Автор: Денис Аветисян
Новый подход к обучению моделей компьютерного зрения позволяет им эффективно решать задачи, требующие логического мышления, используя специально разработанные игровые среды.

Представлен алгоритм PC-GRPO — самообучающийся фреймворк, использующий иерархию головоломок для улучшения визуального рассуждения и выявления недостатков в существующих бенчмарках.
Несмотря на прогресс в обучении моделей «зрение-язык» с помощью обучения с подкреплением, ключевые проблемы, такие как зависимость от ручной разметки и нестабильность обучения, остаются актуальными. В данной работе, ‘Puzzle Curriculum GRPO for Vision-Centric Reasoning’, предлагается методика PC-GRPO — самообучающийся алгоритм, использующий головоломки и динамически взвешенную сложность для повышения качества визуального рассуждения. Показано, что предложенный подход не только улучшает согласованность логических цепочек и конечных ответов, но и повышает стабильность обучения и точность на различных бенчмарках. Можно ли с помощью подобных методов создать масштабируемые и интерпретируемые системы визуального рассуждения, не требующие дорогостоящей ручной разметки данных?
Пределы Обучения с Учителем для Мультимодальных Моделей
Современные модели, объединяющие зрение и язык, в значительной степени полагаются на обучение с учителем, что создает зависимость от обширных, размеченных вручную наборов данных. Этот подход предполагает, что модели обучаются, сопоставляя входные данные (изображения и текст) с заранее определенными правильными ответами, предоставленными людьми. По сути, модели учатся повторять закономерности, обнаруженные в этих размеченных данных, а не понимать лежащие в их основе концепции. Таким образом, производительность таких моделей напрямую связана с качеством и объемом размеченных данных, что влечет за собой значительные затраты времени и ресурсов, а также ограничивает их способность эффективно работать в ситуациях, которые не были явно представлены в обучающем наборе. Несмотря на впечатляющие результаты в определенных задачах, эта зависимость от размеченных данных представляет собой серьезное препятствие для создания действительно интеллектуальных систем, способных к обобщению и адаптации к новым, непредсказуемым условиям.
Современные модели, объединяющие зрение и язык, часто демонстрируют ограниченные возможности в решении задач, требующих сложного логического мышления и обобщения знаний. Исследования показывают, что при столкновении с ситуациями, отличными от тех, на которых они обучались, их производительность существенно снижается. Это связано с тем, что модели, обученные на размеченных данных, склонны к запоминанию паттернов, а не к пониманию принципов, лежащих в основе визуальной информации и языка. В результате, даже небольшие отклонения от привычного контекста могут приводить к ошибкам в рассуждениях и затруднять адаптацию к новым, ранее не встречавшимся сценариям, что ставит под вопрос их способность к настоящему интеллектуальному обобщению.
Использование размеченных человеком данных в обучении моделей, работающих с изображениями и текстом, неизбежно вносит субъективные искажения, отражающие предвзятости аннотаторов и ограниченность их восприятия. Эти предубеждения могут проявляться в неверной интерпретации изображений или текстов, приводя к систематическим ошибкам в работе модели. Более того, процесс ручной разметки является дорогостоящим и трудоемким, что создает серьезные ограничения в масштабируемости и препятствует обучению моделей на действительно больших объемах данных, необходимых для достижения подлинного искусственного интеллекта. Таким образом, зависимость от размеченных данных замедляет прогресс в области компьютерного зрения и обработки естественного языка, подчеркивая необходимость разработки методов обучения, не требующих столь обширного участия человека.
Существенная проблема современных моделей, работающих с визуальной и языковой информацией, заключается в отсутствии внутренней мотивации к самостоятельному исследованию и обучению за пределами заданного набора инструкций. В отличие от биологических систем, которые проявляют любопытство и стремление к познанию нового, искусственный интеллект, как правило, ограничивается выполнением задач, для которых он был специально обучен. Это приводит к тому, что модели испытывают трудности при столкновении с неожиданными или неоднозначными ситуациями, поскольку им не хватает способности к самостоятельному анализу и адаптации. Разработка механизмов, стимулирующих внутреннее любопытство и стремление к самообучению, является ключевой задачей для создания более гибких и интеллектуальных систем искусственного интеллекта, способных к настоящему пониманию и решению сложных задач.
Обучение с Подкреплением для Мультимодальных Моделей: Новый Подход
Предлагаемый фреймворк RLVR представляет собой переход от традиционной настройки моделей с использованием контролируемого обучения к обучению с подкреплением, позволяющему визуально-языковым моделям (VLM) осваивать навыки непосредственно посредством взаимодействия со средой. В отличие от контролируемого обучения, требующего размеченных данных, RLVR позволяет модели самостоятельно исследовать среду и получать вознаграждение за успешные действия, что обеспечивает более гибкий и адаптивный процесс обучения. Такой подход позволяет VLM приобретать знания и навыки, неявно содержащиеся в структуре среды, и применять их для решения новых задач, не требуя предварительного обучения на размеченных данных.
В основе нашего подхода лежит метод PC-GRPO, использующий головоломки в качестве среды для обучения. PC-GRPO генерирует внутренние, верифицируемые награды за успешное решение задач, оценивая логическую последовательность действий, необходимых для достижения цели в головоломке. Награды формируются автоматически, исключая необходимость в ручной аннотации и обеспечивая объективную оценку процесса рассуждений модели. Конструкция головоломок позволяет однозначно определить успех или неудачу, предоставляя чёткий сигнал для обучения с подкреплением и способствуя улучшению навыков логического вывода и планирования.
Метод PC-GRPO базируется на алгоритме Group-relative Policy Optimization (GRPO), обеспечивая устойчивую основу для формирования стратегии обучения. GRPO позволяет оптимизировать политику агента, учитывая относительные различия в производительности между группами состояний, что особенно важно в сложных задачах, где абсолютная оценка недостаточно информативна. В основе GRPO лежит вычисление преимущества (advantage) каждого действия относительно среднего значения по группе состояний, к которой оно относится, а не по всему распределению состояний. Это позволяет более эффективно исследовать пространство действий и избегать локальных оптимумов, что приводит к более стабильному и надежному обучению агента в условиях неполной информации и высокой размерности пространства состояний. Использование относительных оценок повышает устойчивость к шуму и позволяет агенту адаптироваться к изменяющимся условиям среды.
Использование обучения с подкреплением позволяет обойти ограничения, связанные с необходимостью ручной аннотации данных, что является существенным преимуществом перед подходами, основанными на контролируемом обучении. Традиционные методы контролируемого обучения требуют больших объемов размеченных данных, создание которых является трудоемким, дорогостоящим и подверженным субъективным искажениям, отражающим предубеждения аннотаторов. Отсутствие ручной разметки в нашем подходе устраняет эти проблемы, обеспечивая возможность масштабирования обучения моделей без ограничений, связанных с доступностью и качеством размеченных данных, а также снижая риск внедрения нежелательных предубеждений в процессе обучения. Это особенно важно для задач, требующих понимания и генерации естественного языка, где субъективность оценок может значительно повлиять на качество модели.
Верифицируемые Награды посредством Головоломок
В рамках нашей системы обучения используется «Пазл-Курикулум», включающий в себя головоломки трех типов: «Соедини картинку» (Jigsaw Puzzles), «Поворот» (Rotation Puzzles) и «Соедини фрагменты» (PatchFit Puzzles). Данный подход обеспечивает разнообразие тренировочных данных и позволяет модели осваивать различные навыки визуального и логического мышления. Использование этих типов головоломок позволяет создать сложную и многогранную обучающую среду, стимулирующую развитие алгоритмов обработки изображений и пространственного анализа. Комбинация головоломок с различными требованиями к решению способствует более эффективному обучению и повышению обобщающей способности модели.
В рамках предложенной системы, корректное решение каждой головоломки — будь то пазл, головоломка с вращением или задача сопоставления фрагментов — однозначно определяет получение вознаграждения. Этот механизм позволяет модели обучаться методом проб и ошибок, где положительное подкрепление выдается за правильные действия, а отсутствие такового — за ошибочные. Объективность вознаграждения, не зависящая от субъективной оценки, обеспечивает стабильность и предсказуемость процесса обучения, позволяя модели эффективно оптимизировать свою стратегию решения задач. Отсутствие неоднозначности в определении корректного ответа критически важно для надежной работы алгоритмов обучения с подкреплением.
Для оптимизации динамики обучения используется система адаптивной сложности заданий. Данная система динамически регулирует уровень сложности головоломок, концентрируясь на задачах средней сложности. Такой подход позволяет избежать как слишком простых головоломок, которые не стимулируют развитие модели, так и чрезмерно сложных, приводящих к снижению эффективности обучения. Алгоритм отслеживает производительность модели и автоматически корректирует сложность заданий, обеспечивая оптимальный баланс между вызовом и возможностями, что способствует более быстрому и стабильному усвоению материала.
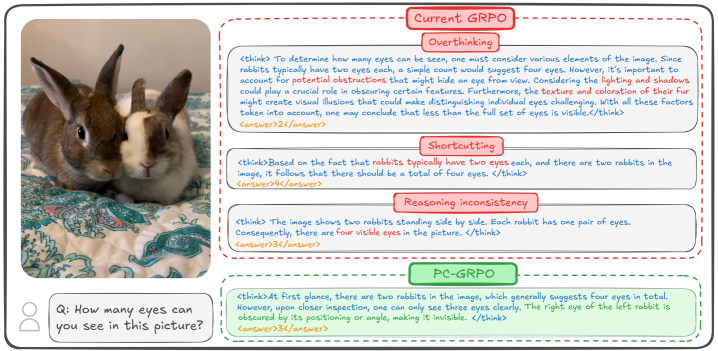
Для оценки согласованности процесса рассуждений модели с окончательным ответом используется метрика Reasoning-Answer Consistency (RAC). RAC измеряет степень соответствия между промежуточными шагами, предпринятыми моделью для решения задачи, и конечным результатом. Высокое значение RAC указывает на то, что модель не просто выдает правильный ответ, но и приходит к нему логичным и обоснованным путем, что является важным показателем надежности и обобщающей способности. Оценка RAC производится путем анализа промежуточных представлений модели и сопоставления их с логической цепочкой, необходимой для получения верного ответа.

Устранение Шума в Данных и Повышение Обобщающей Способности
Исследования показали, что обучение с использованием внутренних наград значительно повышает способность моделей к обобщению, снижая зависимость от потенциально зашумленных данных из стандартных бенчмарков. Вместо того, чтобы полагаться исключительно на оценки, предоставленные человеком, данный подход позволяет модели самостоятельно оценивать качество своих действий и прогресс в решении задачи. Это способствует формированию более надежных и устойчивых к ошибкам систем искусственного интеллекта, поскольку модель учится на основе собственных внутренних критериев, а не на внешних, подверженных субъективности и несовершенству, данных. В результате, достигается улучшенная производительность в новых, ранее не встречавшихся ситуациях, что является ключевым показателем истинного интеллекта и адаптивности.
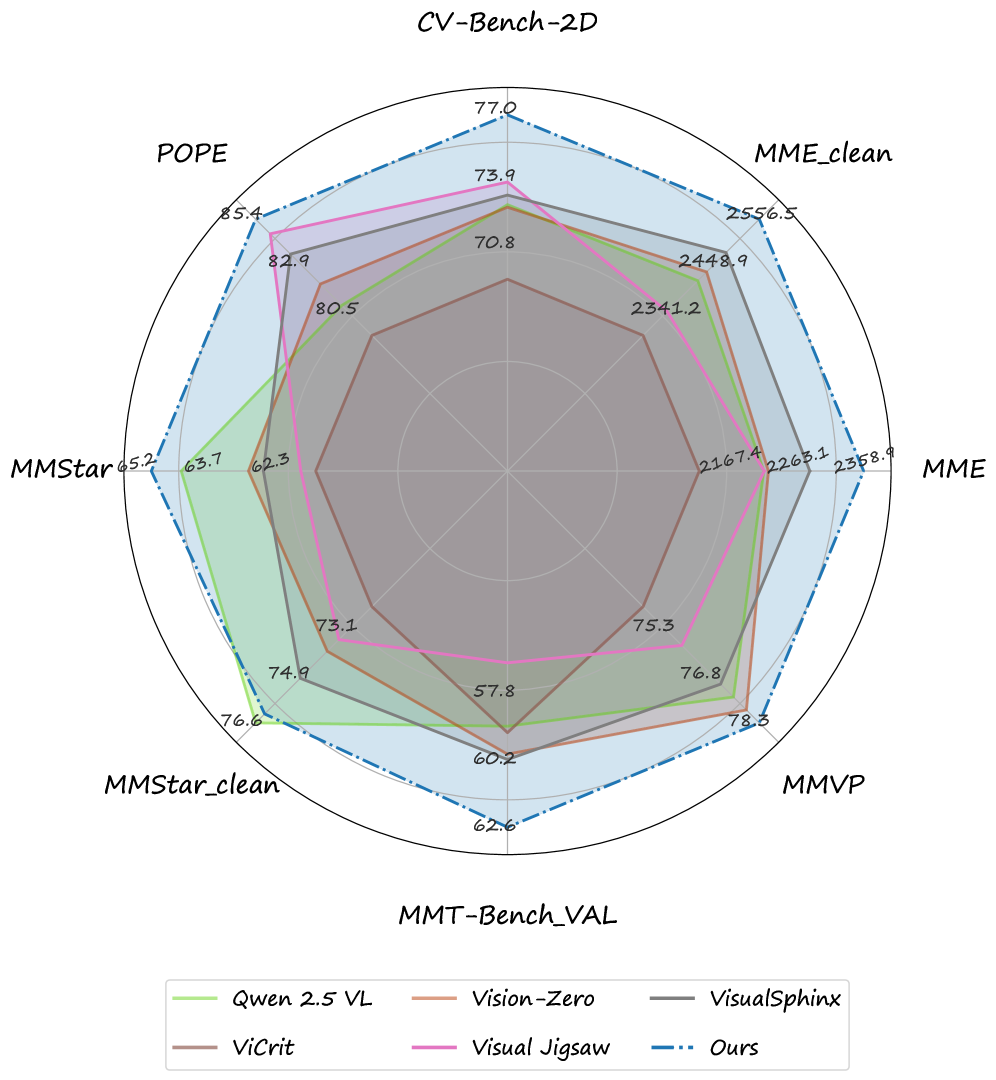
Исследования выявили значительный уровень шума в популярных бенчмарках для оценки визуальных языковых моделей (VLM). Пользовательские исследования показали, что от 10% до 20% данных в таких наборах, как MMStar, SEEDBench и ColorBench, содержат неточности или вводят в заблуждение. Данный шум может существенно искажать результаты оценки, приводя к завышенным или заниженным показателям производительности моделей. Обнаружение и устранение этого шума является критически важным для разработки более надежных и достоверных систем искусственного интеллекта, способных к объективной оценке и самосовершенствованию. Точность данных напрямую влияет на способность моделей к обобщению и адаптации к реальным условиям.
Процесс аудита визуальных языковых моделей (VLM), разработанный исследователями, продемонстрировал высокую точность — от 0.95 до 0.98 — при очистке стандартных наборов данных, таких как MMStar, SEEDBench и ColorBench. Оценка проводилась комитетом экспертных VLM, что позволило выявить и исправить ошибки и несоответствия в аннотациях. Достигнутая точность свидетельствует об эффективности подхода к автоматической проверке качества данных, используемых для обучения моделей, и открывает возможности для создания более надежных и объективных систем искусственного интеллекта. Использование экспертных VLM в качестве арбитров гарантирует высокую степень достоверности и минимизирует риск внесения новых ошибок в процессе очистки данных.
Отделение процесса обучения от ограничений, присущих аннотированным человеком эталонным наборам данных, открывает перспективы для создания более надежных систем искусственного интеллекта. Традиционно, обучение моделей происходит на данных, помеченных людьми, что неизбежно вносит субъективные ошибки и предубеждения. Такой подход ограничивает способность модели к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Исследование показывает, что, фокусируясь на внутренних сигналах вознаграждения и самообучении, можно снизить зависимость от внешних, потенциально зашумленных данных. Это позволяет создавать системы, которые не просто воспроизводят заученные ответы, а действительно понимают задачу и способны к самостоятельному решению проблем, что является ключевым шагом к повышению доверия к искусственному интеллекту и его внедрению в критически важные области.
Вариант GRPO-CARE демонстрирует улучшенную согласованность благодаря внедрению механизма, обеспечивающего выравнивание между последовательными шагами рассуждений. Данный подход позволяет модели более четко придерживаться логической последовательности при решении задач, снижая вероятность противоречий и повышая надежность получаемых ответов. Механизм выравнивания, функционируя как внутренний арбитр, проверяет, соответствует ли каждый последующий шаг рассуждений предыдущим, обеспечивая целостность и непротиворечивость всего процесса. Это особенно важно в сложных задачах, требующих многоступенчатого анализа и логических выводов, где даже незначительные ошибки на ранних этапах могут привести к неверным результатам. Таким образом, GRPO-CARE не только улучшает точность ответов, но и повышает прозрачность и объяснимость процесса принятия решений моделью.

Представленное исследование демонстрирует стремление к математической чистоте в области визуального рассуждения, что находит отражение в разработке алгоритма PC-GRPO. Этот алгоритм, опираясь на принцип возрастающей сложности в обучении, стремится к доказанной корректности, а не просто к успешному прохождению тестов. Как однажды заметил Джеффри Хинтон: «Оптимизация без анализа — это самообман и ловушка для неосторожного разработчика». Данное утверждение особенно актуально в контексте аудита общепринятых визуальных бенчмарков, поскольку исследование выявляет и устраняет шум, мешающий объективной оценке эффективности алгоритмов визуального рассуждения. Таким образом, подход PC-GRPO подчеркивает важность анализа и доказательства корректности в разработке систем искусственного интеллекта.
Что Дальше?
Представленная работа, хотя и демонстрирует улучшение в области визуального рассуждения посредством тщательно выстроенной учебной программы и оптимизации групповой относительной политики, лишь обнажает глубину нерешенных проблем. Сам факт необходимости аудита общепринятых бенчмарков свидетельствует о том, что существующие наборы данных могут быть подвержены скрытым шумам и систематическим ошибкам, что ставит под сомнение достоверность многих опубликованных результатов. Элегантность алгоритма не должна маскировать несовершенство данных, на которых он обучен.
Будущие исследования должны быть направлены не только на повышение производительности моделей, но и на разработку более строгих методов оценки. Необходимо уделить внимание созданию бенчмарков, устойчивых к манипуляциям и способных достоверно отражать реальные когнитивные способности. Простое увеличение масштаба моделей не является решением; истинный прогресс заключается в понимании фундаментальных принципов рассуждения и их воплощении в алгоритмах.
Особенно перспективным представляется исследование методов, позволяющих моделям самостоятельно обнаруживать и исправлять ошибки в данных. Алгоритм, способный к самокритике и самосовершенствованию, — это не просто техническая задача, но и шаг к созданию более надежных и прозрачных систем искусственного интеллекта. В конечном итоге, красота алгоритма проявляется не в трюках, а в непротиворечивости его границ и предсказуемости.
Оригинал статьи: https://arxiv.org/pdf/2512.14944.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
2025-12-18 20:59