Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий динамически комбинировать небольшие адаптеры для достижения впечатляющих результатов в задаче визуального переноса стилей и манипулирования изображениями.

Представлен LoRWeB — фреймворк, использующий базис адаптеров LoRA для гибкого и обобщенного обучения визуальным аналогиям.
Несмотря на успехи в обучении генеративных моделей, задача визуальной аналогии, требующая манипулирования изображениями по аналогии, остается сложной из-за необходимости передачи неявных преобразований. В работе ‘Spanning the Visual Analogy Space with a Weight Basis of LoRAs’ предложен новый подход LoRWeB, использующий динамическое комбинирование обученных адаптеров LoRA для решения этой задачи. LoRWeB демонстрирует передовые результаты и улучшенную обобщающую способность, эффективно охватывая пространство визуальных преобразований через взвешенную основу LoRA-модулей. Может ли подобный подход к разложению адаптеров LoRA стать основой для более гибких и интуитивно понятных инструментов редактирования изображений?
Понимание через Аналогии: Новый Взгляд на Визуальное Преобразование
Традиционные методы обработки изображений, как правило, требуют от пользователя предоставления детальных, пошаговых инструкций для каждого изменения. Это ограничивает творческий потенциал и гибкость, поскольку даже незначительная правка требует явного указания конкретных параметров и действий. В отличие от этого, способность человека к визуальному мышлению позволяет преобразовывать изображения, опираясь на интуицию и примеры, а не на точные инструкции. Такая зависимость от явных команд делает традиционные подходы неэффективными при решении сложных задач, требующих творческого подхода или адаптации к новым, непредвиденным ситуациям. В результате, пользователи часто ограничены рамками предустановленных инструментов и фильтров, что препятствует реализации оригинальных идей и творческих замыслов.
Вместо традиционных методов обработки изображений, требующих точных инструкций для каждого изменения, формируется новый подход — обучение на основе визуальных аналогий. Эта парадигма позволяет системам извлекать закономерности трансформаций из примеров, подобно тому, как человек усваивает навыки, наблюдая за другими. Вместо программирования конкретных действий, алгоритмы учатся преобразовывать изображения, опираясь на предоставленные пары «вход-выход». Такой подход открывает возможности для интуитивного редактирования, позволяя создавать новые изображения, основываясь на освоенных аналогиях и творческих принципах, что значительно расширяет границы автоматической обработки визуальной информации.
Новый подход к обработке изображений открывает возможности для интуитивного редактирования и создания контента, ранее недоступные. Вместо ручного задания каждого изменения, системы, использующие визуальные аналогии, способны самостоятельно преобразовывать изображения, опираясь на примеры, предоставленные пользователем. Это позволяет, например, трансформировать фотографию в стиле известного художника или изменить времена года на изображении одним лишь указанием желаемого результата. Такой подход значительно упрощает процесс творчества, позволяя даже пользователям без специальных навыков в области графического дизайна реализовывать сложные визуальные идеи. По сути, это переход от точного программирования каждого шага к обучению системы понимать и воспроизводить визуальные закономерности, что расширяет границы возможного в области цифрового искусства и дизайна.
Эффективная реализация визуального обучения аналогиям требует разработки усовершенствованных методов представления и комбинирования полученных преобразований. Ключевой задачей является создание компактной и выразительной формы, позволяющей описывать сложные визуальные изменения, такие как стилизация, перенос текстур или даже изменение семантического содержания изображения. Простое перечисление всех возможных преобразований непрактично, поэтому исследователи сосредотачиваются на изучении композиционных структур, позволяющих строить новые преобразования из базовых элементов. Например, преобразование может быть представлено как последовательность операций, каждая из которых отвечает за определенный аспект изменения. Успешная композиция этих операций позволяет создавать сложные и разнообразные визуальные эффекты, приближая возможности машинного зрения к человеческому воображению и творческому потенциалу. Эффективные алгоритмы композиции должны быть устойчивы к шуму и вариациям в данных, обеспечивая надежное и предсказуемое поведение системы.

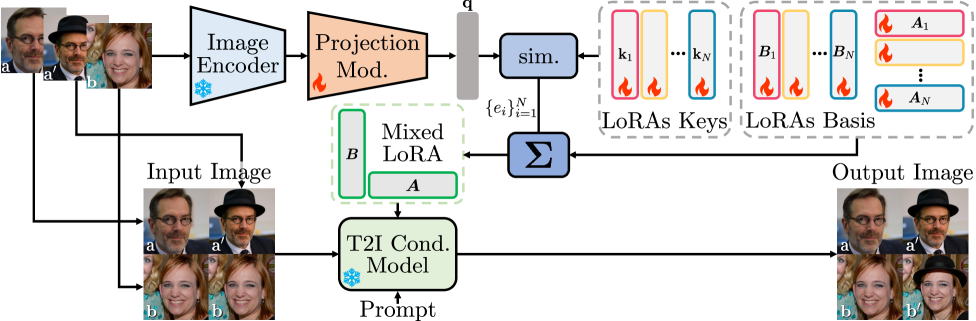
LoRWeB: Архитектура для Композиционных Визуальных Трансформаций
LoRWeB представляет собой новую структуру, использующую набор LoRA (Low-Rank Adaptation) адаптеров для представления разнообразных визуальных преобразований. Вместо обучения отдельных моделей для каждого преобразования, LoRWeB использует относительно небольшие LoRA модули, каждый из которых кодирует специфическую визуальную операцию, такую как изменение цвета, формы или текстуры. Этот подход позволяет эффективно представлять широкий спектр преобразований, используя ограниченное количество параметров. Каждый LoRA адаптер применяется к базовой модели, модифицируя её веса для выполнения конкретного преобразования, при этом сохраняя исходную модель неизменной. Такая модульная структура упрощает добавление и комбинирование различных преобразований, что является ключевым аспектом функциональности LoRWeB.
В основе LoRWeB лежит динамический композиционный энкодер, который предсказывает веса для линейной комбинации LoRA-адаптеров. Этот энкодер принимает на вход исходное изображение и целевое преобразование, и выдает набор весов, определяющих вклад каждого LoRA-адаптера в конечное преобразование. Использование линейной комбинации позволяет создавать сложные визуальные аналогии, комбинируя эффекты нескольких адаптеров, что позволяет модели гибко адаптироваться к разнообразным изменениям визуальных признаков и эффективно обобщать полученные знания на новые, ранее не встречавшиеся преобразования.
Использование LoRA (Low-Rank Adaptation) в LoRWeB обеспечивает высокую параметрическую эффективность, позволяя адаптировать модель к новым визуальным преобразованиям без необходимости полной переподготовки. Вместо обновления всех параметров базовой модели, LoRA обучает небольшие, низкоранговые матрицы, которые добавляются к существующим весам. Это значительно снижает вычислительные затраты и объем требуемой памяти, поскольку количество обучаемых параметров существенно меньше, чем при традиционной тонкой настройке. Фактически, LoRWeB может эффективно применять и комбинировать различные адаптеры LoRA для представления сложных визуальных преобразований, сохраняя при этом низкие требования к ресурсам и обеспечивая быструю адаптацию к новым задачам.
В задачах завершения визуальных аналогий, LoRWeB демонстрирует передовые результаты, превосходя существующие подходы, основанные на использовании отдельных LoRA-адаптеров. Эксперименты показали, что LoRWeB значительно улучшает обобщающую способность модели применительно к ранее не встречавшимся визуальным преобразованиям. Улучшение достигается за счет динамического комбинирования LoRA-адаптеров, что позволяет модели эффективно представлять и применять сложные комбинации преобразований, недоступные для методов, использующих только один адаптер для каждого преобразования. Результаты тестов на стандартных наборах данных подтверждают статистически значимое превосходство LoRWeB по метрикам точности и обобщающей способности.

Внутренний Механизм: Интеграция LoRWeB с Генеративными Моделями
LoRWeB бесшовно интегрируется с условными потоковыми моделями, такими как Flux.1-Kontext, обеспечивая генерацию новых изображений на основе усвоенных аналогий. Данная интеграция позволяет модели использовать полученные знания об отношениях между различными концепциями для создания визуальных представлений, соответствующих заданным аналогиям. Flux.1-Kontext выступает в качестве базовой архитектуры, обеспечивающей генеративный процесс, в то время как LoRWeB предоставляет механизм для внедрения и использования информации об аналогиях, тем самым направляя генерацию изображений в соответствии с желаемыми преобразованиями и отношениями между объектами.
В архитектуре Flux.1-Kontext используется расширенный механизм внимания (extended attention), позволяющий модели устанавливать связи между удаленными элементами входных данных. Это особенно важно при генерации изображений, где контекст может охватывать значительные области. Традиционные механизмы внимания имеют ограничения по длине последовательности, которую они могут эффективно обрабатывать. Расширенный механизм внимания в Flux.1-Kontext преодолевает эти ограничения, позволяя модели учитывать более длинные зависимости и, как следствие, генерировать изображения с улучшенным качеством и большей согласованностью деталей, даже в сложных сценах. Это достигается за счет оптимизированной реализации, снижающей вычислительную сложность при работе с длинными последовательностями.
Для обеспечения соответствия между входной аналогией и сгенерированным изображением, а также повышения семантической согласованности, LoRWeB использует модели CLIP и SigLIP. CLIP (Contrastive Language-Image Pre-training) сопоставляет текст и изображения, оценивая их семантическую близость. SigLIP, являясь расширением CLIP, специально оптимизирован для задач редактирования изображений и позволяет более точно выравнивать изменения, основанные на текстовом запросе. Эти модели служат в качестве метрик для оценки качества генерации, гарантируя, что сгенерированное изображение соответствует заданной аналогии и не содержит семантических несоответствий. Использование CLIP и SigLIP позволяет количественно оценить соответствие между входными данными и выходными результатами, что важно для оценки эффективности LoRWeB.
Оценки LoRWeB, проведенные с использованием визуальных языковых моделей (VLM), демонстрируют высокую точность редактирования и согласованность результатов. Методики оценки, основанные на VLM, позволяют автоматически оценивать, насколько точно внесенные изменения соответствуют заданному условию и насколько логически связным является полученное изображение. Результаты показывают, что LoRWeB превосходит существующие подходы в задачах редактирования изображений, требующих сохранения семантической целостности и визуальной консистентности, что подтверждается количественными метриками и качественным анализом полученных изображений.
Оценка Эффективности и Направления Дальнейших Исследований
Для тщательной оценки качества генерируемых изображений использовался метод двух альтернатив (Two-Alternative Forced Choice), позволяющий объективно измерить предпочтения в восприятии. В рамках данного подхода, моделям, таким как Gemma-3, предоставлялись пары изображений, и они должны были определить, какое из них более реалистично или соответствует заданным критериям. Этот метод, основанный на использовании возможностей моделей в области компьютерного зрения, позволяет не только количественно оценить качество генерации, но и выявить слабые места алгоритмов, обеспечивая основу для дальнейшего улучшения и оптимизации. Благодаря этому, оценка становится более точной и надежной, что критически важно для развития технологий генерации изображений.
Исследования показали, что разработанный фреймворк LoRWeB демонстрирует значительное превосходство над существующими методами в области генерации изображений. В ходе пользовательского тестирования, LoRWeB получил предпочтение в 66.7% случаев, что свидетельствует о его высокой эффективности и способности создавать изображения, более соответствующие ожиданиям пользователей. Данный показатель подтверждает, что предложенный подход позволяет достичь более качественных и привлекательных результатов в сравнении с базовыми моделями, открывая перспективы для его применения в различных творческих задачах и областях визуального искусства.
Разработанная система отличается высокой параметрической эффективностью, что позволяет легко масштабировать её и применять в разнообразных областях обработки изображений и творческих задачах. В отличие от традиционных методов, требующих огромного количества параметров для достижения качественных результатов, данная архитектура позволяет добиться сопоставимых, а зачастую и превосходящих результатов, используя значительно меньше вычислительных ресурсов. Это открывает возможности для развертывания системы на устройствах с ограниченной памятью, а также для адаптации к различным типам изображений и стилям, делая её универсальным инструментом для художников, дизайнеров и исследователей. Возможность тонкой настройки и быстрой адаптации к новым задачам является ключевым преимуществом, обеспечивающим широкую применимость системы в различных креативных процессах.
Исследования показали высокую степень соответствия между оценками, выдаваемыми LoRWeB, и субъективными оценками человека. В частности, использование Visual Language Model (VLM) в рамках LoRWeB продемонстрировало 89.9% согласованность с человеческим восприятием. Это свидетельствует о том, что разработанная система способна эффективно оценивать качество сгенерированных изображений, отражая предпочтения людей в области визуального восприятия. Такая высокая степень соответствия открывает перспективы для автоматизированной оценки и оптимизации генеративных моделей, а также для создания более интуитивно понятных и привлекательных визуальных материалов.
Дальнейшие исследования направлены на расширение возможностей модели в области построения более сложных аналогий, выходящих за рамки простых преобразований. Планируется углубленная работа над композициями, требующими понимания не только визуальных связей, но и контекстуальных зависимостей. Помимо изображений, авторы намерены адаптировать разработанную систему для обработки и генерации видео- и трехмерных данных, что позволит создавать более динамичные и реалистичные визуальные представления. Это расширение предполагает разработку новых алгоритмов и архитектур, способных эффективно обрабатывать более сложные и многомерные данные, открывая перспективы для применения в различных областях, включая создание контента, визуальные эффекты и научную визуализацию.

Представленная работа демонстрирует значительный прогресс в области визуального аналогового обучения благодаря LoRWeB. Этот фреймворк, динамически комбинируя адаптеры LoRA на основе изученного базиса, позволяет достичь выдающихся результатов в редактировании изображений. Как заметил Эндрю Ын: «Мы должны быть осторожны с данными, которые используем. Легко построить модели, которые хорошо работают на тренировочных данных, но плохо обобщаются на новые». В контексте данной статьи, это особенно актуально, поскольку способность LoRWeB к гибкой адаптации и обобщению позволяет преодолеть ограничения традиционных подходов, эффективно справляясь с новыми визуальными задачами и минимизируя риск переобучения.
Куда Ведут Аналогии?
Представленная работа, манипулируя низкоранговыми адаптерами, демонстрирует, что гибкость в пространстве визуальных аналогий достигается не столько усложнением модели, сколько умением комбинировать базовые элементы. Однако, воспроизводимость этих комбинаций остаётся ключевым вопросом. Если закономерность в формировании адаптеров не может быть чётко зафиксирована и повторена, её практическая ценность стремится к нулю. Необходимо исследовать, насколько полученные адаптеры обобщаются на принципиально новые, не встречавшиеся ранее визуальные концепции.
Особый интерес представляет вопрос о природе “базиса” адаптеров. Является ли он универсальным для всех типов визуальных данных, или же для каждого домена необходим свой, специфический базис? Поиск инвариантных признаков, лежащих в основе успешных визуальных аналогий, может привести к созданию моделей, способных к более глубокому пониманию визуального мира, а не просто к механическому копированию стилей.
В конечном счете, ценность подобных исследований определяется не скоростью генерации изображений, а способностью выявлять скрытые закономерности в визуальной информации. Если же эти закономерности остаются невидимыми, а адаптеры — лишь “черным ящиком”, то даже самые впечатляющие результаты рискуют остаться лишь временным эффектом.
Оригинал статьи: https://arxiv.org/pdf/2602.15727.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 22:20