Автор: Денис Аветисян
Новый подход позволяет создавать суверенные большие языковые модели, способные к высоким результатам, даже при ограниченных вычислительных ресурсах и объеме данных.
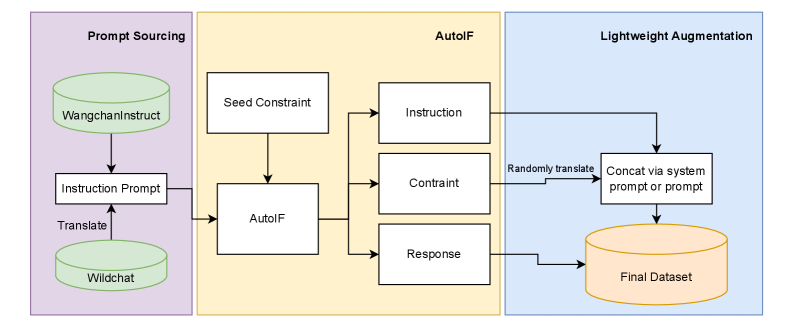
В статье представлена методика Typhoon S, сочетающая обучение с подкреплением, тонкую настройку и инъекцию знаний для создания эффективных языковых моделей, продемонстрированная на примере тайского языка.
Несмотря на стремительное развитие больших языковых моделей (LLM), большинство передовых разработок сосредоточены на высокоресурсных языках, что создает препятствия для суверенных ИИ-систем с ограниченными вычислительными мощностями и данными. В данной работе, ‘Typhoon-S: Minimal Open Post-Training for Sovereign Large Language Models’, представлен минималистичный и открытый рецепт постобучения, сочетающий в себе контролируемое обучение, дистилляцию и обучение с подкреплением, позволяющий создавать суверенные LLM с высокой производительностью. Эксперименты с тайским языком показали, что предложенный подход эффективно трансформирует как адаптированные, так и универсальные базовые модели в инструктивно-настроенные системы, сохраняя при этом специфические знания и улучшая рассуждения в локальном контексте. Возможно ли, используя подобную стратегию постобучения, значительно снизить требования к масштабу данных и вычислений, открывая путь к созданию качественных суверенных LLM в условиях ограниченных ресурсов?
Суверенный Искусственный Интеллект: Основы Независимых Инноваций
Разработка искусственного интеллекта в рамках концепции “суверенного подхода” требует полного контроля над моделями, данными и процессами обучения, что принципиально отличается от традиционных закрытых систем. Вместо использования готовых решений, предлагаемых коммерческими разработчиками, акцент смещается на создание и поддержание собственной инфраструктуры, позволяющей независимо формировать и адаптировать алгоритмы. Такой подход не только обеспечивает защиту от зависимости от внешних поставщиков, но и дает возможность учитывать специфические региональные или организационные потребности, формируя ИИ, максимально отвечающий конкретным задачам и ценностям. Обеспечение полного контроля над всеми этапами жизненного цикла ИИ становится ключевым фактором для развития технологической независимости и инноваций.
Использование моделей с открытыми весами становится необходимым условием для развития искусственного интеллекта, способного адаптироваться к специфическим потребностям и задачам. В отличие от закрытых систем, где алгоритмы и данные недоступны для модификации, открытые модели позволяют локальным разработчикам настраивать и оптимизировать их под конкретные условия и языковые особенности. Это не только стимулирует инновации, но и избавляет от зависимости от конкретного поставщика технологий, предотвращая ситуацию, когда критически важные инструменты оказываются недоступными или не соответствуют меняющимся требованиям. Таким образом, открытость весов способствует созданию более устойчивой и независимой экосистемы искусственного интеллекта, ориентированной на решение региональных и отраслевых задач.
Инициатива “Полностью Открытый Искусственный Интеллект” выступает за принципиально новый подход к разработке и внедрению ИИ, выходящий за рамки простой публикации весов обученной модели. В отличие от традиционных практик, где доступ к исходному коду и данным ограничен, данная инициатива предоставляет полный доступ к всей цепочке обучения — от подготовки данных и архитектуры модели до алгоритмов оптимизации и инструментов оценки. Это означает, что исследователи и разработчики получают не просто готовое решение, а возможность полностью контролировать процесс создания ИИ, адаптировать его под конкретные задачи и потребности, а также проводить независимый аудит и модификацию. Такой подход не только стимулирует инновации и ускоряет прогресс, но и обеспечивает прозрачность и надежность систем искусственного интеллекта, исключая зависимость от конкретных поставщиков и позволяя создавать действительно суверенные ИИ-решения.
Сохранение контроля над моделями искусственного интеллекта имеет первостепенное значение для обеспечения соответствия преимуществ, которые он приносит, конкретным региональным или организационным потребностям. Отсутствие такого контроля может привести к внедрению решений, не учитывающих местные особенности, культурные нюансы или приоритеты развития. Например, алгоритмы, обученные на данных, отражающих реалии одной страны, могут оказаться неэффективными или даже предвзятыми при применении в другой. Поэтому, возможность адаптировать модели и данные под конкретные задачи, а также самостоятельно контролировать весь процесс обучения, является ключевым фактором для получения максимальной пользы от искусственного интеллекта и обеспечения его соответствия целям и ценностям конкретной организации или региона.
Адаптация Модели: От Базовой до Инструктивной
Модель Qwen3-8B-Base представляет собой мощную основу для создания языковых ассистентов, однако она не предназначена для непосредственного выполнения инструкций. Для эффективной работы с пользовательскими запросами требуется дополнительная адаптация, включающая обучение модели понимать и следовать инструкциям. Базовая модель способна генерировать текст, но ей не хватает способности интерпретировать намерения пользователя, выраженные в виде инструкций, и формировать соответствующие ответы без дополнительной подготовки и тонкой настройки.
Модель ‘Typhoon-S-8B-Instruct’ адаптируется из базовой версии посредством двух последовательных этапов. Сначала применяется контролируемое обучение (Supervised Fine-Tuning, SFT), где модель обучается на размеченном наборе данных инструкций и соответствующих ответов. Затем следует обучение с подкреплением на основе политики (On-Policy Distillation, OPD), в ходе которого модель имитирует поведение более мощной модели-учителя, генерируя ответы на те же инструкции. Этот двухэтапный процесс позволяет эффективно перенести знания и навыки из учителя в ‘Typhoon-S-8B-Instruct’, улучшая ее способность следовать инструкциям и генерировать релевантные ответы.
Процесс преобразования базовой модели в ассистента, способного следовать инструкциям, заключается в адаптации ее способности понимать и генерировать ответы на запросы пользователя. Это достигается путем обучения модели на наборе данных, содержащем пары «инструкция-ответ», что позволяет ей сопоставлять входные запросы с соответствующими действиями или откликами. В результате, модель не просто предсказывает следующее слово в последовательности, а формирует осмысленные и релевантные ответы, соответствующие поставленной задаче и контексту запроса. Такая настройка существенно повышает ее пригодность для использования в интерактивных приложениях и системах поддержки.
Модель ThaiLLM-8B была адаптирована для тайского языка и культурного контекста посредством двухэтапного процесса, аналогичного использованному для Typhoon-S-8B-Instruct: сначала проведено обучение с учителем (Supervised Fine-Tuning, SFT), за которым последовала дистилляция с использованием политики (On-Policy Distillation, OPD). В результате адаптации ThaiLLM-8B демонстрирует улучшенные показатели производительности в различных тайских языковых бенчмарках, что подтверждает эффективность данного подхода к локализации и оптимизации больших языковых моделей для конкретных языков и культур.
Юридический Рассуждающий Агент: Экспертиза Через Целенаправленное Обучение
Модель ‘Typhoon-S-4B-Legal-Agent’ представляет собой пример специализированного искусственного интеллекта, разработанного для выполнения задач, требующих продвинутого юридического рассуждения. Данная модель демонстрирует способность к анализу и интерпретации юридических данных, что позволяет ей решать сложные задачи в области права. Её архитектура ориентирована на достижение высокой точности и эффективности при обработке юридической информации, что отличает её от моделей общего назначения.
Модель ‘Typhoon-S-4B-Legal-Agent’ построена на основе языковой модели ‘Qwen3-4B-Instruct-2507’ и использует фреймворк ‘Agentic InK-GRPO’ для расширения предметной области знаний. ‘Agentic InK-GRPO’ позволяет интегрировать внешние инструменты и базы данных, обеспечивая доступ к специализированной информации, необходимой для решения юридических задач. Такой подход позволяет модели не только понимать общие принципы права, но и учитывать конкретные детали и нюансы, характерные для юридической практики, что значительно повышает её эффективность в решении сложных юридических вопросов.
Обучение модели проводилось с использованием датасета NitiBench, специализированного ресурса на тайском языке, предназначенного для оценки способностей к юридическому рассуждению. На момент тестирования, модель размером 4B достигла точности в 19.30% при решении задач, представленных в NitiBench. Этот показатель демонстрирует начальный уровень понимания и обработки юридических вопросов на тайском языке, полученный в результате обучения на данном датасете.
Метод Agentic RFT (Reinforcement Fine-Tuning) был применен для улучшения навыков ведения многоходовых диалогов, что критически важно при обработке сложных юридических запросов. В ходе обучения с подкреплением, модель продемонстрировала абсолютное повышение точности на 4% при оценке на датасете NitiBench, используя 4-х миллиардную версию модели (4B). Данное улучшение свидетельствует об эффективности метода в контексте юридического домена и повышении способности агента к последовательному и логичному взаимодействию с пользователем при решении комплексных задач.
Усиление Рассуждений: Внедрение Знаний и Оптимизация Градиента
Алгоритм InK-GRPO представляет собой развитие метода обучения с подкреплением GRPO, в котором ключевым нововведением является внедрение специализированных знаний в процесс обучения. В отличие от традиционных подходов, где агент самостоятельно исследует пространство решений, InK-GRPO направляет обучение, предоставляя предварительную информацию о предметной области. Этот подход позволяет агенту значительно быстрее осваивать сложные задачи, поскольку он не начинает с нуля, а использует уже существующие знания в качестве отправной точки. Внедрение доменных знаний осуществляется посредством специализированных механизмов, интегрированных в структуру алгоритма, что позволяет эффективно комбинировать преимущества обучения с подкреплением и экспертных систем.
Внедрение специализированных знаний в процесс обучения позволяет агенту значительно ускорить освоение сложных задач и достичь превосходящих результатов. Вместо того чтобы полагаться исключительно на самостоятельное исследование, агент использует предварительно заданную информацию как основу для более эффективного обучения с подкреплением. Такой подход не только сокращает время, необходимое для достижения оптимальной производительности, но и позволяет агенту справляться с задачами, требующими глубокого понимания предметной области, демонстрируя улучшенную способность к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Это особенно важно при решении задач, где объем данных для обучения ограничен или где требуется высокая точность и надежность принимаемых решений.
Сочетание инъекции знаний и обучения с подкреплением позволяет агенту не просто отвечать на вопросы, но и осуществлять полноценное рассуждение при решении юридических задач. В отличие от традиционных систем, опирающихся на жестко заданные правила или статистический анализ, данный подход позволяет агенту анализировать сложные правовые ситуации, выявлять релевантные прецеденты и нормы, и на их основе формулировать аргументированные заключения. Это достигается благодаря интеграции экспертных знаний в процесс обучения, что направляет агента к более эффективному поиску и применению правовых принципов. В результате, система способна не только находить ответы на конкретные вопросы, но и демонстрировать способность к логическому мышлению и решению задач, требующих глубокого понимания правовой материи.
Сохранение общих способностей является критически важным аспектом при обучении агентов искусственного интеллекта, поскольку узкая специализация часто приводит к снижению производительности в неизученных областях. Представленный подход демонстрирует впечатляющую способность к удержанию общих знаний, показывая результаты в диапазоне 48.08%-49.55% на стандартных бенчмарках. Это свидетельствует о том, что внедрение специализированных знаний не приводит к катастрофическому забыванию ранее усвоенной информации, а позволяет агенту эффективно комбинировать новые знания с существующими, обеспечивая гибкость и адаптивность к различным задачам. Такой баланс между специализацией и обобщением является ключевым шагом к созданию действительно интеллектуальных систем.
Будущее Суверенного ИИ: Адаптивность и Контроль
Организации получают возможность создавать индивидуализированные решения в области искусственного интеллекта благодаря сочетанию открытых моделей, целенаправленного обучения и внедрения специализированных знаний. Использование моделей с открытыми весами позволяет избежать зависимости от проприетарных систем и адаптировать AI под конкретные задачи. Целенаправленное обучение, в свою очередь, фокусирует возможности модели на решении узкоспециализированных задач, повышая ее эффективность и точность. Внедрение специализированных знаний, или “knowledge injection”, позволяет обогатить модель информацией, релевантной для конкретной области применения, что значительно расширяет спектр решаемых задач и обеспечивает более качественные результаты. Такой подход позволяет компаниям не просто использовать AI, но и формировать его в соответствии со своими потребностями, открывая новые горизонты для инноваций и развития.
Отказ от проприетарных систем и переход к локализованной адаптации искусственного интеллекта открывает новые горизонты для инноваций. Традиционно, зависимость от закрытых моделей ограничивала возможности организаций по настройке и развитию ИИ под специфические задачи и потребности. Теперь, благодаря возможности самостоятельной разработки и обучения моделей, появляется шанс на создание действительно уникальных решений, учитывающих местные особенности и контекст. Это не просто технический прогресс, но и фактор, способствующий развитию независимости и конкурентоспособности, позволяя организациям формировать собственные траектории развития искусственного интеллекта и более эффективно решать возникающие задачи.
Сочетание суверенного контроля и адаптируемых моделей открывает перспективный путь к созданию действительно полезного искусственного интеллекта. Вместо полагаться на закрытые, универсальные системы, организации получают возможность формировать ИИ, отвечающий их конкретным потребностям и ценностям. Это достигается за счет возможности локальной доработки и обучения моделей, а также внедрения специфических знаний, что позволяет ИИ эффективно решать задачи в заданном контексте. Такой подход не только повышает эффективность, но и гарантирует, что развитие искусственного интеллекта соответствует этическим нормам и стратегическим целям конкретной организации или государства, что является ключевым фактором для построения доверия и безопасного использования ИИ в будущем.
Перспективные исследования в области суверенного искусственного интеллекта направлены на расширение границ применения разработанных методик, выходя за рамки текущих областей. Особое внимание уделяется усовершенствованию процесса внедрения знаний в модели — так называемому “knowledge injection”. Ученые стремятся разработать более эффективные и точные способы передачи специфической информации, позволяющие адаптировать ИИ к потребностям различных отраслей, включая медицину, финансы и промышленность. Совершенствование этих методов предполагает не только увеличение объема передаваемых знаний, но и оптимизацию их формата и структуры, что позволит создавать более гибкие и эффективные системы искусственного интеллекта, способные к обучению и адаптации в различных условиях. Ожидается, что дальнейшие разработки в этой области приведут к появлению ИИ-систем, способных решать сложные задачи, требующие специализированных знаний и глубокого понимания предметной области.
Исследование, представленное в данной работе, демонстрирует, что эффективная архитектура больших языковых моделей не обязательно требует огромных вычислительных ресурсов. Подход Typhoon S акцентирует внимание на минимальном, но целенаправленном пост-обучении, что позволяет создавать суверенные модели, адаптированные к конкретным языкам и задачам. Это соответствует принципу, что структура определяет поведение системы. Как отмечал Бертран Рассел: «Всякое увеличение скорости предполагает увеличение риска». В контексте разработки ИИ, стремление к скорости и масштабу не должно затмевать необходимость в продуманной и эффективной архитектуре, способной обеспечить надежность и контроль. Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений.
Куда же дальше?
Представленная работа демонстрирует, что создание компетентных языковых моделей не обязательно требует колоссальных вычислительных ресурсов и огромных объемов данных. Однако, иллюзия простоты, как часто бывает, скрывает глубину нерешенных проблем. Эффективность метода Typhoon S, безусловно, заслуживает внимания, но вопрос о его масштабируемости на языки и домены, значительно отличающиеся от тайского, остается открытым. Успех, основанный на тщательно подобранных данных и целенаправленном обучении с подкреплением, может оказаться хрупким в условиях реальной, неконтролируемой среды.
Будущие исследования, вероятно, будут сосредоточены на разработке более универсальных стратегий пост-обучения, способных адаптироваться к различным языковым особенностям и доменным требованиям. Важно помнить, что изящное решение — это не всегда самое сложное, но всегда самое понятное. Попытки создания “самообучающихся” систем, игнорирующих фундаментальные принципы лингвистики и когнитивной науки, рискуют обернуться лишь усложнением и безрезультатностью.
В конечном счете, задача заключается не в создании все более мощных моделей, а в понимании того, как знания представляются и обрабатываются. Простота, ясность и целостность — вот те принципы, которые должны лежать в основе любого серьезного исследования в области искусственного интеллекта. Иначе, мы рискуем построить впечатляющий, но бессмысленный механизм.
Оригинал статьи: https://arxiv.org/pdf/2601.18129.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый Шум: Не Враг, а Возможность?
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Видео и Текст: Новая Гармония Генерации
2026-02-01 11:39