Автор: Денис Аветисян
Новый подход позволяет значительно повысить эффективность обучения больших мультимодальных моделей, фокусируясь на наиболее информативных визуальных данных.
В статье представлена метрика Visual Information Gain (VIG) для оценки вклада визуальной информации и метод селективного обучения, снижающий галлюцинации и повышающий эффективность использования данных.
Несмотря на впечатляющие успехи больших мультимодальных моделей, они часто склонны к генерации ответов, не опирающихся на визуальную информацию. В работе ‘Selective Training for Large Vision Language Models via Visual Information Gain’ предложен новый подход, основанный на метрике Visual Information Gain (VIG), количественно оценивающей вклад визуальных данных в процесс предсказания. Показано, что селективное обучение моделей на данных с высоким VIG позволяет существенно улучшить визуальное обоснование ответов, снизить склонность к галлюцинациям и повысить эффективность использования обучающих данных. Какие еще возможности открывает точная оценка вклада визуальной информации для создания более надежных и эффективных мультимодальных систем?
Иллюзия понимания: Текстовая предвзятость в больших визуально-языковых моделях
Все большее распространение получают большие визуально-языковые модели (LVLM), однако наблюдается тенденция к чрезмерной зависимости от предварительных текстовых знаний, а не от непосредственного анализа визуальной информации. Этот феномен проявляется в том, что модели склонны опираться на статистические закономерности, усвоенные из огромных текстовых корпусов, даже если эти закономерности противоречат представленной визуальной сцене. Вместо того чтобы действительно «видеть» и интерпретировать изображение, модели часто предсказывают наиболее вероятный текст, исходя из языкового контекста, что приводит к ошибочным выводам и иллюзии понимания. Таким образом, несмотря на впечатляющие возможности генерации текста по изображениям, LVLM часто демонстрируют поверхностное, а не глубокое мультимодальное восприятие.
Языковая предвзятость в больших визуально-языковых моделях (LVLM) приводит к тому, что они часто делают неточные прогнозы, даже при наличии богатого визуального ввода. Вместо того, чтобы интегрировать визуальную информацию для формирования ответа, модели склонны полагаться на заранее заданные языковые паттерны и ассоциации, что препятствует подлинному мультимодальному пониманию. По сути, модель может генерировать правдоподобный, но ошибочный ответ, поскольку ее «мышление» основано скорее на статистической вероятности слов, чем на фактическом содержании изображения. Это демонстрирует фундаментальный недостаток в способности модели рассуждать и понимать мир, как это делают люди, где визуальное восприятие и языковое понимание тесно взаимосвязаны.
В результате предвзятости к тексту, большие визуально-языковые модели (LVLM) способны генерировать ответы, кажущиеся правдоподобными, но фактически не соответствующие визуальной информации. Этот феномен демонстрирует фундаментальный недостаток в их способности к рассуждению — модель опирается на языковые шаблоны и ожидания, а не на реальное понимание представленных изображений. Таким образом, даже при наличии богатых визуальных данных, модель может выдать логически связный, но ошибочный ответ, что подчеркивает важность разработки методов, позволяющих снизить зависимость от текстовых приоритетов и повысить качество мультимодального анализа.

Измерение визуального обоснования: Роль информационного прироста
Визуальный информационный прирост (VIG) представляет собой ключевую метрику для оценки степени, в которой предсказания модели обусловлены визуальными входными данными. VIG позволяет количественно оценить изменение вероятности предсказания при добавлении визуальной информации, что дает возможность определить, действительно ли модель использует изображение для формирования своих выводов. Фактически, VIG измеряет, насколько сильно предсказания модели изменяются при наличии или отсутствии визуального сигнала, предоставляя объективную оценку её зависимости от визуального ввода и позволяя отличить модели, которые действительно «видят» изображение, от тех, которые полагаются на другие источники информации или эвристики.
Визуальный прирост информации (VIG) количественно оценивает изменение вероятности предсказания модели при введении визуальных данных. По сути, VIG измеряет, насколько сильно предсказание модели зависит от информации, полученной из изображения. Если предсказание существенно меняется при наличии изображения по сравнению с его отсутствием (например, при использовании зашумленного или размытого изображения), это указывает на то, что модель действительно использует визуальную информацию для формирования своего ответа. Низкий VIG, напротив, может свидетельствовать о том, что модель полагается на другие входные данные или использует визуальную информацию недостаточно эффективно, что ставит под сомнение её способность к реальному «зрению».
Вычисление визуального информационного прироста (VIG) основывается на метрике перплексии, позволяющей количественно оценить изменение вероятности предсказания модели при введении визуальной информации. Для более точной изоляции зависимости от визуальных данных применяются методы, такие как использование размытых изображений. Размытие эмулирует потерю информации, что позволяет оценить, насколько существенно визуальное содержимое для формирования предсказания. Разница в перплексии между предсказаниями, основанными на исходном и размытом изображениях, позволяет определить степень влияния визуального ввода на результат работы модели. VIG = P(y|x) - P(y|x_{blurred}), где P(y|x) — вероятность предсказания y при наличии изображения x, а x_{blurred} — размытое изображение.
Усиление визуального обоснования: VIG-guided селективное обучение
Метод VIG-Guided Selective Training представляет собой новый подход к улучшению визуального обоснования в больших многомодальных языковых моделях (LVLM). Он основан на использовании оценки VIG (Visual Importance Gain) для определения наиболее значимых визуальных элементов в обучающих данных. В отличие от традиционных методов, которые обрабатывают все обучающие данные одинаково, VIG-Guided Selective Training динамически приоритизирует выборку данных, фокусируясь на тех образцах, которые содержат наиболее информативные визуальные признаки, что позволяет повысить эффективность обучения и улучшить способность модели связывать текст и визуальную информацию.
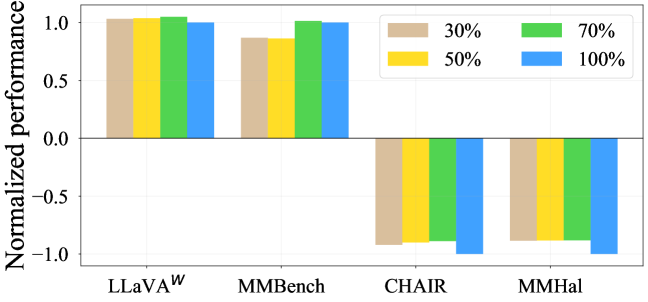
Метод VIG-Guided Selective Training осуществляет приоритизацию обучающих выборок и токенов с высоким значением VIG (Visual Information Gain), что позволяет модели концентрироваться на визуально значимых элементах изображения. В ходе обучения это достигается путем увеличения веса данных с высоким VIG, что способствует улучшению производительности модели при использовании лишь 70% от исходного объема обучающих данных. Такой подход позволяет эффективно обучать модель, фокусируясь на наиболее информативных визуальных признаках и снижая зависимость от текстовых подсказок.
Стратегия, основанная на избирательном усилении влияния визуальной информации в процессе обучения, направлена на развитие подлинного мультимодального понимания у моделей. Вместо слепого запоминания текстовых подсказок и шаблонов, модель стимулируется к активному анализу визуальных признаков, что позволяет ей формировать более глубокие связи между текстом и изображением. Это достигается за счет приоритизации обучающих примеров, где визуальная информация играет ключевую роль, и подавления примеров, в которых доминируют текстовые упрощения. В результате, модель становится менее склонной к использованию текстовых «ярлыков» для выполнения задач визуального обоснования и демонстрирует повышенную точность в сценариях, требующих реального понимания визуального контента.

Оценка мультимодального понимания: Комплекс оценок
Для всесторонней оценки возможностей больших мультимодальных моделей (LVLM) необходим широкий спектр бенчмарков. Такие наборы данных, как MMVet, MMBench и DocVQA, представляют собой критически важные инструменты для измерения эффективности этих моделей в решении различных задач, охватывающих понимание изображений, текста и их совместную обработку. Использование нескольких бенчмарков позволяет не только оценить общую производительность, но и выявить сильные и слабые стороны каждой модели в конкретных областях, что способствует более целенаправленной разработке и совершенствованию алгоритмов. Разнообразие задач, представленных в этих наборах данных, гарантирует, что оценка будет комплексной и отразит реальные сценарии применения мультимодальных моделей.
Для оценки степени галлюцинаций в моделях, работающих с различными типами данных, используются специализированные метрики, такие как CHAIR и POPE. Первая позволяет оценить достоверность текстовых описаний, а POPE — точность определения объектов на изображениях. Исследования показали, что модели, обученные с применением VIG (Vision-and-Instruction Grounding), демонстрируют значительное улучшение — более 10% — по метрике POPE, измеряемой с помощью F1-score. Это свидетельствует о том, что применение VIG позволяет существенно снизить вероятность ложного определения объектов и повысить надежность визуального понимания моделей.
Разработанный комплекс MMHal представляет собой специализированную систему оценки, нацеленную на выявление и анализ галлюцинаций в моделях, работающих с различными типами данных. В отличие от общих бенчмарков, MMHal обеспечивает детальную проверку способности модели генерировать правдивые и соответствующие действительности описания, фокусируясь исключительно на проблеме «галлюцинаций» — то есть, создании информации, не подкрепленной входными данными. Такой подход позволяет точно определить слабые места в архитектуре модели и направляет усилия по улучшению ее надежности и точности. Результаты, полученные с использованием MMHal, дополняют данные, полученные на более широких бенчмарках, предоставляя комплексное представление о производительности модели и стимулируя разработку более совершенных алгоритмов.
К надёжному мультимодальному ИИ: Уточнение визуального обоснования
Контрастивное декодирование представляет собой перспективную методику, применяемую непосредственно во время работы искусственного интеллекта, направленную на снижение влияния языковой предвзятости. Суть подхода заключается в сопоставлении результатов, полученных с учетом визуального ввода, и результатов, полученных без него. Эта процедура позволяет модели выявлять и корректировать ответы, которые чрезмерно зависят от лингвистических шаблонов, а не от фактического визуального содержания. Таким образом, контрастивное декодирование способствует более надежной и объективной интерпретации мультимодальных данных, повышая устойчивость системы к манипуляциям и искажениям в текстовых запросах, что особенно важно для приложений, требующих высокой точности и беспристрастности.
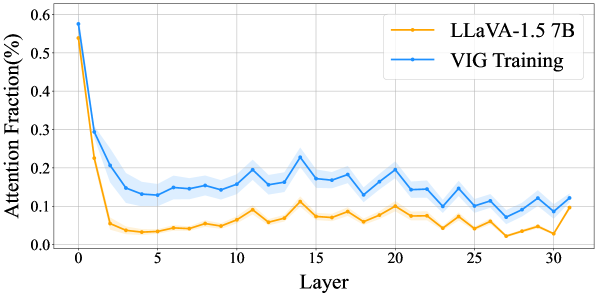
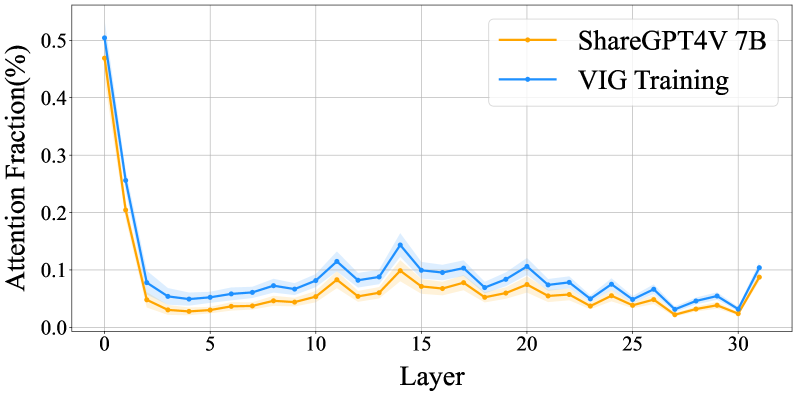
Механизм внимания играет ключевую роль в процессе визуального обоснования, позволяя модели концентрироваться на наиболее релевантных областях изображения. Вместо обработки изображения целиком, модель способна динамически выделять и взвешивать различные участки, сопоставляя их с текстовым запросом. Это достигается путем присвоения каждому региону изображения «веса внимания», отражающего его значимость для понимания запроса. Благодаря этому, модель может эффективно игнорировать несущественную информацию и сосредоточиться на объектах или деталях, непосредственно связанных с поставленной задачей, значительно повышая точность и надежность мультимодальных систем искусственного интеллекта.
Дальнейшие исследования, использующие обширные наборы данных, такие как MS-COCO, имеют решающее значение для создания действительно надёжных и устойчивых мультимодальных систем искусственного интеллекта. Модели, обученные с использованием метода VIG (Visual Information Grounding), демонстрируют повышенную устойчивость к искажениям в текстовых запросах, достигая точности до 39.3% даже при наличии текстовой коррупции. Это указывает на перспективность VIG в качестве подхода к снижению зависимости от текстового ввода и повышению надёжности систем, работающих с визуальной и текстовой информацией, что особенно важно для приложений, требующих высокой степени точности и устойчивости к ошибкам.

Исследование демонстрирует, что эффективное обучение больших визуально-языковых моделей требует не просто увеличения объема данных, а и осознанного отбора наиболее информативных примеров. Как отмечает Эндрю Ын: «Мы должны сосредоточиться на том, что действительно имеет значение». Данная работа, вводя метрику Visual Information Gain (VIG), позволяет количественно оценить вклад визуальной информации в мультимодальные данные. Использование VIG для селективного обучения позволяет снизить склонность моделей к галлюцинациям и повысить эффективность использования данных, подтверждая, что понимание закономерностей в данных — ключевой фактор успешного обучения, а не слепое накопление информации.
Куда Ведет Этот Путь?
Представленный подход, измеряющий вклад визуальной информации в мультимодальные данные посредством метрики Visual Information Gain (VIG), безусловно, открывает новые горизонты в обучении больших визуально-языковых моделей. Однако, следует признать, что количественная оценка «вклада» — задача, всегда сопряженная с определенной долей субъективности. По сути, VIG — это лишь одна из возможных проекций сложной взаимосвязи между визуальным и языковым компонентами, и её адекватность будет определяться спецификой решаемых задач.
Особый интерес представляет возможность использования VIG не только для селективного обучения, но и для выявления «узких мест» в существующих моделях. Понимание того, какие именно визуальные паттерны вызывают наибольшие трудности, позволит сконцентрировать усилия на разработке более эффективных архитектур и алгоритмов обучения. Необходимо помнить, что снижение «галлюцинаций» — это не просто устранение нежелательного поведения, а углубление понимания системой реальных закономерностей.
В конечном счете, успех этого направления будет зависеть от способности исследователей выйти за рамки простых метрик и разработать более комплексные методы оценки «информативности» данных. Ведь визуальное восприятие — это не просто набор пикселей, а сложный процесс интерпретации, требующий учета контекста, знаний о мире и, возможно, даже некоторой доли интуиции. И, как часто бывает, самые интересные открытия ждут тех, кто готов поставить под сомнение общепринятые истины.
Оригинал статьи: https://arxiv.org/pdf/2602.17186.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
2026-02-22 12:34