Автор: Денис Аветисян
Исследователи представили метод ExpAlign, позволяющий более эффективно сопоставлять изображения и текстовые описания, особенно для редких категорий объектов.
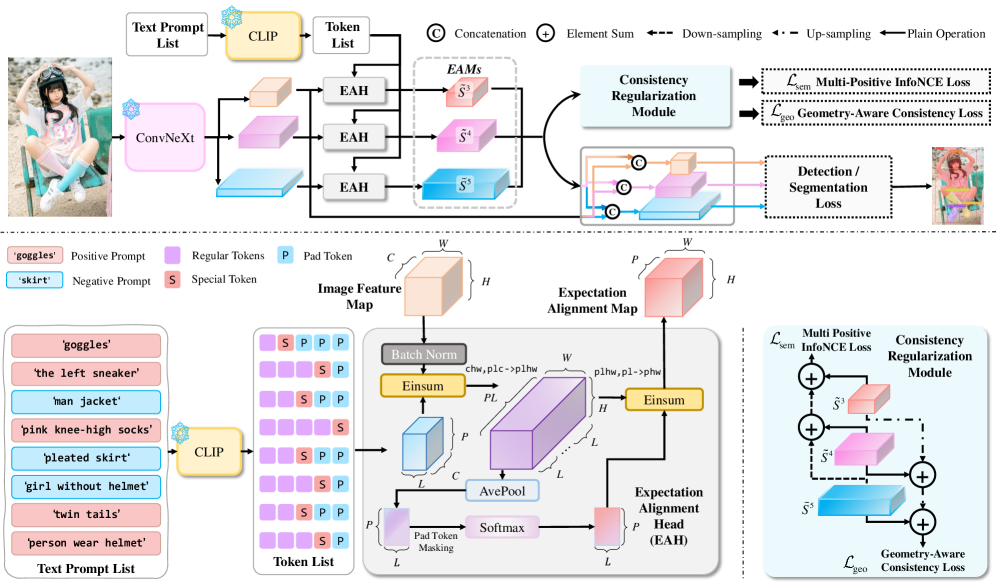
ExpAlign использует принцип согласованности и обучение с подбором экземпляров для улучшения точности сопоставления визуальной и языковой информации в задачах определения объектов на изображениях.
Несмотря на успехи в области сопоставления изображений и текста, задача открытого сопоставления объектов по текстовым запросам остается сложной из-за слабого контроля и необходимости в точной локализации. В данной работе представлен ‘ExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding’, новый фреймворк, основанный на принципах множественного экземпляра обучения и использующий механизм выбора информативных токенов для повышения точности сопоставления. Предложенный подход ExpAlign демонстрирует улучшение результатов в задачах детекции и сегментации, особенно для редких категорий объектов, достигая 36.2 AP$_r$ на LVIS minival split. Возможно ли дальнейшее повышение эффективности ExpAlign за счет интеграции с более мощными языковыми моделями и более сложными схемами регуляризации?
Забытая Элегантность: Проблема Открытой Лексики в Компьютерном Зрении
Традиционные методы обнаружения объектов в компьютерном зрении опираются на заранее заданный набор категорий, что существенно ограничивает их применимость в новых, не предусмотренных сценариях. Данный подход испытывает трудности при распознавании объектов, не входящих в этот фиксированный список, или при интерпретации сложных описаний, включающих отношения между объектами и их атрибутами. По сути, система, обученная идентифицировать «кошку» и «собаку», не сможет корректно определить «кошку, сидящую на красном диване», если не получит дополнительной информации или специальной переподготовки. Это особенно критично в условиях, когда требуется обработка изображений, содержащих объекты, не встречавшиеся в обучающей выборке, или когда необходимо понимать сложные, многословные запросы, описывающие сцену.
Для точного сопоставления текста с областями изображения модели необходимо понимать не просто отдельные слова, а их композицию и тонкие семантические оттенки. Это означает, что алгоритм должен уметь интерпретировать сложные фразы, где значение зависит от взаимосвязи между словами, а также учитывать контекст и подразумеваемые смыслы. Например, фраза «красная машина слева от дерева» требует от модели не только распознавания объектов «машина», «дерево» и цвета «красный», но и понимания пространственных отношений «слева от». Успешное выполнение этой задачи требует продвинутых методов обработки естественного языка и компьютерного зрения, способных улавливать нюансы, которые часто остаются незамеченными при упрощенном анализе.
Существующие методы визуального обоснования сталкиваются с серьезными трудностями при интерпретации неоднозначных или отрицательных понятий, что значительно снижает надежность понимания изображений. Модели часто не способны корректно связать текстовое описание с соответствующей областью на изображении, если описание содержит нечеткие формулировки или отрицания, например, «не синий автомобиль» или «объект слева от стула, но не сам стул». Это связано с тем, что для точной интерпретации требуется не просто распознавание объектов, но и понимание логической структуры предложения и контекстуальных связей. Неспособность корректно обрабатывать такие конструкции приводит к ошибочным результатам и ограничивает применимость систем визуального обоснования в сложных сценариях, где требуется детальное и точное понимание визуальной информации.
ExpAlign: Направление Внимания с Помощью Ожиданий
Механизм Expectation Alignment Head (EAH) в ExpAlign предназначен для генерации карт пространственного выравнивания, обусловленных текстовым запросом, что позволяет уточнить визуальное внимание модели. EAH создает пространственные карты, которые указывают на релевантные области изображения, соответствующие каждому токену в запросе. Этот процесс позволяет модели более точно фокусироваться на ключевых визуальных элементах, релевантных для конкретного запроса, и улучшает качество визуального внимания, направляя обработку изображения на наиболее значимые регионы.
Модуль Expectation Alignment Head (EAH) использует сопоставление на уровне токенов для достижения более точной локализации объектов на изображении. Вместо сопоставления всего текстового запроса с изображением целиком, EAH устанавливает связь между каждым отдельным текстовым токеном и конкретной областью изображения. Такой подход позволяет более детально определить, какие части изображения соответствуют каждому слову или фразе в запросе, что существенно повышает точность определения местоположения объектов и их атрибутов. В результате достигается более гранулярное и точное выравнивание текста и изображения.
Для повышения устойчивости модели ExpAlign использует два метода обучения: Geometry-Aware Consistency Objective (GACO) и Multi-Positive InfoNCE Loss. GACO обеспечивает согласованность пространственных карт выравнивания, что способствует более стабильному определению соответствующих областей изображения. Multi-Positive InfoNCE Loss, основанный на контрастном обучении, усиливает семантическое разделение между различными запросами (prompts), что позволяет модели более точно сопоставлять текстовые описания с визуальными элементами и избегать путаницы между ними. Оба метода совместно работают над улучшением обобщающей способности и надежности модели в различных сценариях.
Для обеспечения согласованности пространственного выравнивания, ExpAlign использует Geometry-Aware Consistency Objective (GACO), который стимулирует формирование логичных и непротиворечивых карт выравнивания. Параллельно, для усиления семантического разделения на уровне запросов, применяется Multi-Positive InfoNCE Loss, реализующая контрастное обучение. Этот подход позволяет модели различать различные запросы и ассоциировать их с соответствующими областями изображения, повышая точность визуального внимания и избегая путаницы между семантически различными концепциями, представленными в запросах.

Подтверждение Эффективности: Наборы Данных и Результаты
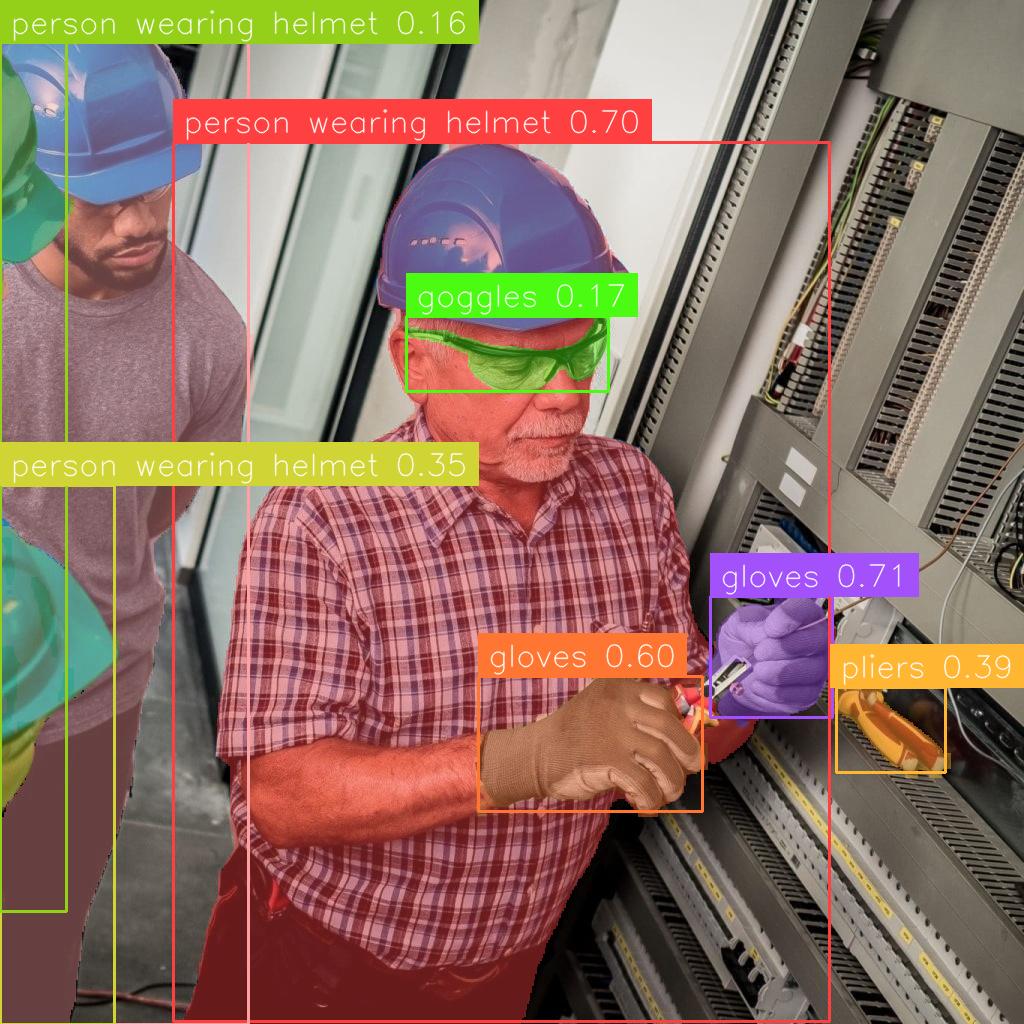
Модель ExpAlign демонстрирует передовые результаты в задачах детекции и сегментации объектов с открытой лексикой. На датасете LVIS minival достигнута точность 37.1 AP (Average Precision). При оценке на более сложных наборах данных, таких как MountainDewCommercial и ShellfishOpenImages*, модель показала значительное улучшение результатов, достигнув 45.46 AP и 42.63 AP соответственно. Данные результаты подтверждают эффективность подхода ExpAlign в решении задач, требующих обобщения на новые, ранее не встречавшиеся классы объектов.
В качестве основы для извлечения признаков в ExpAlign используется DINOv3, что обеспечивает высокую производительность в задаче open-vocabulary grounding. Комбинация DINOv3 с EAH (Efficient Alignment Head) позволила добиться передовых результатов по сравнению с существующими методами. DINOv3 предоставляет надежные и обобщенные представления изображений, а EAH эффективно сопоставляет эти представления с текстовыми запросами, улучшая точность и робастность процесса выравнивания и, как следствие, обеспечивая state-of-the-art результаты в задачах обнаружения и сегментации объектов по текстовому описанию.
Экспериментальные результаты подтверждают эффективность применения как GACO (Generalized Adaptive Cost Optimization), так и InfoNCE (Noise Contrastive Estimation) в процессе выравнивания (alignment). GACO способствует оптимизации затрат на сопоставление признаков, что повышает точность определения объектов. InfoNCE, в свою очередь, улучшает устойчивость модели к шумам и вариациям в данных за счет контрастивного обучения, позволяя более эффективно различать релевантные и нерелевантные признаки. Совместное использование GACO и InfoNCE демонстрирует синергетический эффект, приводящий к повышению общей точности и надежности алгоритма выравнивания.
В ходе экспериментов ExpAlign продемонстрировал результат в 22.4 AP на наборе данных ODinW, что является конкурентоспособным показателем среди современных методов, превосходящим GLIP (19.6 AP). Кроме того, модель показала лидирующие результаты в обнаружении редких категорий на LVIS minival, достигнув AP в 36.2. Данные результаты подтверждают эффективность ExpAlign в задачах обнаружения объектов, особенно в сложных сценариях, включающих редкие или малопредставленные классы.
Расширение Горизонтов: Будущие Применения и Влияние
Развитые возможности привязки к реальности, демонстрируемые ExpAlign, открывают значительные перспективы для робототехники. Система позволяет роботам не просто распознавать объекты, но и точно понимать их взаимосвязь с окружающей средой, что критически важно для эффективной манипуляции предметами и навигации в сложных пространствах. Благодаря способности соотносить текстовые команды с конкретными объектами в визуальном поле, роботы смогут выполнять более сложные и точные задачи, например, сборку деталей или перемещение предметов в соответствии с инструкциями. Это особенно важно для автоматизации производственных процессов, работы в опасных условиях и помощи людям с ограниченными возможностями, где требуется высокая точность и надежность действий робота.
Технология ExpAlign обладает значительным потенциалом для создания инновационных вспомогательных технологий, особенно для людей с нарушениями зрения. Система способна преобразовывать визуальную информацию в детальные словесные описания окружающей среды, позволяя пользователям получать представление об объектах, их расположении и взаимосвязи в реальном времени. Это открывает возможности для повышения самостоятельности и улучшения качества жизни, предоставляя доступ к информации, которая ранее была недоступна. Например, система может описывать сцену перед пользователем, идентифицировать объекты, читать текст или даже помогать ориентироваться в пространстве, что существенно расширяет возможности для полноценного участия в жизни общества.
Предстоящие исследования направлены на расширение возможностей ExpAlign в области анализа видео и сложных сцен. Разработчики планируют адаптировать технологию для обработки динамического контента, позволяя системе не только идентифицировать объекты в отдельных кадрах, но и отслеживать их перемещения и взаимодействия во времени. Это предполагает решение сложных задач, таких как понимание контекста, прогнозирование поведения объектов и интерпретация сложных визуальных повествований. Успешная реализация позволит создавать системы, способные к глубокому анализу видеоданных, что найдет применение в различных областях, включая автономное вождение, видеонаблюдение и робототехнику.
Разрешая давние проблемы сопоставления объектов и понятий в визуальных данных с естественным языком, система ExpAlign открывает новые перспективы для создания более интеллектуальных и адаптивных систем компьютерного зрения. В отличие от предыдущих подходов, требующих заранее определенного словаря, ExpAlign способна понимать и сопоставлять произвольные текстовые описания с изображениями, что значительно расширяет возможности взаимодействия человека и машины. Это позволяет создавать системы, способные не только распознавать объекты, но и понимать контекст и намерения, выраженные в текстовых запросах, что является ключевым шагом к созданию по-настоящему «умных» визуальных систем, способных к гибкому и контекстуально-зависимому анализу окружающей среды.
В очередной раз наблюдается стремление усложнить очевидное. Авторы предлагают ExpAlign для улучшения сопоставления визуальной и языковой информации, особенно для редких категорий. Идея с выделением информативных токенов и регуляризацией карт сопоставления… конечно, звучит умно. Но, по сути, это лишь попытка заставить алгоритм игнорировать шум и фокусироваться на главном. Как будто он сам не мог до этого додуматься. Fei-Fei Li верно подметила: «Искусственный интеллект — это не волшебство, а инженерная дисциплина». И эта дисциплина часто заключается в том, чтобы элегантно обойти проблемы, которые возникли из-за чрезмерной сложности предыдущих решений. В конечном итоге, всё сводится к борьбе с техдолгом, который неизбежно накапливается при каждой новой «революционной» технологии.
Куда же дальше?
Предложенный подход, безусловно, демонстрирует прогресс в согласовании визуальной и языковой информации, особенно в части работы с «длинным хвостом» категорий. Однако, не стоит забывать: каждая «оптимизация» рано или поздно потребует обратной оптимизации. Совершенствование методов выделения информативных токенов — это лишь временное решение. Продакшен всегда найдёт способ выдать запрос, который сломает даже самую элегантную архитектуру.
Будущие исследования, вероятно, будут сосредоточены на создании систем, способных не просто сопоставлять визуальные и языковые данные, а действительно понимать их контекст. Это потребует перехода от методов, основанных на сопоставлении признаков, к более сложным моделям, учитывающим знания о мире. И, конечно, не стоит забывать о проблеме масштабируемости: чем больше данных, тем сложнее поддерживать консистентность и предотвращать накопление ошибок. Архитектура — это не схема, а компромисс, переживший деплой.
В конечном счете, вопрос заключается не в том, чтобы создать идеальную систему сопоставления, а в том, чтобы разработать инструменты, позволяющие адаптироваться к постоянно меняющимся условиям. Мы не рефакторим код — мы реанимируем надежду. И, вероятно, эта работа будет бесконечной.
Оригинал статьи: https://arxiv.org/pdf/2601.22666.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Роботы учатся видеть: новая стратегия управления на основе видео
- Самообучающиеся агенты: новый подход к автономным системам
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Эволюция Симуляций: От Агентов к Сложным Социальным Системам
2026-02-02 19:42