Автор: Денис Аветисян
Исследователи представили комплексную оценку возможностей современных мультимодальных моделей в решении задач, требующих визуального и пространственного мышления, основанных на реальных школьных заданиях.
Оценка мультимодальных больших языковых моделей на задачах визуального рассуждения, адаптированных из начальной школы, выявляет пробелы в пространственном мышлении и подчеркивает потребность в моделях, способных к более глубокому визуальному пониманию.
Несмотря на значительные успехи в текстовом обосновании, способность искусственного интеллекта к пространственному и реляционному мышлению остается критическим препятствием, особенно в задачах начальной математики, где визуальные элементы играют ключевую роль. В данной работе представлена новая методика оценки — ‘Visual Reasoning Benchmark: Evaluating Multimodal LLMs on Classroom-Authentic Visual Problems from Primary Education’ — включающая в себя набор из 701 вопроса, взятых из школьных экзаменов Замбии и Индии, для проверки мультимодальных больших языковых моделей (MLLM) в решении задач визуального мышления. Исследование выявило, что модели демонстрируют лучшие результаты в статических навыках, таких как подсчет и масштабирование, но сталкиваются с ограничениями в динамических операциях, таких как складывание, отражение и вращение. Как обеспечить надежную работу мультимодальных инструментов в классе и избежать неправильной оценки или закрепления ложных представлений у учеников?
Визуальное Рассуждение: За Иллюзией Поверхностного Соответствия
Несмотря на значительный прогресс в разработке мультимодальных больших языковых моделей (MLLM), истинное визуальное рассуждение остается сложной задачей, часто скрываемой за поверхностным сопоставлением образов. Эти модели, демонстрирующие впечатляющие результаты в распознавании объектов и простых визуальных сценариях, зачастую не способны к глубокому анализу, требующему понимания пространственных отношений, причинно-следственных связей и абстрактных концепций, представленных на изображениях. Вместо реального «зрения» и логического вывода, многие MLLM полагаются на статистические закономерности в данных, что приводит к ошибкам в более сложных задачах, где требуется не просто идентифицировать объекты, но и интерпретировать их взаимодействие и контекст. Таким образом, кажущийся успех в решении визуальных задач может быть иллюзией, основанной на способности модели находить корреляции, а не на истинном понимании визуальной информации.
Современные мультимодальные большие языковые модели (MLLM) демонстрируют трудности при решении задач, требующих сложного пространственного мышления и абстрактного визуального вывода. Исследования показывают, что модели зачастую полагаются на поверхностное сопоставление шаблонов, не понимая истинных взаимосвязей между объектами и их расположением в пространстве. Это указывает на фундаментальное ограничение в перцептивных возможностях моделей — неспособность полноценно обрабатывать и интерпретировать визуальную информацию, выходящую за рамки простых визуальных признаков. В результате, модели испытывают затруднения в задачах, требующих понимания причинно-следственных связей, логического анализа визуальных сцен и экстраполяции знаний на новые, незнакомые ситуации, что представляет собой серьезную проблему для их применения в реальных условиях.
Учебные материалы, используемые в реальных образовательных условиях, представляют собой сложную визуальную среду, насыщенную деталями и отвлекающими факторами. Эта естественная «зашумленность» изображений, диаграмм и иллюстраций значительно усугубляет существующие ограничения современных мультимодальных моделей. В отличие от тщательно отобранных и очищенных датасетов, используемых для обучения, реальные материалы часто содержат нечеткие изображения, перекрывающиеся объекты и вариации освещения, что требует от моделей не просто распознавания образов, а глубокого понимания визуальной информации и способности к надежной обработке сложных сцен. Таким образом, способность эффективно анализировать и интерпретировать визуально сложные и зашумленные данные становится критически важным условием для создания действительно интеллектуальных образовательных систем.

Оценка Пространственного Мышления: От Абстракции к Реальным Задачам
Существующие эталоны оценки, такие как Abstraction and Reasoning Corpus (ARC), предоставляют ценные данные о способности к абстрактному визуальному мышлению, однако им не хватает контекстной реалистичности, характерной для задач, используемых в школьной практике. ARC концентрируется на выявлении базовых принципов решения задач, оперируя упрощенными, деконтекстуализированными визуальными элементами. В отличие от этого, школьные задания, как правило, требуют применения этих принципов в конкретных, реалистичных ситуациях, что подразумевает учет дополнительных факторов и понимание контекста. Таким образом, результаты, полученные на ARC, могут не полностью отражать способность модели решать аналогичные задачи в условиях, приближенных к реальным образовательным сценариям.
Проект BabyVision предлагает фундаментальный подход к оценке визуального мышления, фокусируясь на ранних визуальных способностях, таких как распознавание объектов, отслеживание движения и понимание пространственных отношений. Этот подход исходит из предпосылки, что развитие этих базовых навыков является критически важным для формирования более сложных пространственных представлений у моделей машинного обучения. BabyVision использует набор данных, состоящий из изображений и видео, демонстрирующих сцены, типичные для младенцев, и оценивает способность моделей к выполнению задач, связанных с определением местоположения объектов, их размера и ориентации, а также предсказанию их движения. Акцент на ранних визуальных способностях позволяет исследователям изучить, как модели строят и используют пространственные представления, что, в свою очередь, может помочь в разработке более эффективных алгоритмов для решения сложных задач пространственного мышления.
Для преодоления разрыва между абстрактными тестами и реальными задачами необходимо создание нового эталона, включающего аутентичные школьные задания. Этот эталон должен представлять собой набор задач, типичных для начальной школы, и быть направлен на проверку возможностей мультимодальных больших языковых моделей (MLLM) в контексте пространственного мышления, применяемого к практическим ситуациям, с которыми ученики сталкиваются в классе. Такой подход позволит более точно оценить способность моделей к обобщению и переносу знаний, полученных в абстрактных задачах, на реальные сценарии, и выявить слабые места в их понимании пространственных отношений.
Разложение Пространственных Навыков: Вращение, Складывание и Завершение Узоров
Пространственное мышление не является единым навыком, а представляет собой комплекс различных способностей, включающих вращение, складывание, завершение узоров и отражение. Каждая из этих способностей представляет собой отдельную проблему для искусственного интеллекта. Вращение требует понимания изменения ориентации объекта, складывание — прогнозирования формы после преобразований, завершение узоров — выявления закономерностей и экстраполяции, а отражение — восприятия симметрии и зеркальных преобразований. Сложность каждой из этих задач обусловлена необходимостью моделирования трехмерного пространства и понимания взаимосвязей между объектами, что требует от ИИ способности к абстрактному мышлению и визуализации.
Несмотря на относительные успехи многомодальных больших языковых моделей (MLLM) в задачах масштабирования, операции, требующие ментальной манипуляции с объектами в пространстве, такие как вращение и складывание, остаются особенно сложными. Это связано с тем, что подобные задачи требуют не просто распознавания визуальных паттернов, но и построения внутренних трехмерных представлений объектов и предсказания результатов их трансформаций. В отличие от задач, решаемых путем сопоставления визуальных признаков, вращение и складывание требуют от модели способности к абстрактному мышлению и моделированию физических процессов, что выходит за рамки возможностей, демонстрируемых текущими MLLM.
Для детальной оценки пространственного мышления мультимодальных больших языковых моделей (MLLM) используются специализированные бенчмарки, включающие задачи на вращение, складывание и завершение паттернов. Эти тесты позволяют выявить конкретные области, требующие улучшения в алгоритмах обработки пространственной информации. Наблюдается снижение производительности на 5-5.8 процентных пункта при выполнении задач, непосредственно связанных с вращением и отражением объектов, что указывает на повышенную сложность этих операций для текущих MLLM и необходимость дальнейшей оптимизации соответствующих модулей.

Аутентичная Оценка с VRB: От Теории к Реальности Класса
Визуальный бенчмарк рассуждений (VRB) разработан для обеспечения аутентичной оценки знаний, напрямую связанной с реальными условиями обучения. В его основе лежат вопросы, взятые из подлинных экзаменационных работ для начальной школы, используемых в Замбии и Индии. Это позволяет оценить навыки решения задач в контексте, близком к тому, с которым сталкиваются учащиеся в реальных учебных заведениях, а не в искусственно созданных условиях. Использование материалов из Zambia National End of Primary Exams и Jawahar Navodaya Vidyalaya Selection Test гарантирует соответствие оценок текущим образовательным стандартам и задачам, решаемым учащимися в этих странах.
Визуальный бенчмарк рассуждений (VRB) использует вопросы, взятые непосредственно из реальных экзаменационных работ начальной школы из Замбии и Индии, а именно из отборочного теста Jawahar Navodaya Vidyalaya и Национального экзамена по окончании начальной школы в Замбии. Это обеспечивает соответствие оценок реальным задачам, с которыми сталкиваются учащиеся в образовательных учреждениях этих стран. Включение заданий из этих проверенных источников гарантирует, что бенчмарк отражает уровень сложности и типы вопросов, с которыми дети сталкиваются в повседневной учебной практике, что повышает валидность и практическую значимость результатов оценки.
Включение наборов данных MathVista и MATH-V значительно расширяет возможности Visual Reasoning Benchmark (VRB), позволяя оценивать визуальное мышление в контексте решения математических задач. Это обеспечивает комплексную оценку мультимодальных способностей, поскольку VRB проверяет не только общее визуальное рассуждение, но и его применение в математических задачах. На текущий момент, наиболее продвинутые мультимодальные языковые модели (LLM) достигают максимальной точности в 78% при решении задач VRB, что существенно превышает уровень случайного угадывания, составляющий всего 25%.

К Надежному Визуальному Интеллекту: Значение и Будущие Направления
В отличие от существующих эталонов, ориентированных на упрощенные задачи, Визуальный Эталон Надежности (VRB) делает акцент на аутентичной оценке мультимодальных больших языковых моделей (MLLM). Такой подход позволяет выявить критические пробелы в их способностях к пространственному мышлению и перцепции. Исследования, проведенные с использованием VRB, показали, что MLLM часто испытывают трудности при решении задач, требующих понимания трехмерных отношений, распознавания объектов в сложных сценах и интерпретации визуальной информации, приближенной к реальным условиям. В результате, VRB предоставляет более точную и содержательную картину возможностей и ограничений MLLM, что является ключевым шагом на пути к созданию действительно интеллектуальных и надежных систем искусственного интеллекта.
Для преодоления выявленных ограничений в мультимодальных больших языковых моделях (MLLM) необходимы принципиально новые архитектурные решения и методики обучения. Особое внимание следует уделить созданию надежных визуальных представлений, способных эффективно кодировать информацию даже при наличии шумов или искажений. Помимо этого, критически важна разработка эффективных механизмов рассуждений, позволяющих моделям не просто находить ответы, но и логически обосновывать их. Новые подходы к обучению должны стимулировать модели к формированию устойчивых к помехам визуальных признаков и оптимизации процессов вывода, что позволит им демонстрировать более высокую точность и надежность в реальных условиях, где визуальные данные часто бывают неидеальными.
Перспективные исследования в области мультимодальных больших языковых моделей (MLLM) направлены на создание систем, способных не только решать задачи визуального рассуждения, но и объяснять ход своих мыслей. Такая прозрачность в процессе принятия решений критически важна для формирования доверия к искусственному интеллекту, особенно при его использовании в образовательных инструментах. Недавние исследования выявили, что даже незначительные визуальные искажения, например, артефакты, возникающие при копировании изображений, могут снижать точность MLLM на 9 процентных пунктов. Это подчеркивает необходимость разработки моделей, устойчивых к несовершенствам реального мира и способных обеспечивать надежные результаты даже в условиях зашумленных или искаженных данных. В дальнейшем, акцент будет сделан на создании систем, способных к самоанализу и объяснению логики своих выводов, что позволит пользователям лучше понимать и доверять результатам, полученным с помощью ИИ.
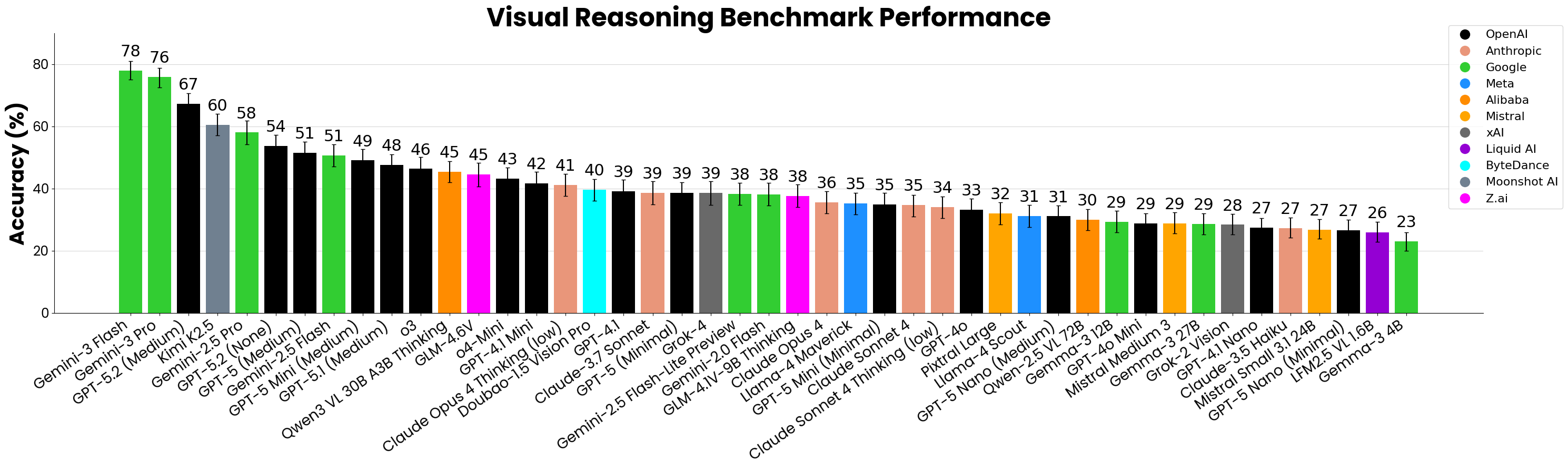
Исследование, представленное в работе, подчеркивает ограничения современных мультимодальных больших языковых моделей в области пространственного мышления. Авторы демонстрируют, что способность к визуальному рассуждению, необходимая для решения задач начальной школы, зачастую оказывается слабой стороной этих систем. Это особенно заметно при решении задач, требующих понимания пространственных отношений и абстрактного мышления. Как заметил Анри Пуанкаре: «Наука не состоит из цепи, в которой каждое звено необходимо, но из огромного количества нитей, большинство из которых обрывается». Данное исследование подтверждает эту мысль: существующие модели, несмотря на впечатляющие успехи в обработке текста, нуждаются в значительном улучшении для эффективного решения задач, требующих визуального и пространственного понимания, что, в свою очередь, необходимо для подлинного обучения в классе.
Куда Далее?
Представленная работа обнажает неожиданную хрупкость многомодальных языковых моделей перед задачами, которые кажутся элементарными для ребенка начальной школы. Стремление к впечатляющим результатам на синтетических бенчмарках часто затмевает потребность в действительном понимании визуальной информации. Иллюзия интеллекта рассеивается, когда модель сталкивается с необходимостью не просто “видеть”, но и рассуждать в пространстве, улавливать причинно-следственные связи, заложенные в визуальном ряде.
Дальнейшие исследования неизбежно должны сместиться в сторону упрощения, а не усложнения. Каждая дополнительная строка кода — это признание несовершенства архитектуры, попытка замаскировать недостаток истинного понимания. Поиск элегантных решений, свободных от избыточности, — вот путь к созданию моделей, способных к подлинному визуальному мышлению. Иначе, каждый новый бенчмарк станет лишь еще одним зеркалом, отражающим поверхностность “интеллекта”.
Необходимо отойти от гонки за параметрами и сосредоточиться на разработке принципиально новых подходов к визуальному представлению знаний. Совершенство не в количестве слоев, а в их отсутствии, в способности модели к абстракции и обобщению, к исчезновению автора в конечном продукте.
Оригинал статьи: https://arxiv.org/pdf/2602.12196.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обучение представлений для динамических систем: новый взгляд
- Понимание сложных систем: новый взгляд на агентные модели
- Преображение лиц: от тепла к реализму с помощью ИИ
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Разреженность и масштаб: семейство языковых моделей Trinity
- Рассуждения на графах: как большие языковые модели учатся видеть мир
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Голос с Акцентом: Управление произношением без акцентированных данных
2026-02-15 20:39