Автор: Денис Аветисян
Исследователи представили комплексный тест для оценки способности искусственного интеллекта генерировать и редактировать изображения, необходимые для выполнения задач на компьютере, требующих последовательного планирования.
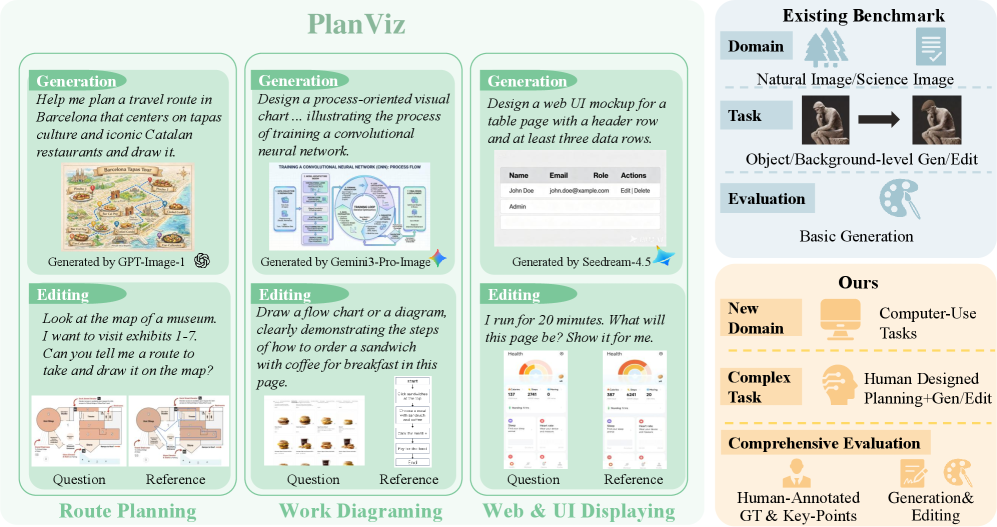
В статье представлена методика PlanViz, предназначенная для оценки возможностей унифицированных мультимодальных моделей (UMM) в задачах визуального планирования, связанных с компьютерным взаимодействием.
Несмотря на впечатляющие успехи унифицированных мультимодальных моделей (UMM) в генерации изображений и мультимодальном рассуждении, их способность к решению задач компьютерного планирования, тесно связанных с повседневной жизнью, остается малоизученной. В данной работе, посвященной разработке эталонного набора данных ‘PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks’, предложен новый подход к оценке возможностей UMM в генерации и редактировании изображений, требующих пространственного мышления и понимания процедур. Эксперименты с разработанным набором данных выявили существенные ограничения существующих моделей в планировании задач, таких как построение маршрутов, создание диаграмм и отображение веб-интерфейсов. Какие архитектурные и обучающие стратегии позволят преодолеть эти ограничения и приблизят нас к созданию действительно планирующих визуальных моделей?
В поисках Универсального ИИ: Объединяя Разные Модальности
Традиционные модели искусственного интеллекта зачастую демонстрируют ограниченные возможности при решении задач, требующих одновременной обработки визуальной и текстовой информации. Это связано с тем, что большинство систем разрабатывались для работы с одним типом данных — либо изображениями, либо текстом — и испытывают трудности при интеграции этих двух модальностей. Например, задача понимания содержания изображения по текстовому описанию или наоборот, генерация изображения на основе текстового запроса, долгое время оставалась сложной для алгоритмов. Неспособность эффективно объединять визуальные и текстовые данные ограничивает потенциал искусственного интеллекта в таких областях, как автоматическое описание изображений, визуальный поиск, ответы на вопросы по изображениям и создание интеллектуальных систем, способных к комплексному анализу окружающей среды.
Современные унифицированные мультимодальные модели (UMM) представляют собой принципиально новый подход к искусственному интеллекту, стремящийся объединить обработку различных типов данных — текста, изображений, аудио и видео — в единую систему. Вместо того, чтобы анализировать каждый тип данных отдельно, UMM интегрируют их, позволяя модели понимать взаимосвязи и контекст между ними. Этот процесс достигается за счет использования общих представлений данных, где информация из разных модальностей преобразуется в единое векторное пространство, что позволяет модели извлекать более глубокие и сложные закономерности. В результате, UMM способны решать задачи, требующие комплексного понимания информации, например, отвечать на вопросы по изображениям, генерировать описания видео или даже создавать новые мультимедийные произведения, демонстрируя значительный прогресс в области искусственного интеллекта.
Новое поколение унифицированных мультимодальных моделей (UMM) открывает перспективы создания значительно более устойчивых и универсальных систем искусственного интеллекта. В отличие от традиционных моделей, специализирующихся на обработке отдельных типов данных, UMM способны интегрировать и анализировать информацию из различных источников, таких как текст, изображения и звук. Это позволяет им не просто распознавать объекты или понимать отдельные фразы, но и осуществлять сложные рассуждения, выявлять скрытые связи и находить решения для задач, требующих комплексного подхода. Способность к объединению разнородных данных существенно расширяет возможности ИИ в таких областях, как автоматический анализ контента, разработка интеллектуальных помощников и создание систем, способных к более глубокому пониманию окружающего мира.
PlanViz: Испытательный Полигон для Планирующих Моделей
Оценка универсальных мультимодальных моделей (UMM) требует использования эталонных тестов, которые проверяют их способность к планированию и выполнению задач, использующих как визуальные, так и текстовые входные данные. Необходимость в таких тестах обусловлена тем, что UMM должны демонстрировать не только способность к восприятию и обработке информации из разных модальностей, но и умение разрабатывать последовательность действий для достижения поставленной цели. Эффективные эталоны должны включать задачи, требующие от модели анализа входных данных, определения необходимых шагов и их последовательной реализации, а также оценки результатов выполнения. Отсутствие адекватных эталонов затрудняет объективное сравнение различных UMM и оценку их прогресса в области планирования и рассуждений.
PlanViz представляет собой набор задач, имитирующих типичные сценарии использования компьютера, требующие планирования действий. В рамках бенчмарка модели должны выполнять такие операции, как генерация изображений по текстовому описанию, редактирование существующих изображений с применением последовательности шагов, и другие подобные задачи. Данные задачи требуют от модели не только понимания инструкций, но и способности декомпозировать сложную цель на последовательность элементарных действий, что позволяет оценить ее навыки планирования и выполнения комплексных операций.
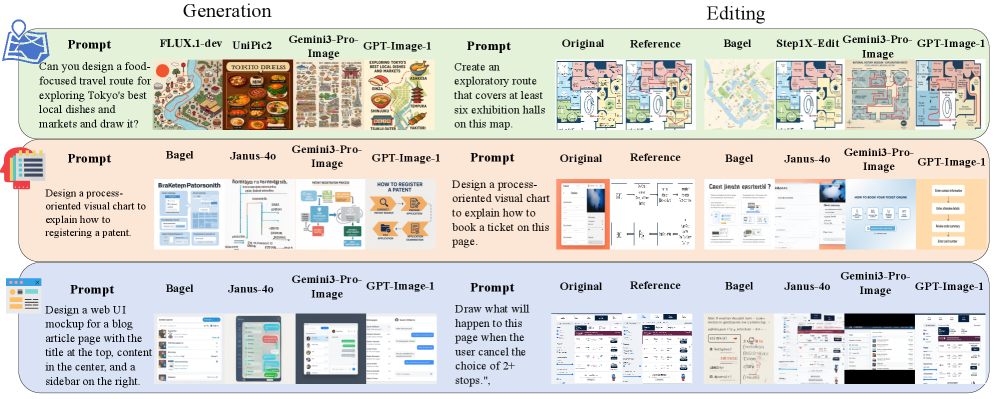
Бенчмарк PlanViz включает в себя оценку подзадач, таких как планирование маршрутов и создание рабочих диаграмм, что позволяет комплексно оценить способности моделей к планированию. Задачи по планированию маршрутов требуют от модели определения оптимальной последовательности действий для достижения заданной цели в визуально представленной среде. Создание рабочих диаграмм, в свою очередь, проверяет способность модели структурировать и визуализировать последовательность операций для решения конкретной задачи. Включение этих подзадач обеспечивает более полную и всестороннюю оценку возможностей моделей в области планирования, выходящую за рамки простых задач генерации или редактирования изображений.

PlanScore: Оцениваем Корректность с Помощью ИИ-Судьи
PlanScore представляет собой адаптивную метрику, предназначенную для оценки корректности, визуального качества и эффективности сгенерированных изображений. В отличие от общих метрик, PlanScore учитывает специфику задачи генерации или редактирования, что позволяет более точно оценивать производительность моделей. Метрика оценивает соответствие изображения заданным условиям, наличие артефактов и общее визуальное восприятие. Оценка производится автоматически, что позволяет проводить масштабное тестирование и сравнение различных алгоритмов генерации и редактирования изображений без необходимости привлечения экспертов-оценщиков.
В основе PlanScore лежит инновационный подход — использование LLM-as-Judge, то есть больших языковых моделей в качестве автоматизированной системы оценки. Вместо традиционных метрик, полагающихся на пиксельные сравнения, LLM-as-Judge анализирует релевантность и когерентность сгенерированных изображений, оценивая, насколько хорошо они соответствуют заданным условиям и требованиям. Этот метод позволяет оценивать качество изображений на более высоком семантическом уровне, учитывая не только визуальные характеристики, но и соответствие поставленной задаче. В частности, в PlanScore используется модель Qwen3-VL-235B-A22B-Instruct для автоматической оценки, что обеспечивает масштабируемость и объективность процесса.
В качестве автоматизированной системы оценки качества сгенерированных изображений используется большая языковая модель Qwen3-VL-235B-A22B-Instruct. Проведенные тесты демонстрируют высокую степень корреляции между оценками, выдаваемыми моделью, и субъективными оценками экспертов, подтвержденную коэффициентом корреляции Пирсона, превышающим 0.8. Средняя абсолютная ошибка (Mean Absolute Error) находится на приемлемом уровне, что свидетельствует о надежности и согласованности оценок, выдаваемых системой LLM-as-Judge, и позволяет использовать ее для автоматизированного анализа и сравнения различных методов генерации и редактирования изображений.
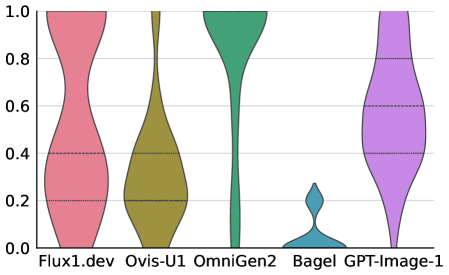
Анализ, проведенный с использованием метрики PlanScore, выявил существенные различия в производительности при задачах генерации и редактирования изображений. Средний балл корректности для сгенерированных изображений составил 0.88, что указывает на высокую точность соответствия заданным условиям. В то же время, при выполнении задач редактирования изображений, показатели корректности варьировались в диапазоне от 0.61 до 0.67. Данный разрыв указывает на то, что алгоритмы демонстрируют более высокую эффективность при создании новых изображений по сравнению с внесением изменений в существующие.
Оценивая Возможности UMM с Помощью PlanViz и PlanScore: Результаты и Выводы
Бенчмарк PlanViz, в сочетании с метрикой PlanScore, предоставляет всестороннюю возможность оценки производительности универсальных мультимодальных моделей (UMM) в задачах планирования. Данный подход позволяет не просто измерить способность модели генерировать последовательность действий, но и оценить их корректность и эффективность в достижении поставленной цели. PlanViz предоставляет стандартизированный набор задач, требующих от UMM понимания визуальной информации и ее преобразования в логические шаги для решения проблемы, а PlanScore количественно оценивает успешность выполнения этих шагов. Благодаря этому, исследователи получают надежный инструмент для сравнения различных моделей и выявления их сильных и слабых сторон в контексте сложных задач планирования, что способствует дальнейшему развитию этой перспективной области искусственного интеллекта.
В рамках всесторонней оценки современных мультимодальных моделей, такие как GPT-Image-1 и Seedream 4.5, подвергаются строгим испытаниям, выявляющим их сильные и слабые стороны. Результаты демонстрируют значительное превосходство закрытых моделей: Seedream 4.5, к примеру, достигает показателя корректности в 0.88 при генерации контента. В то же время, большинство моделей с открытым исходным кодом, как правило, демонстрируют более низкие результаты, зачастую не превышающие 0.55. Эта разница в производительности указывает на существенные различия в возможностях и архитектуре различных мультимодальных моделей, подчеркивая необходимость дальнейших исследований и разработок в данной области.
Интеграция методов, таких как GRPO (Guided Reasoning with Prompt Optimization), значительно повышает эффективность универсальных мультимодальных моделей (UMM), обеспечивая более точные и результативные решения в задачах планирования. Исследования показывают, что модели с применением GRPO демонстрируют улучшенную способность к последовательному рассуждению и генерации планов. Примечательно, что открытые UMM, в отличие от закрытых, характеризуются более высоким коэффициентом вариации, что свидетельствует о большей чувствительности к изменениям в формулировке запроса. Это означает, что небольшие вариации в структуре или содержании запроса могут приводить к существенным различиям в результатах, полученных от открытых моделей, в то время как закрытые модели проявляют большую стабильность и устойчивость к таким изменениям.
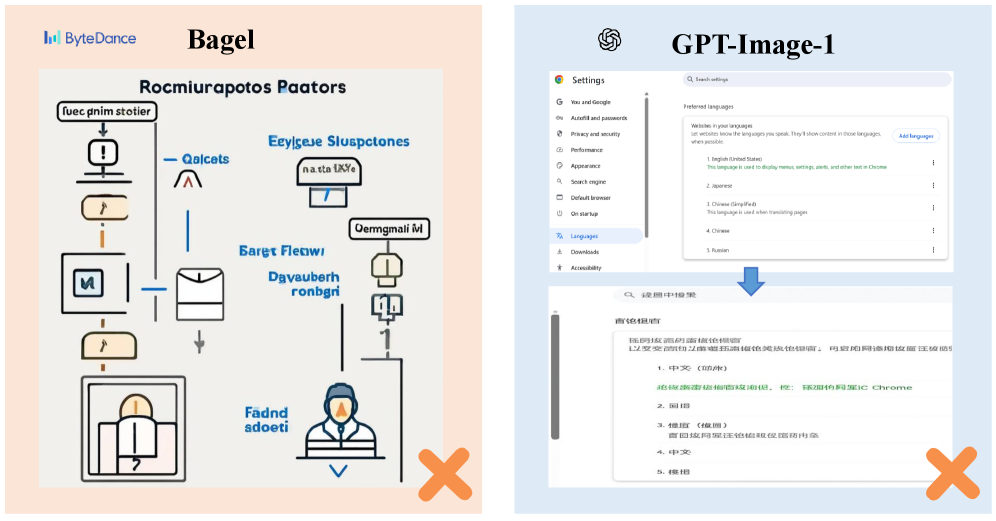
Исследование, представленное в данной работе, неумолимо демонстрирует, что современные унифицированные мультимодальные модели (UMM) сталкиваются с трудностями при планировании визуальных действий, необходимых для выполнения задач, связанных с использованием компьютера. Зачастую, элегантная теория генерации и редактирования изображений разбивается о суровую реальность практического применения. Как метко заметил Дэвид Марр: «Представление о том, что мозг делает, — это не то же самое, что и то, что он делает». Иными словами, способность генерировать визуально привлекательные изображения не гарантирует понимания последовательности действий, необходимых для, скажем, редактирования скриншота или создания нового визуального элемента интерфейса. Создание PlanViz — это попытка зафиксировать эту болезненную истину, создать своеобразный «багтрекер» для алгоритмов, чтобы отслеживать их неудачи в планировании и визуальном исполнении задач.
Что дальше?
Представленный анализ возможностей унифицированных мультимодальных моделей (UMM) в задачах, требующих планирования, неизбежно возвращает к вопросу о цене «унификации». В погоне за всеохватностью, модели зачастую теряют специализацию, и «PlanViz» наглядно демонстрирует, что даже кажущаяся простота компьютерных задач, требующая последовательных действий, представляет серьёзную проблему. Вероятно, будущее за не попытками создать универсальное решение, а за более точной декомпозицией задач и разработкой узкоспециализированных модулей, которые можно будет компоновать.
Следует признать, что любой новый бенчмарк — это, по сути, лишь способ отложить неизбежное. «PlanViz» выявляет слабые места текущих моделей, но, скорее всего, через несколько лет появятся новые, более сложные задачи, над которыми они снова споткнутся. Если код выглядит идеально — значит, его никто не деплоил. И эта закономерность, похоже, справедлива для любой «революционной» технологии.
В конечном итоге, оценка прогресса в области генерации и редактирования изображений не должна сводиться к улучшению метрик на синтетических датасетах. Гораздо важнее понять, как эти модели действительно помогают людям решать реальные проблемы, и признать, что «MVP — это просто способ сказать пользователю: подожди, мы потом исправим». Вероятно, самое ценное, что можно извлечь из этой работы, — это напоминание о необходимости критически оценивать любые заявления о прорывных технологиях.
Оригинал статьи: https://arxiv.org/pdf/2602.06663.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- Искусственный интеллект на службе редких болезней
- Наука, управляемая интеллектом: новая эра открытий
- Квантовый Переворот: От Теории к Реальности
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Плоские зоны: от теории к новым материалам
2026-02-09 23:25