Автор: Денис Аветисян
Исследователи предлагают инновационную архитектуру, позволяющую моделям лучше понимать связь между текстом и изображениями, приближая их к человеческому восприятию.
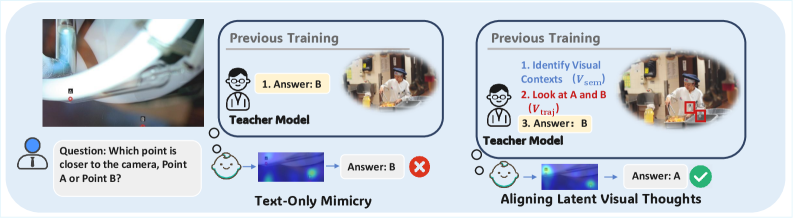
LaViT: выравнивание скрытых визуальных представлений посредством дистилляции знаний и последовательного обучения для эффективного мультимодального рассуждения.
Несмотря на успехи мультимодальных моделей, часто наблюдается расхождение между языковым выводом и реальным визуальным вниманием. В данной работе, представленной под названием ‘LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning’, авторы выявляют критический “восприятийный разрыв” и предлагают новый подход к дистилляции знаний, основанный на выравнивании скрытых визуальных представлений. LaViT заставляет модель-ученика восстанавливать семантику и траектории внимания модели-учителя перед генерацией текста, что существенно улучшает визуальное обоснование и позволяет компактной модели превзойти более крупные аналоги, включая GPT-4o. Возможно ли дальнейшее сокращение разрыва между языковыми и визуальными процессами и создание действительно «видящих» мультимодальных систем?
Разрыв между Восприятием и Пониманием: Когда Видеть — Не Значит Понимать
Современные мультимодальные модели часто демонстрируют так называемый «разрыв в восприятии» — способность генерировать текст, соответствующий запросу, при этом не обладая истинным визуальным мышлением. Несмотря на высокие оценки, полученные при оценке текстовых ответов, модели могут ошибаться в простых задачах, требующих понимания пространственных отношений или причинно-следственных связей на изображении. Этот феномен указывает на то, что модели успешно сопоставляют текст с визуальными данными на поверхностном уровне, но не способны к глубокому анализу и интерпретации визуальной информации, что ограничивает их возможности в решении задач, требующих реального “видения” и понимания.
Наблюдаемый разрыв в восприятии у современных мультимодальных моделей обусловлен тем, что они способны успешно сопоставлять текстовые запросы с визуальными данными, не демонстрируя при этом истинного понимания содержимого изображений. Модели, по сути, оперируют поверхностными соответствиями, находя статистические связи между текстом и визуальными признаками, вместо того чтобы выстраивать логические умозаключения на основе осмысленного анализа визуальной информации. Это приводит к кажущейся успешности в выполнении задач, где требуется простое сопоставление, однако выявляется при более сложных сценариях, требующих глубокого понимания контекста и взаимосвязей между объектами на изображении. В результате, модель может генерировать правдоподобные ответы, которые, тем не менее, лишены реальной осмысленности и не отражают истинное содержание визуального материала.
Современные модели машинного зрения часто используют статические визуальные представления, фиксируя изображение как единый вектор признаков. Однако, такой подход не позволяет уловить динамическую, реляционную информацию, которая критически важна для надежного рассуждения. Вместо анализа взаимосвязей между объектами и их положением в пространстве, модель оперирует лишь статичным «снимком», игнорируя контекст и потенциальные изменения. Это приводит к тому, что модель может успешно выполнять задачи, требующие простого сопоставления изображения и текста, но терпит неудачу при решении более сложных задач, где необходимо понимать, как объекты взаимодействуют друг с другом и что происходит на изображении. По сути, статичные эмбеддинги упускают из виду ключевые аспекты визуальной информации, ограничивая способность модели к истинному визуальному мышлению.
LaViT: Дистилляция Рассуждений в Компактные Модели
LaViT представляет собой фреймворк дистилляции знаний, предназначенный для передачи способности к визуальному рассуждению от большой, предварительно обученной «модели-учителя» к более компактной «модели-ученику». В основе подхода лежит идея передачи не просто визуальных признаков, а логики и стратегий, используемых учителем для анализа изображений. Это достигается путем обучения ученика имитировать внутренние представления и процессы рассуждения учителя, что позволяет ему эффективно решать задачи, требующие понимания визуальной информации, при значительно меньшем количестве параметров и вычислительных затратах.
Вместо прямого копирования визуальных признаков, LaViT фокусируется на выравнивании непрерывных “латентных визуальных мыслей” — внутренних представлений визуальной информации — между большой “моделью-учителем” и меньшей “моделью-учеником”. Этот процесс подразумевает сопоставление не самих пикселей или простых признаков, а более абстрактных, высокоуровневых представлений, сформированных моделью-учителем при обработке изображения. Выравнивание осуществляется путем минимизации различий между латентными представлениями учителя и ученика, что позволяет ученику усваивать способ интерпретации и анализа визуальных данных, а не просто запоминать конкретные визуальные паттерны. В результате, модель-ученик способна генерировать схожие внутренние представления при обработке одних и тех же изображений, что является ключом к переносу навыков рассуждения.
В отличие от традиционных методов обучения, где модель просто запоминает визуальные паттерны и соответствующие им ответы, LaViT позволяет «студенческой» модели усваивать процесс визуального рассуждения. Вместо прямого копирования признаков изображения, происходит передача знаний о том, как модель интерпретирует визуальную информацию и приходит к выводам. Это достигается за счет выравнивания «латентных визуальных мыслей» — внутренних представлений об изображении — между «учительской» и «студенческой» моделями, что позволяет «студенту» обобщать знания и эффективно применять их к новым, ранее не встречавшимся изображениям.

Учебный Процесс и Согласование: Обучение Визуальным Рассуждениям
В процессе обучения используется метод “Curriculum Sensory Gating”, заключающийся в последовательном ограничении и последующем расширении объема визуальной информации, предоставляемой модели. Изначально, входные данные подвергаются значительным ограничениям, что вынуждает модель полагаться на внутренние механизмы рассуждения для обработки и интерпретации. По мере обучения, ограничения постепенно ослабляются, позволяя модели интегрировать больше визуальных деталей, но при этом сохраняя акцент на внутренних процессах анализа. Данный подход направлен на развитие устойчивости к шуму и неполноте данных, а также на улучшение способности модели к абстрактному мышлению и обобщению.
Для обеспечения точного воспроизведения внутренней визуальной семантики и фокусировки на одних и тех же областях изображения, модель-ученик использует методы “Семантической Реконструкции” и “Траектории Выравнивания”. “Семантическая Реконструкция” направлена на точное воссоздание представлений, сформированных моделью-учителем, в то время как “Траектория Выравнивания” обеспечивает соответствие регионов внимания. Процесс контролируется с помощью “Карт Внимания”, которые служат индикаторами областей изображения, наиболее значимых для принятия решений, и позволяют модели-ученику эффективно согласовывать свою фокусировку с моделью-учителем.
Метод “Top-K Sparsification” повышает эффективность обучения и ясность получаемых результатов за счет фокусировки процесса обучения на наиболее значимых весах внимания. Вместо использования всех весов внимания, алгоритм отбирает K весов с наибольшим значением, отбрасывая менее важные. Это позволяет снизить вычислительную нагрузку, упростить модель и предотвратить переобучение, поскольку обучение концентрируется на наиболее релевантных областях изображения и взаимосвязях между ними. Выделение только наиболее важных весов внимания способствует более четкой интерпретации процесса принятия решений моделью и повышает устойчивость к шуму и отвлекающим факторам.
В LaViT для эффективной обработки визуальной информации используются ‘латентные токены’ — дискретное представление непрерывных внутренних ‘мыслей’ модели, сформированных на основе анализа изображений. Преобразование непрерывных латентных представлений в дискретные токены позволяет использовать стандартные методы обработки последовательностей, применяемые в задачах обработки естественного языка, такие как трансформеры. Это существенно упрощает архитектуру модели и повышает ее вычислительную эффективность, позволяя обрабатывать визуальную информацию в дискретном пространстве, что облегчает обучение и масштабирование.

Валидация и Более Широкое Влияние: Рассуждения, Превосходящие Восприятие
Исследования, проведенные на стандартных эталонах, таких как MMVP и BLINK, продемонстрировали превосходство LaViT над существующими мультимодальными моделями. LaViT достиг точности в 67.33% на MMVP и относительной точности определения глубины в 78.23% на BLINK. Эти результаты свидетельствуют о значительном прогрессе в способности модели к комплексному анализу визуальной информации и её интеграции с другими модальностями, что открывает новые перспективы для создания более совершенных систем искусственного интеллекта.
Модель LaViT-3B демонстрирует значительный прогресс в задачах, требующих детального визуального восприятия. В ходе тестирования на бенчмарках MMVP и BLINK, она показала прирост точности до 5,0% по сравнению с существующими моделями, что свидетельствует о её улучшенной способности к распознаванию тонких визуальных деталей. При этом, LaViT-3B не только сопоставима по производительности с более крупными моделями, насчитывающими 7 миллиардов параметров, но и превосходит их, а также конкурирует с проприетарной моделью GPT-4o. Такой результат указывает на эффективность разработанной архитектуры и открывает перспективы для создания компактных и высокопроизводительных систем компьютерного зрения.
В ходе тестирования модели LaViT-3B на бенчмарке BLINK, специализирующемся на оценке способностей к рассуждению, был достигнут показатель точности IQ-теста в 32.0%. Этот результат демонстрирует, что модель способна не просто распознавать визуальные паттерны, но и применять логическое мышление для решения задач, требующих понимания контекста и вывода заключений. Достигнутый уровень точности указывает на значительный прогресс в разработке систем искусственного интеллекта, способных к более сложному визуальному анализу и принятию решений, что открывает перспективы для их применения в областях, требующих интеллектуальной обработки визуальной информации.
Исследование демонстрирует, что в модели LaViT-3B удалось значительно повысить стабильность и эффективность механизма внимания по сравнению с эталонной моделью. В частности, коэффициент вариации (CV) внимания снижен до 0.102, что существенно ниже значения 0.392, зафиксированного в эталонной модели. Одновременно с этим, энтропия внимания также уменьшилась с 4.870 до 4.686. Эти изменения свидетельствуют о более сфокусированном и предсказуемом процессе принятия решений моделью, что, в свою очередь, способствует повышению её надежности и точности при обработке визуальной информации и выполнении сложных задач.
Данная работа закладывает основу для создания более устойчивых и надежных систем искусственного интеллекта, способных к истинному визуальному пониманию окружающего мира. Потенциал этих разработок простирается далеко за рамки простых задач распознавания образов, открывая новые возможности в таких областях, как робототехника, где требуется надежная ориентация и взаимодействие с окружающей средой, автономная навигация, обеспечивающая безопасное и эффективное передвижение без участия человека, и, что особенно важно, медицинская визуализация, где точный анализ изображений может существенно повысить качество диагностики и лечения. Развитие подобных систем позволит не просто «видеть» изображения, но и интерпретировать их содержание, делая шаги к созданию действительно интеллектуальных машин.
Исследование LaViT демонстрирует, что эффективное мультимодальное рассуждение требует не просто обработки визуальной информации, но и выстраивания чёткой связи между тем, что видит модель, и тем, как она это интерпретирует. Фактически, преодоление «разрыва восприятия» — ключевой шаг к созданию систем, способных к истинному пониманию. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть создан для расширения возможностей человека, а не для их замены». Данная работа, фокусируясь на выравнивании «скрытых визуальных мыслей» посредством дистилляции знаний и кураторского отбора, стремится именно к этому — к созданию более надёжных и понятных систем, способных к более глубокому анализу визуальных данных.
Куда Ведет Этот Путь?
Представленная работа, стремясь преодолеть разрыв между декларативным знанием и истинным визуальным пониманием, открывает, скорее, цикл вопросов, чем закрывает их. Успех LaViT в выравнивании латентных визуальных представлений, безусловно, является шагом вперед, но возникает закономерный вопрос: достаточно ли этого для достижения подлинного “мышления”? Не является ли выравнивание, по сути, лишь более изощренной формой имитации, а не эмуляцией когнитивных процессов?
Перспективы дальнейших исследований, очевидно, лежат в области более глубокого изучения механизмов визуального внимания и их интеграции с языковыми моделями. Однако, критически важно не ограничиваться исключительно улучшением производительности на текущих бенчмарках. Необходимо разработать принципиально новые методы оценки, способные выявлять не просто “что” модель отвечает, но и “как” она пришла к этому ответу, раскрывая истинную природу её “видения”.
Возможно, настоящая революция произойдет не в увеличении масштаба моделей, а в переходе к более принципиальным архитектурам, вдохновленным нейробиологией. Ведь в конечном счете, задача состоит не в создании искусственного интеллекта, который просто отвечает на вопросы, а в создании системы, способной к подлинному обучению и адаптации, подобно живому организму.
Оригинал статьи: https://arxiv.org/pdf/2601.10129.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-16 21:55