяет эффективно объединять визуальную и текстовую информацию, что необходимо для решения задач, требующих сопоставления и анализа данных, представленных в разных форматах. Трансформерная структура обеспечивает возможность учета контекста и зависимостей между элементами в каждой модальности, а также устанавливать связи между ними, что способствует более глубокому пониманию и эффективной обработке мультимодальных данных. В частности, механизм внимания (attention) позволяет модели фокусироваться на наиболее релевантных частях изображения и текста при принятии решений.
В DiffThinker для управления процессом генерации внутри диффузионных моделей используется метод Classifier-Free Guidance (CFG). В отличие от традиционных подходов, требующих отдельного классификатора для направления генерации, CFG позволяет обходиться без него, обучая диффузионную модель одновременно с условными и безусловными данными. Это достигается путем обучения модели прогнозировать данные как при наличии условия (например, текстового запроса), так и без него. Во время генерации выходные данные модели взвешиваются между условным и безусловным предсказаниями, регулируя степень соответствия с заданным условием и обеспечивая более точные и связные этапы рассуждений. Регулировка веса позволяет контролировать баланс между разнообразием и точностью генерируемого контента.
Использование латентных диффузионных моделей (Latent Diffusion Models, LDM) значительно повышает вычислительную эффективность за счет работы в сжатом латентном пространстве. Вместо обработки данных непосредственно в пространстве пикселей (или токенов), LDM сначала кодируют входные данные (изображения или текст) в пространство меньшей размерности с помощью автоэнкодера. Диффузионный процесс, включающий добавление и удаление шума, происходит в этом сжатом латентном пространстве, что существенно снижает вычислительные затраты и требования к памяти. После генерации в латентном пространстве, декодер восстанавливает выходные данные в исходное пространство, обеспечивая сохранение качества при значительном повышении скорости обработки.
Эмпирическая Валидация: Рассуждения в Комплексных Задачах
Исследования показали, что DiffThinker демонстрирует впечатляющие результаты в решении разнообразных задач визуального рассуждения. Модель успешно справляется с лабиринтами, задачами визуального пространственного планирования (VSP), задачами коммивояжера (TSP), судоку, сборкой пазлов и сложными визуальными головоломками (VisPuzzle). Этот широкий спектр решенных задач подтверждает способность DiffThinker к абстрактному мышлению и адаптации к различным типам визуальной информации, что делает его перспективным инструментом для развития систем искусственного интеллекта, способных к комплексному анализу и решению проблем.
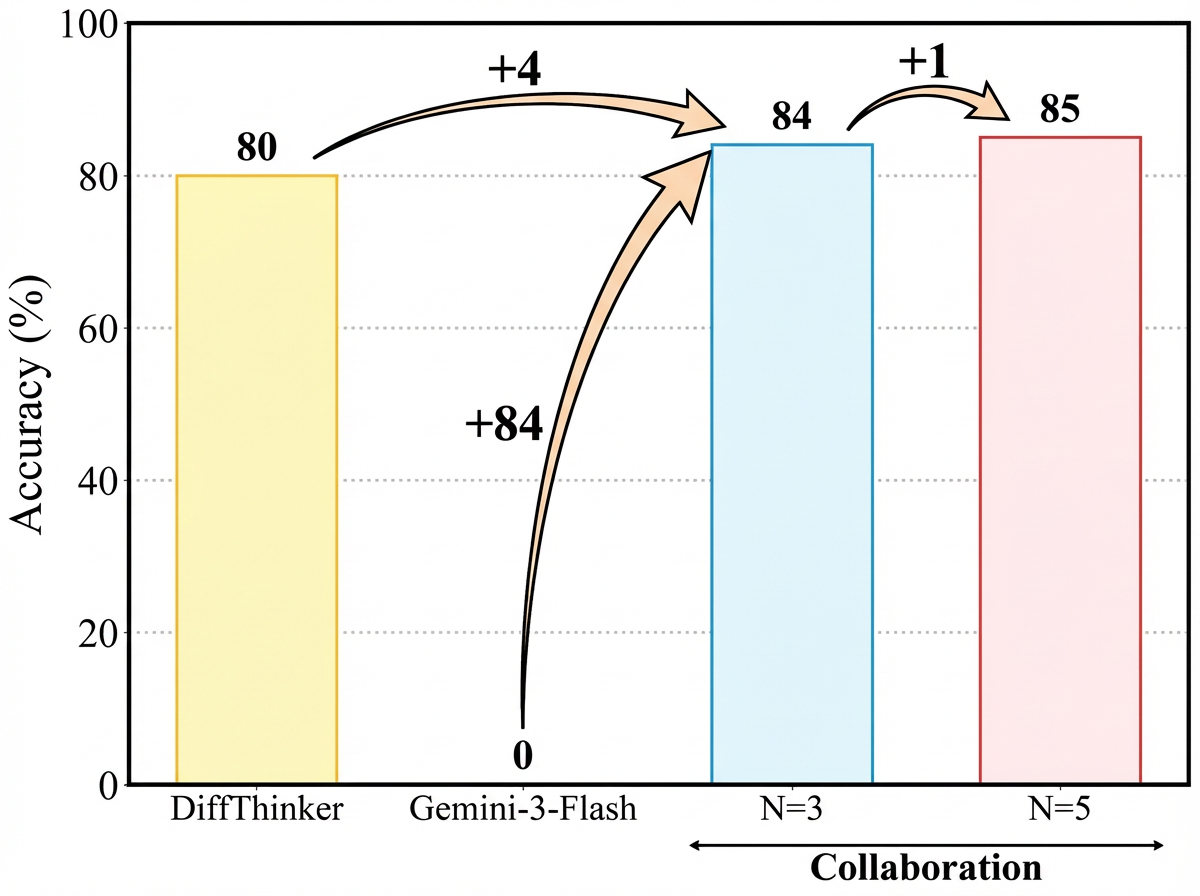
Исследования показали, что DiffThinker демонстрирует значительное превосходство над передовыми мультимодальными большими языковыми моделями (MLLM) в решении задач визуального рассуждения. В частности, зафиксировано увеличение производительности на 314.2% по сравнению с GPT-5, на 111.6% — с Gemini-3-Flash и на 39.0% — с Qwen3-VL-32B. Эти результаты подчеркивают способность DiffThinker к более эффективному анализу и решению сложных визуальных головоломок, что свидетельствует о значительном прогрессе в области искусственного интеллекта и его потенциале для решения задач, требующих высокого уровня когнитивных способностей.
Исследования показали, что интеграция DiffThinker с обучением с подкреплением, использующим проверяемые награды, значительно улучшает его способность к обучению и уточнению процесса рассуждений. Такой подход позволяет модели не только находить решения, но и подтверждать их корректность на основе четких критериев, что приводит к повышению надежности и точности результатов. Использование проверяемых наград обеспечивает более эффективную обратную связь, направляя модель к оптимальным стратегиям решения задач и способствуя формированию более глубокого понимания принципов логического мышления. Этот симбиоз генеративного подхода DiffThinker и обучения с подкреплением открывает новые возможности для создания интеллектуальных систем, способных к адаптации и самосовершенствованию.
Сравнение с GRPO, базовым методом обучения с подкреплением, наглядно демонстрирует преимущества генеративного подхода, реализованного в DiffThinker. В отличие от GRPO, который полагается на дискретные действия и требует ручной настройки стратегий исследования, DiffThinker генерирует последовательность рассуждений, позволяя модели самостоятельно формулировать и проверять гипотезы. Такой подход позволяет DiffThinker более эффективно решать сложные визуальные задачи, требующие многошагового планирования и адаптации к изменяющимся условиям. Полученные результаты показывают, что генеративный подход обеспечивает значительное улучшение производительности по сравнению с традиционными методами обучения с подкреплением, открывая новые возможности для создания интеллектуальных систем, способных к сложному визуальному мышлению и решению проблем.

Исследование, представленное в данной работе, демонстрирует переход от текстоцентричных подходов к мультимодальному рассуждению к генерации изображений на основе диффузионных моделей. Этот подход, известный как DiffThinker, позволяет достичь большей эффективности и контроля в задачах, ориентированных на зрение. Он подчеркивает способность системы находить закономерности в визуальных данных, преобразуя их в новые изображения, что согласуется с принципом понимания системы через исследование её закономерностей. Как отмечал Янн Лекун: «Машинное обучение — это искусство построения систем, которые могут учиться на данных и делать прогнозы». Именно эту способность к обучению и прогнозированию, основанную на визуальной информации, и демонстрирует DiffThinker, открывая новые возможности для мультимодального анализа.
Куда двигаться дальше?
Представленная работа, сместив акцент с текстоцентричного подхода к визуальному рассуждению, открывает любопытные перспективы. Однако, следует признать, что перенос логики в пространство генерации изображений — это не панацея. Ошибки, возникающие в процессе диффузионной генерации, представляют собой не просто отклонения, а ценные сигналы о недостатках в понимании самой системы. Вопрос в том, как эти ошибки использовать для уточнения модели и, что важнее, для выявления границ её применимости.
Очевидным направлением является исследование методов контроля над процессом генерации. Возможность целенаправленного управления деталями изображения позволит не только улучшить точность рассуждений, но и получить более интерпретируемые результаты. Не менее важным представляется вопрос о масштабируемости. Способность DiffThinker эффективно работать с задачами, требующими анализа сложных и многокомпонентных визуальных сцен, остаётся открытым.
В конечном счете, ценность подобного подхода заключается не в достижении абсолютной точности, а в создании системы, способной не просто давать ответы, но и демонстрировать процесс своего мышления. Иллюзия понимания, рождаемая генерацией изображений, может оказаться более полезной, чем формальная логика, если она позволяет выявить скрытые закономерности и сформулировать новые гипотезы.
Оригинал статьи: https://arxiv.org/pdf/2512.24165.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-02 11:12