Автор: Денис Аветисян
Новая модель объединяет зрение и язык, опираясь на глубокое понимание трехмерной геометрии окружающего мира.
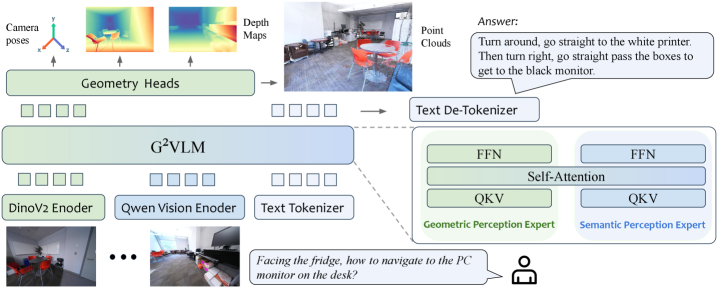
G²VLM: геометрия как основа для унифицированной 3D-реконструкции и пространственного мышления.
Несмотря на успехи моделей «зрение-язык», пространственный интеллект остается сложной задачей, ограничивающей их возможности в понимании и рассуждениях о трехмерном мире. В данной работе представлена модель G$^2$VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning, объединяющая реконструкцию 3D-сцены с глубоким пониманием пространственных отношений. Предложенный подход позволяет эффективно использовать визуальную геометрию для решения как задач 3D-реконструкции, так и задач пространственного мышления, демонстрируя конкурентоспособные результаты. Сможет ли G$^2$VLM стать основой для создания более интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром, например, для редактирования 3D-сцен?
Проблема Пространственного Понимания в Моделях Зрение-Язык
Современные модели, объединяющие зрение и язык, демонстрируют значительные трудности в задачах, требующих развитого пространственного мышления. Это ограничивает их применимость в реальных условиях, где необходимо понимать и интерпретировать трёхмерное окружение по двухмерным изображениям. Например, задачи, связанные с навигацией, сборкой объектов или пониманием сложных сцен, часто оказываются за пределами возможностей этих систем. Неспособность эффективно обрабатывать пространственные отношения между объектами приводит к ошибкам в описании изображений, неточным ответам на вопросы и, в конечном итоге, снижает полезность моделей в практических приложениях, таких как робототехника или помощь людям с ограниченными возможностями зрения.
Современные системы, объединяющие зрение и язык, зачастую достигают результатов путем простого увеличения масштаба вычислительных ресурсов и объема данных, что оказывается неэффективным и не позволяет достичь уровня понимания, присущего биологическим системам. В отличие от человеческого зрения, способного к быстрому и точному анализу пространственных отношений, существующие модели тратят несоразмерно много энергии и времени на решение задач, требующих пространственного мышления. Этот подход, основанный на грубой силе, не позволяет им эффективно обобщать знания и адаптироваться к новым, незнакомым ситуациям, ограничивая их применение в реальных условиях, где требуется надежное и экономичное понимание окружающего мира.
Существенная проблема современных моделей, объединяющих зрение и язык, заключается в их сложности с явным представлением и рассуждением о трехмерной геометрии на основе двухмерных изображений. В то время как человек легко восстанавливает пространственные отношения из плоских картинок, искусственному интеллекту это дается крайне тяжело. Модели часто полагаются на статистические закономерности, а не на глубокое понимание формы, размера и взаимного расположения объектов в пространстве. Способность к реконструкции $3D$ сцены из $2D$ проекции является фундаментальным аспектом истинного пространственного интеллекта, и недостаток этой способности ограничивает возможности моделей в решении задач, требующих понимания физического мира, таких как навигация, манипулирование объектами или интерпретация сложных визуальных сцен.
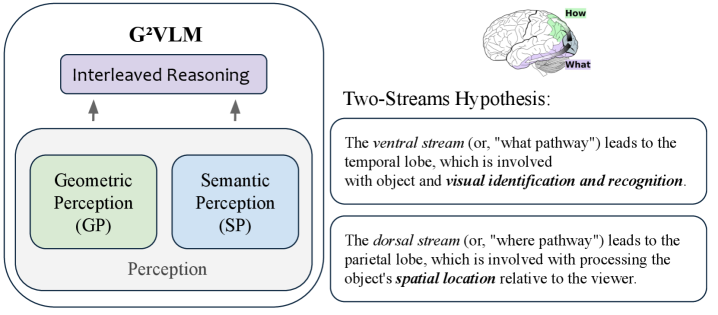
G2VLM: Новая Архитектура для Интегрированного Визуального Геометрического Понимания
G2VLM представляет собой унифицированную модель «зрение-язык», в которой обучение визуальной геометрии интегрировано непосредственно в базовую архитектуру. В отличие от традиционных подходов, где геометрическое понимание сцены формируется неявно, G2VLM явно моделирует геометрические взаимосвязи между объектами и их пространственное расположение. Это достигается путем интеграции специализированного модуля, способного извлекать и представлять геометрические признаки, что позволяет модели более эффективно решать задачи, требующие пространственного рассуждения, такие как визуальное вопросно-ответное взаимодействие и навигация в среде. Такой подход позволяет G2VLM не просто распознавать объекты на изображении, но и понимать их взаимное расположение и контекст в трехмерном пространстве.
Архитектура G2VLM использует двойной кодировщик, объединяющий сильные стороны семантического и геометрического экспертов. Семантический кодировщик обрабатывает визуальную информацию для извлечения высокоуровневых понятий и отношений между объектами, в то время как геометрический кодировщик специализируется на извлечении и кодировании информации о пространственном расположении и геометрических свойствах сцены. Такой подход позволяет модели одновременно учитывать как семантическое содержание изображения, так и его геометрическую структуру, что улучшает ее способность к решению задач, требующих пространственного рассуждения и понимания взаимосвязей между объектами в сцене. Взаимодействие между этими двумя кодировщиками осуществляется посредством механизмов внимания и объединения признаков, что обеспечивает эффективный обмен информацией и совместное представление визуальной информации.
Ключевым нововведением в G2VLM является интеграция эксперта по геометрическому восприятию (Geometric Perception Expert), использующего модель DINOv2 для надежной экстракции признаков. DINOv2, самообучающаяся модель визуального представления, обеспечивает извлечение устойчивых и информативных признаков из изображений, что позволяет эксперту формировать явное геометрическое понимание сцены. В отличие от традиционных подходов, полагающихся на неявное изучение геометрии, G2VLM напрямую кодирует геометрическую информацию, улучшая способность модели к решению задач, требующих пространственного рассуждения и понимания взаимосвязей между объектами в изображении. Использование DINOv2 позволяет эксперту эффективно обрабатывать сложные сцены и обеспечивать робастность к изменениям освещения, масштаба и точки зрения.
Архитектура G2VLM использует подход Mixture-of-Transformer-Experts (MoT) для увеличения емкости модели и повышения производительности в задачах, требующих сложного пространственного рассуждения. MoT позволяет динамически маршрутизировать входные данные к подмножеству экспертов (Transformer-блоков) из общего пула, что позволяет модели специализироваться на различных аспектах входных данных и эффективно использовать параметры. Вместо использования одной большой Transformer-модели, MoT использует несколько небольших экспертов, что снижает вычислительную сложность и улучшает масштабируемость. Это особенно важно для задач, связанных с визуальной геометрией, где необходимо обрабатывать сложные пространственные отношения и большие объемы визуальной информации. В G2VLM, MoT способствует улучшению точности и эффективности в задачах, требующих понимания геометрической структуры сцены.

Подтверждение Эффективности G2VLM: Результаты на Пространственных Бенчмарках
В ходе всестороннего тестирования на бенчмарке SPAR-Bench модель G2VLM продемонстрировала превосходство в решении сложных задач пространственного мышления по сравнению с существующими визуально-языковыми моделями (VLM). Полученный результат G2VLM превысил показатель GPT-4o на 18.5 пунктов, что свидетельствует о значительном улучшении способности модели к пониманию и анализу пространственных отношений между объектами в визуальных сценах. Данный результат подтверждается количественными метриками, оценивающими точность и надежность пространственного рассуждения.
Модель G2VLM демонстрирует высокую точность в задачах оценки глубины по монокулярному изображению и построении облаков точек, что является ключевым для понимания трехмерных сцен. Оценка глубины по одному изображению позволяет модели восстанавливать информацию о расстоянии до объектов, в то время как построение облаков точек предоставляет детальное трехмерное представление геометрии сцены. Эти возможности критически важны для широкого спектра приложений, включая робототехнику, дополненную реальность и компьютерное зрение, где необходимо точное понимание структуры окружающего пространства и положения объектов в нем. Высокая точность в данных задачах позволяет G2VLM эффективно решать более сложные задачи, требующие понимания трехмерной геометрии.
Модель G2VLM демонстрирует высокую точность в задаче оценки положения камеры (Camera Pose Estimation), что критически важно для приложений в области робототехники и дополненной реальности. Оценка положения камеры заключается в определении пространственной ориентации и местоположения камеры в трехмерном окружении. Высокая точность в этой задаче позволяет роботам надежно ориентироваться и взаимодействовать с окружающим миром, а также обеспечивает корректное наложение виртуальных объектов на реальное изображение в приложениях дополненной реальности. Точность G2VLM в данной области позволяет решать задачи, требующие точного понимания трехмерной структуры сцены и положения камеры в ней.
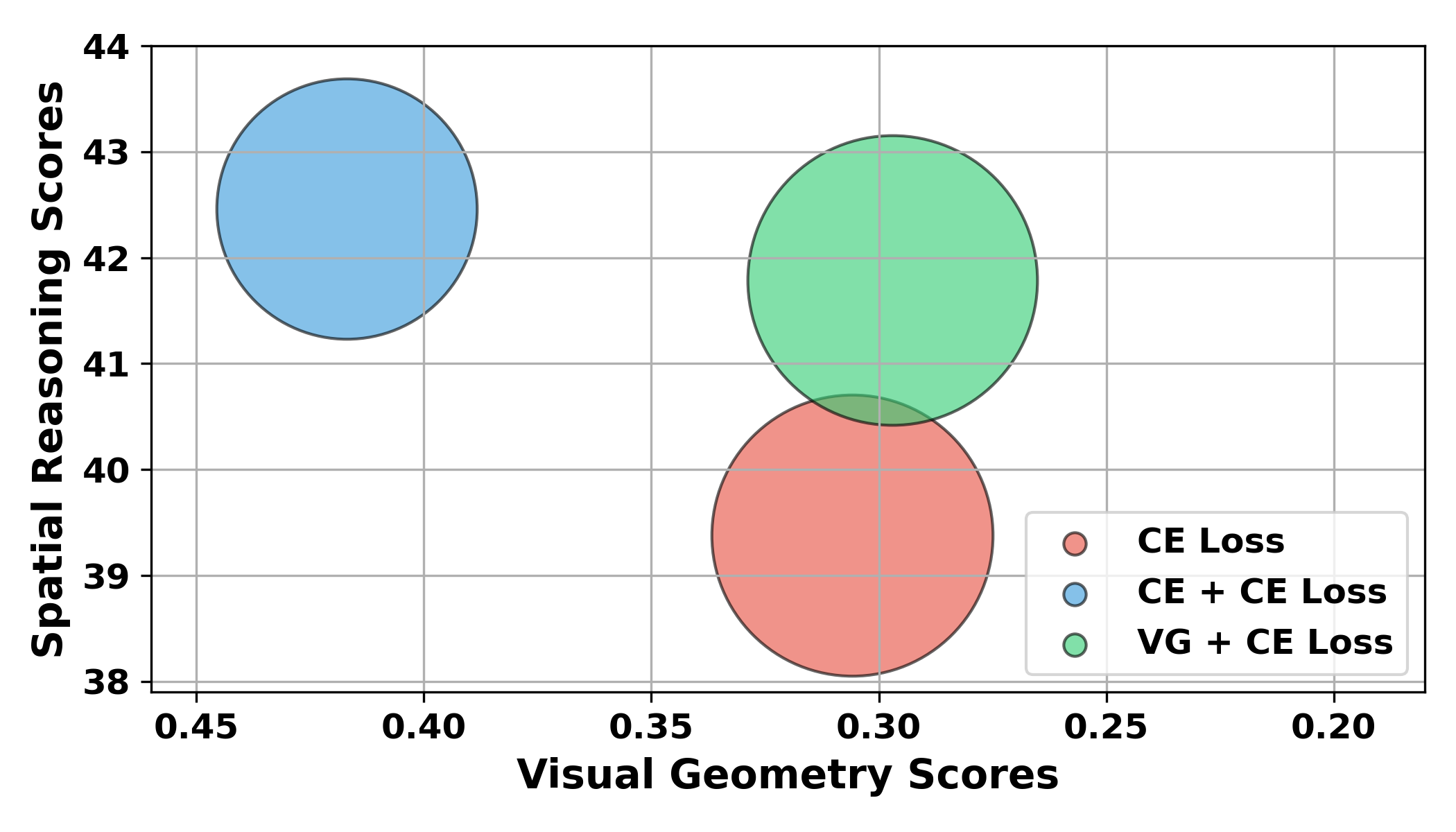
При оценке на наборе данных Sintel, модель G2VLM показала абсолютную относительную ошибку (Abs Rel) в 0.297. Этот результат представляет собой снижение по сравнению с результатом, достигнутым моделью VGGT, который составил 0.335. Показатель Abs Rel является метрикой, широко используемой для оценки точности моделей, предсказывающих глубину, и более низкое значение указывает на более высокую точность прогнозирования глубины в сцене. Таким образом, снижение Abs Rel на 0.038 демонстрирует улучшение точности оценки глубины, обеспечиваемое моделью G2VLM.
В ходе оценки на наборе данных SPAR-Bench, G2VLM продемонстрировал результаты, превосходящие показатели, демонстрируемые людьми. В частности, модель достигла более высокого балла в категории «Low» (низкий уровень сложности) SPAR-Bench, что свидетельствует о её способности к решению задач пространственного рассуждения, требующих базового понимания 3D-сцен и отношений между объектами. Этот результат подтверждается количественными данными, показывающими статистически значимое превышение человеческих показателей в данной категории, что указывает на потенциал G2VLM для применения в задачах, требующих точного и эффективного пространственного анализа.

Расширяя Горизонты: Потенциальные Применения и Будущие Направления
Способность G2VLM к точному представлению и рассуждению о трехмерном пространстве открывает новые горизонты для применения в таких областях, как робототехника, автономное вождение и дополненная реальность. Модель позволяет роботам более эффективно ориентироваться в окружающей среде, понимать сложные сцены и взаимодействовать с объектами, что критически важно для выполнения сложных задач. В сфере автономного вождения, G2VLM способствует более надежному восприятию окружающего мира, позволяя транспортным средствам точнее оценивать расстояния, обнаруживать препятствия и прогнозировать траектории движения. Кроме того, в дополненной реальности, модель обеспечивает более реалистичное и точное наложение виртуальных объектов на реальное окружение, улучшая пользовательский опыт и открывая новые возможности для интерактивных приложений. Таким образом, G2VLM представляет собой важный шаг к созданию интеллектуальных систем, способных эффективно функционировать в сложном трехмерном мире.
Результаты, продемонстрированные моделью на наборе данных Sintel, свидетельствуют о значительном прогрессе в области реалистичного понимания сцен и анализа видео. Sintel, известный своими сложными синтетическими сценами и реалистичными движениями объектов, представляет собой серьезный вызов для алгоритмов компьютерного зрения. Способность G2VLM успешно обрабатывать и интерпретировать видеопоследовательности из этого набора данных указывает на ее потенциал в решении более сложных задач, таких как анализ действий, отслеживание объектов и предсказание будущих событий в видео. Данные результаты подтверждают, что модель способна не только распознавать объекты в кадре, но и понимать их взаимосвязи и динамику, что является ключевым шагом на пути к созданию систем, способных к полноценному визуальному восприятию окружающего мира.
Дальнейшие исследования G2VLM направлены на расширение способности модели к обобщению, то есть к корректной работе с данными, отличными от тех, на которых она обучалась. Особое внимание уделяется освоению методов обучения с небольшим количеством примеров (few-shot learning) и переноса знаний (transfer learning). Это позволит G2VLM адаптироваться к новым задачам и средам, требуя значительно меньше обучающих данных, чем традиционные подходы. Успешная реализация этих направлений откроет путь к созданию более гибких и универсальных систем компьютерного зрения, способных эффективно функционировать в разнообразных и непредсказуемых условиях реального мира.
Интеграция G2VLM с большими языковыми моделями открывает перспективы создания по-настоящему интеллектуальных агентов, способных беспрепятственно взаимодействовать с физическим миром. Данное объединение позволит не только понимать визуальную информацию о пространстве, но и интерпретировать ее в контексте лингвистических команд и запросов. Представьте себе робота, способного не просто распознавать объекты, но и выполнять сложные инструкции, сформулированные на естественном языке, адаптируясь к изменяющимся условиям окружающей среды. Такой симбиоз визуального и лингвистического интеллекта позволит создавать системы, способные к самостоятельному обучению, планированию действий и решению задач в реальном времени, приближая нас к созданию действительно автономных и адаптивных агентов, функционирующих в физическом мире.
Исследование, представленное в данной работе, демонстрирует значительный прогресс в области визуально-языковых моделей, интегрируя трехмерную геометрию и пространственное рассуждение. Модель G$^2$VLM, основанная на принципах Mixture-of-Experts, способна не только реконструировать трехмерные сцены, но и понимать пространственные отношения между объектами. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть построен на понимании, а не только на распознавании образов». Данное утверждение особенно актуально для G$^2$VLM, поскольку модель выходит за рамки простого сопоставления изображения и текста, стремясь к глубокому пониманию геометрии и пространственных взаимосвязей, что позволяет ей успешно решать сложные задачи 3D-реконструкции и пространственного понимания.
Куда двигаться дальше?
Представленная работа, безусловно, демонстрирует прогресс в интеграции геометрического восприятия и лингвистического анализа. Однако, не стоит забывать, что «понимание» системы — это не просто достижение высоких результатов в benchmark-тестах. За кажущейся точностью 3D-реконструкции и пространственного мышления скрывается неизбежная упрощенность модели мира. Необходимо критически оценивать границы применимости G2VLM, особенно в ситуациях, требующих учета контекста, здравого смысла и неявных знаний.
Следующим шагом видится не просто увеличение масштаба моделей или добавление новых параметров, а разработка методов, позволяющих моделировать неопределенность и учитывать потенциальные ошибки восприятия. Важно исследовать возможности интеграции G2VLM с системами, способными к самообучению и активному исследованию окружающей среды. Внимательная проверка границ данных позволит избежать ложных закономерностей, а акцент на интерпретируемость модели — приблизиться к истинному пониманию.
Будущее, вероятно, за системами, способными не просто «видеть» и «говорить», но и задавать вопросы, строить гипотезы и критически оценивать собственные результаты. Иными словами, необходимо переосмыслить саму концепцию «интеллекта» в контексте машинного обучения, избегая антропоморфных иллюзий и признавая фундаментальные ограничения существующих подходов.
Оригинал статьи: https://arxiv.org/pdf/2511.21688.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые прорывы: Хорошее, плохое и смешное
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-28 01:06