Автор: Денис Аветисян
Исследователи предлагают инновационный метод токенизации изображений, вдохновленный принципами коммуникации, для создания более осмысленных и организованных визуальных представлений.

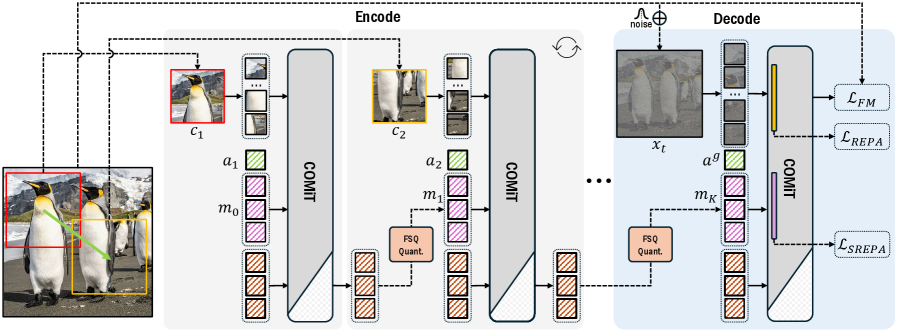
В статье представлена COMiT — система, использующая итеративный процесс коммуникации и реконструкции для обучения структурированным представлениям изображений, что обеспечивает улучшенные результаты на различных эталонных тестах.
Несмотря на успехи в области дискретного представления изображений, существующие методы токенизации часто фокусируются на реконструкции, упуская из виду семантическую структуру объектов. В данной работе, ‘Communication-Inspired Tokenization for Structured Image Representations’, представлен подход COMiT, вдохновленный принципами человеческой коммуникации, который рассматривает токенизацию как итеративный процесс обмена информацией и восстановления изображения. Ключевым нововведением является построение латентного сообщения в рамках фиксированного бюджета токенов путем последовательного наблюдения за фрагментами изображения и рекурсивного обновления дискретного представления. Способствует ли такой подход к формированию более интерпретируемой, объектно-ориентированной структуры токенов и улучшению обобщающей способности моделей компьютерного зрения?
За пределами Пикселей: Понимание Визуальной Информации
Традиционные методы обработки изображений зачастую рассматривают их как непрерывный массив пикселей, что существенно ограничивает возможности семантического понимания и анализа взаимосвязей между объектами. Такой подход игнорирует присущую визуальной информации структуру и контекст, препятствуя выделению значимых элементов и их интерпретации. Вместо анализа изображения как целого, состоящего из осмысленных частей, происходит обработка отдельных точек, что затрудняет распознавание объектов, понимание сцены и установление логических связей между ними. Данное ограничение особенно критично в задачах, требующих не просто обнаружения объектов, но и понимания их функций, взаиморасположения и контекста, что необходимо для полноценного «зрения» компьютерных систем.
Непосредственное применение архитектуры Transformer к изображениям сталкивается с существенными трудностями, обусловленными как вычислительной сложностью, так и неспособностью эффективно учитывать присущую визуальным данным структуру. Обработка изображений как последовательности пикселей требует огромных вычислительных ресурсов, поскольку количество токенов (пикселей) значительно превосходит типичные текстовые последовательности, с которыми Transformer изначально разрабатывался. Более того, такой подход игнорирует иерархическую организацию визуальной информации — от простых краев и текстур до сложных объектов и сцен. В результате, модель испытывает трудности с пониманием взаимосвязей между различными частями изображения и не способна эффективно извлекать семантически значимые признаки, необходимые для полноценного визуального анализа и понимания.
Для достижения подлинного понимания изображений, недостаточно просто обрабатывать их как массивы пикселей. Эффективный анализ требует разбиения визуальной информации на отдельные, значимые элементы — так называемые “токены”. Эти токены представляют собой не просто фрагменты изображения, а осмысленные объекты или части объектов, несущие в себе семантическую информацию. Такой подход позволяет алгоритмам не просто распознавать паттерны, но и устанавливать связи между различными элементами изображения, понимать их взаимоотношения и, в конечном итоге, “видеть” изображение так, как это делает человек. Вместо работы с огромным количеством пикселей, система оперирует ограниченным набором осмысленных единиц, что значительно упрощает задачу и повышает эффективность анализа, открывая возможности для более сложного визуального рассуждения и интерпретации.

Ранние Подходы к Токенизации Изображений
Первые подходы к токенизации изображений, такие как VQ-VAE и одномерная токенизация, представляли собой попытку дискретизации визуальных данных, однако часто приводили к ограниченной выразительности и размытым реконструкциям. VQ-VAE, используя векторное квантование, сжимал изображение в дискретное пространство, но из-за ограничений в размере кодового словаря и неспособности эффективно моделировать сложные зависимости между пикселями, реконструированные изображения страдали от потери деталей и нечеткости. Одномерная токенизация, последовательно преобразуя изображение в последовательность токенов, также демонстрировала аналогичные недостатки, особенно при работе с изображениями высокого разрешения, где сложность моделирования длинных последовательностей приводила к потере информации и снижению качества реконструкции.
Модели с механизмом внимания (Attentive Encoding) и рекуррентного внимания (Recurrent Attention Models) представляли собой улучшение по сравнению с ранними методами токенизации изображений, поскольку позволяли выборочно фокусироваться на релевантных областях изображения. Это достигалось за счет использования механизмов внимания, которые динамически взвешивали различные части изображения при генерации токенов. Однако, применение механизмов внимания требовало значительных вычислительных ресурсов, особенно при обработке изображений высокого разрешения. Сложность вычислений внимания растет квадратично с увеличением количества пикселей, что делало эти модели ресурсоемкими и ограничивало их масштабируемость для задач, требующих обработки больших объемов данных или работы в реальном времени.
Модели MaskGIT и последовательная токенизация продемонстрировали потенциал подхода маскированного моделирования изображений, позволяя генерировать изображения путем последовательного предсказания скрытых фрагментов. Однако, в отличие от некоторых других методов, они не имели встроенного механизма для сопоставления дискретных токенов с устоявшимися визуальными семантическими категориями или объектами. Это ограничивало возможность контролировать процесс генерации изображений на уровне конкретных объектов или атрибутов и затрудняло интерпретацию полученных токенов с точки зрения визуального содержания.

COMiT: Коммуникационный Токенизатор Изображений
COMiT использует итеративный процесс кодирования фрагментов изображения в токены, их передачи в латентное пространство и последующей реконструкции. В ходе каждой итерации происходит уточнение представления токенов на основе ошибки реконструкции. Этот цикл позволяет модели последовательно улучшать качество кодирования и декодирования, оптимизируя представление изображения в латентном пространстве. В процессе итераций происходит не только снижение ошибки реконструкции, но и повышение устойчивости представления к шуму и вариациям в данных. В результате, модель обучается создавать более компактные и информативные токены, эффективно представляющие исходное изображение.
В основе COMiT лежит обучение устойчивого и эффективного латентного пространства для токенов изображения посредством комбинации методов Flow Matching и автоэнкодеров. Flow Matching используется для создания непрерывного отображения между токенами и латентным пространством, обеспечивая плавную и контролируемую трансформацию данных. Автоэнкодеры, в свою очередь, позволяют сжимать данные в латентное представление, а затем восстанавливать их, минимизируя потери информации и способствуя обучению компактного и информативного латентного пространства. Комбинирование этих подходов обеспечивает высокую эффективность кодирования и декодирования изображений, а также устойчивость к шуму и вариациям данных.
В COMiT используется адаптивная политика кадрирования, сочетающая глобальное и локальное кадрирование для эффективного захвата как широкого контекста, так и мелких деталей при кодировании и декодировании изображений. Глобальное кадрирование обеспечивает учет общей композиции и структуры изображения, в то время как локальное кадрирование фокусируется на конкретных областях, позволяя более точно захватывать детализированную информацию. Комбинация этих подходов позволяет модели COMiT эффективно представлять изображение в виде токенов, сохраняя как общую семантику, так и важные локальные признаки, что улучшает качество реконструкции и повышает эффективность кодирования.

Проверка COMiT: Производительность и Обобщение
Проверка методом классификационного зондирования (Classification Probing) подтверждает, что COMiT формирует осмысленные и различимые представления изображений. Данный метод заключается в обучении линейного классификатора на основе скрытых представлений, полученных COMiT, для предсказания меток классов изображений. Высокая точность классификации, достигнутая в ходе этих экспериментов, свидетельствует о том, что COMiT эффективно извлекает и кодирует визуальную информацию, необходимую для различения различных объектов и сцен. Это указывает на способность модели к формированию богатых и информативных представлений, пригодных для последующих задач компьютерного зрения.
Представления токенов, формируемые COMiT, могут быть сопоставлены с существующими визуальными семантическими категориями посредством методов, таких как Выравнивание Распространения Представлений (Representation Propagation Alignment, REPA). REPA позволяет переносить знания из предварительно обученных моделей визуальной семантики на токены COMiT, улучшая интерпретируемость и обобщающую способность модели. Этот процесс включает в себя определение соответствий между токенами COMiT и существующими визуальными понятиями, что позволяет использовать накопленные знания для улучшения понимания сцены и повышения точности сегментации.
Оценка модели COMiT на наборе данных MSCOCO показала ее превосходство в обобщении состава, что свидетельствует о способности модели понимать сложные взаимосвязи между объектами. Достигнутый средний показатель Intersection over Union (mIoU) составил 0.58 при использовании карт внимания из 24-го слоя. Данный результат демонстрирует, что COMiT эффективно выявляет и использует информацию о взаиморасположении объектов для точного определения границ и их взаимодействия в изображении.
Результаты тестирования COMiT на наборе данных Visual Genome демонстрируют его превосходство над существующими моделями в задачах семантического зондирования и реляционного рассуждения. В ходе экспериментов COMiT последовательно показывал более высокие показатели точности в определении семантических свойств объектов и установлении связей между ними по сравнению с альтернативными подходами. Данные результаты подтверждают способность COMiT к более глубокому пониманию визуальной информации и эффективному анализу сложных сцен, что делает его перспективным решением для задач компьютерного зрения, требующих как распознавания объектов, так и понимания их взаимосвязей.
Будущие Направления: К Интеллектуальным Системам Зрения
Предлагаемый подход COMiT, использующий дискретное токенизированное представление изображений, открывает значительные возможности для оптимизации хранения и передачи данных. В отличие от традиционных методов, работающих с массивами пикселей, COMiT позволяет сжимать визуальную информацию в компактные токены, что особенно важно для устройств с ограниченными ресурсами, таких как мобильные роботы и периферийные вычислительные системы. Это снижение требований к пропускной способности и объему памяти не только ускоряет обработку изображений, но и делает возможным развертывание сложных систем компьютерного зрения непосредственно на краю сети, расширяя спектр применений, от автономной навигации до оперативной диагностики в удаленных районах. Такой подход к представлению данных позволяет создавать более эффективные и масштабируемые системы, способные обрабатывать визуальную информацию в режиме реального времени, даже в условиях ограниченных ресурсов.
Исследования направлены на объединение архитектуры COMiT с крупными языковыми моделями, что позволит создать мультимодальные системы, способные бесшовно интегрировать визуальную и текстовую информацию. Такой подход предполагает, что визуальные данные, представленные в виде дискретных токенов COMiT, могут быть эффективно использованы в качестве входных данных для языковых моделей, расширяя их возможности понимания и генерации контента. В результате, системы смогут не только распознавать объекты на изображениях, но и описывать их, отвечать на вопросы о визуальной сцене и даже генерировать связные тексты, основанные на визуальном контексте. Данное направление исследований обещает значительный прогресс в создании искусственного интеллекта, способного к комплексному анализу и интерпретации информации из различных источников.
В отличие от традиционных систем компьютерного зрения, обрабатывающих изображения на уровне отдельных пикселей, разработанная модель COMiT переходит к дискретному представлению визуальной информации. Такой подход позволяет системе оперировать не с сырыми данными изображения, а с абстрактными, осмысленными токенами, что значительно упрощает задачу понимания сцены. Это открывает путь к созданию интеллектуальных систем, способных не просто распознавать объекты, но и устанавливать между ними взаимосвязи, делать логические выводы и, в конечном итоге, демонстрировать настоящее понимание происходящего на изображении. Благодаря этому, COMiT представляет собой важный шаг на пути к созданию систем компьютерного зрения, способных к рассуждениям и принятию решений, приближая их к человеческому зрению.

Исследование, представленное в данной работе, демонстрирует, что организация визуальных данных может быть значительно улучшена за счёт подхода, вдохновлённого принципами коммуникации. Авторы предлагают рассматривать процесс токенизации как итеративное взаимодействие, в котором информация последовательно передаётся и реконструируется. Это созвучно идеям Дэвида Марра, который утверждал: «Главная задача когнитивной науки — понять, как мозг преобразует информацию, а не просто её хранит». Подобно тому, как мозг обрабатывает сенсорные данные, COMiT стремится создать структурированные представления изображений, где каждый токен несёт в себе значимую семантическую информацию. Такой подход, фокусирующийся на преобразовании и организации данных, открывает новые возможности для достижения более эффективных и интерпретируемых моделей.
Что дальше?
Представленный подход к токенизации изображений, вдохновленный принципами коммуникации, открывает интересные перспективы, но, как и любое упрощение сложной реальности, неизбежно оставляет вопросы. Замечательно, что алгоритм демонстрирует улучшенную семантическую организацию, однако истинная мера успеха — не в достижении лучших показателей на текущих бенчмарках, а в способности системы адаптироваться к принципиально новым задачам, к данным, которые выходят за рамки привычных паттернов. Каждое отклонение от идеала, каждая аномалия в процессе реконструкции — это возможность выявить скрытые зависимости, которые ускользают от внимания при работе с «чистыми» данными.
Особый интерес представляет исследование влияния структуры «коммуникации» между токенами на конечное качество представления. Можно предположить, что оптимизация не только самого процесса реконструкции, но и «топологии» обмена информацией между токенами, позволит добиться более гибких и устойчивых представлений. Важно также исследовать, как этот подход масштабируется на более сложные и многообразные типы данных, например, видео или трехмерные сцены.
По сути, задача состоит не в создании «идеального» токенизатора, а в разработке системы, способной учиться на своих ошибках, адаптироваться к новым условиям и, возможно, даже неожиданным образом открывать новые закономерности в визуальном мире. Именно в этих отклонениях, в этих «шумах», и кроется подлинный потенциал для развития искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.20731.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-25 13:07