Автор: Денис Аветисян
Новый подход использует возможности видеомоделей для итеративного улучшения генерации изображений по текстовому описанию, приближая их к человеческому пониманию.
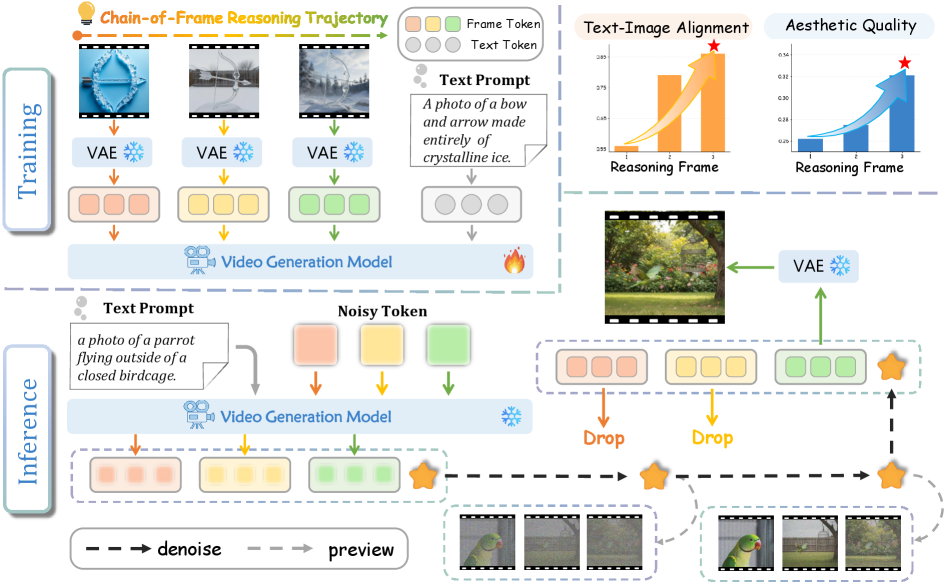
В статье представлена модель CoF-T2I, использующая цепочку фреймов и обучающаяся на новом датасете CoF-Evol-Instruct для высококачественной генерации изображений по текстовым запросам.
Несмотря на успехи современных моделей генерации изображений по тексту, механизмы визуального рассуждения в этом процессе остаются недостаточно изученными. В работе ‘CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation’ предложен новый подход, использующий возможности видеомоделей для последовательного визуального уточнения итеративного формирования изображения. Авторы демонстрируют, что применение принципов «цепочки кадров» (Chain-of-Frame) позволяет значительно улучшить качество генерируемых изображений и достичь конкурентоспособных результатов на стандартных бенчмарках. Может ли такой подход открыть новые горизонты в области высококачественной генерации изображений и сделать визуальное рассуждение ключевым компонентом будущих моделей?
За гранью статичных изображений: Потребность в причинно-следственном рассуждении
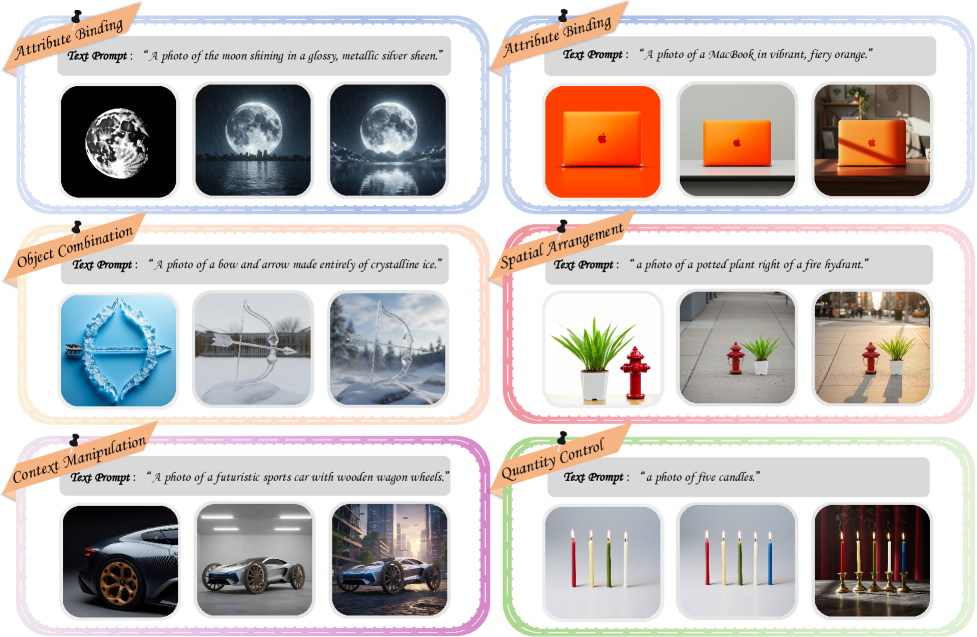
Традиционные модели генерации изображений из текста зачастую испытывают трудности при создании сложных сцен, требующих детального понимания взаимосвязей между объектами. Ограниченность этих систем проявляется в неспособности корректно отобразить нюансы пространственного расположения, взаимодействия и зависимостей между элементами изображения. Например, при запросе «Красный куб стоит на синей сфере, а рядом с ними — зеленая пирамида», модель может ошибочно расположить объекты, игнорировать их относительные размеры или неверно интерпретировать предлоги, описывающие их пространственное положение. Данная проблема возникает из-за того, что большинство существующих алгоритмов стремятся создать изображение сразу, без поэтапного уточнения и проверки соответствия элементов запросу, что приводит к нелогичным и визуально некорректным результатам.
Существующие модели генерации изображений по текстовому описанию часто сталкиваются с трудностями при создании сложных сцен, что обусловлено их неспособностью к последовательному уточнению понимания запроса. В отличие от человеческого мышления, которое предполагает итеративный процесс уточнения и коррекции, эти модели, как правило, выполняют однократный проход по заданному тексту. Это приводит к несоответствиям и неточностям в конечном изображении, особенно при наличии сложных взаимосвязей между объектами или когда требуется соблюдение тонких деталей. Отсутствие механизма обратной связи и возможности пересмотра первоначальной интерпретации запроса существенно ограничивает их способность создавать визуально когерентные и логически последовательные изображения, что подчеркивает необходимость разработки принципиально новых подходов к генерации визуального контента.
Необходимость в новой парадигме генерации изображений обусловлена потребностью в создании визуальных представлений, которые формируются не мгновенно, а последовательно, подобно человеческому мышлению. Вместо однократной обработки текстового запроса, предлагается моделировать итеративный процесс, в котором понимание сцены постепенно углубляется и уточняется. Это означает, что система должна не просто «видеть» отдельные объекты, но и «размышлять» над их взаимосвязями, выявлять скрытые закономерности и разрешать неоднозначности. Такой подход позволяет создавать более когерентные и реалистичные изображения, где каждый элемент логически связан с остальными, а общая композиция отражает сложную структуру исходного запроса. В результате, генерация изображений превращается из простой интерпретации текста в активный процесс визуального «рассуждения».
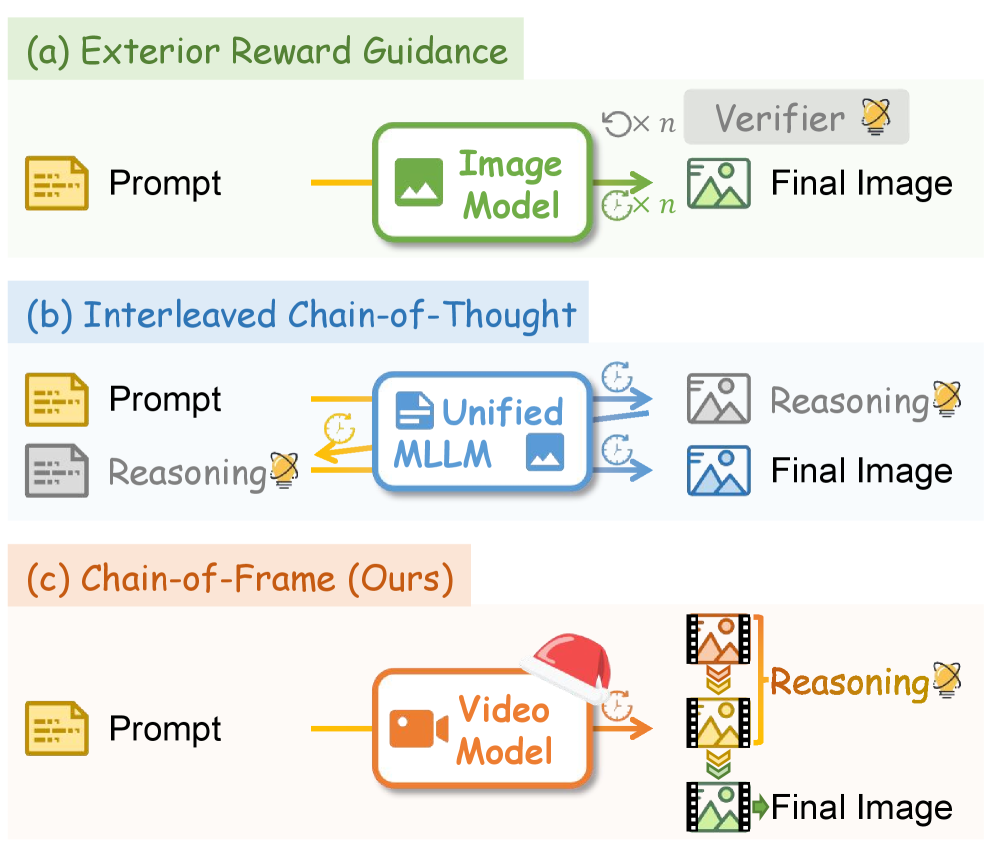
CoF-T2I: Видеогенерация для синтеза изображений
Метод CoF-T2I использует принципы генерации видео для улучшения синтеза изображений из текста посредством итеративной доработки. Вместо однократного создания изображения, CoF-T2I рассматривает процесс генерации как последовательность шагов, аналогичную созданию видео, где каждое последующее изображение уточняется на основе предыдущего и текстового запроса. Такой подход позволяет модели постепенно детализировать и улучшать визуальную согласованность генерируемого изображения, что приводит к более реалистичным и качественным результатам. Итеративный процесс включает в себя генерацию промежуточных кадров, которые последовательно корректируются для достижения желаемого результата, что повышает общую точность и детализацию итогового изображения.
Подход CoF-T2I рассматривает генерацию изображения как последовательный процесс, что позволяет моделировать логические рассуждения и повышать визуальную связность. Вместо одномоментного создания изображения, CoF-T2I генерирует промежуточные кадры, постепенно уточняя и детализируя изображение. Это итеративное построение позволяет модели учитывать предыдущие этапы генерации, обеспечивая более согласованное и правдоподобное изображение. Такой подход имитирует когнитивный процесс рассуждения, в котором сложные задачи решаются путем последовательного выполнения логических шагов, что приводит к улучшению общей визуальной целостности и реалистичности сгенерированного изображения.
В основе CoF-T2I лежит видеогенерационный бэкбон, использующий архитектуры Wan2.1 VAE и Causal VAE для создания промежуточных кадров в процессе синтеза изображений. Wan2.1 VAE обеспечивает эффективное кодирование и декодирование данных, необходимые для генерации визуального контента, в то время как Causal VAE позволяет моделировать последовательные зависимости между кадрами, что критически важно для поддержания когерентности и реалистичности генерируемого изображения. Использование этих моделей позволяет разложить задачу синтеза изображения на последовательность шагов, каждый из которых генерирует промежуточный кадр, улучшая качество и детализацию конечного результата.
Для обеспечения плавных и согласованных переходов между кадрами в процессе генерации изображений, CoF-T2I использует методы Rectified Flow и Flow Matching. Rectified Flow позволяет моделировать непрерывные преобразования между кадрами, устраняя резкие изменения и артефакты. Flow Matching, в свою очередь, фокусируется на обучении модели предсказывать векторное поле потока, направляющее преобразование одного кадра в другой. Это достигается путем минимизации расхождения между предсказанным и истинным потоком, что обеспечивает более реалистичные и визуально связные переходы между промежуточными кадрами, формирующими итоговое изображение. Оба метода работают совместно, повышая стабильность и качество процесса генерации.

CoF-Evol-Instruct: Основа для обучения модели
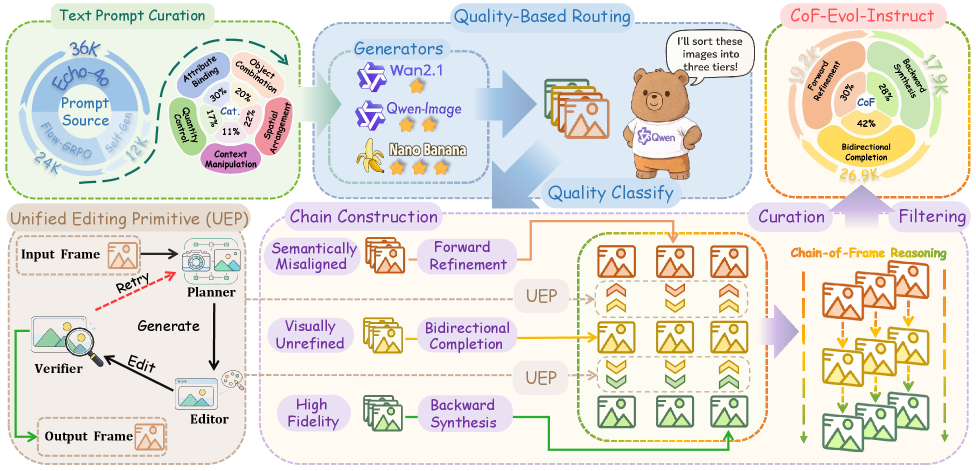
Набор данных CoF-Evol-Instruct, состоящий из 64 000 последовательностей, является основой для обучения модели CoF-T2I. Этот набор данных предоставляет высококачественные обучающие примеры, необходимые для эффективной работы модели при генерации изображений на основе последовательных инструкций. Каждая последовательность в наборе данных содержит информацию, необходимую для обучения модели последовательному уточнению и улучшению изображений, что критически важно для достижения высокого качества и согласованности генерируемых результатов. Объем и качество данных в CoF-Evol-Instruct напрямую влияют на производительность и возможности CoF-T2I.
Для обеспечения качества и релевантности данных в наборе CoF-Evol-Instruct был разработан конвейер курирования данных. В его основе лежит большая мультимодальная модель Qwen3-VL-8B, используемая для автоматической оценки и фильтрации последовательностей. Qwen3-VL-8B анализирует соответствие каждой последовательности заданным критериям, включая семантическую согласованность, визуальное качество и соответствие инструкциям, что позволяет исключить нерелевантные или ошибочные данные и сформировать высококачественный обучающий набор для CoF-T2I.
Набор данных CoF-Evol-Instruct состоит из последовательностей CoF (Compositional Frame), что позволяет модели обучаться итеративному уточнению сцены кадр за кадром. Каждая последовательность CoF представляет собой серию изображений, где каждое последующее изображение является доработанной версией предыдущего, с добавлением или изменением деталей. Такой формат обучения позволяет CoF-T2I освоить процесс последовательного улучшения визуального контента, обеспечивая более высокую согласованность и качество генерируемых изображений за счет учета предыдущих состояний сцены.
Экспериментальные результаты показывают, что использование тщательно отобранного набора данных CoF-Evol-Instruct значительно улучшает качество и связность генерируемых изображений моделью CoF-T2I. Количественные метрики, такие как FID и CLIP Score, демонстрируют снижение ошибок и повышение соответствия сгенерированных изображений заданным текстовым описаниям. Наблюдается улучшение визуальной детализации, реалистичности и последовательности кадров в динамических сценах, что подтверждается субъективной оценкой экспертов и автоматизированными алгоритмами оценки качества изображений.
Валидация CoF-T2I: Бенчмаркинг и перспективы
Для оценки эффективности разработанной модели CoF-T2I проводилось тестирование с использованием общепринятых отраслевых бенчмарков, таких как GenEval и Imagine-Bench. Эти инструменты позволяют объективно сравнить качество генерируемых изображений и видео с результатами, полученными другими передовыми моделями. Использование стандартизированных тестов гарантирует, что результаты оценки CoF-T2I могут быть надежно сопоставлены с достижениями в области генерации изображений, что необходимо для определения реального прогресса и потенциала данной технологии. Такой подход к валидации обеспечивает прозрачность и позволяет научно обоснованно подтвердить заявленные преимущества CoF-T2I.
Принципы причинно-следственного рассуждения (CoF), лежащие в основе CoF-T2I, оказались востребованными и в других передовых системах генерации видео, таких как Sora2 и Veo3. Это свидетельствует о том, что способность модели понимать и учитывать взаимосвязи между объектами и событиями является ключевым фактором для создания реалистичного и последовательного видеоконтента. Использование CoF позволяет этим моделям не просто генерировать визуально привлекательные кадры, но и обеспечивать логическую связность между ними, что значительно повышает общее качество и правдоподобность сгенерированных видеороликов. Внедрение CoF в различные архитектуры подтверждает его универсальность и потенциал для дальнейшего развития области генеративного видео.
Способность модели CoF-T2I к рассуждениям в процессе генерации, подкрепленная мультимодальными верификаторами, значительно повышает её надежность и творческий потенциал. В отличие от систем, оперирующих лишь заученными шаблонами, данная модель способна анализировать входные данные и контекст непосредственно в момент создания видео, что позволяет избегать логических несостыковок и создавать более правдоподобные и оригинальные сцены. Мультимодальные верификаторы, используя информацию из различных источников — текста, изображений и других модальностей — проверяют соответствие генерируемых кадров заданным условиям и логическим связям, тем самым гарантируя целостность и согласованность видеоряда. Такой подход не только снижает вероятность появления артефактов и нереалистичных ситуаций, но и открывает возможности для генерации более сложных и детализированных видео, где каждый кадр логически вытекает из предыдущего и соответствует общему сюжету.
Для повышения качества и согласованности генерируемых изображений в процессе преобразования текста в видео, модель CoF-T2I использует так называемое “кадровое представление”. Данный подход заключается в анализе и обработке каждого кадра видео как отдельной, но взаимосвязанной единицы. Вместо генерации видео как единого целого, модель фокусируется на последовательном создании логичных и визуально связных кадров. Это позволяет достичь большей детализации, избежать визуальных артефактов и обеспечить плавность перехода между кадрами. Такой метод существенно улучшает восприятие видеоряда, делая его более реалистичным и естественным для зрителя, а также повышает общую согласованность визуального повествования.
Исследования показали, что модель CoF-T2I демонстрирует впечатляющие результаты в генерации изображений, достигая показателя 0.86 по шкале GenEval и 7.468 по шкале Imagine-Bench. Эти оценки, полученные на общепризнанных отраслевых бенчмарках, подтверждают конкурентоспособность разработанного подхода и его способность создавать высококачественные и соответствующие запросам изображения. Данные результаты свидетельствуют о том, что CoF-T2I эффективно решает сложные задачи генерации, обеспечивая высокую степень согласованности и реалистичности в создаваемых визуальных материалах, что делает его перспективным инструментом для широкого спектра приложений.
Исследование демонстрирует, что модели, способные к последовательному визуальному рассуждению, подобно CoF-T2I, представляют собой не просто генераторы изображений, а скорее цифровых големов, обучающихся на последовательности «кадров-мыслей». Этот подход, использующий видео-фундаментальные модели, напоминает алхимический процесс: из хаоса данных выкристаллизовывается осмысленное изображение. Геффри Хинтон однажды заметил: «Я думаю, что нейронные сети — это просто способ автоматизировать обучение». Данная работа, с её акцентом на итеративное улучшение через «Chain-of-Frame reasoning», подтверждает эту мысль, показывая, что обучение происходит не одномоментно, а через последовательные шаги, словно заклинание, требующее повторений для достижения желаемого результата. Особое внимание к датасету CoF-Evol-Instruct подчеркивает, что даже самая мощная модель нуждается в тщательно отобранных «снах», чтобы правильно интерпретировать мир.
Что дальше?
Предложенная архитектура CoF-T2I, заигрывая с видео-моделями как с инструментами визуального рассуждения, скорее намекает на путь, чем прокладывает его. Иллюзия итеративного улучшения изображения — это всего лишь способ убедить себя, что модель действительно “понимает” запрос, а не просто перебирает вероятности. Настоящая проверка ждет впереди: сможет ли подобный подход выйти за рамки эстетической привлекательности и решать задачи, требующие истинного логического вывода из визуальной информации?
Создание датасета CoF-Evol-Instruct — это, безусловно, шаг вперёд, но данные не врут, они просто помнят избирательно. Любой набор обучающих примеров — это лишь фрагмент реальности, и его влияние на поведение модели всегда будет непредсказуемым. Будущие исследования должны быть направлены не только на увеличение объёма данных, но и на разработку методов, позволяющих модели самостоятельно обнаруживать и исправлять собственные ошибки, не полагаясь на внешние метрики, которые являются лишь формой самоуспокоения.
В конечном счете, CoF-T2I — это ещё один ритуал в попытке обуздать хаос. Предсказательная модель — это просто способ обмануть будущее, и её эффективность будет зависеть не от сложности алгоритма, а от того, насколько хорошо мы умеем интерпретировать шепот этого самого хаоса. Следующим шагом, вероятно, станет поиск способов заставить модель не просто генерировать изображения, а создавать новые смыслы.
Оригинал статьи: https://arxiv.org/pdf/2601.10061.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-16 11:52