Автор: Денис Аветисян
Новый бенчмарк SO-Bench оценивает, насколько хорошо мультимодальные модели извлекают структурированную информацию из изображений.
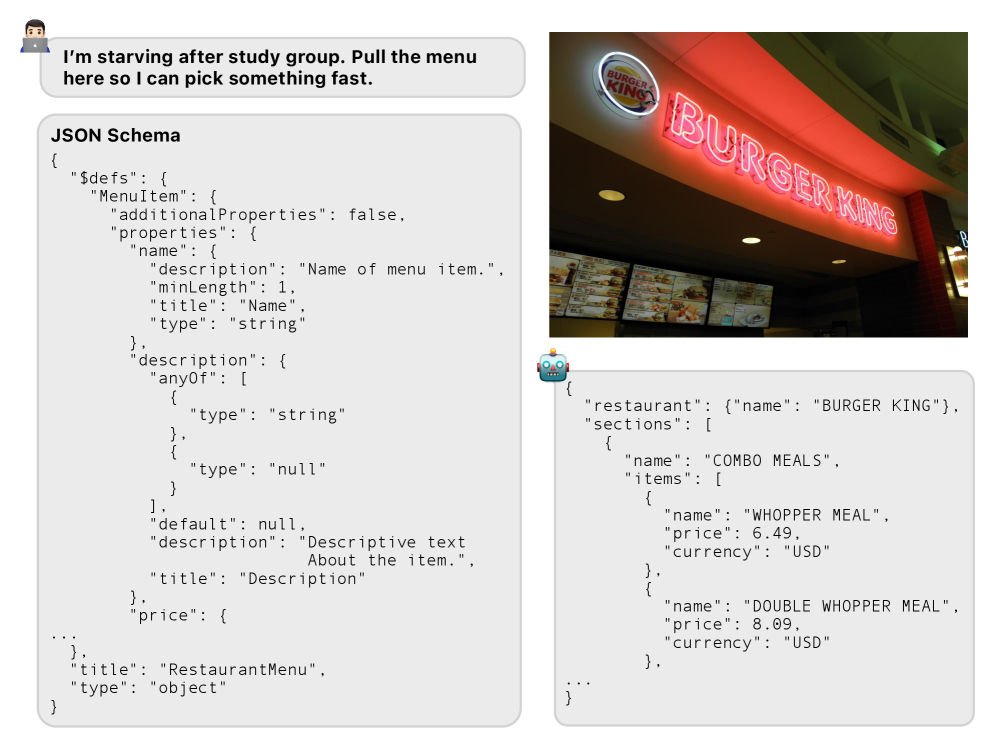
SO-Bench — это комплексная оценка способности больших мультимодальных языковых моделей соответствовать заданным схемам и извлекать данные из визуального контента.
Несмотря на успехи в области генеративных моделей, извлечение структурированных данных из визуальной информации остается сложной задачей для мультимодальных больших языковых моделей. В данной работе представлена платформа SO-Bench: A Structural Output Evaluation of Multimodal LLMs, предназначенная для всесторонней оценки способности моделей извлекать информацию, соответствующую предопределенным схемам, из изображений различных типов. Эксперименты с использованием SO-Bench выявили существенные недостатки в точности и соответствии генерируемых результатов заданным схемам, подчеркивая необходимость улучшения мультимодального структурного рассуждения. Сможем ли мы создать модели, способные надежно интегрироваться с внешними системами, требующими строго структурированных данных?
Вызов Структурированной Генерации Данных
Мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющий потенциал в обработке информации, однако надежное генерирование выходных данных в структурированном формате остается серьезной проблемой. Несмотря на прогресс в области искусственного интеллекта, модели часто испытывают трудности с последовательным и точным соответствием заданным схемам данных. Эта сложность проявляется в неспособности MLLM безошибочно извлекать и представлять информацию в виде таблиц, JSON или других форматов, необходимых для практических приложений, таких как автоматизированный анализ данных или создание баз знаний. Повышение надежности структурированного вывода является ключевой задачей, требующей разработки новых архитектур и методов обучения, способных гарантировать соответствие генерируемых данных заранее определенным требованиям.
Несмотря на впечатляющий прогресс в области больших мультимодальных языковых моделей, простое увеличение их размера не обеспечивает надежного следования предопределенным схемам данных. Исследования показывают, что увеличение числа параметров модели само по себе не гарантирует точность и последовательность структурированного вывода. Модели могут генерировать данные, которые формально соответствуют схеме, но содержат семантические ошибки или неточности, что существенно ограничивает их применимость в задачах, требующих высокой степени достоверности, таких как автоматизированное извлечение информации или построение баз знаний. Это подчеркивает необходимость разработки специализированных методов обучения и архитектур, ориентированных на явное обеспечение соответствия структуре данных, а не полагающихся исключительно на масштабирование модели.
Способность объединять визуальную информацию со структурированными данными имеет решающее значение для множества практических применений, включая автоматизированное заполнение баз данных, создание отчетов и поддержку интеллектуальных систем анализа изображений. Однако, для оценки эффективности моделей в решении этой задачи требуются надежные метрики, выходящие за рамки традиционных показателей точности. Простое сравнение с эталонными данными часто оказывается недостаточным, поскольку не учитывает семантическую согласованность и полноту извлеченной информации. Разработка комплексных метрик, способных оценивать не только корректность отдельных элементов, но и общую структуру и логическую связность полученных данных, является ключевой задачей для дальнейшего развития моделей, способных эффективно взаимодействовать с визуальным миром и преобразовывать его в полезную структурированную информацию.
Построение Надежного Конвейера Генерации Схем
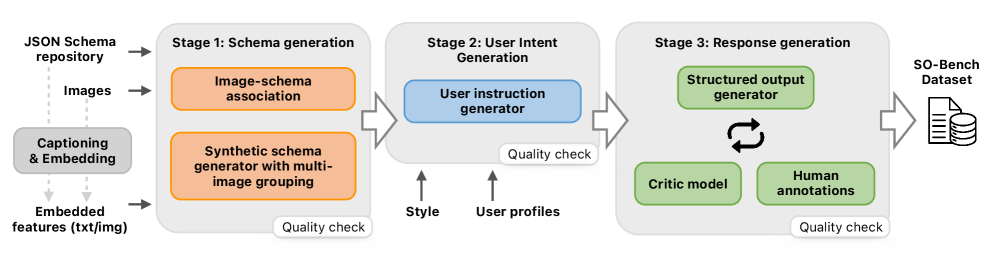
Предлагаемый конвейер генерации схем предназначен для создания разнообразного и сложного набора JSON схем. Он включает в себя автоматизированный процесс, охватывающий сбор существующих схем из открытых источников, а также генерацию новых схем с использованием параметрических алгоритмов и техник мутации. Разнообразие обеспечивается варьированием типов данных, глубины вложенности, количества обязательных и необязательных полей, а также использованием различных ограничений на значения. Сгенерированный набор схем предназначен для оценки и улучшения обобщающей способности моделей, работающих со структурированными данными, и включает в себя как простые, так и сложные структуры для обеспечения комплексного тестирования.
Для повышения обобщающей способности моделей, конвейер генерации схем использует как существующие, реальные схемы JSON, полученные из различных источников, так и синтетически сгенерированные их вариации. Синтетические схемы создаются путем применения ряда трансформаций к исходным схемам, включая изменение типов данных, добавление или удаление полей, а также модификацию ограничений на значения. Комбинация реальных и синтетических данных позволяет обучать модели на более разнообразном наборе примеров, что способствует улучшению их способности к адаптации к новым, ранее не встречавшимся схемам и данным.
В основе конвейера генерации схем лежит использование image embeddings для установления связи между визуальными концепциями и соответствующими структурами JSON-схем. Image embeddings, полученные с помощью предобученных моделей компьютерного зрения, преобразуют изображения в векторные представления. Эти векторы затем используются для поиска и сопоставления с соответствующими фрагментами схем, описывающими объекты и атрибуты, представленные на изображении. Данный подход позволяет создавать схемы, которые отражают визуальные данные, и обучать модели мультимодальному рассуждению, способному обрабатывать и интегрировать информацию из визуальных и структурированных источников. Использование image embeddings обеспечивает более тесную связь между визуальным миром и структурированными данными, что является ключевым для задач, требующих понимания и обработки мультимодальной информации.
Представляем SO-Bench: Новый Оценочный Бенчмарк
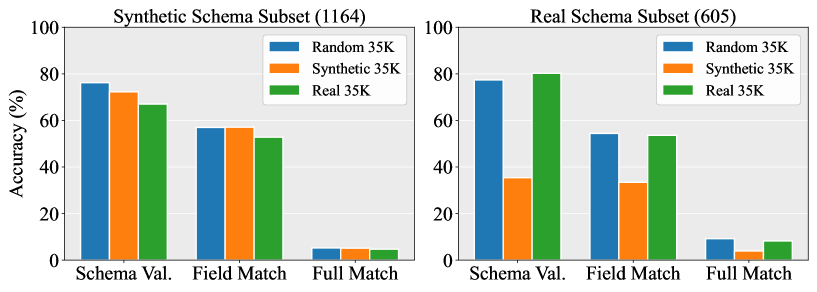
SO-Bench — это новый оценочный набор данных, разработанный для проверки способности мультимодальных больших языковых моделей (MLLM) генерировать структурированные данные, соответствующие сложным JSON-схемам. Набор состоит из 1800 примеров, полученных на основе анализа 112 000 разнообразных изображений. SO-Bench предназначен для оценки способности моделей не только понимать визуальный контент, но и корректно преобразовывать его в структурированный формат, определяемый заранее заданными схемами. Акцент сделан на оценке способности к генерации структурированных выходных данных, а не просто на распознавании объектов на изображениях.
Конструкция SO-Bench разработана для прямой оценки двух ключевых аспектов работы MLLM: понимания визуальной информации и соответствия генерируемых данных заданной схеме JSON. В отличие от существующих бенчмарков, SO-Bench не ограничивается простой валидацией схемы, а оценивает полноту и корректность структурированного вывода, что позволяет получить более комплексную и репрезентативную метрику производительности. Бенчмарк учитывает не только формальное соответствие генерируемых данных схеме, но и способность модели корректно интерпретировать визуальный контент и извлекать из него необходимые данные для построения структурированного вывода.
Первоначальные оценки, проведенные с использованием SO-Bench, демонстрируют ограничения современных MLLM-моделей. Несмотря на то, что модели, такие как Gemini-2.5-Pro, достигают почти 98% точности валидации схемы JSON, формирование полностью корректных структурированных выходных данных остается сложной задачей, при этом максимальная достигнутая точность составляет всего 17.1%. Данный результат был получен на наборе данных, включающем 6.5 тысячи реальных и синтетических схем, что указывает на существенный разрыв между соответствием синтаксису схемы и фактическим пониманием визуального контента и его корректным представлением в структурированном формате.
Исследование, представленное в статье, подчеркивает важность структурированного вывода в мультимодальных больших языковых моделях. Способность извлекать данные в соответствии с заранее определенными схемами — ключевой аспект для надежной интеграции с внешними системами, что находит отражение в представленном SO-Bench. Как заметил Эндрю Ын: «Машинное обучение — это искусство баланса между смещением и разбросом». Это особенно верно в контексте структурированного вывода: необходимо найти баланс между способностью модели следовать схеме (минимизация смещения) и точностью извлеченных данных (минимизация разброса). Пренебрежение любым из этих аспектов снижает практическую ценность системы, ограничивая ее применение в реальных задачах, где важна не только гибкость, но и предсказуемость результатов.
Куда же дальше?
Представленный SO-Bench, как и любой инструмент измерения, лишь обнажает существующие несовершенства, а не устраняет их. Наблюдается закономерная тенденция: модели демонстрируют способность к поверхностному извлечению информации, однако, столкнувшись с неоднозначностью или необходимостью глубокого понимания визуального контекста, быстро теряют точность. Это напоминает умелого каллиграфа, искусно выводящего отдельные иероглифы, но теряющего нить повествования при попытке составить из них осмысленное произведение.
Будущие исследования, несомненно, должны сосредоточиться на разработке методов, позволяющих моделям не просто «видеть» объекты на изображении, но и понимать их взаимосвязи, причинно-следственные связи и скрытые намерения. Необходимо отойти от оценки лишь формального соответствия схеме и перейти к оценке семантической корректности извлеченной информации. Иначе говоря, требуется не просто заполнить ячейки таблицы, но и понять, что за ними скрывается.
Очевидно, что дальнейшее развитие потребует не только усовершенствования архитектур моделей, но и создания более качественных и разнообразных обучающих данных, отражающих всю сложность и неоднозначность реального мира. Иначе, мы рискуем создать лишь иллюзию интеллекта, красивую, но пустую.
Оригинал статьи: https://arxiv.org/pdf/2511.21750.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые прорывы: Хорошее, плохое и смешное
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая криптография: от теории к практике
2025-12-01 08:24