Автор: Денис Аветисян
Новая архитектура позволяет смартфонам понимать и генерировать изображения, открывая возможности для мультимодальных приложений непосредственно на устройстве.
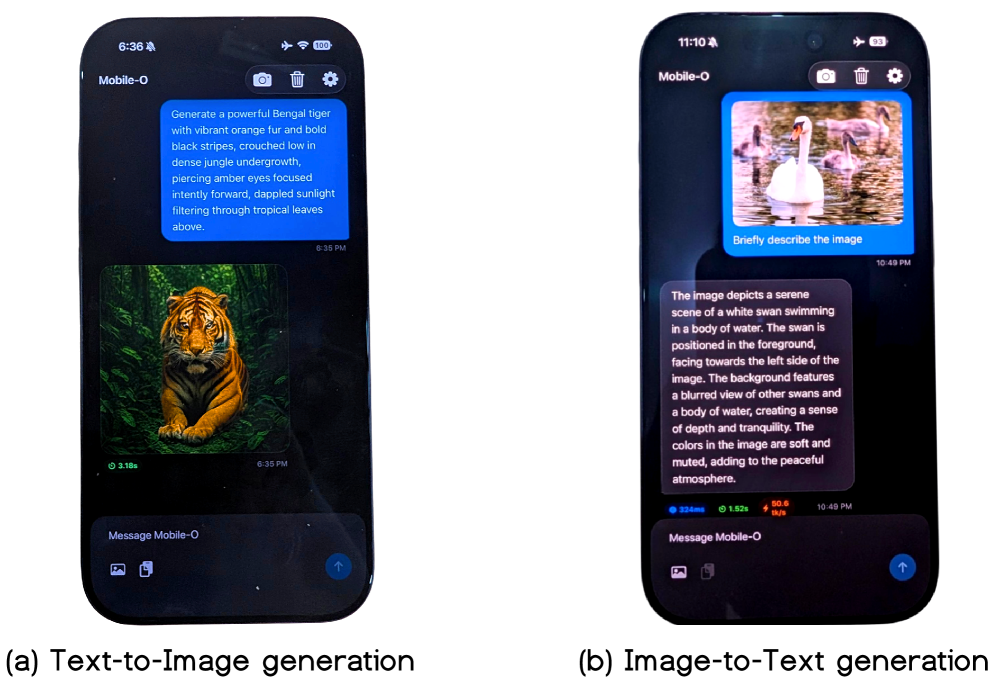
Представлена компактная и эффективная унифицированная мультимодальная модель Mobile-O для выполнения задач визуального понимания и генерации на мобильных устройствах.
Несмотря на значительный прогресс в области мультимодального искусственного интеллекта, объединение возможностей понимания и генерации визуального контента в рамках компактной модели, пригодной для развертывания на мобильных устройствах, остается сложной задачей. В данной работе представлена модель ‘Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device’, предлагающая эффективное решение этой проблемы за счет архитектуры, объединяющей визуальное и языковое представления с помощью диффузионной модели. Ключевым элементом является модуль Mobile Conditioning Projector (MCP), обеспечивающий кросс-модальное согласование с минимальными вычислительными затратами, что позволяет достичь конкурентоспособной или превосходящей производительности по сравнению с другими унифицированными моделями, при этом работая в 6-11 раз быстрее. Возможно ли создание полностью автономных мультимодальных систем, способных к обучению и адаптации непосредственно на мобильных устройствах без необходимости подключения к облачным сервисам?
Понимание через Синтез: Преодоление Разрыва между Модальностями
Традиционные модели, работающие с визуальной и текстовой информацией, зачастую обрабатывают эти потоки данных раздельно, что существенно ограничивает их способность к комплексному мультимодальному рассуждению. Вместо полноценного взаимодействия и синтеза знаний, они оперируют с визуальными и текстовыми признаками как с независимыми сущностями. Это приводит к тому, что модель не может в полной мере понять контекст, установить сложные связи между изображением и текстом, и, как следствие, демонстрирует ограниченные возможности в задачах, требующих глубокого понимания взаимосвязи между этими модальностями. Подобный подход препятствует развитию систем искусственного интеллекта, способных воспринимать мир так, как это делает человек — интегрируя информацию, поступающую из разных источников.
Для достижения истинного понимания, объединяющего визуальную и текстовую информацию, необходимы архитектуры, способные эффективно сливать данные из обеих модальностей. Современные исследования показывают, что простое конкатенирование признаков часто оказывается недостаточным, требуя более сложных механизмов внимания и взаимодействия. Разрабатываемые модели стремятся не просто сопоставить изображение и текст, но и создать единое семантическое представление, позволяющее извлекать более глубокие и осмысленные взаимосвязи. Такие архитектуры используют различные стратегии, включая кросс-модальные трансформаторы и механизмы внимания, позволяющие модели фокусироваться на наиболее релевантных частях изображения и текста при формировании общего понимания. Это позволяет преодолеть ограничения традиционных подходов и приблизиться к созданию систем, способных рассуждать и делать выводы на основе мультимодальных данных, подобно человеческому восприятию.
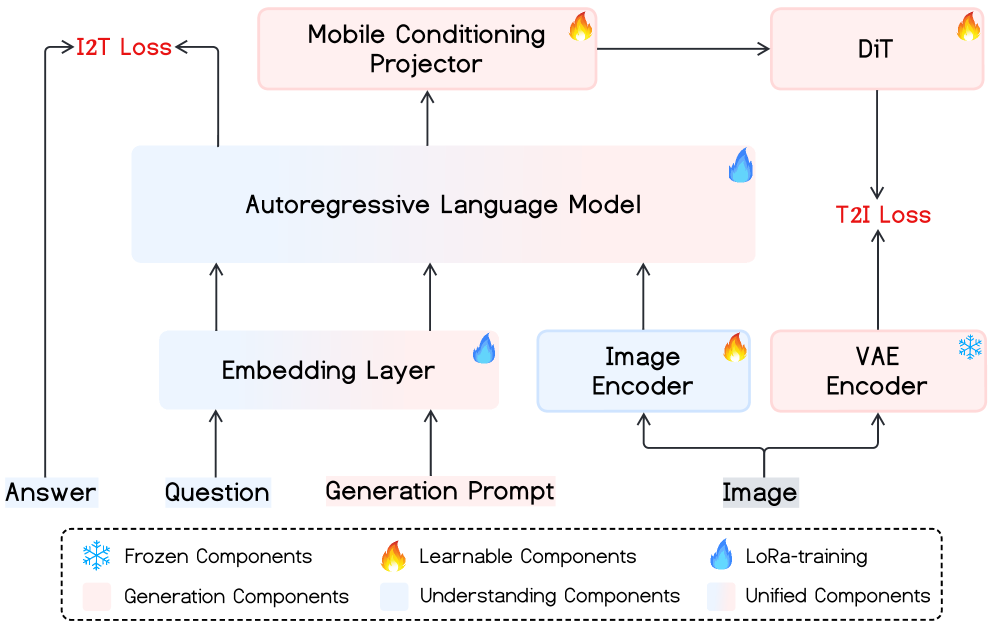
Mobile-O: Унифицированная Архитектура для Искусственного Интеллекта на Устройстве
Mobile-O представляет собой унифицированную мультимодальную модель, разработанную с учетом ограничений вычислительных ресурсов мобильных устройств. В отличие от традиционных подходов, требующих значительных объемов памяти и вычислительной мощности, Mobile-O оптимизирована для работы непосредственно на мобильных платформах, обеспечивая возможность выполнения сложных задач обработки и генерации данных без необходимости подключения к облачным сервисам. Ключевым аспектом является компактная архитектура модели, позволяющая снизить требования к памяти и энергопотреблению, что делает её пригодной для использования в широком спектре мобильных приложений и сценариев.
В архитектуре Mobile-O для бесшовной интеграции скрытых состояний визуально-языковой модели (VLM) с пространством обуславливания диффузионной модели используется модуль Mobile Conditioning Projector (MCP). MCP выполняет проекцию скрытых состояний VLM в пространство, совместимое с диффузионной моделью, что позволяет эффективно объединить визуальную и текстовую информацию. Этот процесс обеспечивает совместное использование представлений различных модальностей для генерации изображений на основе текстовых запросов и визуальных данных, при этом сохраняется компактность и эффективность модели для работы на мобильных устройствах.
Архитектура Mobile-O обеспечивает возможность как мультимодального понимания, так и генерации контента благодаря непосредственному соединению визуальных и текстовых представлений. Это позволяет модели создавать изображения в реальном времени — генерация изображения размером 512×512 пикселей на iPhone занимает приблизительно 3 секунды. Такая скорость достигается за счет оптимизации модели для работы на устройствах с ограниченными вычислительными ресурсами, что делает возможным выполнение сложных задач непосредственно на мобильном устройстве без необходимости обращения к облачным сервисам.
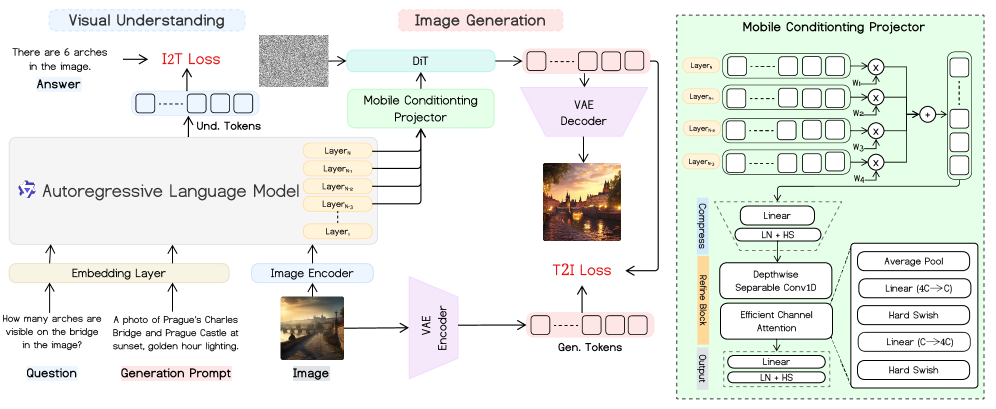
Унифицированное Пост-Обучение: Оптимизация для Мультимодального Мастерства
Модель Mobile-O обучается с использованием нового подхода постобучения, основанного на унифицированном наборе данных, состоящем из четверок (запрос для генерации, изображение, вопрос, ответ). Такая структура данных позволяет модели одновременно обрабатывать и сопоставлять текстовые запросы, визуальную информацию и соответствующие вопросы с ответами. Этот подход обеспечивает одновременное обучение модели пониманию взаимосвязей между различными модальностями данных, что способствует улучшению ее способности к обобщению и решению задач, требующих мультимодального анализа.
Оптимизация Mobile-O использует ряд методов для повышения эффективности и стабильности обучения. LoRA (Low-Rank Adaptation) позволяет адаптировать модель с меньшим количеством обучаемых параметров, снижая вычислительные затраты и требования к памяти. Использование формата BF16 (BFloat16) обеспечивает ускорение вычислений и снижение потребления памяти по сравнению с FP32, сохраняя при этом достаточную точность. Для обеспечения стабильной сходимости применяется ZeRO-3 (Zero Redundancy Optimizer), который разделяет состояния оптимизатора, градиенты и параметры модели между несколькими GPU, снижая требования к памяти каждого устройства. Наконец, Cosine Annealing — это метод изменения скорости обучения, который постепенно снижает ее в процессе обучения, что способствует более плавной сходимости и предотвращает переобучение.
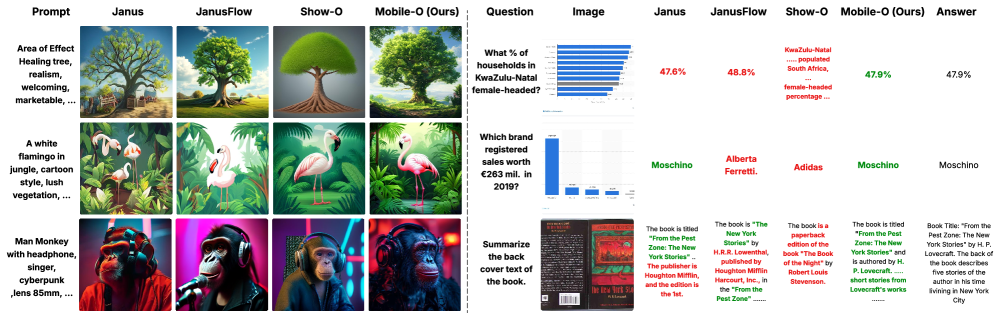
В результате применения описанного подхода к обучению модель демонстрирует среднюю точность понимания в 66.2%, что на 1.4% выше показателей, достигнутых на этапе SFT (Supervised Fine-Tuning) по семи стандартным бенчмаркам. Кроме того, модель достигла показателя GenEval в 0.74, что на 5.0% превосходит результаты модели Show-O. Данные метрики подтверждают эффективность предложенной методики оптимизации для повышения производительности мультимодальных моделей.
Развертывание на Устройстве и Перспективы Развития
Mobile-O разработан с акцентом на эффективное развертывание непосредственно на пользовательских устройствах, что достигается за счет использования специализированных фреймворков, таких как CoreML и MLX. Эти инструменты позволяют оптимизировать модель для работы на мобильных процессорах, обеспечивая высокую скорость обработки и снижая зависимость от облачных вычислений. В результате, становится возможным выполнять сложные задачи, связанные с генерацией изображений, локально, без передачи данных на внешние серверы, что значительно повышает конфиденциальность и оперативность взаимодействия пользователя с системой.
Для значительной оптимизации модели и обеспечения её эффективной работы на мобильных устройствах, в ключевом модуле обработки (MCP) были внедрены свёрточные операции, разделенные по глубине (Depthwise Separable Convolutions). Этот подход позволяет существенно снизить вычислительную нагрузку и объём необходимых параметров, что особенно важно для устройств с ограниченными ресурсами. В результате, на платформе NVIDIA Jetson Orin Nano, модель демонстрирует впечатляющую скорость генерации изображений — около 4 секунд. Такая производительность открывает возможности для создания приложений, работающих в режиме реального времени, непосредственно на пользовательских устройствах, без необходимости передачи данных на удалённые серверы.
Модель Mobile-O, насчитывающая 1,6 миллиарда параметров, демонстрирует значительное преимущество в эффективности по сравнению с альтернативными решениями, такими как JanusFlow (2,1 млрд параметров) и Show-O (2,6 млрд параметров). Эта компактность открывает возможности для нового поколения персонализированных и конфиденциальных приложений искусственного интеллекта, способных функционировать непосредственно на пользовательских устройствах. Благодаря сниженным требованиям к вычислительным ресурсам и памяти, Mobile-O позволяет осуществлять обработку данных локально, устраняя необходимость отправки информации на удаленные серверы и, таким образом, обеспечивая повышенную защиту личных данных. Это, в свою очередь, способствует развитию приложений, способных к мгновенному, интерактивному мультимодальному взаимодействию, что ранее было затруднительно из-за ограничений по производительности и конфиденциальности.

Исследование демонстрирует, что эффективное мультимодальное понимание и генерация контента непосредственно на мобильных устройствах требует компромисса между вычислительной сложностью и производительностью. Модель Mobile-O, представленная в работе, наглядно это подтверждает, демонстрируя возможность достижения приемлемого качества обработки визуальной информации и генерации изображений в условиях ограниченных ресурсов. Как однажды заметил Эндрю Ын: «Самое важное — это не создание сложных моделей, а понимание данных, на которых они обучаются». Это высказывание особенно актуально в контексте Mobile-O, где оптимизация модели для работы на мобильных устройствах неразрывно связана с глубоким анализом и пониманием характеристик визуальных и текстовых данных.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал унифицированных мультимодальных моделей на мобильных платформах. Однако, не стоит забывать о фундаментальной проблеме: границы данных, особенно в задачах генерации, остаются коварными ловушками. Достижение истинной «универсальности» требует не просто увеличения объёма обучающих данных, но и разработки методов, способных критически оценивать их качество и предвзятость. В противном случае, рискуем получить не разумного помощника, а эхо-камеру собственных иллюзий.
Особый интерес представляет вопрос о масштабируемости. Успешное развёртывание модели на мобильном устройстве — это лишь первый шаг. Необходимо исследовать возможности адаптации к различным аппаратным конфигурациям и оптимизации энергопотребления. Более того, следует учитывать, что “понимание” — это не просто распознавание образов, а способность к абстракции и обобщению. Достижение этой цели потребует новых архитектур и алгоритмов, способных моделировать причинно-следственные связи и контрфактическое мышление.
В конечном счёте, будущее мультимодальных моделей на мобильных устройствах зависит от нашей способности задавать правильные вопросы. Не “что машина может сделать?”, а “что машина должна делать?”. И, что ещё важнее, как обеспечить, чтобы её действия соответствовали нашим ценностям и этическим принципам. Иначе, технологический прогресс рискует стать лишь отражением наших собственных слабостей.
Оригинал статьи: https://arxiv.org/pdf/2602.20161.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Искусственный интеллект и квантовая физика: кто кого?
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Оживший аватар: Генерация видео в реальном времени по голосу
- Серебро и медь: новый взгляд на наноаллои
- Единый язык материи: как научные модели учатся понимать мир
- Автопилот, который видит мир: новый подход к автономному вождению
- Нейросеть нового поколения: Nemotron 3 Nano для продвинутого ИИ
- Python или SQL: Где кроется слабость языковых моделей?
2026-02-24 06:45