Автор: Денис Аветисян
Исследователи представили V-REX — комплексную платформу для оценки способности моделей понимать и последовательно анализировать визуальную информацию.

V-REX — это бенчмарк и методология «цепочки вопросов» для оценки многоступенчатого исследовательского визуального мышления в моделях «зрение-язык».
Несмотря на успехи современных мультимодальных моделей в ответах на конкретные вопросы, их способность к сложному визуальному рассуждению, требующему последовательного исследования и анализа, остается ограниченной. В данной работе представлена методика и бенчмарк ‘V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions’ для оценки многоступенчатого исследовательского визуального мышления, использующая цепочку вопросов (Chain-of-Questions). Анализ современных моделей показал различия в их способности к планированию последовательности действий и выполнению этих действий для получения окончательного ответа. Каковы перспективы развития моделей, способных эффективно и самостоятельно проводить визуальное исследование и делать обоснованные выводы?
Вызов Сложного Визуального Рассуждения
Современные модели, объединяющие зрение и язык, известные как VLMs, демонстрируют значительные трудности при решении задач, требующих последовательного, многоступенчатого рассуждения. В отличие от простых задач, где ответ можно получить напрямую из входных данных, сложные сценарии, например, понимание причинно-следственных связей в изображении или планирование действий для достижения определенной цели, требуют от модели не только распознавания объектов, но и способности выстраивать логическую цепочку, делать промежуточные выводы и учитывать контекст. Это ограничение существенно снижает эффективность VLMs в реальных приложениях, где часто требуется анализ сложных визуальных ситуаций и принятие обоснованных решений на основе полученной информации, например, в робототехнике, автономном вождении или медицинской диагностике. Неспособность к последовательному рассуждению становится критическим препятствием для создания по-настоящему интеллектуальных систем, способных решать сложные задачи, подобные тем, с которыми сталкивается человек.
Существующие оценочные тесты для моделей, работающих с изображениями и языком, зачастую не способны в полной мере проверить способность к исследовательскому мышлению. Эти тесты, как правило, предполагают наличие всей необходимой информации в изначальном представлении, в то время как реальные задачи требуют активного поиска и анализа дополнительных данных. Модели, успешно справляющиеся с традиционными тестами, могут демонстрировать существенные затруднения в ситуациях, когда необходимо самостоятельно формулировать вопросы, исследовать окружение и интегрировать полученные знания для достижения цели. Таким образом, для более точной оценки возможностей искусственного интеллекта в решении сложных задач необходимо разрабатывать новые, более реалистичные тесты, стимулирующие активное исследование и самостоятельный поиск информации.

V-REX: Эталон Исследовательского Рассуждения
V-REX разработан для строгой оценки способности визуальных языковых моделей (VLM) выполнять многоступенчатое исследовательское визуальное рассуждение, акцентируя внимание на активном сборе информации. В отличие от задач, требующих мгновенного ответа, V-REX проверяет, способна ли модель последовательно задавать вопросы и анализировать визуальные данные для достижения цели. Оценка проводится посредством имитации процесса активного поиска необходимой информации, что позволяет выявить способность модели к целенаправленному исследованию и извлечению релевантных сведений из визуального окружения. Данный подход позволяет более точно оценить способность VLM к решению сложных задач, требующих не просто распознавания объектов, но и активного взаимодействия с визуальным контентом.
В основе V-REX лежит фреймворк “Цепочка вопросов” (Chain-of-Questions, CoQ), который позволяет разлагать сложные задачи на последовательность подвопросов. Такой подход имитирует процесс решения проблем человеком, где для достижения конечной цели требуется последовательное получение и анализ информации. CoQ предполагает, что каждая стадия решения задачи формируется как ответ на конкретный подвопрос, а полученный ответ служит основой для формирования следующего вопроса, что обеспечивает структурированный и логичный процесс рассуждений. В V-REX данный фреймворк используется для оценки способности визуальных языковых моделей (VLM) к многоступенчатому исследованию и логическому выводу.
Набор данных V-REX состоит из 702 702 примеров и 2504 вопросов, что обеспечивает всестороннюю оценку способностей к рассуждению. Объем выборки позволяет проводить статистически значимые тесты и оценивать производительность моделей в различных ситуациях. Большое количество примеров и вопросов необходимо для надежной оценки и сравнения различных визуальных языковых моделей (VLM) в задачах, требующих многоступенчатого логического вывода и активного сбора информации. Размер набора данных обеспечивает достаточное покрытие различных сценариев и категорий рассуждений, что позволяет получить более полную картину возможностей VLM.
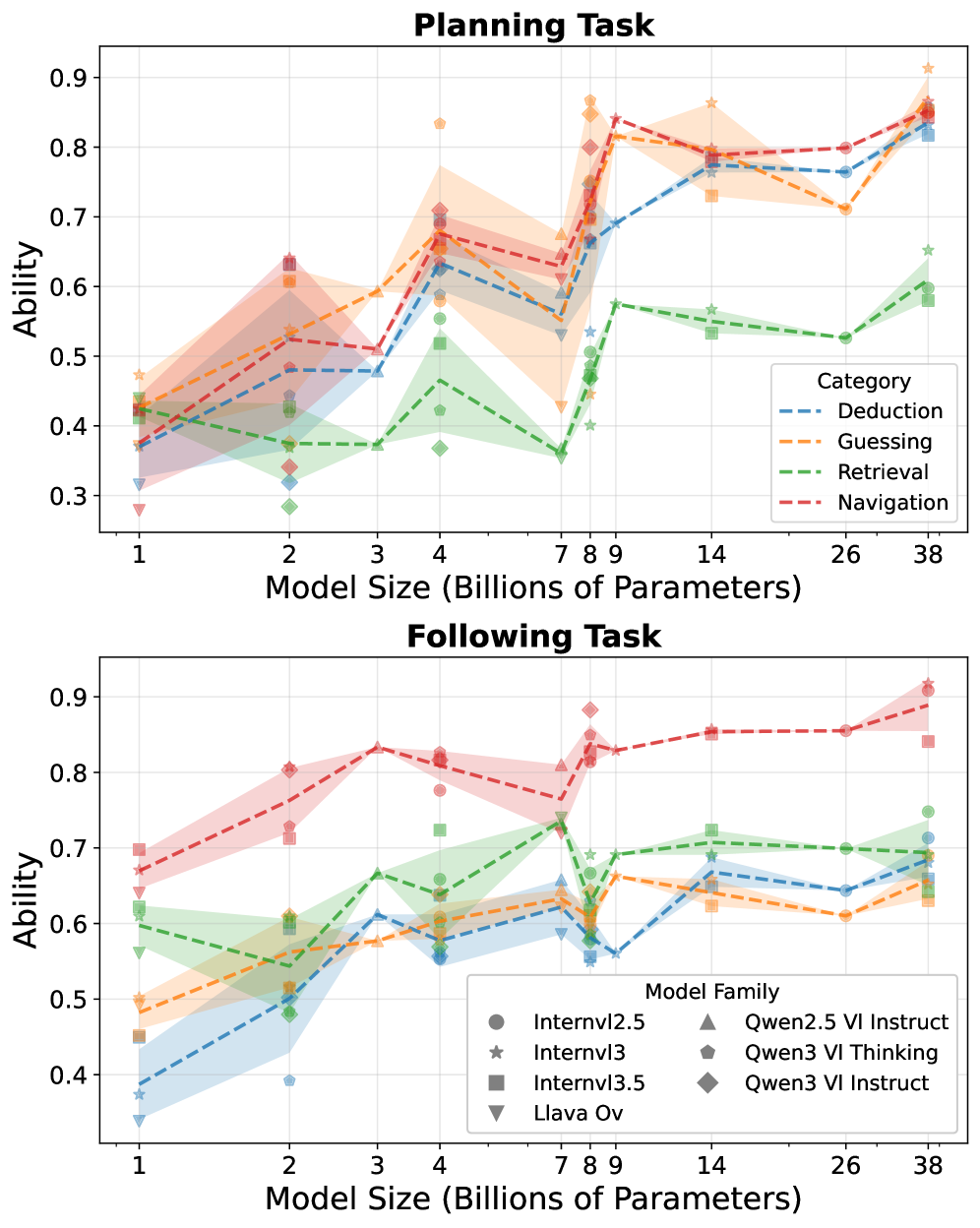
V-REX включает в себя разнообразные категории оценки рассуждений, такие как дедукция, угадывание, навигация и извлечение информации. Эти категории охватывают 44 различных типа рассуждений и применяются в 15 сценариях, представляющих собой практические ситуации. Такая структура позволяет комплексно оценить способности визуальных языковых моделей (VLM) к решению задач, требующих различных стратегий и адаптации к меняющимся условиям, и обеспечивает более полное понимание их возможностей в широком спектре сценариев.

Деконструкция Рассуждений: Планирование и Выполнение
В рамках V-REX, задача планирования (Planning Task) оценивает способность модели выделять вспомогательные подвопросы, необходимые для решения общей задачи. Это позволяет определить стратегическое мышление модели, поскольку успешное выполнение требует не просто обработки информации, но и декомпозиции сложной проблемы на более мелкие, управляемые компоненты. Оценка происходит на основе релевантности и достаточности выбранных подвопросов для последующего получения корректного ответа на исходный вопрос. Выбор подвопросов рассматривается как ключевой элемент планирования и демонстрация способности модели к логическому рассуждению.
Задача «Последование» в V-REX оценивает способность модели последовательно отвечать на выделенные подвопросы, что является ключевым показателем когерентности и логичности рассуждений. В ходе выполнения данной задачи, модель должна не просто предоставить ответы на каждый подвопрос, но и обеспечить их взаимосвязь и последовательность, формируя единую логическую цепочку. Оценка производится на основе корректности ответов на каждый подвопрос, а также на соответствие логической структуры ответов заданному плану рассуждений. Неспособность модели последовательно обрабатывать подвопросы указывает на ограничения в её способности к многошаговому логическому выводу и построению связных аргументов.
Предварительные результаты тестирования современных мощных визуально-языковых моделей (VLM) демонстрируют значительные трудности при выполнении задач планирования и последовательного решения подзадач. Наблюдаемые неудачи указывают на ограничения в способности моделей формулировать стратегический план рассуждений и эффективно его реализовывать, даже при наличии значительных вычислительных ресурсов и объема данных для обучения. Это свидетельствует о том, что простое масштабирование моделей не решает проблему глубокого логического мышления и требует разработки новых подходов к архитектуре и обучению.

Оценка Производительности и Роль Масштабирования Модели
Исследование, проведенное с использованием различных визуальных языковых моделей — LLaVA, InternVL и Qwen — выявило чёткую взаимосвязь между размером модели и её результативностью на бенчмарке V-REX. Наблюдаемая закономерность соответствует общепринятому закону масштабирования ($Scaling Law$), согласно которому увеличение числа параметров модели, как правило, приводит к улучшению её способностей. Данные, полученные в ходе экспериментов, подтверждают, что более крупные модели демонстрируют более высокую точность в решении задач визуального рассуждения, что указывает на значимость масштаба для достижения прогресса в области мультимодального искусственного интеллекта. Этот факт подчеркивает потенциал дальнейшего увеличения размеров моделей для улучшения их производительности, хотя и не является единственным фактором, определяющим качество работы.
Несмотря на очевидную корреляцию между размером модели и её производительностью, исследования показывают, что простое увеличение масштаба не является универсальным решением. Даже самые крупные языковые модели демонстрируют сложности при решении задач, требующих сложного логического мышления и многоступенчатого анализа. Это указывает на то, что для существенного улучшения способностей к рассуждению необходимы не только большие объемы параметров, но и инновационные архитектуры и методы обучения, способные преодолеть ограничения, связанные с обработкой абстрактных понятий и установлением причинно-следственных связей. Таким образом, увеличение масштаба является лишь одним из факторов, и для достижения прорывных результатов требуются комплексные подходы к разработке и обучению моделей.
Исследования выявили существенные слабости современных визуальных языковых моделей в области восстановления после ошибок. Модели зачастую демонстрируют неспособность скорректировать первоначальные неверные ответы, что критически затрудняет решение многошаговых задач, требующих последовательного логического вывода. Даже при наличии больших объемов данных и значительных вычислительных ресурсов, модели испытывают трудности с самокоррекцией и адаптацией к новым данным после совершения ошибки. Это указывает на необходимость разработки новых методов обучения и архитектур, направленных на повышение способности моделей к обнаружению и исправлению собственных ошибок, а также к более надежному выполнению сложных, требующих последовательности действий, задач.
Анализ задач, представленных в бенчмарке V-REX, выявил, что для успешного решения требуется в среднем 3,57 последовательных шагов логических рассуждений. Этот показатель позволяет провести детальную оценку когнитивных способностей визуальных языковых моделей (VLM), выходя за рамки общей метрики точности. Установление столь точного значения последовательности рассуждений открывает возможность для более адресной оптимизации архитектур VLM и разработки специализированных методов обучения, направленных на улучшение их способности к многоступенчатому решению задач и более глубокому пониманию визуальной информации. Такой подход позволяет не просто констатировать факт наличия или отсутствия решения, но и анализировать процесс мышления модели, что критически важно для создания действительно интеллектуальных систем.
Перспективы Развития: К Более Надежным и Исследовательским VLM
Платформа V-REX представляет собой ценный инструмент для продвижения исследований в области визуального рассуждения, предоставляя исследователям возможность разрабатывать и оценивать новые подходы к решению сложных задач. Она позволяет создавать разнообразные сценарии, требующие не просто распознавания объектов на изображении, а и логического вывода на основе визуальной информации. Благодаря V-REX, ученые могут более эффективно тестировать модели, определяя их способность к анализу, синтезу и применению знаний в контексте визуальных данных, что способствует созданию более интеллектуальных и надежных систем искусственного интеллекта, способных к решению реальных задач.
В дальнейших исследованиях особое внимание будет уделено усложнению сценариев, используемых для оценки визуальных языковых моделей (VLM). Предполагается внедрение более реалистичных и многогранных ситуаций, требующих от моделей не просто распознавания объектов, а и понимания контекста, причинно-следственных связей и скрытых взаимосвязей. Кроме того, планируется интеграция внешних знаний — фактов, здравого смысла и общедоступной информации — для углубления способности моделей к рассуждениям. Такой подход позволит не только повысить точность ответов, но и приблизить VLM к человеческому уровню понимания и принятия решений, преодолевая ограничения, связанные с недостатком контекста и общих знаний в текущих моделях.
Для дальнейшего повышения точности оценки способностей к визуальному мышлению, создатели V-REX планируют использовать возможности больших языковых моделей, таких как GPT-5, для автоматической генерации отвлекающих факторов в задачах. Вместо ручного создания этих факторов, которые могут быть предвзятыми или недостаточно сложными, GPT-5 позволит генерировать широкий спектр реалистичных и когнитивно сложных отвлекающих элементов. Это позволит более эффективно отделить истинное визуальное рассуждение от поверхностных закономерностей, которые могут быть освоены моделями без глубокого понимания визуальной информации. Внедрение такой системы генерации отвлекающих факторов значительно усложнит задачи для моделей, выявляя их слабые места и стимулируя разработку более надежных и интеллектуальных систем визуального мышления.

Представленное исследование демонстрирует важность последовательного, многошагового рассуждения в моделях, работающих с визуальной информацией. V-REX, как новый бенчмарк, позволяет оценить способность моделей не просто отвечать на вопросы, но и планировать последовательность действий для достижения цели. Это особенно важно, поскольку, как однажды заметил Ян Лекун: «Машинное обучение — это, по сути, поиск закономерностей в данных». Разработка V-REX позволяет более точно выявлять закономерности в способностях моделей к визуальному рассуждению, что, в свою очередь, способствует созданию более надёжных и эффективных систем искусственного интеллекта. Бенчмарк фокусируется на исследовании возможностей планирования и следования инструкциям, что является ключевым шагом к созданию действительно интеллектуальных систем.
Куда двигаться дальше?
Представленный бенчмарк V-REX, несомненно, выявляет слабости современных Vision-Language Models в области многошагового визуального рассуждения. Однако, само обнаружение несостоятельности — лишь отправная точка. Истинная ценность заключается не в констатации факта, что модель «забывает» предыдущие шаги, а в разработке принципиально новых архитектур, гарантирующих непротиворечивость цепочки рассуждений. Недостаточно просто «обучить» модель планировать; необходимо формально доказать корректность этого планирования. Иначе мы имеем дело лишь с иллюзией интеллекта.
Крайне важно сместить акцент с эмпирической оценки производительности на верификацию алгоритмов. Статистическая значимость результатов на тестовом наборе данных не является доказательством общей применимости. Необходимо разработать формальные методы, позволяющие доказать, что модель способна к дедуктивному рассуждению в заданном визуальном контексте. Иначе говоря, требуется переход от «работает на примерах» к «доказано корректно».
В перспективе, исследования должны быть направлены на создание систем, способных к самопроверке и коррекции ошибок в процессе визуального рассуждения. Необходимо выйти за рамки простого предсказания ответов и перейти к построению систем, способных объяснить логику своих действий и, в случае необходимости, выявить и исправить собственные ошибки. В противном случае, все усилия по улучшению производительности останутся лишь косметическим ремонтом несостоятельного алгоритма.
Оригинал статьи: https://arxiv.org/pdf/2512.11995.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Память против контекста: Когда ИИ нужно вспоминать, а не перечитывать
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Пространственное мышление видео: новый подход к обучению ИИ
- Оптимизация квантовых вычислений: новый подход к порядку переменных
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
2025-12-16 11:52